本文主要是介绍数据解读广大“钢铁直男”眼中的女神评判标准(文末有彩蛋),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者介绍:徐麟,目前就职于互联网公司数据部,哥大统计数据狗,从事数据挖掘&分析工作,喜欢用R&Python玩一些不一样的数据
个人公众号:数据森麟(ID:shujusenlin),知乎同名专栏作者。
本文图片来自于“懂球帝”APP

笔者作为一位喜爱足球的球迷,“懂球帝”一定会是款必不可少的app,即使是只有16G的空间,也从未将其卸载。然而我们今天聊的与足球无关,而是去聊懂球帝上的“女神大会”专栏,作为一个大型“钢铁直男”聚集地,“懂球帝”上对各位女神的评分,对广大“钢铁直男”群体也具有一定代表性。
目前女神大会更新至了第90期,总共出场了90位女神,界面如下:

我们通过fiddler获取该界面中女神的照片地址以及每一篇文章的id编号,用于之后的爬取和可视化,代码如下:
import json
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
import os
os.chdir('D:/爬虫/女神')id_list = []
title_list = []
pic_list = []
date_list=[]for i in range(1,6):url= 'http://api.dongqiudi.com/search?keywords=%E5%A5%B3%E7%A5%9E%E5%A4%A7%E4%BC%9A&type=all&page='+str(i) html = requests.get(url=url).contentnews = json.loads(html.decode('utf-8'))['news']this_id = [k['id'] for k in news]this_pic = [k['thumb'] for k in news]this_title = [k['title'] for k in news]this_date = [k['pubdate'] for k in news]this_title=[BeautifulSoup(k,"html.parser").text for k in this_title]id_list = id_list+this_idtitle_list = title_list+this_titlepic_list = pic_list+this_picdate_list = date_list+this_date另一方面,每位女神的评分都在下一期当中,我们需要爬取文章内容进行获取:

爬取代码如下:
prev_title_list = []
score_list=[]
count_list=[]
for id in id_list:url = 'http://www.dongqiudi.com/archive/{k}.html'.format(k=id) header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win32; x32; rv:54.0) Gecko/20100101 Firefox/54.0','Connection': 'keep-alive'}cookies ='v=3; iuuid=1A6E888B4A4B29B16FBA1299108DBE9CDCB327A9713C232B36E4DB4FF222CF03; webp=true; ci=1%2C%E5%8C%97%E4%BA%AC; __guid=26581345.3954606544145667000.1530879049181.8303; _lxsdk_cuid=1646f808301c8-0a4e19f5421593-5d4e211f-100200-1646f808302c8; _lxsdk=1A6E888B4A4B29B16FBA1299108DBE9CDCB327A9713C232B36E4DB4FF222CF03; monitor_count=1; _lxsdk_s=16472ee89ec-de2-f91-ed0%7C%7C5; __mta=189118996.1530879050545.1530936763555.1530937843742.18'cookie = {}for line in cookies.split(';'):name, value = cookies.strip().split('=', 1)cookie[name] = value html = requests.get(url,cookies=cookie, headers=header).contenttry:content = BeautifulSoup(html.decode('utf-8'),"html.parser")score = content.find('span',attrs={'style':"color:#ff0000"}).textprev_title = content.find('a',attrs={"target": "_self"}).textprev_title_list.append(prev_title)score_list.append(score)sentence = content.text.split(',')count=[k for k in sentence if re.search('截至目前',str(k))][0]count_list.append(count)except:continue我们此次利用R语言中的ggimage包,将获取到的女神图片加入到最终的图表中,提高可视化效果,首先看一下整体评分的TOP15名单:

朱茵、林志玲、高圆圆位居榜单前三位,不知道这份榜单是否符合你心目中的女神标准,而这三位也恰好成为了目前出场的90位女星当中香港、台湾、大陆的最高分。值得一提的是,懂球帝小编对于活跃于90年代的香港女星情有独钟,从中选取了非常多的女神,而这些女神的评分也都名列前茅。
下面看一下目前出场的90位女神中,排名相对靠后的几位:
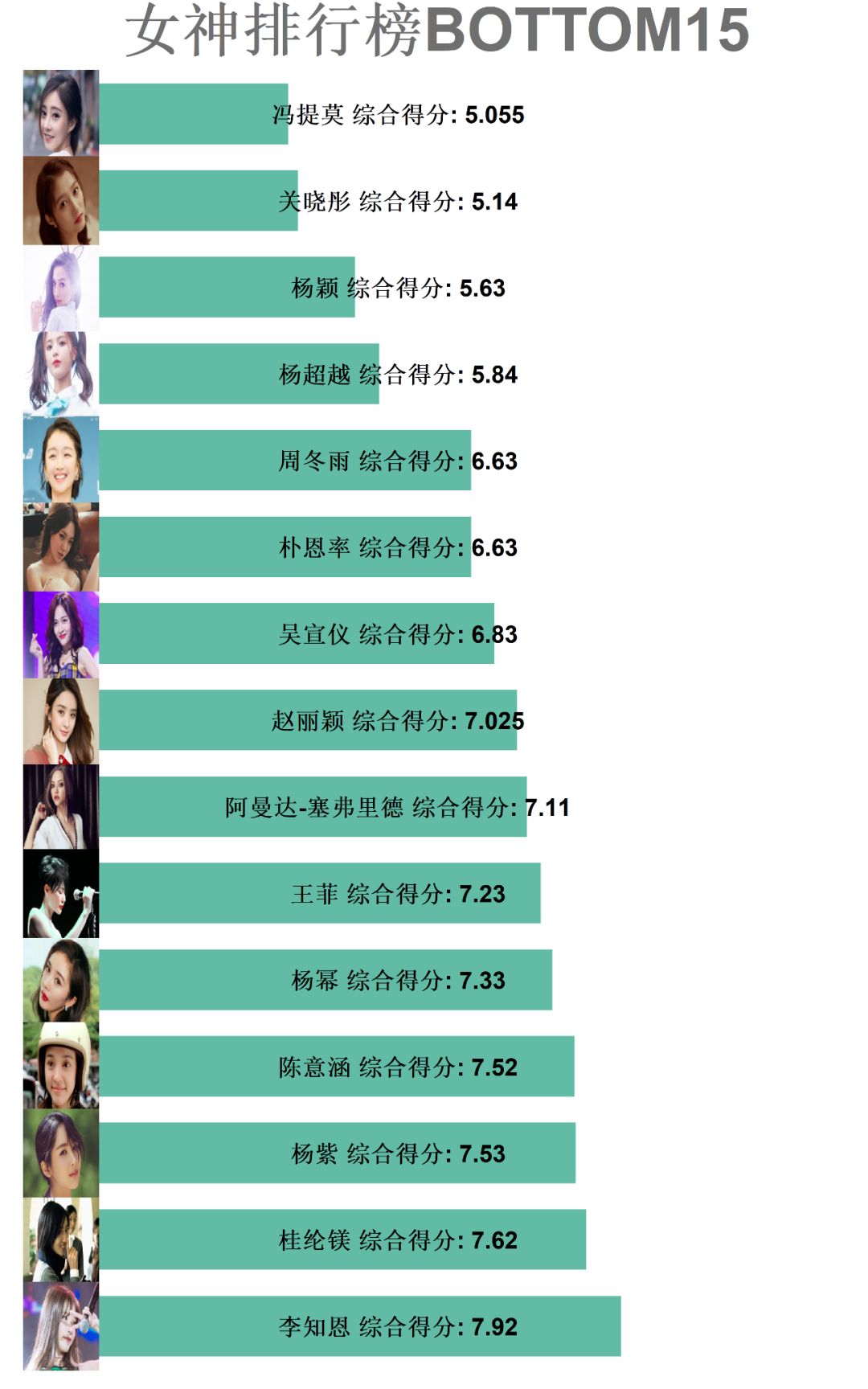
很多朋友会觉得这份榜单对于年轻女神有些苛刻,可能这也代表了广大网友对于各位年轻女神的美好期许,体现了她们未来的无限可能。
我们分区域看一下目前各个区域排名前十的名单:




看完了各个区域TOP10的名单之后,我们进行一下区域的对比:
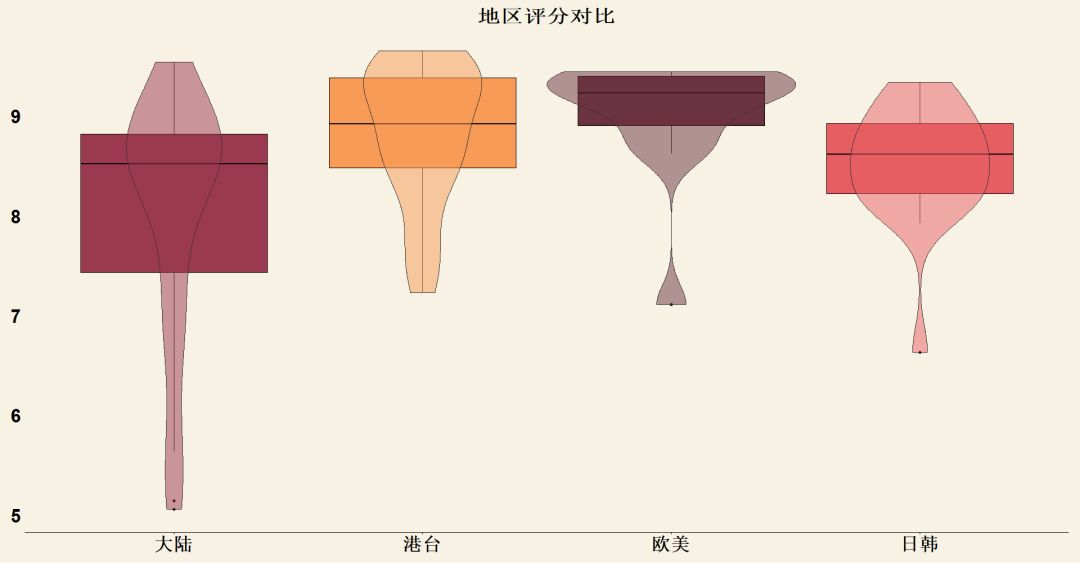
我们将小提琴图与盒形图相结合,进行区域的对比,可以看到大陆女星的评分相对偏低,一方面是由于部分女神的评分较低,拉低了整体的分值,另一方面也是由于目前出场的大陆女星年龄普遍偏小,而这一点也会在下一部分得到证实
我们看一下各个年份出生的女星总体评分情况对比,其中“60后”选项也包含了60前的女神,“90后”选项也包含了00后的女神
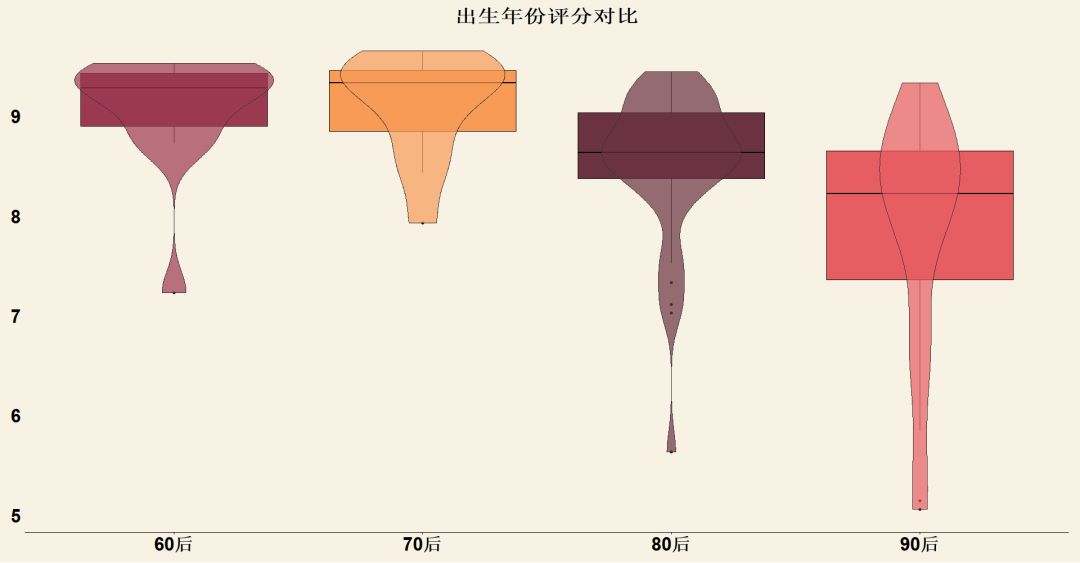
可以看到60后、70后的女神们平均分数要高于80后,而80后显著高于90后,一方面说明了大家对老牌女神们的认可,另一方面也是体现了大家对新生女神们的无限期许
我们下面将区域与年份综合起来进行对比:
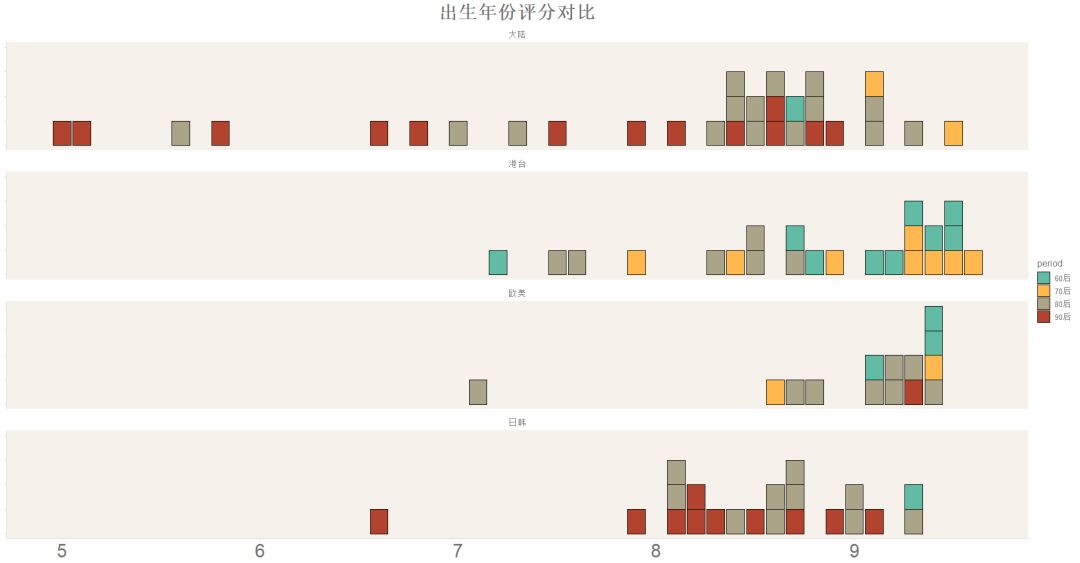
可以看到参与评分的大陆女神普遍比较年轻,这也一定程度解释了此前提到的大陆女神整体评分偏低的原因。而港台女神普遍集中在60、70后,这些女神们活跃的90年代也是香港电影、电视的黄金时期,我们也期待着香港影视未来的复苏
懂球帝目前的女神大会做到了90期,并没有十分完整地囊括广大女神,比如“四旦双冰”就都没有出现,使得这次的数据并不能完全地表述广大“钢铁直男”心中的女神标准,未来随着期数的增加,相信会有更加完善的分析
最后,小编突发奇想,想要看下在一周中不同时间出场的女神评分是否会有区别:

出乎小编意料的是,在小编一周中最开心的三天周四(即将放假),周五(迎接放假),周六(享受放假)的三天中出场的女神评分反而偏低,或许是由于数据量偏少,未来随着期数的增加,小编也会密切关注这点。
评论并转发这篇文章,获得点赞数最多的两位读者可以从下面链接中出现的书籍任选一本作为奖品: ,要求评论超过25字,并与本文相关,截止时间为12月19日21点
公众号后台回复“女神”可以获取本文代码地址
◆ ◆ ◆ ◆ ◆
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以通过扫描下方管理员二维码,让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
●
●
●
●
●
这篇关于数据解读广大“钢铁直男”眼中的女神评判标准(文末有彩蛋)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




