本文主要是介绍只会用马拉车求最长回文子串?太浪费啦!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写周赛题解有一段时间了,感觉周赛题目的类型比较分散,不利于系统的学习,所以萌生了写专题的想法。
接下来的一段时间,我会写一些常用的算法或者数据结构,希望能帮到大家。如果大家有想了解的算法,也可以在文末留言。
回文串是个什么铁憨憨
正读和反读都相同的字符序列为“回文”,如“aba”、“abba”是“回文”,“abcde”和“bba”则不是“回文”。
再比如古人秀出天际的回文诗:
莺啼岸柳弄春晴, 柳弄春晴夜月明;
明月夜晴春弄柳, 晴春弄柳岸啼莺。
判断字符串是否回文
从定义可知,一个长为 n 的字符串 S 是回文串的充要条件是,对于 i ∈ [0, n-1],都有S[i]与S[n-1-i] 相等。也就是S的前一半和后一半是"镜像"的。基于此,老铁们应该都有了O(n)的枚举解法:
bool is_palindrome(const std::string &str) {// 只枚举前一半就 OK 了for(int i = 0, n = str.size(); i < n/2; i++) {if(str[i] != str[n-i-1]) {return false; // 只要有一个位置不相等,那就肯定不是回文咯}}return true; // 所有位置都符合要求,那当然是回文咯
}
求个最长回文子串试试?
因为回文串是中心对称的,我们可以先枚举子串的中心,然后从中心处向两边探测,直到发现两端字符不相等或者到达字符串边缘。
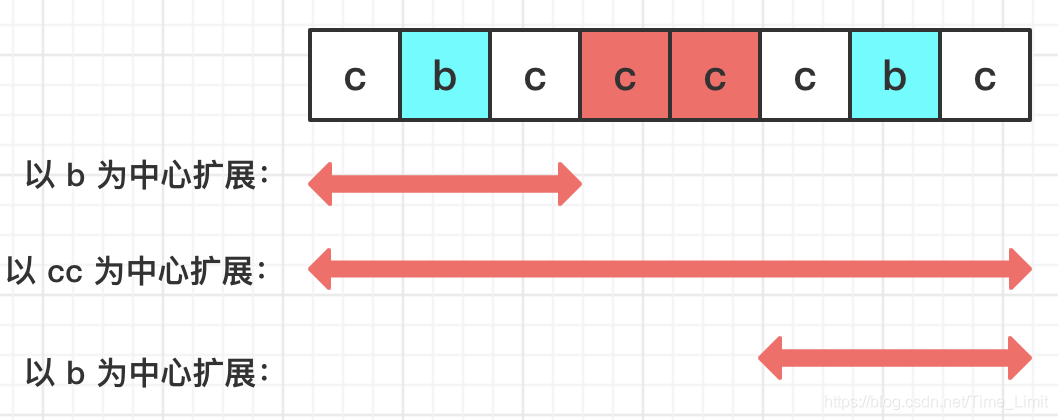
需要注意回文串的长度,如果是奇数的话,中心是一个字符,如果是偶数的话,中心是两个字符,比如上图中的"cc"就是最长字符的中心。
string longestPalindrome(string s) {int pos = 0, len = s.size() ? 1 : 0;for(int i = 0; i < s.size(); i++) {int l = i, r = i; // 以 s[i] 中心,向两边扩展while(0 <= l && r < s.size() && s[l] == s[r]) {l--;r++;}if(r-l-1 > len) {len = r-l-1;pos = l+1;}l = i, r = i+1; // 以 s[i],s[i+1] 为中心,向两边扩展while(0 <= l && r < s.size() && s[l] == s[r]) {l--;r++;}if(r-l-1 > len) {len = r-l-1;pos = l+1;}}return s.substr(pos, len);}
机智的老铁们,有没有从上图中发现一些端倪?两个 “b” 是关于 “cc” 对称的,且都包含在以"bb"为中心的回文子串中,那就意味着当已知以左"b"为中心的回文长度时,以右"b"为中心的回文长度就不用从0开始探测了。
这就是 Manacher 算法的精髓!充分利用已知的回文串,减少不必要的校验,使得时间复杂度降至O(n)!

马拉车第一步,插入占位符
选择一个原字符串中不存在的字符作为占位符,将占位符插入到原字符串的 n+1 个间隔。比如字符串"abba",变为"$a$b$b$a$"。这使得所有回文子串的长度都变成了奇数!
这可以用反证法证明一下:如果一个回文子串的长度是偶数,那么必然一端是占位符,另一端不是占位符,这与回文串的定义是矛盾的!

马拉车第二步,初始化
s :原始的字符串。
str : s 插入占位符之后得到的字符串。
L :算法过程中,已知的右端点最靠右的,回文子串的,左端点,初始为 0。
R :算法过程中,已知的右端点最靠右的,回文子串的,右端点,初始为 -1。
dp :一个数组。dp[i] 表示以 str[i] 为中心的回文子串的长度。
马拉车第三步,计算dp数组!
- 从 0 开始枚举 i :
- 如果 i 不在 [L,R] 中,dp[i] = 1。仅含一个字符的子串肯定是回文的。
- 如果 i 在 [L,R] 中,那么由对称的特性可知,dp[i] = min((R-i)*2-1, dp[L+R-i])。
- 使用中心枚举法探测更长的子串,从 dp[i] 开始探测长度。
- dp[i]确定后,若 i+dp[i]/2 > R,说明找到了右端点更靠右的子串,那么更新L,R:
- L = i - dp[i]/2
- R = i + dp[i]/2
- 遍历 dp,找到最大的 dp[i],根据 i 及 dp[i] 可以计算出 str 中最长回文子串的左右端点,然后可以计算出原始字符串 s 中最长回文子串的左右端点。
我觉得可以这样理解马拉车算法:从中心枚举法的基础上,加了一个 dp 数组,利用回文串中心对称的特性,加速了探测长度的过程。
dp 数组是如何工作的
接下来,再理解一下 dp数组是如何工作的。

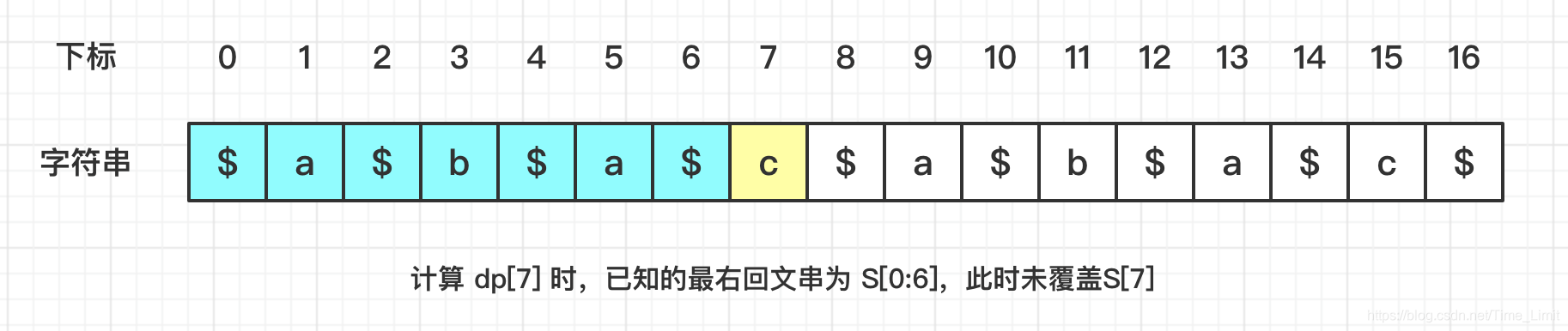
可以发现,因为整个字符串都是回文的,使得 dp 数组也是中心对称的!这也就是意味着,当求出前一半时,后一半可以直接利用中心对称的特性直接获得!回文子串对应的 dp 子数组都是中心对称的吗?很遗憾,并不是,比如下图:

图中的 S[2:8] 构成了一个回文子串,然而 dp[2:8] 子数组并不是中心对称的。
既然这样,我们在利用回文子串 S[L:R] 计算 dp[i] 时,需要注意边界问题:设 dis 为 i 到 R 的距离,i_mirror 为与 i 中心对称的下标,
- S[L:R] 得出的 dp[i] 不能超过 dis*2+1。如果超过了该值,那 dp[i] 代表的子串就超出了 S[L:R] 的范围,那 dp[i] 的有效性就无法保证了。
- 同时,由中心对称得出的 dp[i] 也不能比 dp[i_mirror] 更大。如果超过了,也无法保证 dp[i] 的有效性了。
综上所述:
- 当 i 被一个回文串S[L:R]覆盖时,可以加速 dp[i] 的探测过程:
- dp[i] = min((R-i)*2+1, dp[R+L-i])
- 当 i 没有被回文串覆盖时:
- dp[i] = 1
这也解释了,探测过程中要保存右端点最靠右的串而不是最长的回文子串的原因:因为我们是从左到右枚举的,这样可以最大程度的覆盖还没有计算的 dp,这样才能更有效的加速!
还要明白一点:上述公式只是加速了 dp 的探测,而不是直接得到最优解。所以,加速之后,我们还要继续探测。
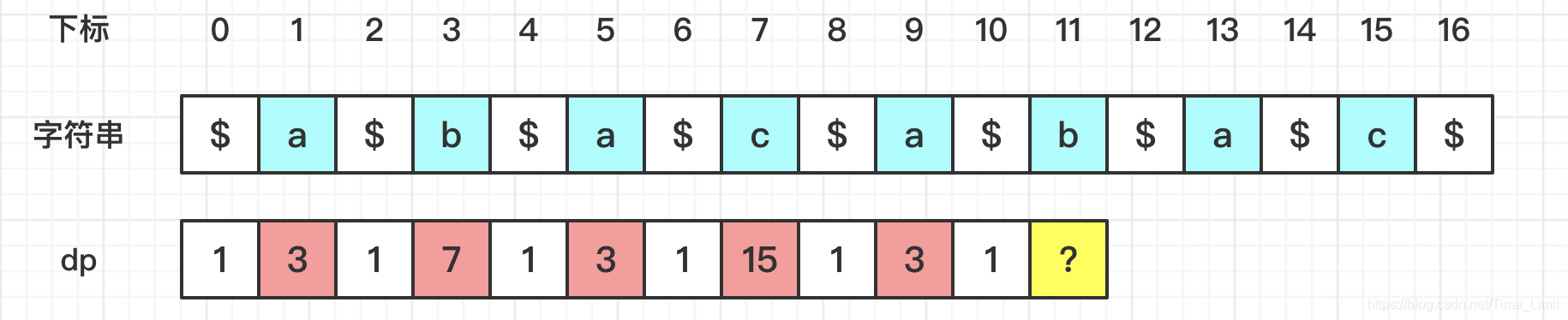
当要计算 dp[11] 时,如按中心枚举法,需从 1 开始探测。但马拉车加速后,可以直接从 7 开始:
- 已知的最右回文串为 S[0:14],则 (14-11)*2+1 = 7。
- i_mirror = R+L-i = 14+0-11 = 3,则 dp[3] = 7。
- 所以dp[11] = min(7,7) = 7。
然后继续探测,发现了以 S[11] 为中心的更长的回文子串 S[6:16],其长度为 11。
Manacher算法只是对中心枚举法的优化!!只是利用了回文串的中心对称特性!!只是加速了长度的探测过程!!

时间复杂度
接下来,尝试证明一下Manacher算法的时间复杂度。
当开始计算 dp[i] 时:
- 如果 i <= R,则可以进行加速,加速之后 dp[i] 标识的回文子串 P[i] 的右端点有两种情况:
- P[i] 的右端点等于 R。此时需要继续探测。
- P[i] 的右端点小于 R。此时不需要继续探测了,因为P[i] 完全内含在了 S[L:R] 中,不可能继续扩张了。
- 如果 R < i,则 dp[i] 要从 1 开始探测。
下列图片展示了未覆盖,内含,边界对齐三种情况:
- 未覆盖
- 内含

- 边界对齐
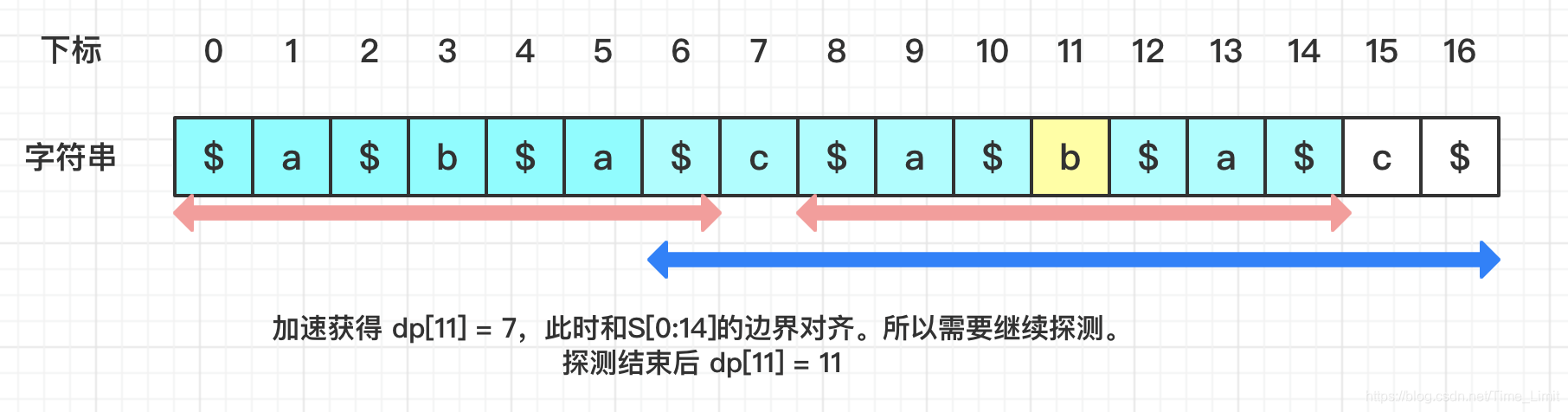
可以发现,当 dp[i] 内含于S[L:R]时,则计算过程结束,时间复杂度O(1)。
其他情况下,则需要继续探测。如果探测成功,则会更新R,这是因为只有 R 之后的字符才会被探测。如果探测失败,则计算过程结束。
也就是说,每个字符最多会被成功探测一次,每个dp[i]最多会探测失败一次。即平均每个字符最多会有一次成功探测和一次失败探测。
所以总的时间复杂度为O(n)。
每次证明时间复杂度都感觉语无伦次

压榨马拉车的剩余价值
有些题目需要频繁的判断任意子串是否是回文的。本文分享一下利用马拉车的长度数组判断任意子串是否回文的方法,时间复杂度低至 O(1) 。

先来回忆一下马拉车:
- 选择占位符,根据原始字符串 S 构造字符串 PS。
- O(n) 的计算长度数组 len。len[i] 表示 PS 中,以 PS[i]为中心的最长的回文子串的长度。
当我们要判断 S[L:R]是否为回文串时,仅需两个步骤:
- 找到 PS 中与 S[L:R] 对应的子串位置,记为 PS[L’: R’]。
- L’ = L*2+1
- R’ = R*2+1
- 判断 len[mid] 是否小于PS[L’:R’]的长度。如果小于,则S[L:R]不是回文,反之则是。
- mid = (L’ + R’) / 2

以 S[1:5] 为例,首选换算对应子串位置,得到 PS[3:11],找到PS[3:11]的中心 PS[7],通过查询长度数组 len,得知以 PS[7] 为中心的最长回文串的长度为 15。显然 PS[3:11] 及 S[1:5] 都是回文的。
偶数长度的字符串同样有效,比如 S[6:7],老铁们可自行验证~
尝试证明一下
因为 len[mid] 记录的是以 PS[mid] 为中心的最长回文子串的长度。而S[L:R] 对应的PS[L’:R’] 也是以 PS[mid] 为中心的子串。显然:
- 当 PS[L’:R’] 的长度不超过 len[i] 时,PS[L’:R’] 一定是回文串。
- 当 PS[L’:R’] 超过 len[mid],PS[L’ : R’] 一定不是回文串。
否则的话就与长度数组 len 的定义矛盾了,所以上述结论一定是成立的。
几个练习题
- 5. 最长回文子串
- 647. 回文子串
- 131. 分割回文串
- 132. 分割回文串 II
代码
class Manacher {public:Manacher(const std::string &s) {construct(s);};void getLongestPalindromeString(int &position, int &length) {// 找到最长的回文子串的位置与长度。position = -1, length = -1;for(int i = 0; i < len.size(); i++) {if(len[i] > length) {length = len[i];position = i;}}// 映射到原始字符串中的位置。position = position/2 - length/4;length = length/2;return;}// s[L:R] 是否是回文的bool isPalindrome(int L, int R) {L = L*2 + 1;R = R*2 + 1;int mid = (L+R)/2;if(0 <= mid && mid < len.size() && R-L+1 <= len[mid]) {return true;}return false;}private:vector<int> len;void construct(const std::string &s) {vector<char> vec;// 用 0 作为分隔符vec.resize(s.size()*2+1);for(int i = 0; i < s.size(); i++) {vec[i<<1|1] = s[i];}int L = 0, R = -1;len.resize(vec.size());for(int i = 0, n = vec.size(); i < n; i++) {if(i <= R) { // 被覆盖了,尝试加速len[i] = min((R-i)*2+1, len[L+R-i]);} else { // 未被覆盖,那就没办法加速了,从 1 开始。len[i] = 1;}// 尝试继续探测int l = i - len[i]/2 - 1;int r = i + len[i]/2 + 1;while(0 <= l && r < vec.size() && vec[l] == vec[r]) {--l;++r;}// 更新len[i] = r-l-1;if(r > R) {L = l+1;R = r-1;}}}
};

这篇关于只会用马拉车求最长回文子串?太浪费啦!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




