本文主要是介绍商品序列建模在新用户承接上的应用实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文是从精排链路上对新用户的助推,聚焦了跨域信息的充分利用。
背景
随着淘宝直播带货业务的发展,好玩、互动、专业有品质的购物理念刺激着人们的消费需求。当前平台内中高活用户由于经常光顾,无论是在优惠刺激下的"薅羊毛", 还是闲逛满足自己的购物需求,还是主播的粉丝受众等因素,自然而然地使他们的直播购物习惯,访问主播心智日渐成熟。每天晚高峰大量直播间开播,海量的高活用户将直播的流量抬高,驱动供给侧直播间场效及主播讲解内容得以充分分发,用户对主播,主播对用户的相互衔接match关系,成就了中高活用户的相对精准的推荐效果,然后中高活用户的点击、时长、互动率,成交转化率已经到了一定的水位,而新用户的效率较低,规模不大,相比中高活用户还有很大的提升空间,因此针对新用户承接的意义尤为重要。
业务的思考及挑战
直播推荐是一个实时性强,互动好玩,多模态跨域的场景。实时性:指推荐内容是实时讲解的主播,只有开播的直播间才能进入推荐内容池。不像静态的商品或资讯类一旦上架,就可以反复推荐。当用户到访即便"猜准"了用户的偏好,但是跟用户兴趣相关的主播没有开播,没法儿推荐他喜欢的,但是还必须对用户有内容呈现,此时的结果可能不是很感兴趣,因而可能会损伤用户体验;互动好玩:可以与推荐曝光的主播通过“一问一答”评论,刷礼物,点赞,关注、分享等方式进行互动,通常互动,直播间的主播会马上回应你,感觉好玩。多模态跨域:指内容侧包括了直播card的封面图片、card的文本title、主播讲解的音频asr、主播颜值,售卖的货品、甚至直播间的背景音乐等信息,是一个综合类的多域信息,对其理解有一定的挑战。比如在直播间跳动的封面图上看到了自己曾经点击感兴趣的商品,“满1000元抽天猫投影仪”,粗看是跟投影仪有关,但是进去之后发现主播是在卖化妆品,这样体验也不好。推荐内容理解准确才可能更精准的推荐。跨域行为的建模,内容侧是主播,而行为中有用户的商品序列,如何把跨域的行为与推荐内容的主播有效适配也是很关键的。淘宝进来的用户购物心智很强,不像快手抖音以娱乐内容消费为主导,跟传统的ctr模型不同在于要解决好跨域信息的打通,如何建模使得商品和主播的sideinfo没有对齐的情况下更“默契”的融合,对促点击成交效率和扩销量规模起着更重要的作用。
在这样的业务特色下重新审视新用户,新用户在效果提升上虽有空间但是问题和挑战很大。天然上具有数量少,稀疏性,随机性的特点。大数据的思想:有海量数据才具备建模学习中间规律和知识的可能,越有规律模型越容易收敛。如果数据少、任意发散、没有规律性,模型是很难学习表达充分的。当前学术界也对冷启(冷启用户,冷启物品)问题进行了各种探索实践,结合淘宝内的各个直播场景看新用户的问题。
▐ 新用户对直播间访问心智不健全
直播广场频道页是通过淘宝首页直播宫格引导二次流转进入,能进二跳的中高活用户居多,新用户大部分止步于首页。
原因一从复登率来看,频道页高活用户复登率最高,中活用户复登率次之,而新用户的复登率最低,新用户对直播的访问粘性是远低于中高活用户,这样直接导致新用户在直播域的访问稀疏,因此新用户在直播间的到访很难表达。
原因二是受高活用户热门主播品类的影响。目前的模型中样本点击分布以中高活用户为主导,在货场方面个别品类出现的太多,并且大量的出现在page1,position的靠前的会比后面的ctr高,久而久之样本就会有一定的bias,点击的未必就是他感兴趣的。
▐ 需要专门提升新用户的体验
要想服务好新用户,首先要认识清楚什么是新用户,这样有助于新用户效率体验方面的提升。我们之前更多是从全体用户出发,用一套体系和运营标准来建模提效,通过多目标,分时间段等方式带动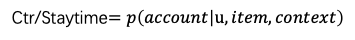 最大化。这些对高活用户很友好,新用户和高活用户的活跃程度不同,放之四海皆准的大一统视角很难服务好新用户,需要从新用户本身的特点出发,如:新用户的拉新拉活(如红包优惠),主播侧内容质量(即用优质热门的内容来吸引新用户)等手段提升新用户的体验。
最大化。这些对高活用户很友好,新用户和高活用户的活跃程度不同,放之四海皆准的大一统视角很难服务好新用户,需要从新用户本身的特点出发,如:新用户的拉新拉活(如红包优惠),主播侧内容质量(即用优质热门的内容来吸引新用户)等手段提升新用户的体验。
▐ 借助跨域知识在新用户上不充分
新用户虽然复登率低不够活跃,但是仍然有一些和其他用户共同的需求,比如秋天换季的时候,一些新用户也具有“皮肤干”需要补水保湿需求,天气转凉需要一些季节性明显的商品需求,将这些需求抽象成边,将新用户和直播间抽象成节点,形成特定的知识图谱,来提升新用户的体验和转化。
▐ 对直播间实时讲解商品信息获取不足
如前所述,直播推荐内容侧涉及的参与方众多:包含主播,直播间售卖的商品,直播卡片封面图及文本描述信息,主播讲解语音,还有video是一个多模态的载体。直播推荐跟传统的商品、资讯类推荐很不一样,商品和资讯是“死的”东西,一旦上架或生产出来就不会变化,对其理解和刻画相对容易,并且在内容池可以多次推荐。比如对螺狮粉感兴趣的人任何时候到访,螺狮粉的商品是始终可以推荐给他。而直播推荐的内容载体是活生生的人和商品,对欧莱雅感兴趣的人到访,如果欧莱雅的直播间不开播也无法推荐,需要的是一种订阅的模式,用户和感兴趣的主播达成某种契约-”我开播了你再来”,更重要的是直播间售卖商品也是变化的,因为一个直播间会卖很多商品,一段时间卖A商品,另一段时间卖B商品,捕捉也有一定难度。当用户来的时候,如果刚好播到这个用户感兴趣的商品,那这个转化效率会大大提高。因此抓住当前直播间主播正在讲解的商品及类目信息,对新用户承接甚至整体推荐效果有很大帮助。
历史的回顾
在解决冷启问题上已有的方法归纳为三类:第一类充分利用跨域的信息,把新用户或冷启物品其他领域内的信息充分挖掘迁移打通到待推荐的内容领域;第二类探索方法。在广告领域你可能会听到一个叫做“一键起量”的名词。即新用户或新物品到来的时候,先给他一定的流量进行探索,然后逐步感知真实的分布;第三类是建模的思路。如通过DropoutNet来缓解对冷启ID embedding的依赖,更多通过其内容属性来进行推荐,如Meta Warm Up Framework(MWUF)通过拉伸函数将冷启ID embedding与非冷启动ID embedding空间打通,实现了“冷热转换”,用热的带动冷的学习。还有利用Meta learning的思想对冷启ID结合其他信息生成一个embedding,模拟冷启动的过程,不过meta learning的相关研究在ICLR2021的统计中发现热度下跌。本文结合淘宝直播场景下新用户的问题,首先采用第一类方法进行实践。在样本中发现新用户的很多特征都是空的,那么通过跨域信息弥补新用户的特征是更容易拿到业务收益的方法。
基于前面的分析再次聚焦在用户的商品行为上,因为淘宝是一个超级的商品货场,用户有着丰富的商品访问,发掘发现用户的商品购物需求对直播推荐的效率有正相关性。同时序列特征能够通过某种方式的实现聚合能比单点特征具备更丰富的信息,并且有很好的个性化,力量更强大。淘宝直播推荐场景下,用户访问的商品心智较强,不像短视频平台用户为了消费时间,泛娱乐的目的更多。对新用户来讲,其直播的访问非常稀疏,一个月内主播的访问行为,但是其点击商品丰富,还有一个原因是放长历史宽度我们更能发现一些周期性的规律,更能发现他的真实兴趣偏好,短期一两次可能是随机行为,但是历史上的多次那可能就是重度爱好者,对发现真实兴趣至关重要。因此做好新用户在商品域的特征和建模对其在淘宝内直播的场景下的推荐是有重要意义的。再次回顾序列转录的发展,从RNN,LSTM,TextCNN,ELMO再到Transformer注意力领域的Bert,XLnet,DIN,DIEN,SIM,都是对序列的建模。其中SIM以工程的手法提效算法,通过类目检索的方式将life-long的商品行为中提取信息。然而SIM的life-long需要耗费大量的存储计算资源。如存储用户1000个商品长度的序列,每天要耗费几十T的内存资源,同时在超长的商品序列上做target attention计算耗时,除非团队有丰厚的存储计算预算才能在线使用,并且SIM更关注与目标的相关性,他其实做了前提假设,序列就是用户的历史兴趣,可实际中并非完全是,里面会含有不少的噪音,缺乏用户的兴趣性(就是从用户历史里发现了跟当前目标相关的信息,但他不一定是用户真正感兴趣的,就是曝光出来,用户也不点很快溜走,这种现象大量存在,比如点击了月饼,出现了大量的月饼,这样的体验也未必最佳),需要强化对用户兴趣的表达,不仅跟目标相关并且用户感兴趣从这个方向入手构建网络,也有缺乏发现性的问题,总是从历史出发来看当前目标的因果推理,没有从未来看现在。针对这些问题提出了多通道lifelong的商品序列网络的构建,旨在相关性的基础上兼顾用户的兴趣信号。
多通道lifeelong商品序列网络构建
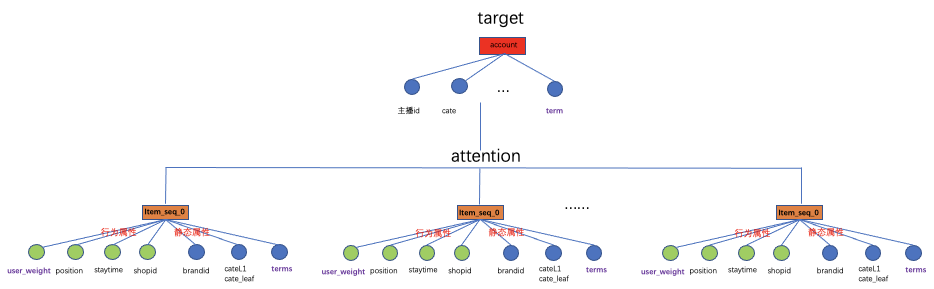
▐ 长商品序列sideinfo的重新定义
如下所示:对于用户的商品行为序列中每个元素的sideinfo从以下方面进行设计,总体分为用户对商品的行为属性和商品本身的静态属性。user_weight表示用户对商品、用户对类目的显式兴趣表达:即通过对访问次数、时长、访问时间归因折算出一个兴趣权重。user_weight如何有效使用也是值得思考的一个问题,首先是将其直接应用到模型网络里以超参的形式存在,那么会有一个风险,网络输出来的logits和这种离线硬算方式的权重大小不在一个空间,有可能发挥不出作用;其次是将这个dense值映射到网络里做成可训练的方式利用,可以hashbucket到固定的分桶,也可以AutoDis的方式。
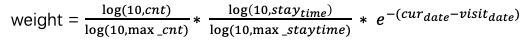
position表示按用户点击的时间从大到小排序,最近访问的在前面,含义:如果用户最近的商品行为对点击主播有帮助则positon靠前的权重会学得大,反之亦然,通过position来刻画用户商品行为的周期变化。staytime对商品的访问时长:对于商品的场景如果用户下过单的商品可能最近一段时间不会感兴趣,那么staytime越大反倒会拉低重要程度。shopid即店铺的信息,brandid是品牌,cate类目一级和叶子类目以及商品的title的term,分别是从不同程度对商品的文本描述。term是更细粒度的刻画。作为导火线的target 主播,其sideinfo除了之前的信息外,加入了直播间的商品term。加入商品的itemid会使模型变大,暂时不加商品id。
▐ 第一版:以时长过滤的商品序列
拉长用户最近一年或更长周期的商品序列,以userid和itemid为key进行聚合(频次,累加st,max(visit_time))按时长设定一定的阈值过滤得到用户的商品序列。这是用纯商品来刻画的用户行为序列,虽然精准,但是截断长度后,难免会损失信息,无法拿到相对完整的商品序列,如果全部保留需要耗费大量的存储资源,另外资源运算rt和存储预算都很难支持,同时给后续的模型迭代带来不变。
▐ 第二版:用户多类目采样的商品序列
为了既精准刻画用户的真实感兴趣的商品行为,同时又尽可能多的拿到全量的用户商品行为,并且在已有的资源条件下完成。因此采用近似逼近的方式,(微积分的思想就是以直代曲,近似,求和,取极限)。近期的商品行为能反映用户最近的需求,对实时场景的直播推荐场景更重要,因此最近的若干个商品全部保留,后面的引入类目采样,把用户所有的商品以一级类目建立索引,在每个类目下按权重,频次,时间取最大的top3商品,因为一级类目有几百个,这样最大的商品序列上限为几百个。以target来回望历史,目标是找到跟target相关的,第一眼望去是类目泛搜索一下,能够匹配了,再看第二眼更细粒度的商品,而此种方法,保留了用户的所有类目,商品进行了类目下的采样,这样就保证了在有限的长度下,拿到了尽可能多的用户商品信息,不失太多精度。在短实时的商品集合外,扩展了target的命中范围。
▐ 数据case分析
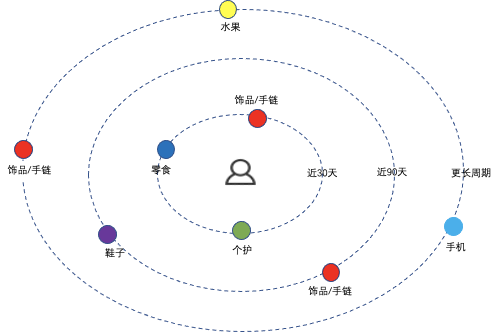
以某个序列为例:某个用户最近30天访问了零食、个护、饰品/手链,再最近90天访问过鞋子、饰品/手链,在更长的周期内也访问了手机、水果、饰品/手链。将时间维度拉长后,更容易找到一些周期性的规律,发现用户真正感兴趣的。能看出对饰品/手链有偏好。
假定一个饰品/手链的主播来了,前50个里出现了一个,拉长时间,发现该用户的后面有多个,因此会对饰品/手链起到更强的辅助作用。
▐ 模型结构
模型的整体结构如下所示。红框里的模块就是多通道提取的Life-long商品序列网络结构。(1) 特征上依然是推荐的经典配置用户column,itemcolumn,上下文ui column,以及主播序列,图转换序列,跨域的商品序列。序列的融合方式采用DIN的target attention聚合生成融合embedding;(2) MLP分为Main net和bias net,Main Net建模打分的主要信息,Bias Net建模用户的bias,特别是直播的场景下,训练样本里带有很多用户的bias信息,某个用户对个别主播特别感兴趣,那曝光点击就会有所倾向,为了生态更加繁荣,保证公平性,加入Bias Net把用户的倾向性刻画出来。在线上serving的时候根据需要,决定是否使用biasNet,对于低活新用户访问频次比较低,对直播间没啥感觉,他可能没什么bias偏向,高活用户的bias更明显一些;(3)最上层是logit layer学习LTR。
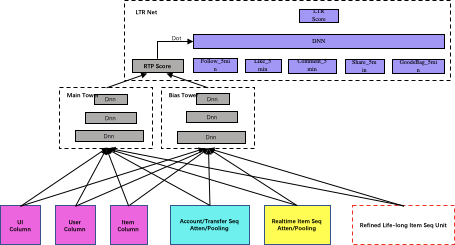
多通道提取的Life-long商品序列网络结构如下所示,思想其实很简单。传统的sim模型是通过target的类目从lifelong的商品序列里检索出一个相关性序列,并且匹配方式是一种不同类目的硬检索方式,有就是有,没有就是没有,如果当前target是酒水,而用户序列里含有茶叶或咖啡,通过硬检索的方式两者很难相关,从泛化意义上来看茶叶咖啡,还有酒水都是喝的,具有一定的相关性,这种情况会有很多类似的case。其实现过程是在abfs表回调检索类sql逻辑的接口实现,然后送入模型图里做attention或pooling聚合。该过程需要实现约定好数据格式,严格按照建好的schema,多团队协作构建,并且检索效率发生在rtp解析数据里。
我的做法是将检索过程以矩阵运算的方式在模型图里完成,rtp只要解析出原始的lifelong序列和target的类目,送入模型里就可以通过矩阵检索的方式完成。这种方式:一是可以更加灵活的控制检索逻辑,如:是否开启检索,检索使用什么样的query,检索后返回的个数等信息都可以在训练配置文件简单配置便可以实现;二是能够更灵活的扩展,除了一般的硬匹配方式外,可以实现embedding去检索,因为不同类目的embedding已经在模型的user侧或content侧使用,可以轻松的把这个embedding拿来进行泛化检索,并且embedding和序列的embedding还是在一个模型里端到端的方式更新,保证了一致性;三是提升打分效率,降低线上rt。
为了从原始序列中提取出既和target相关,同时又是用户感兴趣的信息。构建了5个维度的序列提取通道。其中通道1、2、3、5是候选target的相关性通道:即通过target的不同维度的信息来提取序列里跟他相关的元素。通道4是用户相关性的兴趣通道,主要提取跟user更match的元素序列。因为在用户的原始数据中会有噪音,虽然是用户交互过的物品,不能保证就是用户真实的兴趣,通道4就是通过建模清洗过滤出跟用户更靠近的序列信息。
提出原理过程如下:经过三步,输入一个原始的序列[batch,N1,dim]和一个激活因子,最后返回一个提取后的序列[batch,N2,dim],其中N2 < N1。第一步:计算激活因子下序列里每个元素的概率,如果激活因子是各类目的Id,e_i表示序列里第i个元素,计算e_i的sideinfo里是否包含activeFactor,包含为1, 不包含为0;如果激活因子activeFactor是embedding向量,计算向量e_i和向量activeFactor的cosin相似度作为概率;第二步:对整个序列会计算出N1个概率值,按大到小取出top N2个元素对应的索引;第三步:根据索引Indices集合,从序列里取出对应的元素重组出一个“子序列”(不一定连续),“子序列”各个sideinfo保持不变。

下图的网络结构中最左侧通道1是通过主播的离线统计top类目对life-long seq进行挑选,这里可做主播不同级类目(即按叶子类目,一级类目进行检索),也可以将主播的类目按一定的策略机制或NLP技术(词向量,tf*idf, topic相关等)进行扩展,扩展出最相关的top1类目,top2类目,top20类目进行检索。尝试使用一级类目扩展出top5在采样后的300长度序列上检索后提取的序列长度如下。检索后,为了保持信息的对齐,做target的离线信息的attention(因为直播场景下target还是实时信息),实现通道1检索提取序列的聚合。
右侧的四个通道可以认为是一种soft match的方式。因为输入的特征共享了embedding layer,在同一个端到端的空间内,是可以利用向量内积的形式检索提取,默认设定的每个通道检索选出20个长度的序列。通道2使用的是主播实时上架商品的类目的embedding,对序列中每个元素的embedding计算内积,取内积权重最大的top20对应的元素组成提取后的序列,与attention和gate门控聚合方式不同的是:直接将top相关的信息单独拿出来,舍弃掉了其他信息,而attention、gate、包括胶囊网络在内都是计算出了一个重要权重,"水分"的权重会小但是加权和以后水分信息还会在里面,以LSTM的四个gate为例,历史的长期信息会经过忘记门,结合当前的输入提取出有效信息存入Cell中,但是没有把无效信息的完全去掉,只是乘以了一个门控权重。按此检索提取,通道3和通道5是通过主播的离线/实时的信息的embedding进行检索。通道4是用户表征的embedding的检索,即在兴趣的维度上来看历史的序列到底哪些更感兴趣。通道2345提取出来的序列组成一个新的序列,在这个序列上做target实时信息的attention。实时信息更能描述当前直播间的状态。
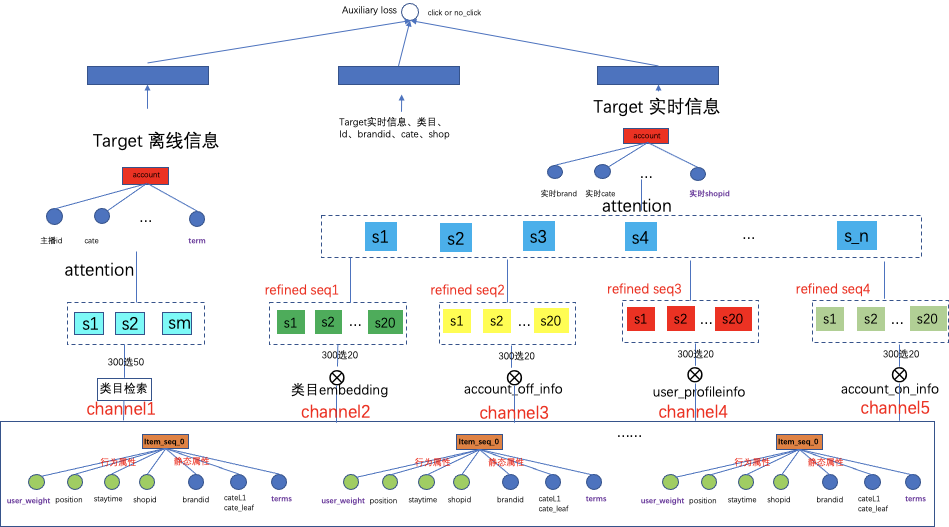
此外,引入辅助loss来校准从用户的长周期商品序列里抽取出的用户兴趣表达。将类目检索后的序列经过离线target attention聚合后形成的向量,与经过主播侧信息,用户侧信息embedding检索后序列,经过主播实时信息作为query进行target attention聚合后的向量concat,同时拼接target的实时信息,类目,brand,shop,cate等构建二分类辅助loss:辅助loss基于用户的历史行为,来推导用户对当前候选主播点击或不点击。与maintower的主loss不同点在于,mainet里融合了主播侧更多的信息,在辅助loss的网络里只挑选了主播的id,类目,brand,shop,主播实时讲解top3商品的相关信息进行校准。其实复用了点击信息来监督用户历史兴趣的抽取,更复杂的loss后期探讨。辅助loss和主loss分开交替更新。
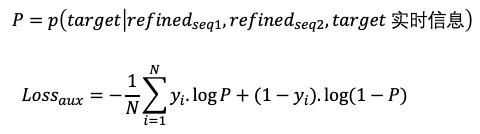
碰到的问题及解决
▐ 训练上的优化:正则化方法
为了让新加入这部分多通道life-long seq 提取unit的网络结构快速收敛。在训练方式上加入了一种正则化的方法。实时商品序的target attention的Q,K,V矩阵在之前的base模型中都已经预训练过,我们主ctr模型中权重的初始化都置0,训练过程通过逐渐积累梯度来作为参数的权重,为了加快在已有训练的网络里新加的sub网络,我利用已经训练好的参数去初始化新加序列target attention权重,将实时商品序列的target attention的Q,K, V作为life-long商品序列target attention中的Q,K,V矩阵的初始化。训练过程发现,很少的训练步数就能把totalauc拉到一定的高度。查阅相关资料发现Lee et al., 2020年发表的论文中提出的方法叫Mixout正则化方法,也是类似的trick,他们利用pretrained weights来随机替换参数。
▐ 网络结构的优化
随着通道数的增加,提取合并后的序列逐渐变长,做softmax计算attention权重的时候,会使得概率变小。因为长度越大softmax的分母也会越大。这样会拉低整体的概率,使得重要的变得没那么重要了。为了解决此问题,从底层矩阵运算角度对多通道提取出的序列行进行优化。具体做法:将提纯汇总的序列,正常做target attention得出attention的权重向量,与之前在全序列上做softmax不同的是,对权重向量按不同的通道拆解形成不同序列的权重向量,进行局部单元上(每个检索通道后的小序列)做softmax。这样target,一次激活attention权重运算,完成多个序列的attention平滑,多个序列的信息并没有丢失。我把这部分成为“单激活多兴趣网络”。也许你说干脆把每个通道提取的序列各自做各自的target attention互不影响,这样是可以的,但是模型的参数网络会复杂,在实际发现每新加一个序列做target attention线上rt会增加5-6ms。rt的增加会引发超时率,失败率,流控率上升等一系列问题,因此需要以一种更加“绿色节能”的方式来做。
之前的方式:
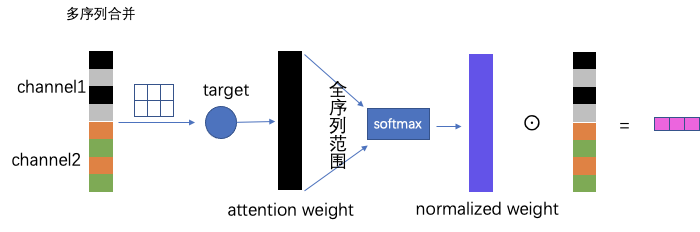
改进后的方式:
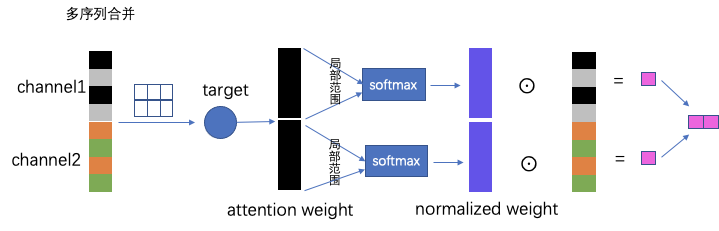
上线后的效果
▐ 模型效果的验证
固定一条带预测的样本,分别在base模型、多通道检索提取和多维检索提取&辅助loss模型上进行打分验证。该条样本待打分的account的item_terms是"多肉,美诺,植物,绿植,梦露,萌肉,桃蛋,奶酪,yns,bjt",说明是一个卖多肉的主播;某包含多个"多肉,植物"的lifelong序列,模型对该序列与该account的rtpScore如下:
样本id | 模型 | rtpScore | |
实验1 | aaaaa12454570888 | 多维检索提取&辅助loss | 0.824909 |
实验2 | aaaaa12454570888 | 多通道检索提取 | 0.72 |
base | aaaaa12454570888 | 目前base模型 | 0.64744 |
说明通过多通道提取Lifelong商品序列模型打分比base模型更高,起到了加强的作用。有助于把用户真正感兴趣和与target的相关性显现出来。
▐ 上线效果
在淘宝直播频道页场景下,整体新用户上一跳曝光uv、 pv 及曝光pctr上涨明显,二跳人均点击总时长、次日复登率等均有较大幅度提升。
分人群用户上:低活用户、回流用户pctr上升显著,二跳点赞、评论、分享、关注pctr提升明显;零活用户除一跳指标提升外, 点击pv成交转化率也有了大幅提升。
在生态上:曝光发现性和点击发现性均增加,同时曝光主播数量上升,对头部集中度有一定的降低,生态良好。该模型整体对新用户起到了明显拉动作用,在新用户占比多的场景效果估计会更明显。
后续规划
首先是跨场景的应用,将该技术同步向直播的其他场景推进,如首页商品和直播卡片混排场景,直播上下滑等场景进行迁移;其次在该框架下,可以扩展提取的通道,比如多样性的通道,发现性通道,新颖性通道都是可以快速方便加入。每个通道聚焦自己的提取信息;第三在辅助loss的设计上还可以优化,抽象出来看多通道提取是将用户原始的显性表达,转录到另一个空间,生成了用户的另一个贴近打分target的表达,可以利用GAN生成对抗的方式,让这个生成的表达更强。其实每个通道也可以看成是不同的task,借助feature info metric的手段发现哪些通道对target更加有效,进而重点从梯度回传的角度对通道有所侧重的提取和优化。
从冷启问题全局上看,本文是从精排链路上对新用户的助推,聚焦了跨域信息的充分利用,后续也可以从召回,重排,全链路上打通新用户的通道,结合一些探索策略进行协同拉升。
团队介绍
淘宝直播算法团队以解决业务问题为导向,驱动技术创新,旨在打造业内领先的推荐模型,不断拓展电商新生态,为消费者带来有趣好玩、品质专业、物美价廉的新消费体验。承担了c端用户、主播、商家、货品交织的精准内容分发、流量转化等角色,带动供给侧主播的跃迁率、开播率以及用户侧点击、停留时长、互动、成交等指标上涨。涉及到了召回、粗排、精排LTR、重排、odl等推荐的传统技术方向,并且具有实时性,多模态,变化性等鲜明的业务特色。团队先后在特征重要性、异构序列融合、多目标等多个技术点上取得一定的成果,但面临的业务挑战和问题依然很大,希望能与业内同行保持交流,一起学习成长!
✿ 拓展阅读

作者|北极
编辑|橙子君


这篇关于商品序列建模在新用户承接上的应用实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



