本文主要是介绍TiKV 源码阅读三部曲(一)重要模块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者简介:谭新宇,清华大学软件学院研三在读,Apache IoTDB committer,Talent Plan Community mentor。
TiKV 是一个支持事务的分布式 Key-Value 数据库,目前已经是 CNCF 基金会 的顶级项目。
作为一个新同学,需要一定的前期准备才能够有能力参与 TiKV 社区的代码开发,包括但不限于学习 Rust 语言,理解 TiKV 的原理和在前两者的基础上了解熟悉 TiKV 的源码。
TiKV 官方源码解析文档 详细地介绍了 TiKV 3.x 版本重要模块的设计要点,主要流程和相应代码片段,是学习 TiKV 源码必读的学习资料。当前 TiKV 已经迭代到了 6.x 版本,不仅引入了很多新的功能和优化,而且对源码也进行了多次重构,因而一些官方源码解析文档中的代码片段已经不复存在,这使得读者在阅读源码解析文档时无法对照最新源码加深理解;此外尽管 TiKV 官方源码解析文档系统地介绍了若干重要模块的工作,但并没有将读写流程全链路串起来去介绍经过的模块和对应的代码片段,实际上尽快地熟悉读写流程全链路会更利于新同学从全局角度理解代码。
基于以上存在的问题,笔者将基于 6.1 版本的源码撰写三篇博客,分别介绍以下三个方面:
- TiKV 源码阅读三部曲(一)重要模块:TiKV 的基本概念,TiKV 读写路径上的三个重要模块(KVService,Storage,RaftStore)和断点调试 TiKV 学习源码的方案
- TiKV 源码阅读三部曲(二)读流程:TiKV 中一条读请求的全链路流程
- TiKV 源码阅读三部曲(三)写流程:TiKV 中一条写请求的全链路流程
希望此三篇博客能够帮助对 TiKV 开发感兴趣的新同学尽快了解 TiKV 的 codebase。
本文为第一篇博客,将主要介绍 TiKV 的基本概念,TiKV 读写路径上的三个重要模块(KVService,Storage,RaftStore)和断点调试 TiKV 学习源码的方案。
基本概念
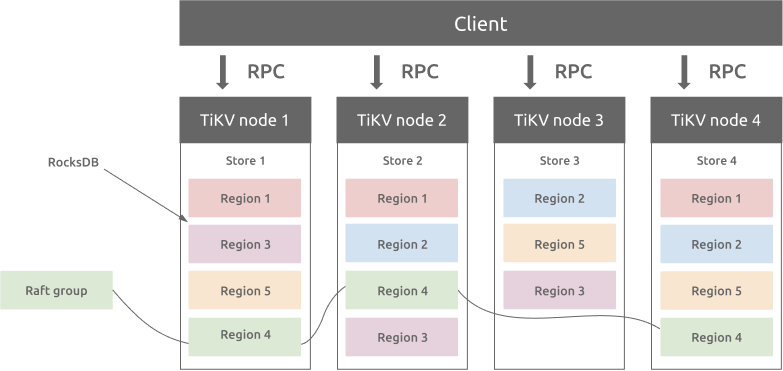
TiKV 的架构简介可以查看 官方文档。总体来看,TiKV 是一个通过 Multi-Raft 实现的分布式 KV 数据库。
TiKV 的每个进程拥有一个 store,store 中拥有若干 region。每个 region 是一个 raft 组,会存在于副本数个 store 上管理一段 KV 区间的数据。
重要模块
KVService
TiKV 的 Service 层代码位于 src/server 文件夹下,其职责包括提供 RPC 服务、将 store id 解析成地址、TiKV 之间的相互通信等。有关 Service 层的概念解析可以查看阅读 TiKV 源码解析系列文章(九)Service 层处理流程解析。
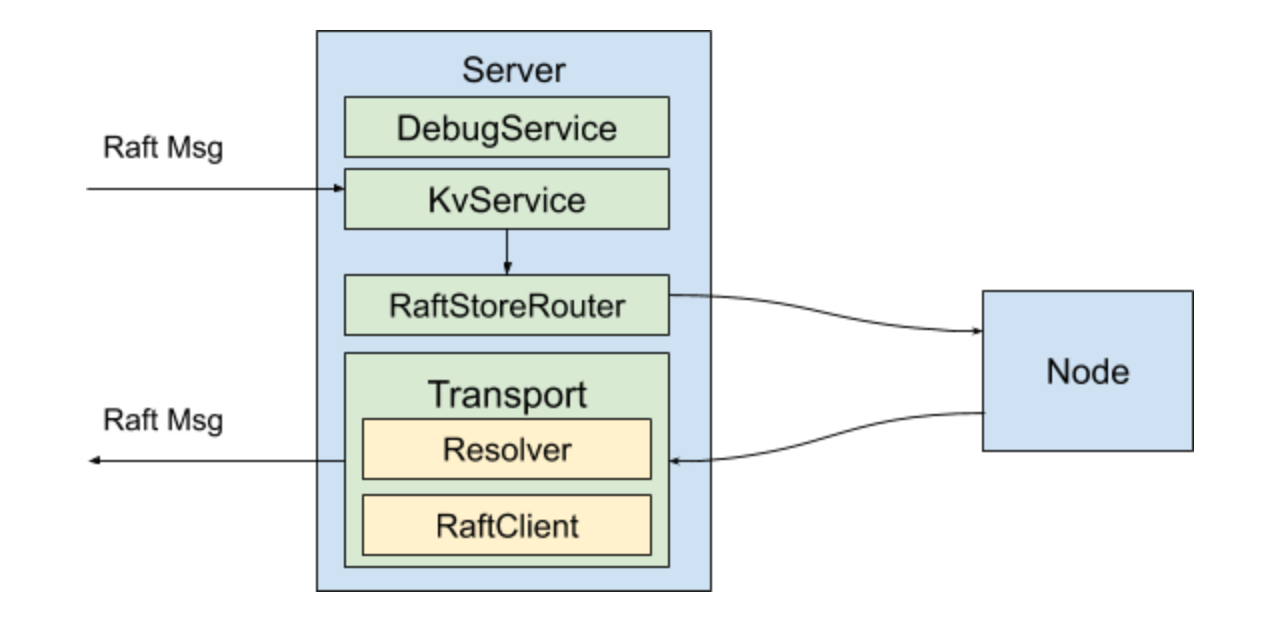
TiKV 包含多个 gRPC service。其中最重要的一个是 KVService,位于 src/server/service/kv.rs 文件中。
KVService 定义了 TiKV 的 kv_get,kv_scan,kv_prewrite,kv_commit 等事务操作 API,用于执行 TiDB 下推下来的复杂查询和计算的 coprocessor API,以及 raw_get,raw_put 等 Raw KV API。batch_commands 接口则是用于将上述的接口 batch 起来,以优化高吞吐量的场景。另外,TiKV 的 Raft group 各成员之间通信用到的 raft 和 batch_raft 接口也是在这里提供的。
本小节将简单介绍 KVService 及其启动流程,并顺带介绍 TiKV 若干重要结构的初始化流程。
cmd/tikv-server/main.rs 是 TiKV 进程启动的入口,其主要做了以下两个工作:
- 解析配置参数
- 使用
server::server::run_tikv(config)启动 tikv 进程
fn main() {let build_timestamp = option_env!("TIKV_BUILD_TIME");let version_info = tikv::tikv_version_info(build_timestamp);// config parsing// ...// config parsingserver::server::run_tikv(config);
}
对于 components/server/src/server.rs 的 run-tikv 函数,其会调用 run_impl 函数并根据配置参数来启动对应的 KV 引擎。
在 run_impl 函数中,首先会调用 TikvServer::<CER>::init::<F>(config) 函数做若干重要结构的初始化,包含但不限于 batch_system, concurrency_manager, background_worker, quota_limiter 等等,接着在 tikv.init_servers::<F>() 里将 RPC handler 与 KVService 绑定起来,最后在 tikv.run_server(server_config) 中便会使用 TiKV 源码解析系列文章(七)gRPC Server 的初始化和启动流程 中介绍的 grpc server 绑定对应的端口并开始监听连接了。
/// Run a TiKV server. Returns when the server is shutdown by the user, in which
/// case the server will be properly stopped.
pub fn run_tikv(config: TikvConfig) {...// Do some prepare works before start.pre_start();let _m = Monitor::default();dispatch_api_version!(config.storage.api_version(), {if !config.raft_engine.enable {run_impl::<RocksEngine, API>(config)} else {run_impl::<RaftLogEngine, API>(config)}})
}#[inline]
fn run_impl<CER: ConfiguredRaftEngine, F: KvFormat>(config: TikvConfig) {let mut tikv = TikvServer::<CER>::init::<F>(config);...let server_config = tikv.init_servers::<F>();...tikv.run_server(server_config);signal_handler::wait_for_signal(Some(tikv.engines.take().unwrap().engines));tikv.stop();
}fn run_server(&mut self, server_config: Arc<VersionTrack<ServerConfig>>) {let server = self.servers.as_mut().unwrap();server.server.build_and_bind().unwrap_or_else(|e| fatal!("failed to build server: {}", e));server.server.start(server_config, self.security_mgr.clone()).unwrap_or_else(|e| fatal!("failed to start server: {}", e));
}
KVService 服务启动后,所有发往监听端口的请求便会路由到 KVService 对应的 handler 上。有关 KVService 目前支持的接口,可以直接查看 kvproto 对应的 service Tikv,目前的 RPC 接口已经接近 60 个,每个接口在代码中都会对应一个 handler。
// Key/value store API for TiKV.
service Tikv {// Commands using a transactional interface.rpc KvGet(kvrpcpb.GetRequest) returns (kvrpcpb.GetResponse) {}rpc KvScan(kvrpcpb.ScanRequest) returns (kvrpcpb.ScanResponse) {}rpc KvPrewrite(kvrpcpb.PrewriteRequest) returns (kvrpcpb.PrewriteResponse) {}rpc KvPessimisticLock(kvrpcpb.PessimisticLockRequest) returns (kvrpcpb.PessimisticLockResponse) {}rpc KVPessimisticRollback(kvrpcpb.PessimisticRollbackRequest) returns (kvrpcpb.PessimisticRollbackResponse) {}...
}
当 KVService 收到请求之后,会根据请求的类型把这些请求转发到不同的模块进行处理。对于从 TiDB 下推的读请求,比如 sum,avg 操作,会转发到 Coprocessor 模块进行处理,对于 KV 请求会直接转发到 Storage 模块进行处理。
KV 操作根据功能可以被划分为 Raw KV 操作以及 Txn KV 操作两大类。Raw KV 操作包括 raw put、raw get、raw delete、raw batch get、raw batch put、raw batch delete、raw scan 等普通 KV 操作。 Txn KV 操作是为了实现事务机制而设计的一系列操作,如 prewrite 和 commit 分别对应于 2PC 中的 prepare 和 commit 阶段的操作。
与 TiKV 源码解析系列文章(七)gRPC Server 的初始化和启动流程 中介绍的 handler example 不同,当前 KVService 对事务 API 例如 kv_prewrite, kv_commit 和 Raw API 例如 raw_get, raw_scan 进行了封装,由于他们都会被路由到 Storage 模块,所以接口无关的逻辑都被封装到了 handle_request 宏中,接口相关的逻辑则被封装到了 future_prewirte, future_commit 等 future_xxx 函数中。需要注意的是,对于 coprocessor API,raft API 等相关接口依然采用了原生对接 grpc-rs 的方式。
macro_rules! handle_request {($fn_name: ident, $future_name: ident, $req_ty: ident, $resp_ty: ident) => {handle_request!($fn_name, $future_name, $req_ty, $resp_ty, no_time_detail);};($fn_name: ident, $future_name: ident, $req_ty: ident, $resp_ty: ident, $time_detail: tt) => {fn $fn_name(&mut self, ctx: RpcContext<'_>, mut req: $req_ty, sink: UnarySink<$resp_ty>) {forward_unary!(self.proxy, $fn_name, ctx, req, sink);let begin_instant = Instant::now();let source = req.mut_context().take_request_source();let resp = $future_name(&self.storage, req);let task = async move {let resp = resp.await?;let elapsed = begin_instant.saturating_elapsed();set_total_time!(resp, elapsed, $time_detail);sink.success(resp).await?;GRPC_MSG_HISTOGRAM_STATIC.$fn_name.observe(elapsed.as_secs_f64());record_request_source_metrics(source, elapsed);ServerResult::Ok(())}.map_err(|e| {log_net_error!(e, "kv rpc failed";"request" => stringify!($fn_name));GRPC_MSG_FAIL_COUNTER.$fn_name.inc();}).map(|_|());ctx.spawn(task);}}
}impl<T: RaftStoreRouter<E::Local> + 'static, E: Engine, L: LockManager, F: KvFormat> Tikvfor Service<T, E, L, F>
{handle_request!(kv_get, future_get, GetRequest, GetResponse, has_time_detail);handle_request!(kv_scan, future_scan, ScanRequest, ScanResponse);handle_request!(kv_prewrite,future_prewrite,PrewriteRequest,PrewriteResponse,has_time_detail);...handle_request!(raw_get, future_raw_get, RawGetRequest, RawGetResponse);handle_request!(raw_batch_get,future_raw_batch_get,RawBatchGetRequest,RawBatchGetResponse);handle_request!(raw_scan, future_raw_scan, RawScanRequest, RawScanResponse);...fn coprocessor(&mut self, ctx: RpcContext<'_>, mut req: Request, sink: UnarySink<Response>) {forward_unary!(self.proxy, coprocessor, ctx, req, sink);let source = req.mut_context().take_request_source();let begin_instant = Instant::now();let future = future_copr(&self.copr, Some(ctx.peer()), req);let task = async move {let resp = future.await?.consume();sink.success(resp).await?;let elapsed = begin_instant.saturating_elapsed();GRPC_MSG_HISTOGRAM_STATIC.coprocessor.observe(elapsed.as_secs_f64());record_request_source_metrics(source, elapsed);ServerResult::Ok(())}.map_err(|e| {log_net_error!(e, "kv rpc failed";"request" => "coprocessor");GRPC_MSG_FAIL_COUNTER.coprocessor.inc();}).map(|_| ());ctx.spawn(task);}...
}
在事务相关 API 的 future_xxx 函数实现中,对于带有写语义的 future_prewrite, future_commit 等函数,由于它们会被统一调度到 Storage 模块的 sched_txn_command 函数中,当前又抽象出了 txn_command_future 宏来减少冗余代码;对于带有读语义的 future_get, future_scan 等函数,由于他们会分别调用 Storage 模块的 get/scan 等函数,因而目前并没有进行进一步抽象。
macro_rules! txn_command_future {($fn_name: ident, $req_ty: ident, $resp_ty: ident, ($req: ident) $prelude: stmt; ($v: ident, $resp: ident, $tracker: ident) { $else_branch: expr }) => {fn $fn_name<E: Engine, L: LockManager, F: KvFormat>(storage: &Storage<E, L, F>,$req: $req_ty,) -> impl Future<Output = ServerResult<$resp_ty>> {$preludelet $tracker = GLOBAL_TRACKERS.insert(Tracker::new(RequestInfo::new($req.get_context(),RequestType::Unknown,0,)));set_tls_tracker_token($tracker);let (cb, f) = paired_future_callback();let res = storage.sched_txn_command($req.into(), cb);async move {defer!{{GLOBAL_TRACKERS.remove($tracker);}};let $v = match res {Err(e) => Err(e),Ok(_) => f.await?,};let mut $resp = $resp_ty::default();if let Some(err) = extract_region_error(&$v) {$resp.set_region_error(err);} else {$else_branch;}Ok($resp)}}};($fn_name: ident, $req_ty: ident, $resp_ty: ident, ($v: ident, $resp: ident, $tracker: ident) { $else_branch: expr }) => {txn_command_future!($fn_name, $req_ty, $resp_ty, (req) {}; ($v, $resp, $tracker) { $else_branch });};($fn_name: ident, $req_ty: ident, $resp_ty: ident, ($v: ident, $resp: ident) { $else_branch: expr }) => {txn_command_future!($fn_name, $req_ty, $resp_ty, (req) {}; ($v, $resp, tracker) { $else_branch });};
}txn_command_future!(future_prewrite, PrewriteRequest, PrewriteResponse, (v, resp, tracker) {{if let Ok(v) = &v {resp.set_min_commit_ts(v.min_commit_ts.into_inner());resp.set_one_pc_commit_ts(v.one_pc_commit_ts.into_inner());GLOBAL_TRACKERS.with_tracker(tracker, |tracker| {tracker.write_scan_detail(resp.mut_exec_details_v2().mut_scan_detail_v2());tracker.write_write_detail(resp.mut_exec_details_v2().mut_write_detail());});}resp.set_errors(extract_key_errors(v.map(|v| v.locks)).into());
}});fn future_get<E: Engine, L: LockManager, F: KvFormat>(storage: &Storage<E, L, F>,mut req: GetRequest,
) -> impl Future<Output = ServerResult<GetResponse>> {let tracker = GLOBAL_TRACKERS.insert(Tracker::new(RequestInfo::new(req.get_context(),RequestType::KvGet,req.get_version(),)));set_tls_tracker_token(tracker);let start = Instant::now();let v = storage.get(req.take_context(),Key::from_raw(req.get_key()),req.get_version().into(),);async move {let v = v.await;let duration_ms = duration_to_ms(start.saturating_elapsed());let mut resp = GetResponse::default();if let Some(err) = extract_region_error(&v) {resp.set_region_error(err);} else {match v {Ok((val, stats)) => {...}Err(e) => resp.set_error(extract_key_error(&e)),}}GLOBAL_TRACKERS.remove(tracker);Ok(resp)}
}
自 3.x 版本以来,KVService 利用了多个宏显著减少了不同 RPC handler 间的冗余代码,然而这些宏目前还不能被 Clion 等调试工具的函数调用关系链捕捉到,这可能会困惑刚开始查看函数调用链却无法找到对应 handler 的新同学。
通过本小节,希望您能够了解 KVService 的作用和 TiKV 的启动流程,不仅具备寻找全局重要结构体初始化代码片段的能力,还能够迅速找到 KVService 中需要的 RPC handler 开始从上到下追踪 RPC 请求的调用路径。
Storage
Storage 模块位于 Service 与底层 KV 存储引擎之间,主要负责事务的并发控制。TiKV 端事务相关的实现都在 Storage 模块中。有关 3.x 版本的 Storage 模块可以参照 TiKV 源码解析系列文章(十一)Storage - 事务控制层。
经过三个大版本的迭代,Storage 和 Scheduler 结构体已经发生了一些变化,本小节将基于之前的源码解析文档做一些更新和补充。
Storage 结构体:
- engine:代表的是底层的 KV 存储引擎,利用 Trait Bound 来约束接口,拥有多种实现。实际 TiKV 使用的是 RaftKV 引擎,当调用 RaftKV 的 async_write 进行写入操作时,如果 async_write 通过回调方式成功返回了,说明写入操作已经通过 raft 复制给了大多数副本,并且在 leader 节点(调用者所在 TiKV)完成写入,后续 leader 节点上的读就能够看到之前写入的内容
- sched:事务调度器,负责并发事务请求的调度工作
- readPool:读取线程池,所有只读 KV 请求,包括事务的和非事务的,如 raw get、txn kv get 等最终都会在这个线程池内执行。由于只读请求不需要获取 latches,所以为其分配一个独立的线程池直接执行,而不是与非只读事务共用事务调度器。值得注意的是,当前版本的 readPool 已经支持根据读请求中的 priority 字段来差别调度读请求,而不是全部看做相同优先级的任务来公平调度
pub struct Storage<E: Engine, L: LockManager, F: KvFormat> {// TODO: Too many Arcs, would be slow when clone.engine: E,sched: TxnScheduler<E, L>,/// The thread pool used to run most read operations.read_pool: ReadPoolHandle,...
}#[derive(Clone)]
pub enum ReadPoolHandle {FuturePools {read_pool_high: FuturePool,read_pool_normal: FuturePool,read_pool_low: FuturePool,},Yatp {remote: Remote<TaskCell>,running_tasks: IntGauge,max_tasks: usize,pool_size: usize,},
}
Scheduler 结构体:
- id_alloc:到达 Scheduler 的请求都会被分配一个唯一的 command id
- latches:写请求到达 Scheduler 之后会尝试获取所需要的 latch,如果暂时获取不到所需要的 latch,其对应的 command id 会被插入到 latch 的 waiting list 里,当前面的请求执行结束后会唤醒 waiting list 里的请求继续执行。至于为什么需要 latches,可以参考 TiKV 源码解析系列文章(十二)分布式事务 中的
Scheduler 与 Latch章节 - task_slots:用于存储 Scheduler 中所有请求的上下文,比如暂时未能获取到所有所需 latch 的请求会被暂存在 task_slots 中
- lock_mgr:悲观事务冲突管理器,当多个并行悲观事务之间存在冲突时可能会暂时阻塞某些事务。TiKV 悲观事务具体原理可参考博客 TiDB 新特性漫谈:悲观事务
- pipelined_pessimistic_lock/in_memory_pessimistic_lock/enable_async_apply_prewrite:TiKV 悲观事务若干优化引入的新字段,具体优化可参考博客 TiDB 6.0 实战分享丨内存悲观锁原理浅析与实践
/// Scheduler which schedules the execution of `storage::Command`s.
#[derive(Clone)]
pub struct Scheduler<E: Engine, L: LockManager> {inner: Arc<SchedulerInner<L>>,// The engine can be fetched from the thread local storage of scheduler threads.// So, we don't store the engine here._engine: PhantomData<E>,
}struct SchedulerInner<L: LockManager> {// slot_id -> { cid -> `TaskContext` } in the slot.task_slots: Vec<CachePadded<Mutex<HashMap<u64, TaskContext>>>>,// cmd id generatorid_alloc: CachePadded<AtomicU64>,// write concurrency controllatches: Latches,sched_pending_write_threshold: usize,// worker poolworker_pool: SchedPool,// high priority commands and system commands will be delivered to this poolhigh_priority_pool: SchedPool,// used to control write flowrunning_write_bytes: CachePadded<AtomicUsize>,flow_controller: Arc<FlowController>,control_mutex: Arc<tokio::sync::Mutex<bool>>,lock_mgr: L,concurrency_manager: ConcurrencyManager,pipelined_pessimistic_lock: Arc<AtomicBool>,in_memory_pessimistic_lock: Arc<AtomicBool>,enable_async_apply_prewrite: bool,resource_tag_factory: ResourceTagFactory,quota_limiter: Arc<QuotaLimiter>,feature_gate: FeatureGate,
}
最开始看到 id_alloc 和 task_slots 的介绍时往往会好奇为每个 command 生成唯一 id 的意义是什么? task_slots 里面存的上下文到底是什么?实际上这与 TiKV 的异步执行框架有关系。
以下是 Storage 模块执行事务请求的关键函数 schedule_command,可以看到,每个请求一进入函数首先会申请一个递增唯一的 cid,接着依据该 cid 将本次请求的 command 包在一个 task 中,然后将该 task 附带 callback 生成一个 TaskContext 插入到 task_slot 中,之后便会尝试去申请 latches,如果成功便会继续调用 execute 函数去真正执行 task,否则便似乎没有下文了?那么如果 task 申请 latches 失败,之后该 task 会在什么时候被执行呢?
fn schedule_command(&self, cmd: Command, callback: StorageCallback) {let cid = self.inner.gen_id();let tracker = get_tls_tracker_token();debug!("received new command"; "cid" => cid, "cmd" => ?cmd, "tracker" => ?tracker);let tag = cmd.tag();let priority_tag = get_priority_tag(cmd.priority());SCHED_STAGE_COUNTER_VEC.get(tag).new.inc();SCHED_COMMANDS_PRI_COUNTER_VEC_STATIC.get(priority_tag).inc();let mut task_slot = self.inner.get_task_slot(cid);let tctx = task_slot.entry(cid).or_insert_with(|| {self.inner.new_task_context(Task::new(cid, tracker, cmd), callback)});if self.inner.latches.acquire(&mut tctx.lock, cid) {fail_point!("txn_scheduler_acquire_success");tctx.on_schedule();let task = tctx.task.take().unwrap();drop(task_slot);self.execute(task);return;}let task = tctx.task.as_ref().unwrap();let deadline = task.cmd.deadline();let cmd_ctx = task.cmd.ctx().clone();self.fail_fast_or_check_deadline(cid, tag, cmd_ctx, deadline);fail_point!("txn_scheduler_acquire_fail");
}/// Task is a running command.
pub(super) struct Task {pub(super) cid: u64,pub(super) tracker: TrackerToken,pub(super) cmd: Command,pub(super) extra_op: ExtraOp,
}// It stores context of a task.
struct TaskContext {task: Option<Task>,lock: Lock,cb: Option<StorageCallback>,pr: Option<ProcessResult>,// The one who sets `owned` from false to true is allowed to take// `cb` and `pr` safely.owned: AtomicBool,write_bytes: usize,tag: CommandKind,// How long it waits on latches.// latch_timer: Option<Instant>,latch_timer: Instant,// Total duration of a command._cmd_timer: CmdTimer,
}/// Latches which are used for concurrency control in the scheduler.
///
/// Each latch is indexed by a slot ID, hence the term latch and slot are used
/// interchangeably, but conceptually a latch is a queue, and a slot is an index
/// to the queue.
pub struct Latches {slots: Vec<CachePadded<Mutex<Latch>>>,size: usize,
}
进入 Latches::acquire 函数中去细究,可以看到其会渐进的去收集所有 latch,如果在本次函数调用中没有收集到所有的 latch, 当前线程不会受到任何阻塞而是直接返回 false。当然在返回 false 之前其也会利用 latch.wair_for_wake 函数将当前 task 的 id 放到对应 latch 的 waiting 队列里面,之后当前线程便可以处理其他的任务而不是阻塞在该任务上。由于每个获取到所有 latch 去执行的任务会在执行结束后调用 scheduler::release_lock 函数来释放所拥有的全部 latch,在释放过程中,其便能够获取到阻塞在这些 latch 且位于 waiting 队列首位的所有其他 task,接着对应线程会调用 scheduler::try_to_wake_up 函数遍历唤醒这些 task 并尝试再次获取 latch 和执行,一旦能够获取成功便去 execute,否则继续阻塞等待其他线程再次唤醒即可。
/// Tries to acquire the latches specified by the `lock` for command with ID
/// `who`.
///
/// This method will enqueue the command ID into the waiting queues of the
/// latches. A latch is considered acquired if the command ID is the first
/// one of elements in the queue which have the same hash value. Returns
/// true if all the Latches are acquired, false otherwise.
pub fn acquire(&self, lock: &mut Lock, who: u64) -> bool {let mut acquired_count: usize = 0;for &key_hash in &lock.required_hashes[lock.owned_count..] {let mut latch = self.lock_latch(key_hash);match latch.get_first_req_by_hash(key_hash) {Some(cid) => {if cid == who {acquired_count += 1;} else {latch.wait_for_wake(key_hash, who);break;}}None => {latch.wait_for_wake(key_hash, who);acquired_count += 1;}}}lock.owned_count += acquired_count;lock.acquired()
}pub fn wait_for_wake(&mut self, key_hash: u64, cid: u64) {self.waiting.push_back(Some((key_hash, cid)));
}/// Releases all the latches held by a command.
fn release_lock(&self, lock: &Lock, cid: u64) {let wakeup_list = self.inner.latches.release(lock, cid);for wcid in wakeup_list {self.try_to_wake_up(wcid);}
}/// Releases all latches owned by the `lock` of command with ID `who`,
/// returns the wakeup list.
///
/// Preconditions: the caller must ensure the command is at the front of the
/// latches.
pub fn release(&self, lock: &Lock, who: u64) -> Vec<u64> {let mut wakeup_list: Vec<u64> = vec![];for &key_hash in &lock.required_hashes[..lock.owned_count] {let mut latch = self.lock_latch(key_hash);let (v, front) = latch.pop_front(key_hash).unwrap();assert_eq!(front, who);assert_eq!(v, key_hash);if let Some(wakeup) = latch.get_first_req_by_hash(key_hash) {wakeup_list.push(wakeup);}}wakeup_list
}/// Tries to acquire all the necessary latches. If all the necessary latches
/// are acquired, the method initiates a get snapshot operation for further
/// processing.
fn try_to_wake_up(&self, cid: u64) {match self.inner.acquire_lock_on_wakeup(cid) {Ok(Some(task)) => {fail_point!("txn_scheduler_try_to_wake_up");self.execute(task);}Ok(None) => {}Err(err) => {// Spawn the finish task to the pool to avoid stack overflow// when many queuing tasks fail successively.let this = self.clone();self.inner.worker_pool.pool.spawn(async move {this.finish_with_err(cid, err);}).unwrap();}}
}
实际上一旦构造出 TaskContext 并插入到 task_slots 中,只要持有 id 便可以去 task_slots 中获取到该 task 和其对应的 callback,那么任何一个线程都可以去执行该任务并返回客户端对应的执行结果。
总体来看,这样的异步执行方案相当于在 command 级别抽象出了一套类协程调度逻辑,再辅以 Rust 原生的无栈协程,减少了很多 grpc 线程之间的同步阻塞和切换。
通过本小节,希望您能够了解 Storage 模块的组织结构,并对 scheduler 的异步并发请求调度方案有一定的认知,能够在正确的位置去追踪单个请求的异步调用路径。
RaftStore
RaftStore 常被认为是 TiKV 最复杂,最晦涩的模块,劝退了相当一部分开发者。
在笔者看来这主要跟要保证 multi-raft + split/merge 在各种 case 下的一致性/正确性有关,本身的语义就十分复杂,那实现也就很难简单了。尽管有太多需要注意的细节,但如果仅要了解 RaftStore 的大体框架依然是可行的。
TiKV 源码解析系列文章(十七)raftstore 概览 介绍了 3.x 版本的 RaftStore,目前 RaftStore 已经有了些许的变化,本小节将简单补充笔者的理解。
Batch System 是 RaftStore 处理的基石,是一套用来并发驱动状态机的机制。
状态机的核心定义如下:
/// A `Fsm` is a finite state machine. It should be able to be notified for
/// updating internal state according to incoming messages.
pub trait Fsm {type Message: Send;fn is_stopped(&self) -> bool;/// Set a mailbox to FSM, which should be used to send message to itself.fn set_mailbox(&mut self, _mailbox: Cow<'_, BasicMailbox<Self>>)whereSelf: Sized,{}/// Take the mailbox from FSM. Implementation should ensure there will be/// no reference to mailbox after calling this method.fn take_mailbox(&mut self) -> Option<BasicMailbox<Self>>whereSelf: Sized,{None}fn get_priority(&self) -> Priority {Priority::Normal}
}/// A unify type for FSMs so that they can be sent to channel easily.
pub enum FsmTypes<N, C> {Normal(Box<N>),Control(Box<C>),// Used as a signal that scheduler should be shutdown.Empty,
}
状态机通过 PollHandler 来驱动,定义如下:
/// A handler that polls all FSMs in ready.
///
/// A general process works like the following:
///
/// loop {
/// begin
/// if control is ready:
/// handle_control
/// foreach ready normal:
/// handle_normal
/// light_end
/// end
/// }
///
/// A [`PollHandler`] doesn't have to be [`Sync`] because each poll thread has
/// its own handler.
pub trait PollHandler<N, C>: Send + 'static {/// This function is called at the very beginning of every round.fn begin<F>(&mut self, _batch_size: usize, update_cfg: F)wherefor<'a> F: FnOnce(&'a Config);/// This function is called when the control FSM is ready.////// If `Some(len)` is returned, this function will not be called again until/// there are more than `len` pending messages in `control` FSM.////// If `None` is returned, this function will be called again with the same/// FSM `control` in the next round, unless it is stopped.fn handle_control(&mut self, control: &mut C) -> Option<usize>;/// This function is called when some normal FSMs are ready.fn handle_normal(&mut self, normal: &mut impl DerefMut<Target = N>) -> HandleResult;/// This function is called after [`handle_normal`] is called for all FSMs/// and before calling [`end`]. The function is expected to run lightweight/// works.fn light_end(&mut self, _batch: &mut [Option<impl DerefMut<Target = N>>]) {}/// This function is called at the end of every round.fn end(&mut self, batch: &mut [Option<impl DerefMut<Target = N>>]);/// This function is called when batch system is going to sleep.fn pause(&mut self) {}/// This function returns the priority of this handler.fn get_priority(&self) -> Priority {Priority::Normal}
}
大体来看,状态机分成两种,normal 和 control。对于每一个 Batch System,只有一个 control 状态机,负责管理和处理一些需要全局视野的任务。其他 normal 状态机负责处理其自身相关的任务。每个状态机都有其绑定的消息和消息队列。PollHandler 负责驱动状态机,处理自身队列中的消息。Batch System 的职责就是检测哪些状态机需要驱动,然后调用 PollHandler 去消费消息。消费消息会产生副作用,而这些副作用或要落盘,或要网络交互。PollHandler 在一个批次中可以处理多个 normal 状态机。
在 RaftStore 里,一共有两个 Batch System。分别是 RaftBatchSystem 和 ApplyBatchSystem。RaftBatchSystem 用于驱动 Raft 状态机,包括日志的分发、落盘、状态跃迁等。已经提交的日志会被发往 ApplyBatchSystem 进行处理。ApplyBatchSystem 将日志解析并应用到底层 KV 数据库中,执行回调函数。所有的写操作都遵循着这个流程。
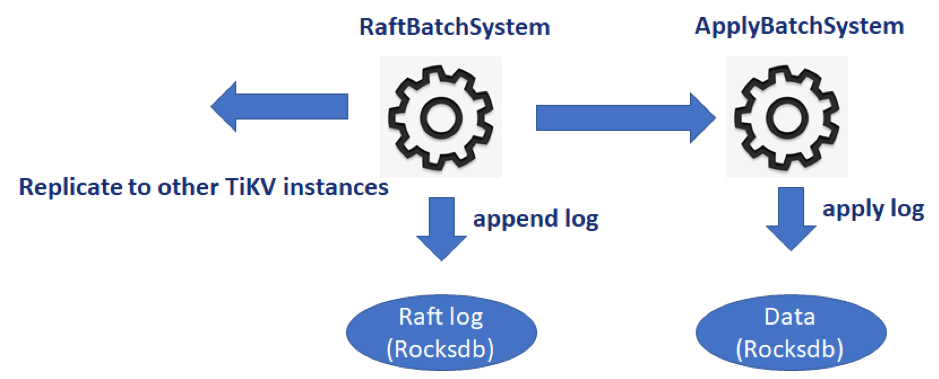
具体一点来说:
- 每个 PollHandler 对应一个线程,其在 poll 函数中会持续地检测需要驱动的状态机并进行处理,此外还可能将某些 hot region 路由给其他 PollHandler 来做一些负载均衡操作。
- 每个 region 对应一个 raft 组,而每个 raft 组在一个 BatchSystem 里就对应一个 normal 状态机,
- 对于 RaftBatchSystem,参照 TiKV 源码解析系列文章(二)raft-rs proposal 示例情景分析 中提到的 raft-rs 接口,每个 normal 状态机在一轮 loop 中被 PollHandler 获取一次 ready,其中一般包含需要持久化的未提交日志,需要发送的消息和需要应用的已提交日志等。对于需要持久化的未提交日志,最直接的做法便是将其暂时缓存到内存中进行攒批,然后在当前 loop 结尾的 end 函数中统一同步处理,这无疑会影响每轮 loop 的效率, TiKV 的 6.x 版本已经将 loop 结尾的同步 IO 抽到了 loop 外交给了额外的线程池去做,这进一步提升了 store loop 的效率,具体可参考该 issue。对于需要发送的消息,则通过 Transport 异步发送给对应的 store。对于需要应用的已提交日志,则通过 applyRouter 带着回调函数发给 ApplyBatchSystem。
- 对于 ApplyBatchSystem,每个 normal 状态机在一轮 loop 中被 PollHandler 获取 RaftBatchSystem 发来的若干已经提交需要应用的日志,其需要将其攒批提交并在之后执行对应的回调函数返回客户端结果。需要注意的是,返回客户端结果之后 ApplyBatchSystem 还需要向 RaftBatchSystem 再 propose ApplyRes 的消息,从而更新 RaftBatchSystem 的某些内存状态,比如 applyIndex,该字段的更新能够推动某些阻塞在某个 ReadIndex 上的读请求继续执行。
如下便是 BatchSystem 的启动流程及 poll 函数:
/// A system that can poll FSMs concurrently and in batch.
///
/// To use the system, two type of FSMs and their PollHandlers need to be
/// defined: Normal and Control. Normal FSM handles the general task while
/// Control FSM creates normal FSM instances.
pub struct BatchSystem<N: Fsm, C: Fsm> {name_prefix: Option<String>,router: BatchRouter<N, C>,receiver: channel::Receiver<FsmTypes<N, C>>,low_receiver: channel::Receiver<FsmTypes<N, C>>,pool_size: usize,max_batch_size: usize,workers: Arc<Mutex<Vec<JoinHandle<()>>>>,joinable_workers: Arc<Mutex<Vec<ThreadId>>>,reschedule_duration: Duration,low_priority_pool_size: usize,pool_state_builder: Option<PoolStateBuilder<N, C>>,
}impl<N, C> BatchSystem<N, C>
whereN: Fsm + Send + 'static,C: Fsm + Send + 'static,
{fn start_poller<B>(&mut self, name: String, priority: Priority, builder: &mut B)whereB: HandlerBuilder<N, C>,B::Handler: Send + 'static,{let handler = builder.build(priority);let receiver = match priority {Priority::Normal => self.receiver.clone(),Priority::Low => self.low_receiver.clone(),};let mut poller = Poller {router: self.router.clone(),fsm_receiver: receiver,handler,max_batch_size: self.max_batch_size,reschedule_duration: self.reschedule_duration,joinable_workers: if priority == Priority::Normal {Some(Arc::clone(&self.joinable_workers))} else {None},};let props = tikv_util::thread_group::current_properties();let t = thread::Builder::new().name(name).spawn_wrapper(move || {tikv_util::thread_group::set_properties(props);set_io_type(IoType::ForegroundWrite);poller.poll();}).unwrap();self.workers.lock().unwrap().push(t);}/// Start the batch system.pub fn spawn<B>(&mut self, name_prefix: String, mut builder: B)whereB: HandlerBuilder<N, C>,B::Handler: Send + 'static,{for i in 0..self.pool_size {self.start_poller(thd_name!(format!("{}-{}", name_prefix, i)),Priority::Normal,&mut builder,);}for i in 0..self.low_priority_pool_size {self.start_poller(thd_name!(format!("{}-low-{}", name_prefix, i)),Priority::Low,&mut builder,);}self.name_prefix = Some(name_prefix);}
}/// Polls for readiness and forwards them to handler. Removes stale peers if/// necessary.pub fn poll(&mut self) {fail_point!("poll");let mut batch = Batch::with_capacity(self.max_batch_size);let mut reschedule_fsms = Vec::with_capacity(self.max_batch_size);let mut to_skip_end = Vec::with_capacity(self.max_batch_size);// Fetch batch after every round is finished. It's helpful to protect regions// from becoming hungry if some regions are hot points. Since we fetch new FSM// every time calling `poll`, we do not need to configure a large value for// `self.max_batch_size`.let mut run = true;while run && self.fetch_fsm(&mut batch) {// If there is some region wait to be deal, we must deal with it even if it has// overhead max size of batch. It's helpful to protect regions from becoming// hungry if some regions are hot points.let mut max_batch_size = std::cmp::max(self.max_batch_size, batch.normals.len());// Update some online config if needed.{// TODO: rust 2018 does not support capture disjoint field within a closure.// See https://github.com/rust-lang/rust/issues/53488 for more details.// We can remove this once we upgrade to rust 2021 or later edition.let batch_size = &mut self.max_batch_size;self.handler.begin(max_batch_size, |cfg| {*batch_size = cfg.max_batch_size();});}max_batch_size = std::cmp::max(self.max_batch_size, batch.normals.len());if batch.control.is_some() {let len = self.handler.handle_control(batch.control.as_mut().unwrap());if batch.control.as_ref().unwrap().is_stopped() {batch.remove_control(&self.router.control_box);} else if let Some(len) = len {batch.release_control(&self.router.control_box, len);}}let mut hot_fsm_count = 0;for (i, p) in batch.normals.iter_mut().enumerate() {let p = p.as_mut().unwrap();let res = self.handler.handle_normal(p);if p.is_stopped() {p.policy = Some(ReschedulePolicy::Remove);reschedule_fsms.push(i);} else if p.get_priority() != self.handler.get_priority() {p.policy = Some(ReschedulePolicy::Schedule);reschedule_fsms.push(i);} else {if p.timer.saturating_elapsed() >= self.reschedule_duration {hot_fsm_count += 1;// We should only reschedule a half of the hot regions, otherwise,// it's possible all the hot regions are fetched in a batch the// next time.if hot_fsm_count % 2 == 0 {p.policy = Some(ReschedulePolicy::Schedule);reschedule_fsms.push(i);continue;}}if let HandleResult::StopAt { progress, skip_end } = res {p.policy = Some(ReschedulePolicy::Release(progress));reschedule_fsms.push(i);if skip_end {to_skip_end.push(i);}}}}let mut fsm_cnt = batch.normals.len();while batch.normals.len() < max_batch_size {if let Ok(fsm) = self.fsm_receiver.try_recv() {run = batch.push(fsm);}// When `fsm_cnt >= batch.normals.len()`:// - No more FSMs in `fsm_receiver`.// - We receive a control FSM. Break the loop because ControlFsm may change// state of the handler, we shall deal with it immediately after calling// `begin` of `Handler`.if !run || fsm_cnt >= batch.normals.len() {break;}let p = batch.normals[fsm_cnt].as_mut().unwrap();let res = self.handler.handle_normal(p);if p.is_stopped() {p.policy = Some(ReschedulePolicy::Remove);reschedule_fsms.push(fsm_cnt);} else if let HandleResult::StopAt { progress, skip_end } = res {p.policy = Some(ReschedulePolicy::Release(progress));reschedule_fsms.push(fsm_cnt);if skip_end {to_skip_end.push(fsm_cnt);}}fsm_cnt += 1;}self.handler.light_end(&mut batch.normals);for index in &to_skip_end {batch.schedule(&self.router, *index);}to_skip_end.clear();self.handler.end(&mut batch.normals);// Iterate larger index first, so that `swap_reclaim` won't affect other FSMs// in the list.for index in reschedule_fsms.iter().rev() {batch.schedule(&self.router, *index);batch.swap_reclaim(*index);}reschedule_fsms.clear();}if let Some(fsm) = batch.control.take() {self.router.control_scheduler.schedule(fsm);info!("poller will exit, release the left ControlFsm");}let left_fsm_cnt = batch.normals.len();if left_fsm_cnt > 0 {info!("poller will exit, schedule {} left NormalFsms",left_fsm_cnt);for i in 0..left_fsm_cnt {let to_schedule = match batch.normals[i].take() {Some(f) => f,None => continue,};self.router.normal_scheduler.schedule(to_schedule.fsm);}}batch.clear();}
}
通过本小节,希望您能够了解 BatchSystem 的大体框架,并知悉 PollHandler 和 FSM 的物理含义,以便结合之后的博客去熟悉全链路读写流程。
调试方案
断点调试是一种学习源码的有效手段。当不是很熟悉 gdb 等工具时,使用一些更现代的 IDE 会大幅提升调试代码的体验。
笔者平时采用了 CLion + intellij-rust 的工具链来调试 Rust 代码。需要注意的是,在使用 CLion 调试 TiKV 源码时,需要参照 Cargo book 修改 TiKV cargo.toml 中 [profile.test] 和 [profile.dev] 的 debug 选项 来开启调试信息,否则在 Clion 里断点调试时会无法看到对应的堆栈信息。
实际上如果要做到以上读写路径的全链路追踪,最简单的方法便是从集成测试里面寻找一些 case,接着从 Service 模块开始打断点,之后执行调试即可。在这里推荐 integrations/server/kv_service.rs 中的测试,里面的 test 都会构造 TiKVClient 发送真实的 RPC 请求,且服务端也基本不包含 Mock 组件,可以完整的去追踪一条 RPC 的全链路流程。
此外由于 TiKV 的代码中有比较多的 spawn 和回调函数,刚开始可能并不能很直接的串起来流程,但相信通过上文的介绍,您已经大致了解其异步框架的实现,从而可以在正确的闭包位置打下断点,进而熟悉地追踪单条请求的全链路实现。
总结
本篇博客介绍了 TiKV 的基本概念,TiKV 读写路径上的三个重要模块(KVService,Storage,RaftStore)和断点调试 TiKV 学习源码的方案
希望本博客能够帮助对 TiKV 开发感兴趣的新同学尽快了解 TiKV 的 codebase。
感谢您的阅读~
这篇关于TiKV 源码阅读三部曲(一)重要模块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




