本文主要是介绍Flink SQL TopN语句详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TopN 定义(⽀持 Batch\Streaming): TopN 对应离线数仓的 row_number(),使⽤ row_number() 对某⼀个分组的数据进⾏排序。
应⽤场景: 根据 某个排序 条件,计算 某个分组 下的排⾏榜数据。
SQL 语法标准:
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownumFROM table_name)
WHERE rownum <= N [AND conditions];
- ROW_NUMBER() :标识 TopN 排序⼦句;
- PARTITION BY col1[, col2…] :标识分区字段,代表按照这个 col 字段作为分区粒度对数据排序取 topN,下述案例中的 partition by key ,根据需求中的搜索关键词(key)做为分区;
- ORDER BY col1 [asc|desc][, col2 [asc|desc]…] :标识 TopN 的排序规则,是按照哪些字段、顺序或逆序进⾏排序;
- WHERE rownum <= N :这个⼦句是必须的,加上这个⼦句,Flink 才能将其识别为 TopN 查询,其中 N 代表 TopN 的条⽬数;
- [AND conditions] :其他的限制条件也可以加上。
实际案例: 取某个搜索关键词下的搜索热度前 10 名的词条数据。
输⼊数据为搜索词条数据的搜索热度数据,当搜索热度发⽣变化时,会将变化后的数据写⼊到数据源的 Kafka 中:
数据源 schema:-- 字段名 备注
-- key 搜索关键词
-- name 搜索热度名称
-- search_cnt 热搜消费热度(⽐如 3000)
-- timestamp 消费词条时间戳
CREATE TABLE source_table (name STRING NOT NULL,search_cnt BIGINT NOT NULL,key STRING NOT NULL,row_time timestamp(3),WATERMARK FOR row_time AS row_time
) WITH ('connector' = 'filesystem', 'path' = 'file:///Users/hhx/Desktop/source_table.csv','format' = 'csv'
);A,100,a,2021-11-01 00:01:03
A,200,a,2021-11-02 00:01:03
A,300,a,2021-11-03 00:01:03
B,200,b,2021-11-01 00:01:03
B,300,b,2021-11-02 00:01:03
B,400,b,2021-11-03 00:01:03
C,300,c,2021-11-01 00:01:03
C,400,c,2021-11-02 00:01:03
C,500,c,2021-11-03 00:01:03
D,400,d,2021-11-01 00:01:03
D,500,d,2021-11-02 00:01:03
D,600,d,2021-11-03 00:01:03-- 数据汇 schema:
-- key 搜索关键词
-- name 搜索热度名称
-- search_cnt 热搜消费热度(⽐如 3000)
-- timestamp 消费词条时间戳
CREATE TABLE sink_table (key BIGINT,name BIGINT,search_cnt BIGINT,`timestamp` TIMESTAMP(3)
) WITH (...
);-- DML 逻辑
INSERT INTO sink_table
SELECT key, name, search_cnt, row_time as `timestamp`
FROM (SELECT key, name, search_cnt, row_time, -- 根据热搜关键词 key 作为 partition key,然后按照 search_cnt 倒排取前 2 名ROW_NUMBER() OVER (PARTITION BY key ORDER BY search_cnt desc) AS rownumFROM source_table)
WHERE rownum <= 2
输出结果:
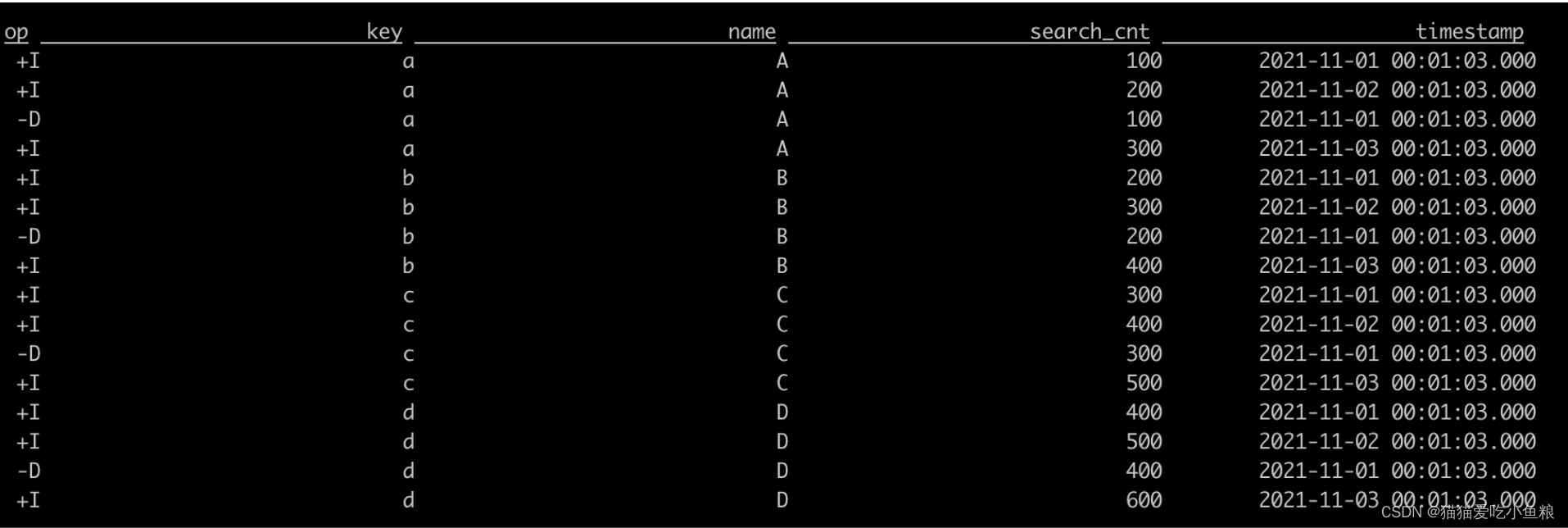
注意: 包含回撤流。
上⾯ SQL 会翻译成以下三个算⼦
数据源 :数据源即最新的词条下⾯的搜索词的搜索热度数据,消费到 Kafka 中数据后,按照 partition key 将数据进⾏ hash 分发到下游排序算⼦,相同的 key 数据将会发送到⼀个并发中;
排序算⼦ :为每个 Key 维护了⼀个 TopN 的榜单数据,接受到上游的⼀条数据后,如果 TopN 榜单还没有到达 N 条,则将这条数据加⼊ TopN 榜单后,直接下发数据,如果到达 N 条之后,经过 TopN 计算,发现这条数据⽐原有的数据排序靠前,那么新的 TopN 排名就会有变化,就变化了的这部分数据,之前下发的排名数据被撤回(即回撤数据),然后下发新的排名数据;
数据汇 :接收到上游的数据之后,然后输出到外部存储引擎中。
这篇关于Flink SQL TopN语句详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





