本文主要是介绍【MySQL】总结:外部txt数据导入MySQL的避坑指南(ERROR code: 3948/2068/1300/1366),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(一)背景:
昨天在导入外部数据(txt文件)到MySQL时成功收获5连错,花了小半天把问题解决,意识到这或许是新手在导入数据时容易出现的问题。因此决定基于报错问题总结导入外部数据时要注意的事项,希望能够帮到MySQL学习的同好们。
(二)环境及语句:
Windows 10;
MySQL Server 8.0.29;
MySQL Workbench 8.0.29;
(三)结论:
我导入txt文件的代码如下:

语句模板为:
# 导入外部数据到Monthly_Indicator中load data infile 'txt文件的绝对路径(包含扩展名)'into table 目标表格fields terminated by '\t' # 我的txt文件分割方式为制表符,制表符符号为'\t',因此指定MySQL导入时的分割方式为'\t';ignore 1 lines;# 我的txt文件第一行是字段名,导入时应忽略字段名,故指定MySQL忽略第一行;需要注意的事项为:
请检查你的local_infile状态,确保它是打开的;
请将txt文件编码格式改成utf-8;
请确保外部文件对应字段的数据类型和MySQL中的一致;
请将txt文件移至MySQL Server路径的Uploads文件夹中:
(四)避坑总结:
1. 请检查你的local_infile状态:
- local_infile是全局系统变量,功能是决定能否使用load data local infile的命令。
- MySQL 8.0.29 中,local_infile的默认状态是关闭的。
- 因此,如果想利用load data local infile录入外部数据,请先将其打开。
- 未打开local_infile的报错为:
ERROR: 3948, Loading local data is disabled - this must be enabled on both the client and server sides.
打开local_infile的方式如下:
-
打开MySQL Server 8.0 Command Line Clinet:
-
检查local_infile状态:
输入如下语句mysql > show variables like 'local_infile'; # 输入上述语句就能够检查local_infile状态。 (mysql > 是打开客户端后自动显示的,所以不用重复输入)
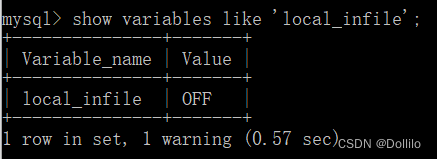
可以看到local_infile的Value为"OFF“,此时的local_infile是关闭的,无法通过load data local infile导入外部数据。
-
打开local_infile开关:
(1)输入如下语句
set global local_infile = 1; 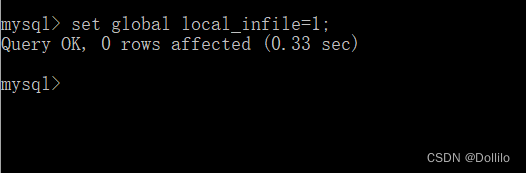
(2)再次检查local_infile状态:
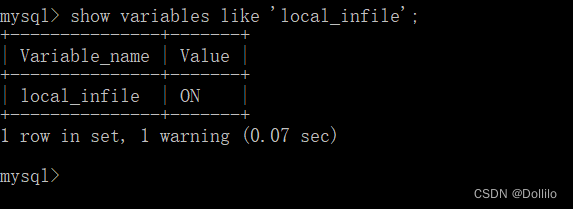
可以看见此时的local_infile已经打开了。
2. 请将txt文件编码格式改成utf-8:
- MySQL的默认编码是utf8;
- txt文件的默认编码是ANSI;
- 如果不改txt文件编码就直接导入MySQL,则会读取失败;
- 不改txt文件编码的报错为:
Error Code: 1300. Invalid utf8mb4 character string:''
改变txt的编码,只需要打开目标文件,点击【另存为】,在弹出界面的右下角就能够选择编码格式,我们选择UTF-8就好了。
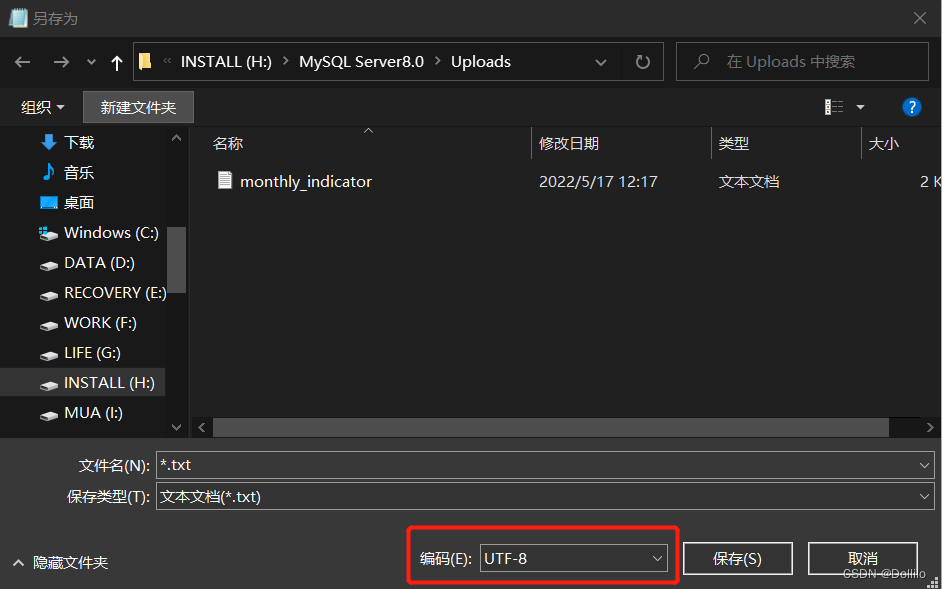
3. 请确保外部文件对应字段的数据类型和MySQL中的一致:
- 导入数据前,我们会现在MySQL中定义表,并为字段设置数据类型;
- 如果txt文件对应的字段数据类型和MySQL对应字段数据类型不一致,就可能会发生报错;
- 例子:MySQL中字段ranking设置为整型,而txt中ranking却是字符' - '。那么,在将txt录入MySQL时,ranking数据的录入就会因为数据类型不符而失败;
- 数据类型不匹配时的报错为:
Error Code: 1366. Incorrect integer value: '- ' for column 'ranking' at row 1
(仅展示一种情况,实际报错情况不仅限于这一种)
4. 请将txt文件移至MySQL Server路径的Uploads文件夹中:
- 未将txt文件移至Uploads文件夹的报错为:
Error Code: 2068. LOAD DATA LOCAL INFILE file request rejected due to restrictions on access.
由于不把txt文件移到Uploasd文件夹下会报错,所以我们应该将txt移进去,方法如下:
(1)找到你的MySQL Server路径:
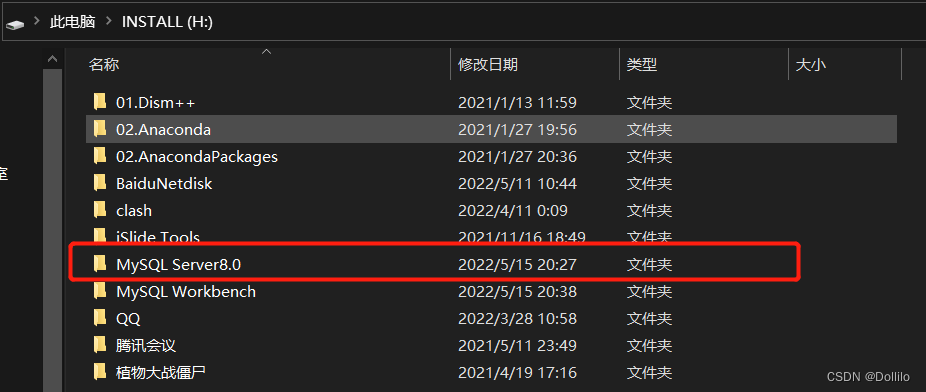
如果是自定义路径安装的,指定的路径就是MySQL Server8.0的路径;如果忘记了路径在哪里,可以打开 MySQL Server 8.0 Command Line Clinet,输入以下语句找回:
show variables like '%basedir%'; 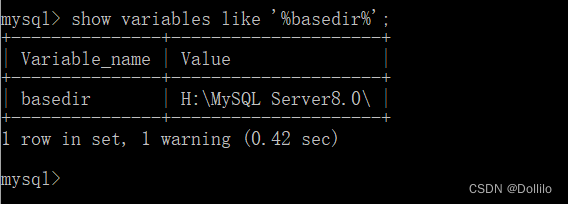
(2)将txt文件移到MySQL Server8.0\Uploads中:
双击MySQL Server8.0后,进入Uploads文件夹。
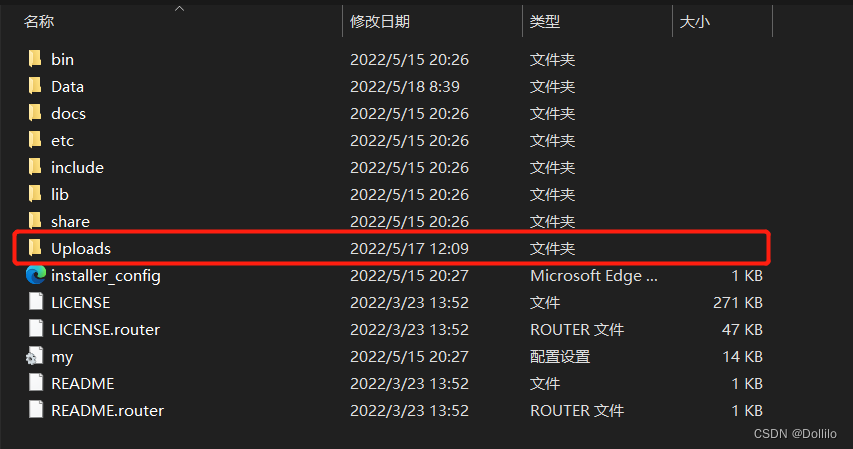
 将txt文件移到这里就好了。
将txt文件移到这里就好了。
这篇关于【MySQL】总结:外部txt数据导入MySQL的避坑指南(ERROR code: 3948/2068/1300/1366)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






