本文主要是介绍大模型激增:真的需要这么多吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI领域已转变为全球企业和国家间的竞技场。众多企业意图建立各自的大语言模型。例如,沙特阿拉伯购买了逾3000块H100芯片来培养其语言模型。这种现象引起了业内人士的思考,无论是互联网初创时期还是今日的AI环境,有市场机会的地方必有竞争。随着众多竞争者的进入,AI竞技场更加激烈。

Transformer引领AI新纪元
在2017年,8位谷歌的计算机科学家发布了一篇名为《Attention Is All You Need》的研究论文,标志着Transformer算法的诞生。此篇成果蜚声AI界,为后续的AI浪潮铺路。
以往,机器阅读长篇文字存在巨大挑战,不同于图像识别,人类阅读需要考虑上下文关系理解。
在初始的神经网络处理文本时每个输入是独立的,容易出现误译。直到2014年,计算机科学家伊利亚(Ilya Sutskever)采用RNN(循环神经网络)改进了文本处理效果,推动了谷歌翻译技术的飞跃。
RNN提出了“循环设计”,让每个神经元既接受当前时刻输入信息,也接受上一时刻的输入信息,进而使神经网络具备了“结合上下文”的能力。
 循环神经网络,出自知乎《循环神经网络RNN——深度学习第十章》
循环神经网络,出自知乎《循环神经网络RNN——深度学习第十章》
传统的循环神经网络(RNN)采用顺序计算,虽然它能够考虑上下文信息,但其计算效率并不高,且难以处理大量参数。于是,沙泽尔(Noam Shazeer)和他的团队从2015年开始致力于开发RNN的替代产品。他们的努力结晶即为Transformer。与RNN相比,Transformer带来了两大创新:并行计算的位置编码机制,以及加强的上下文处理能力。
Transformer的成功逐渐成为了自然语言处理(NLP)领域的主流算法。即便是一度为RNN做出贡献的计算机科学家伊利亚(Ilya Sutskever)也转向了Transformer。此后,Transformer成为了大模型研发中的核心技术。
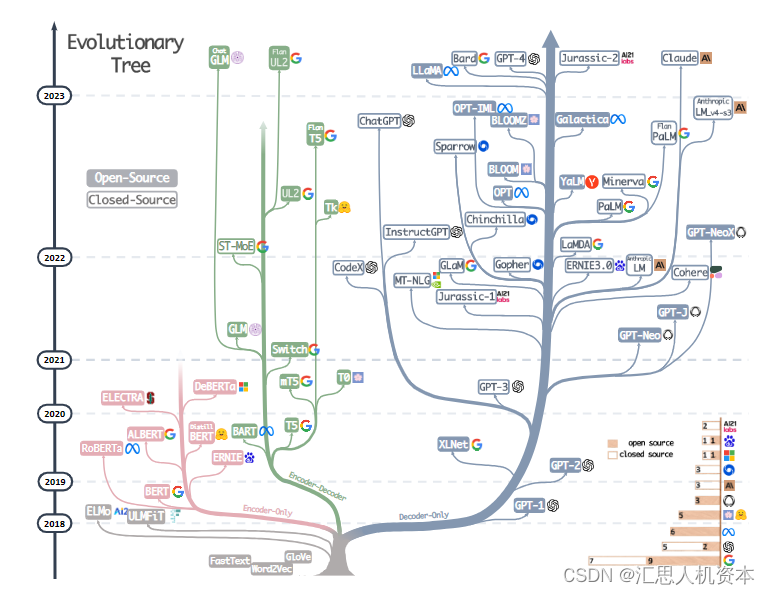 灰色的树根为Transformer,图片参考论文地址:https://arxiv.org/abs/2304.13712
灰色的树根为Transformer,图片参考论文地址:https://arxiv.org/abs/2304.13712
随着Transformer的普及,AI研究焦点转向数据工程和模型架构。几乎所有技术先进的公司都开始开发自己的大模型。Semi Analysis预测,OpenAI的技术一旦被开源。其他大型科技公司也很快就能够复制其成功。
大模型竞逐,开源生态兴起
当前,大模型发展呈现白热化趋势。最新数据显示,截止今年7月,国内大模型总数已超过美国。各国都在积极研发,如印度的Bhashini和韩国Naver的HyperClova X。
大模型如今被视为工程问题而非科学难题。随着Transformer算法的发展,只要有足够的资金和计算资源,理论上任何机构都可研发出自己的大模型。但仅有大模型,并不意味着能跻身AI领域的巨头。例如,尽管Falcon模型在某些排名中领先于其他模型,其对于Meta的市场冲击实际上有限。
企业的开源策略旨在分享技术成果,同时也希望获得社区的贡献。活跃的开发者社区已成为开源大模型的核心竞争力。作为例证,Meta公司自2015年以开源为主基调,并经常举办相关活动鼓励开发者使用和改进其Llama系列模型。据统计,目前Hugging face平台上使用Llama 2开源协议的LLM已经超过了1500个。
 图片参考网址:https://huggingface.co/Riiid/sheep-duck-llama-2
图片参考网址:https://huggingface.co/Riiid/sheep-duck-llama-2
尽管大模型如雨后春笋般涌现,但在性能上,多数模型与OpenAI的GPT-4存在显著差距。近期AgentBench测试显示,GPT-4以4.41分位列首位,而第二名的Claude得分为2.77分。很多声名狭闻的开源LLM的测试成绩仅为GPT-4的1/4左右。这种差距主要归因于OpenAI拥有高质量的研究团队和长期的研究经验。换言之,大模型的真正竞争力并非只在于其参数规模,而在于其背后的开源生态建设与出色的推理性能(闭源模型)
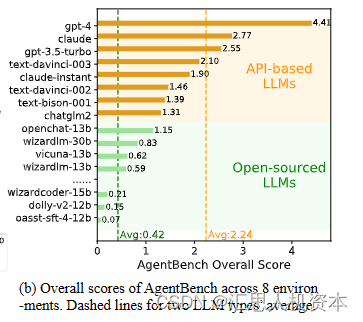
图片参考论文:https://arxiv.org/abs/2308.03688v1
预期随着开源社区的活跃化,大模型的性能可能会逐渐趋同。但目前,除少数如Midjourney外,大模型盈利的困难仍是一个现实问题。
AI行业成本失衡,大模型供应商前路难
近日,一篇关于“OpenAI可能在2024年底破产”的文章引起了公众的热议。文章指出,OpenAI在发展ChatGPT之后的亏损速度呈现明显上升。2022年,该公司亏损达到5.4亿美元,期望微软等投资者为其买单。此新闻反映了大模型提供商所面临的核心问题:成本与收益的巨大失衡。
高AI运营成本让多数公司难盈利,仅英伟达、博通等为例外。Omdia数据显示,尽管英伟达二季度销售了30万块H100芯片且市场热需,但AI投资远超收入,存在1250亿美元缺口。即便行业巨头微软和Adobe也承受压力:微软的AI编程工具GitHub Copilot由于高额的运行成本,每月要倒贴每个用户20美元至80美元;此外,Adobe也同样如此,因此Adobe推出积分制度,对超额使用的Firefly AI用户限速。
虽然大模型如ChatGPT推进了AI革命,其真实价值仍受质疑。面对同质竞争和众多开源模型,大模型供应商将遭遇更大考验。
关于企元大数据
广州企元大数据科技有限公司,专注于人工智能企业应用,为企业提供内部专属的人工智能模型开发、生成式AI开发以及全面的人工智能咨询服务。我们的产品 AIW全智通,凭借其独特的认知引擎,不仅为中小企业提供了经济、定制化的AI解决方案,还确保了其输出的可管理性与准确性,完全满足企业的业务策略和道德规范。AIW开发底座版(AI PaaS),利用核心的封装式AI模块化技术,为企业提供了与现有业务系统兼容的AI增强解决方案。它的模块化和标准化设计,以及为企业现有系统增加AI功能的能力,都使得企业可以低成本、高效率地进行数字化升级。

关于汇思人机资本
汇思软件(上海)有限公司(简称:Cyberwisdom Group)是一家领先的企业级人工智能、数字学习解决方案和人才持续专业发展管理提供商,基于一套平台、内容、技术和方法论构建,我们的服务包括学习管理系统(LMS)、企业人工智能管理平台、企业Metaverse设计、定制课件设计、现成的电子学习内容和数字化劳动力业务流程外包管理。
汇思在香港、广州、深圳、上海、北京、中山、新加坡和吉隆坡均设有分支机构,汇思超过 200人强大研发团队,拥有自主研发的一系列企业级人才发展学习方案,包括wizBank7.0学习管理系统以及企业全栈人工智能管理平台 TalentBot AI PAAS 2.0。作为领先的企业人工智能及人机发展解决方案供应商,汇思不仅提供平台技术,并且拥有亚太地区庞大的定制课程设计开发团队,超过2000门自主版权的通用课件,游戏化学习,学习支持与推广服务等。

汇思深度企业人工智能咨询 Deep Enterprise AI Consulting基于多年来的”人机发展“的成熟经验,深厚技术和影响力,团队的定位是给予”企业人机学习及发展无限的可能性。”
这篇关于大模型激增:真的需要这么多吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








