本文主要是介绍“活图”的时系列数据带通滤波器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
活图的带通滤波器
在分析时系列数据时,有时候为了从数据中找出有利于分析的结果,需要对数据进行解析,看其究竟和哪些因素有关,从而了解其趋向,尤其在科研实践中如此。对有可能是看起来杂乱无章的时域数据进行频域变换,然后再在频域进行处理,最终再将结果返回至时域。
“活图(中文版活图ver8.1现在是常州微识自动化科技有限公司产品之一http://www.microverify.com/col.jsp?id=114)”中针对时域处理有许多函数,包括FFT和FILTER等,其中FILTER函数自身已经包括FFT计算。笔者根据函数FILTER的性能,编制了普遍化应用的带通滤波器应用图“带通滤波器”,既可进行带通滤波也能进行单一频率滤波,本应用图在处理时系列数据时有一定的用途。
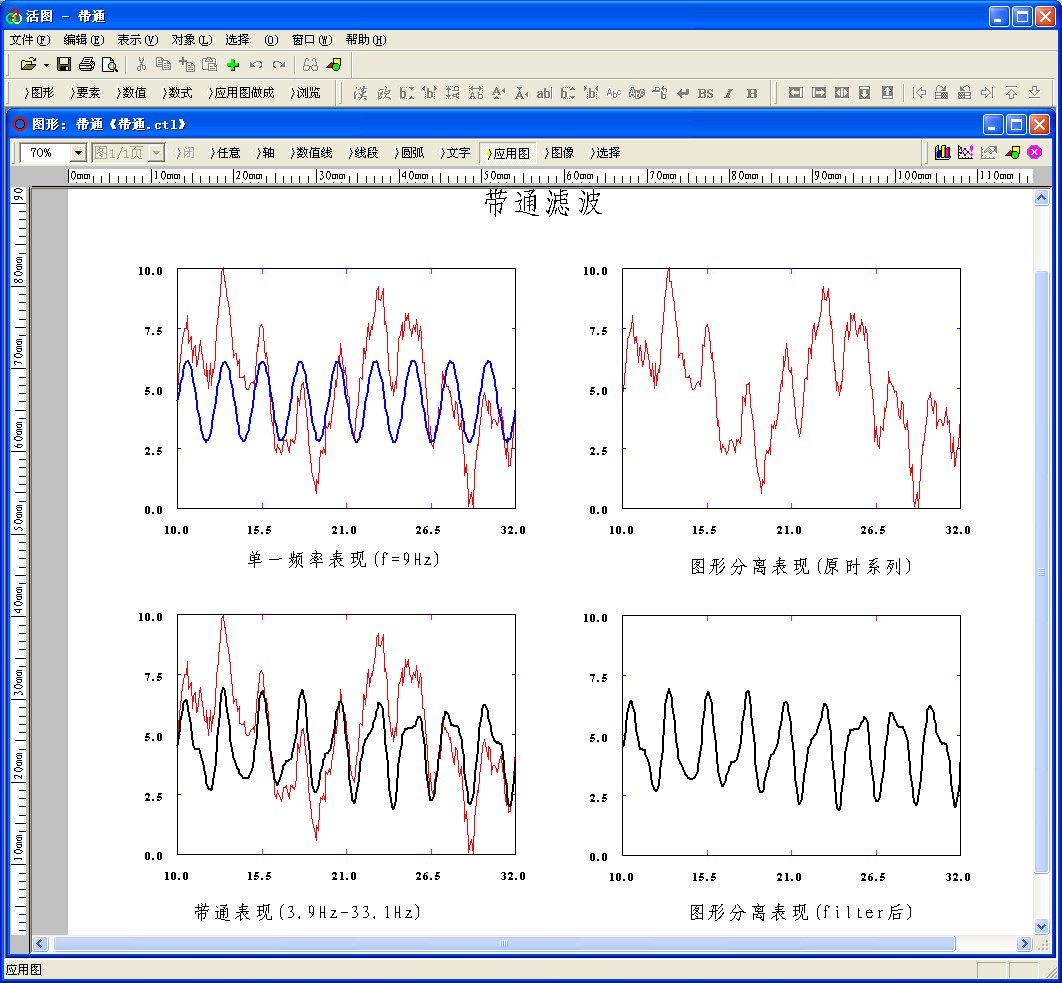
图1
图1是应用图“带通滤波器”的界面,该应用图共有37个输入参数,如图2所示。与函数相关的参数是参数4的输入时系列数据组编号,参数5的采样频率,参数6的0:带通1:单一,参数7的带通开始频率,参数8的带通终了频率和参数9的单一频率,其余的参数是图形表现的调整参数,如线的粗细,颜色等等,可根据实际情况自行调整。
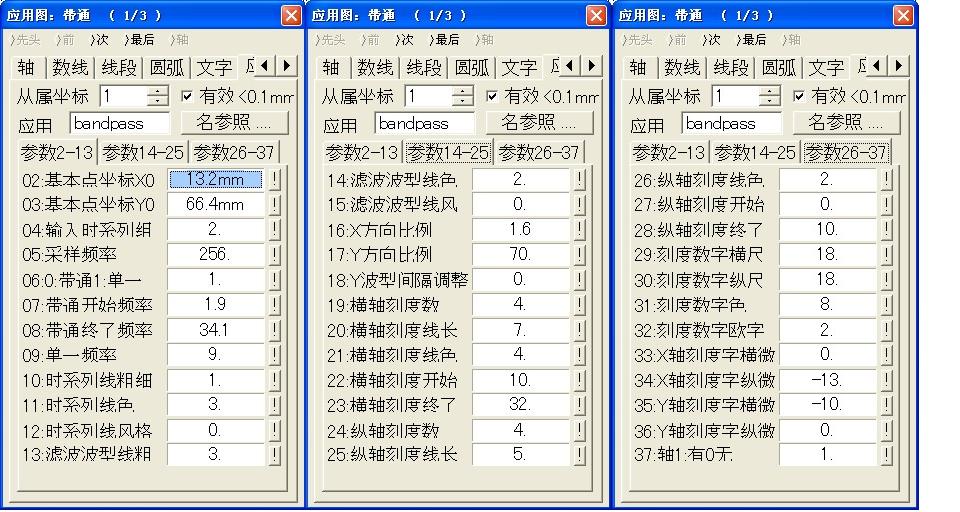
图2
实际应用时,将采样的时系列数据输入至活图的数据窗口内,给该数据组编上编号,将参数4赋值成这个编号就行;参数5是时系列数据的采样频率,将参数5赋值成该采样值就行;参数6是确定是进行带通滤波还是进行单一频率滤波选择参数,如果是进行带通滤波,就将参数6赋值成0,此时参数9不起作用,如果是进行单一频率滤波,就将参数6赋值成1就行,此时参数7和参数8不起作用;参数7是带通滤波时带通的起始频率;参数8是带通滤波时带通的终了频率,根据实际需要对这两个参数进行赋值;参数9是进行单一频率滤波时的指定要滤掉的频率值,赋值成该值就行。其余参数可按照图形的表现选择了,如喜好的刻度字库类型或进行刻度值位置微调整等等。
本应用图无需编程,只需将原始时系列数据组号带入既可,且图形表现灵活易变。
这篇关于“活图”的时系列数据带通滤波器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







