本文主要是介绍爬取软科-中国大学排行榜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取软科中国大学排行榜

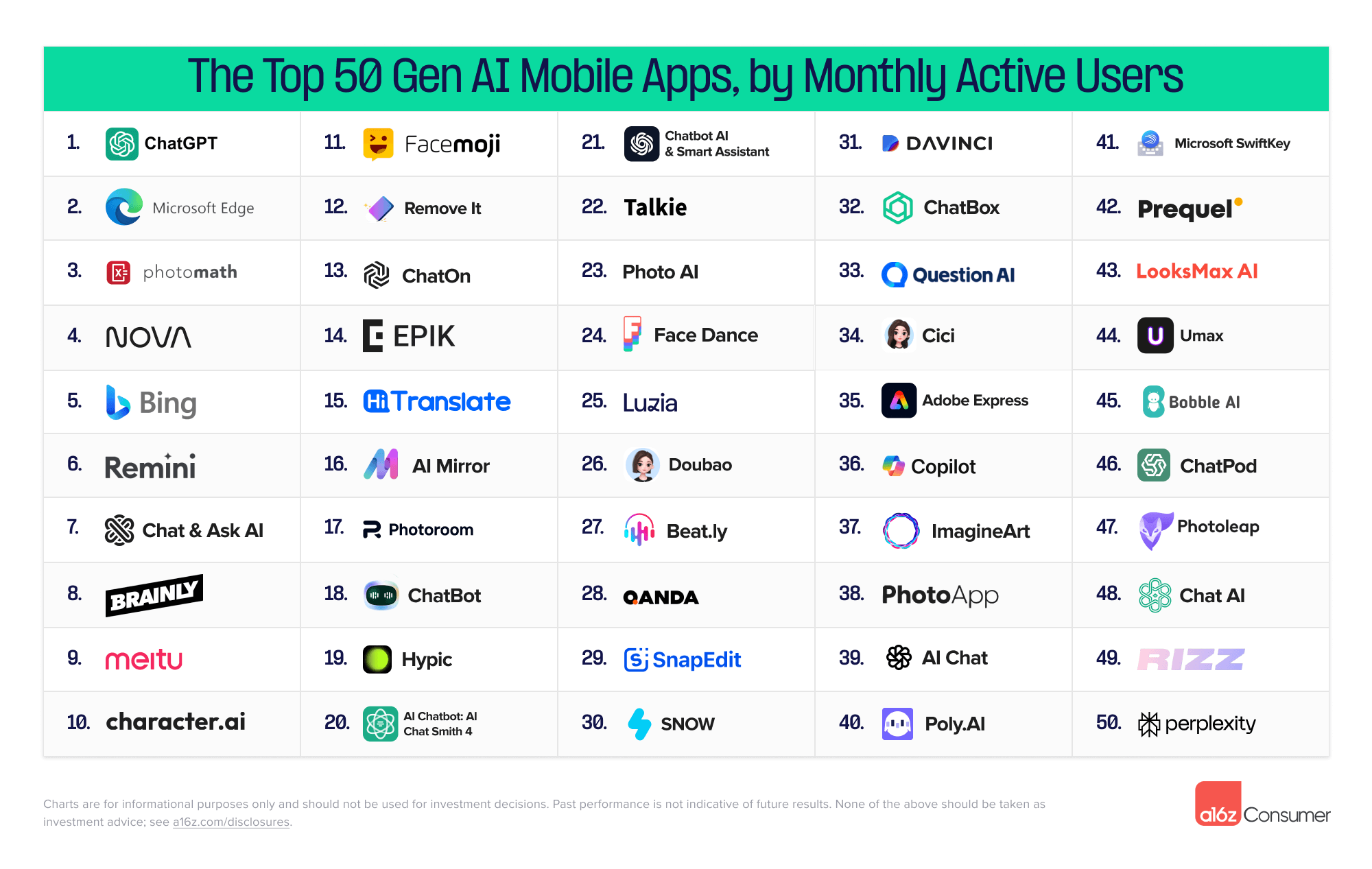
要求最后得到的文本爬取的格式如下

import requestsr=requests.get('http://www.shanghairanking.cn/rankings/bcur/2020')r.status_coder.encoding=r.apparent_encodingr.text
##输出展示文本
school=r.textfrom bs4 import BeautifulSoupsoup=BeautifulSoup(school,'html.parser')soup.tbodysoup.find_all('tbody')[0].find_all('tr')[0].find_all('td')[0].string.replace('\n','').replace(' ','')
##输出“1”
soup.find_all('tbody')[0].find_all('tr')[0].find_all('td')[1].a.string
##'清华大学'
soup.find_all('tbody')[0].find_all('tr')[0].find_all('td')[2].string.replace('\n','').replace(' ','')
##‘北京’
soup.find_all('tbody')[0].find_all('tr')[0].find_all('td')[3].string.replace('\n','').replace(' ','')
##‘综合’
soup.find_all('tbody')[0].find_all('tr')[0].find_all('td')[4].string.replace('\n','').replace(' ','')
##‘852.5’
soup.find_all('tbody')[0].find_all('tr')[0].find_all('td')[5].string.replace('\n','').replace(' ','')
##'38.2'
整理,利用for循环输出排名
for t in soup.find_all('tbody')[0].find_all('tr'):print(t.find_all('td')[0].string.replace('\n','').replace(' ',''),t.find_all('td')[1].a.string,t.find_all('td')[2].string.replace('\n','').replace(' ',''),t.find_all('td')[3].string.replace('\n','').replace(' ',''),t.find_all('td')[4].string.replace('\n','').replace(' ',''),t.find_all('td')[5].string.replace('\n','').replace(' ',''))

完成输出,具体导出呈txt或相关文件,可以看一下美团或者相亲的那个导出方法。
这篇关于爬取软科-中国大学排行榜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![[图]12大编程语言收入排行榜](/front/images/it_default.jpg)