本文主要是介绍2016“数据引领 飞粤云端”广东航空大数据创新大赛极客奖:Oh my god团队,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:2016“数据引领 飞粤云端”广东航空大数据创新大赛,由广东省人民政府和阿里巴巴集团联合主办,旨在提高全社会对大数据价值的认识,培养大数据应用人才,鼓励数据创新创业实践,推动航空大数据技术成果转化和落地。本文整理自本次大赛极客奖获奖团队Oh my god的现场答辩。
本文整理自获得2016“数据引领 飞粤云端”广东航空大数据创新大赛获得极客奖的Oh my god团队的答辩视频。Oh my god团队中的三名成员都是西安电子科技大学研二的学生,同时也都是数据挖掘的爱好者,以下为团队简介:

Oh my god团队的答辩中主要围绕了以下四个方面:
正如赛题介绍中所描述的,对于机场客流量的预测其实是非常有意义的。而本次大赛为比赛团队提供了白云机场两个月的数据记录,包括WIFI连接记录、安检记录以及航班排班表等数据信息,并要求对于未来两个整天,也就是11月11号以及11月12号每个WIFI点10分钟内的平均设备的数量进行预测,测评的公式如下图所示。
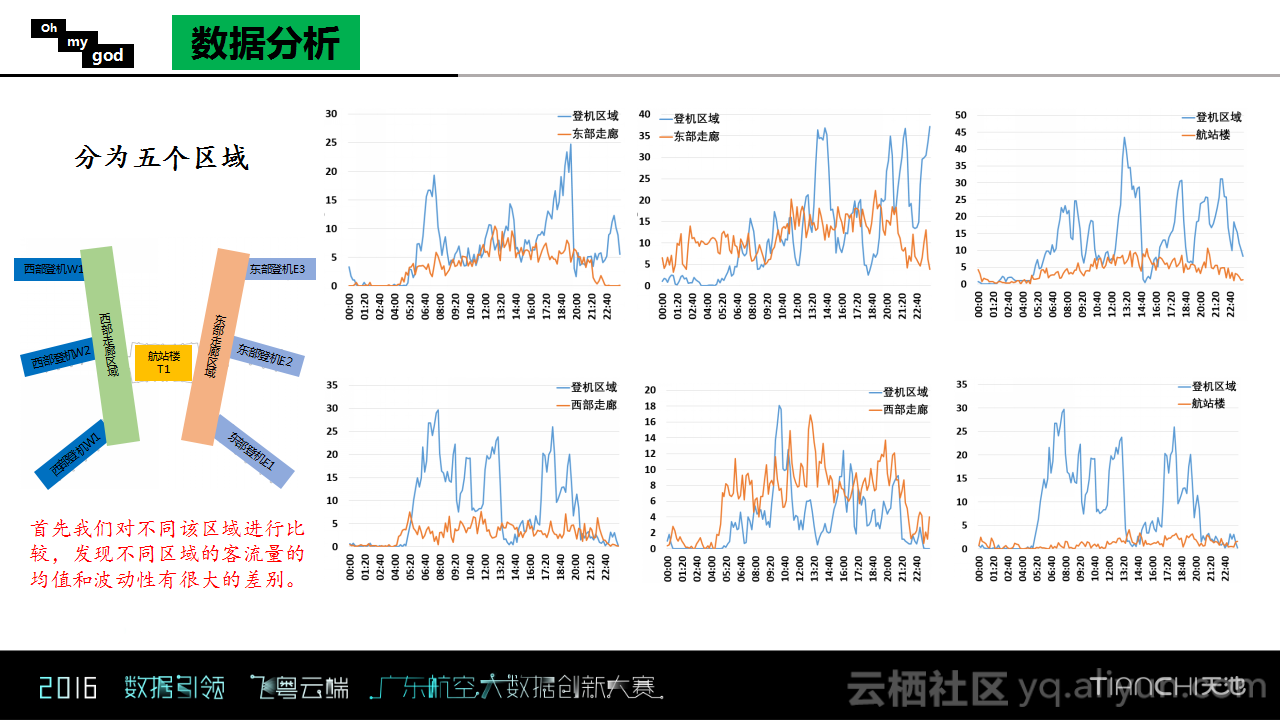
在数据分析阶段,Oh my god团队将白云机场划分成了5个区域,分别是最中间的航站楼以及东西两边各有的两片登记区域,以及连接航站楼和登机区域的两片走廊。对于这些区域进行简单的可视化分析发现不同区域的客流量的均值和波动性存在很大的差别,登机区域的客流量波动是比较大的,同时业务量也是比较大的;相比而言,航站楼区域和走廊区域的客流量就比较稳定,并且Oh my god团队对此提供了数据统计来支撑这一观点。
白云机场的登机区域具有大业务量、大波动的特点,这是预测的难点和重点,所以Oh my god团队对这个区域进行了单独的分析和建模。他们在进行数据分析时也尝试着使用历史的统计量对WIFI的接入量进行了拟合,并发现历史统计量是非常有意义的,其对于某一个WIFI在某一时间点的平均水平有非常好的把握,但是对于登机区域WIFI的波动却不能很好地拟合。

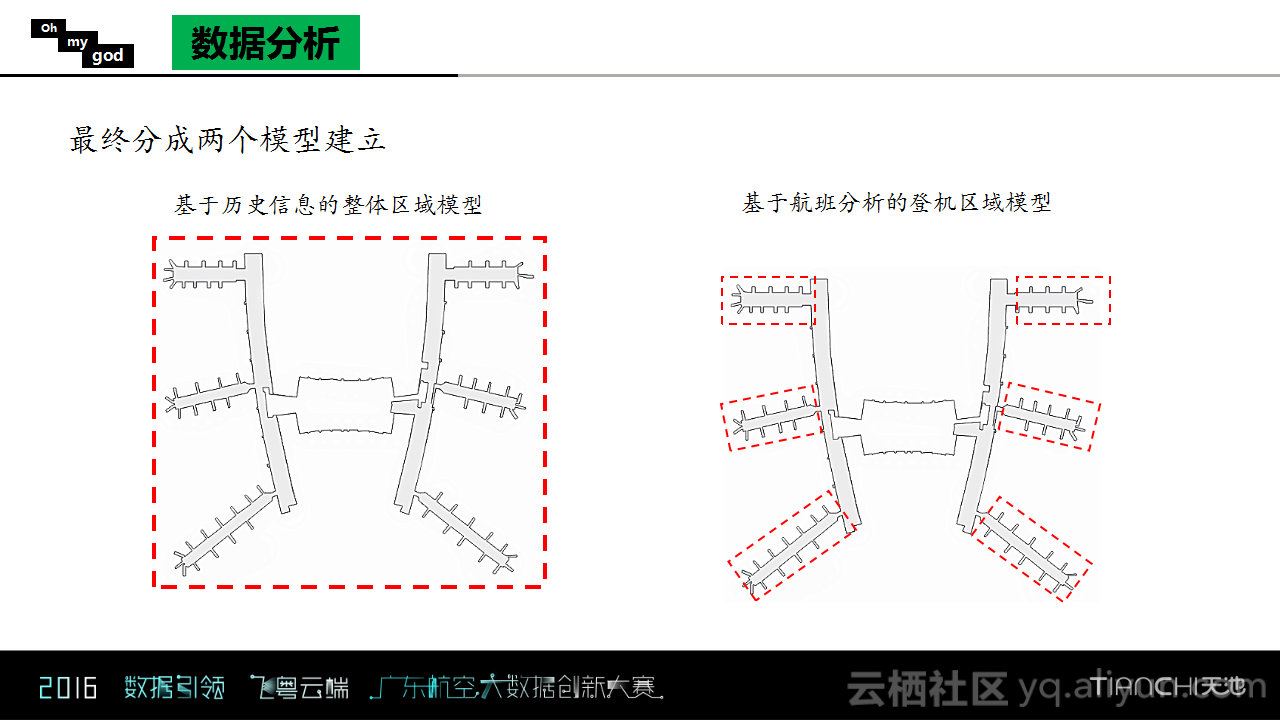
根据以上的分析,Oh my god团队构建了两个主要模型。一个是基于历史信息的整体区域模型,另一个是基于航班分析的登机区域模型。
解决方案
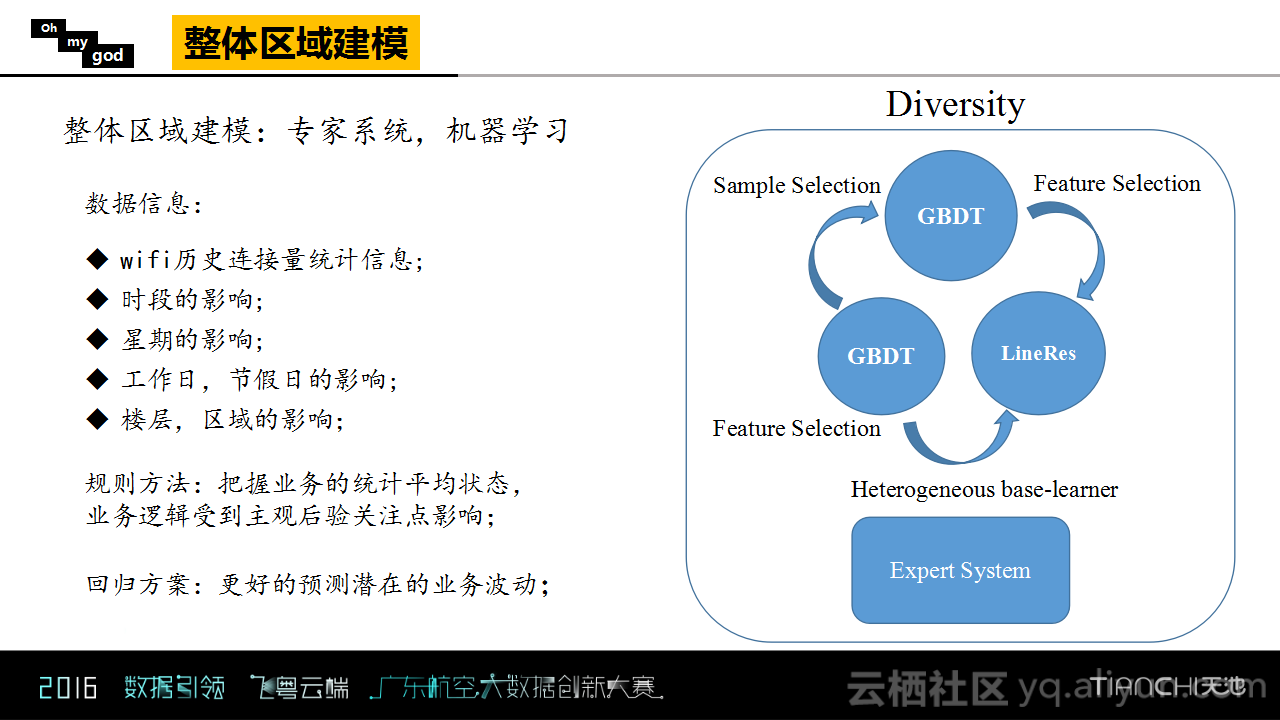
Oh my god团队首先对于整体区域进行建模,这部分使用了两种方法进行,一种是专家系统,也就是规则方法,另外一种是机器学习方法。Oh my god团队在进行数据分析时考虑了以下的影响因素,首先是WIFI历史连接量的统计信息,这个统计信息对于平均量的把握是非常有意义的,而且因为预测的是每十分钟的接入量,所以时段的影响也必须要考虑,除此之外还考虑了星期、节假日以及楼层区域的影响,加上数据信息以及对于业务的理解就构建了这样的一个专家系统。并且基于这些信息,提取了特征并且构建了机器学习方法,而且该模型使用的机器学习方法包含了两种,一种是GBDT,另外一种则是线性回归。最后,将规则结果以及机器学习的结果进行了融合,得到最终整体区域建模的结果。
接下来,介绍建模中使用的规则方法。如何通过历史统计量进行合理地预测呢?Oh my god团队认为这需要依赖于背后的业务逻辑,并且他们根据数据分析得到了如下图所示的一些业务逻辑。
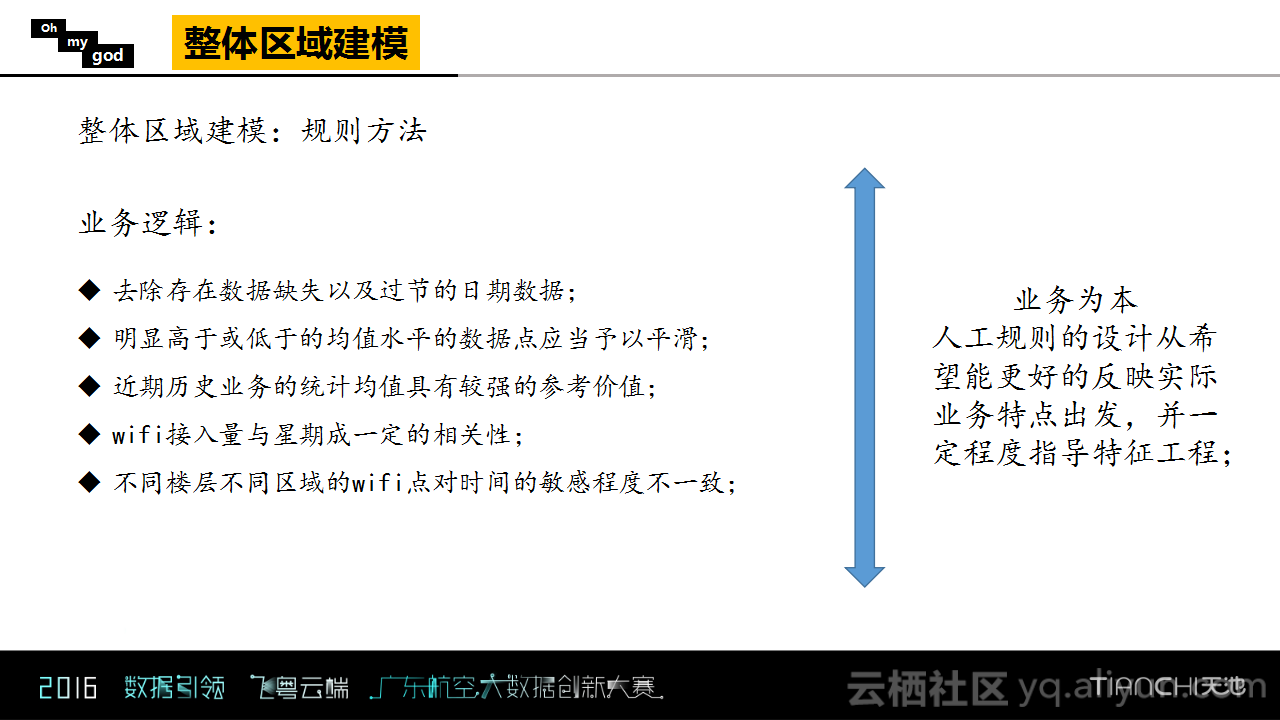
业务逻辑中的前两条其实可以看做是数据预处理的过程,也就是除去一些业务缺失以及节假日的时间点,因为需要预测的两天不是节假日,所以像国庆节这样日期的数据对于分析的干扰是比较大的,必须要去除的。除此之外,在模型中还做了平滑来去除异常点的影响。对于第三点,近期历史业务的统计均值是具有较强的参考价值的,也就是说离预测时间越近,数据的统计和参考意义就越强。
对于星期的相关性而言,需要预测的两天11号和12号分别是周五和周六,一般而言这两天的业务量会比较大,所以星期的影响也必须要考虑进去。最后一点是不同楼层,不同区域的WIFI点对于时间的敏感程度不一致,这一点无论是通过线上测试还是天池对于成绩的反馈都给出一个感觉:3楼业务量大,波动也大,对于时间的敏感程度也比较高,所以在进行分析时,时间跨度取得短一些比较好;而1,2楼业务量比较稳定,所以时间跨度可以取长一些。Oh my god团队的模型就是基于以上的这些业务逻辑来做的,换句话说也就是以业务为本的。

接下来,Oh my god团队介绍了他们所使用到的机器学习方法。首先,他们使用了特征工程,将WIFI的ID、所处的时段、楼层区域等进行了one-hat编码作为一个特征,并且做了一些统计量,前1,3,5,7,14天对应十分钟,对应小时统计信息以及星期、区域的统计信息作为相应的特征,并且统计了WIFI的接入量及方差排名特征。而且为了表现不同特征之间的交互信息还做了交叉特征。
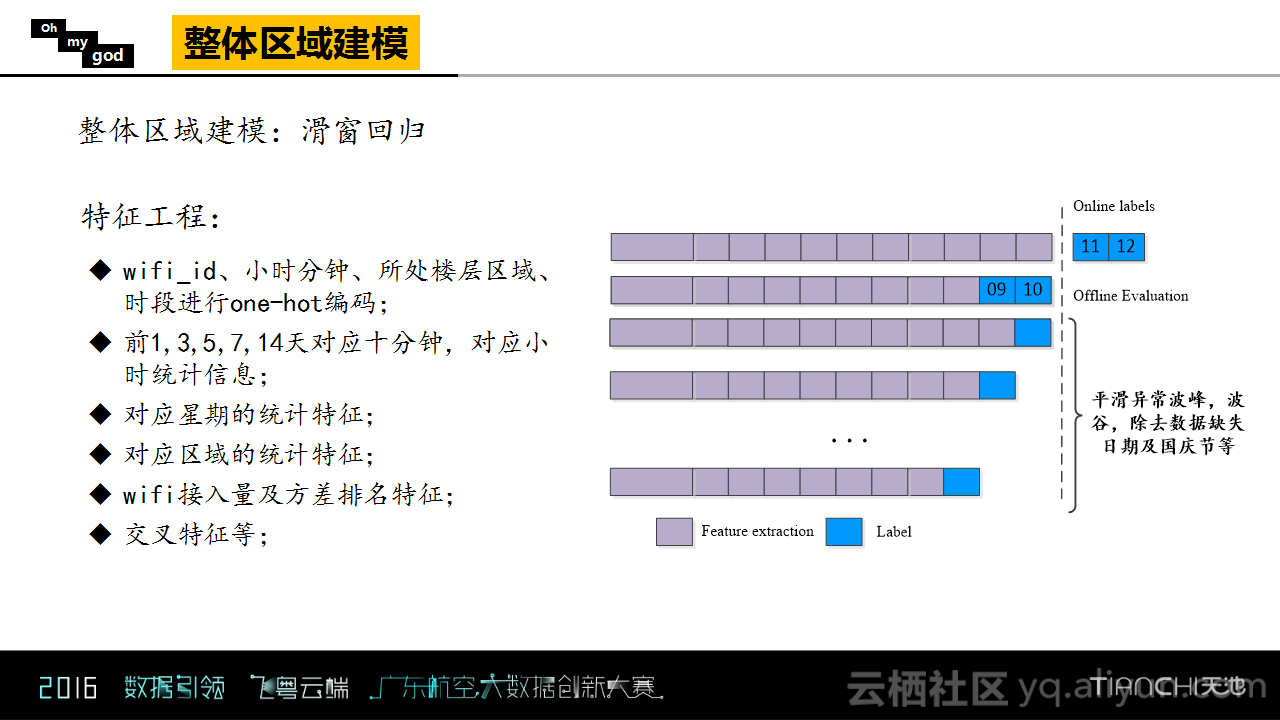
因为要预测11月11号和12号的信息,为了保证时效性,Oh my god团队选取了9号和10号的数据作为测试集,而使用之前的时间段作为序列集,并且在提取特征的时候使用了滑动窗口的方式。而在提取特征之前的数据预处理也是非常重要的,值得强调的一点是训练集的选择也是非常重要的,虽然需要预测的两天是周五和周六,但是与之前的周五、周六相比,这两天的业务量没有那么大,所以在选择的时候需要保证训练集和线上测试集的一致性。
划分完数据集、做完特征工程之后,Oh my god团队使用了GBDT和线性回归来进行预测,并结合刚才所提到的规则方法,将结果进行融合并作为整体区域建模的最终结果。
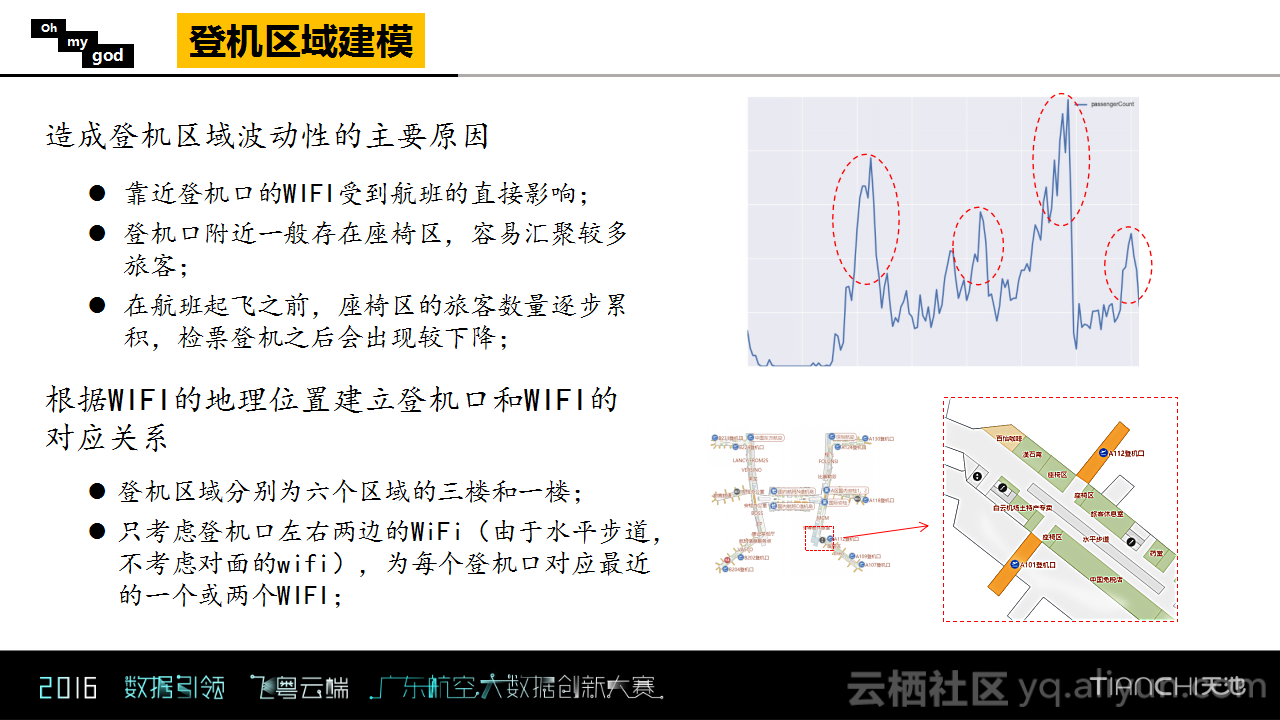
登机口区域的业务量比较大,其波动也比较大,所以对其进行了单独的分析建模,而这里分析的重点就是要找出隐藏在这些波动背后的原因究竟是什么。其实登机口区域有很多的休息座椅区,一般情况下,乘客都是根据航班起飞的时间提前到达登机口区域进行候机的,所以候机口在飞机起飞前非常容易汇集乘客。根据以上的分析以及WIFI坐标点信息,Oh my god团队对于登机口以及WIFI进行了对应,再基于航班的信息表提取了相应的特征,并且使用GDBT进行回归分析。
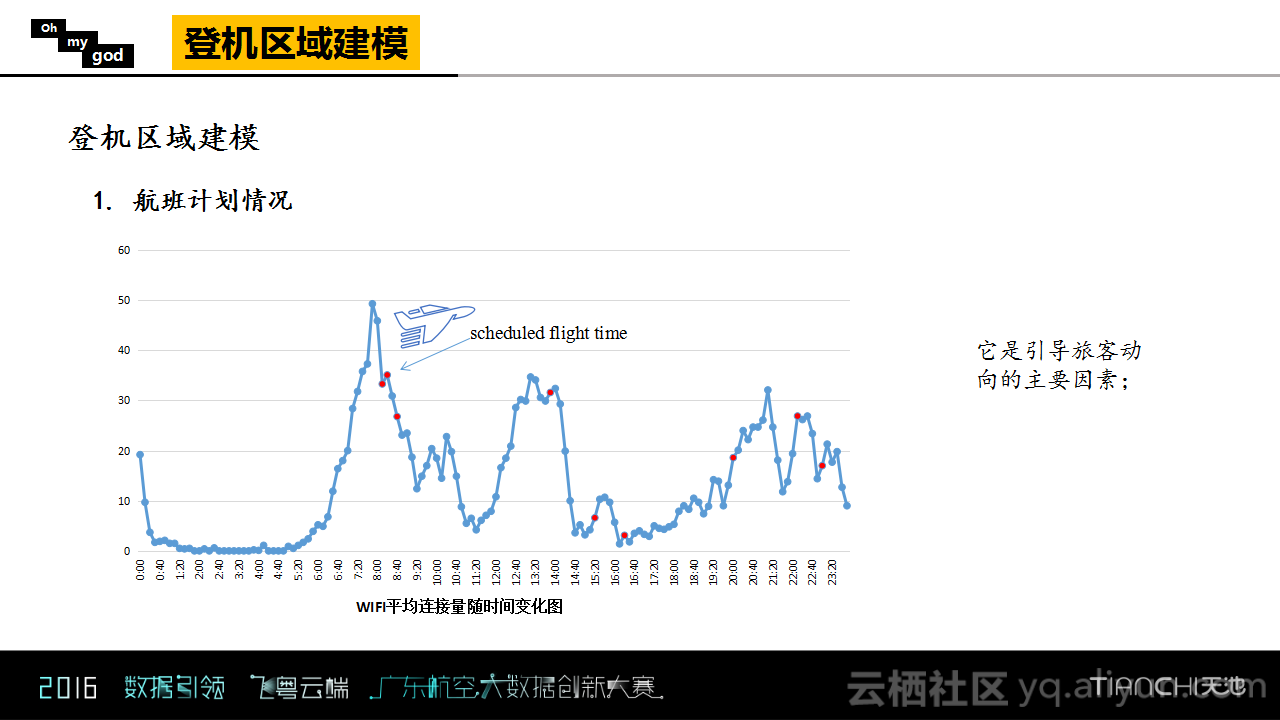
下图是某一个WIFI点在某天平均接入量的连接图,图上红色点就是航班的起飞时间,可以明显看出,在航班起飞之前有业务量上涨的情况出现,并且其范围的确是有限的,而且对于前面不同时间点的影响是不一样的。
WIFI的连入量与航班起飞的不同时间关系对应着不同的影响因子。Oh my god团队从大量的历史数据中统计出乘客的登机习惯,发现大多数乘客会选择在飞机起飞前50到100分钟内通过安检并进行候机,因为客流量是累计的过程,所以这里应该考虑累计率。一般情况下,乘客经过安检以后会直接去登机口候机,所以可以认为对于安检习惯统计出来的比例是起飞时间对应前面时段不同时间的影响因子的。
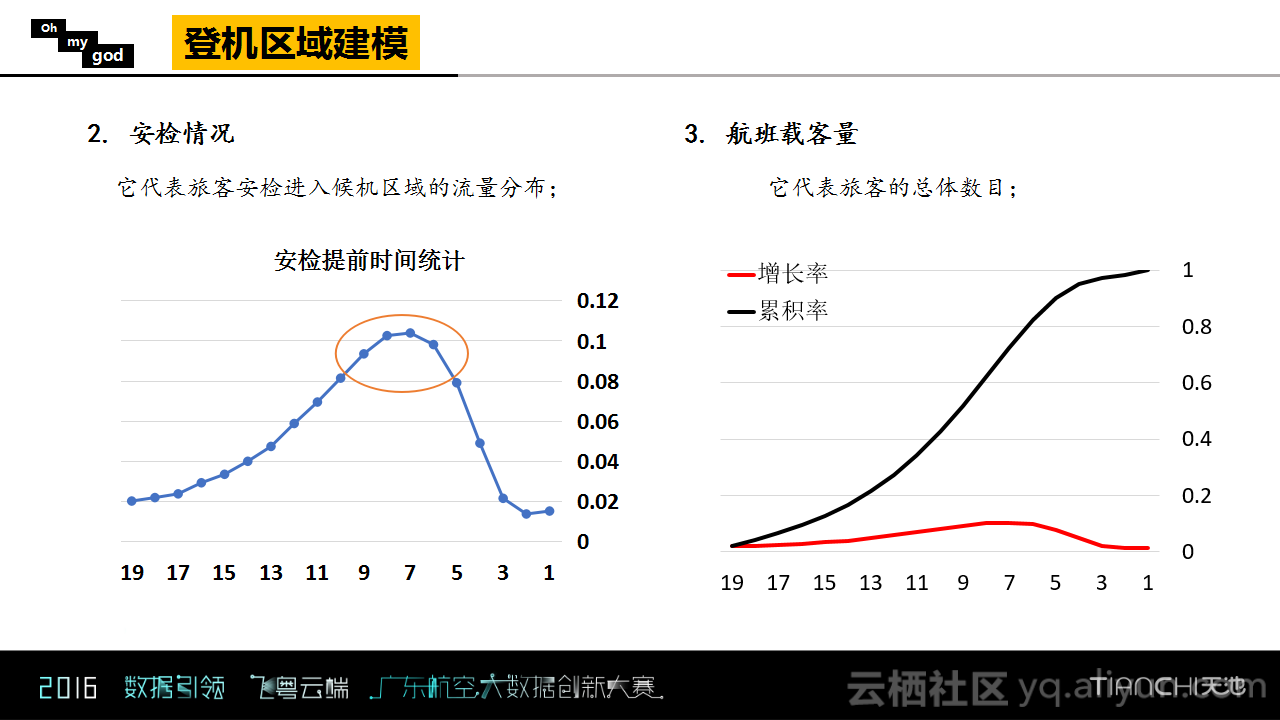
除此之外,建模中还考虑了航班载客量的影响因素。其实在提取特征时是将航班的载客量以及影响因子一起考虑的,也就是假设某一个登机口处在后3小时内有两架航班要起飞,下图中的时间点2就是表示同时受到了两架航班的影响,所以会存在叠加的效果。
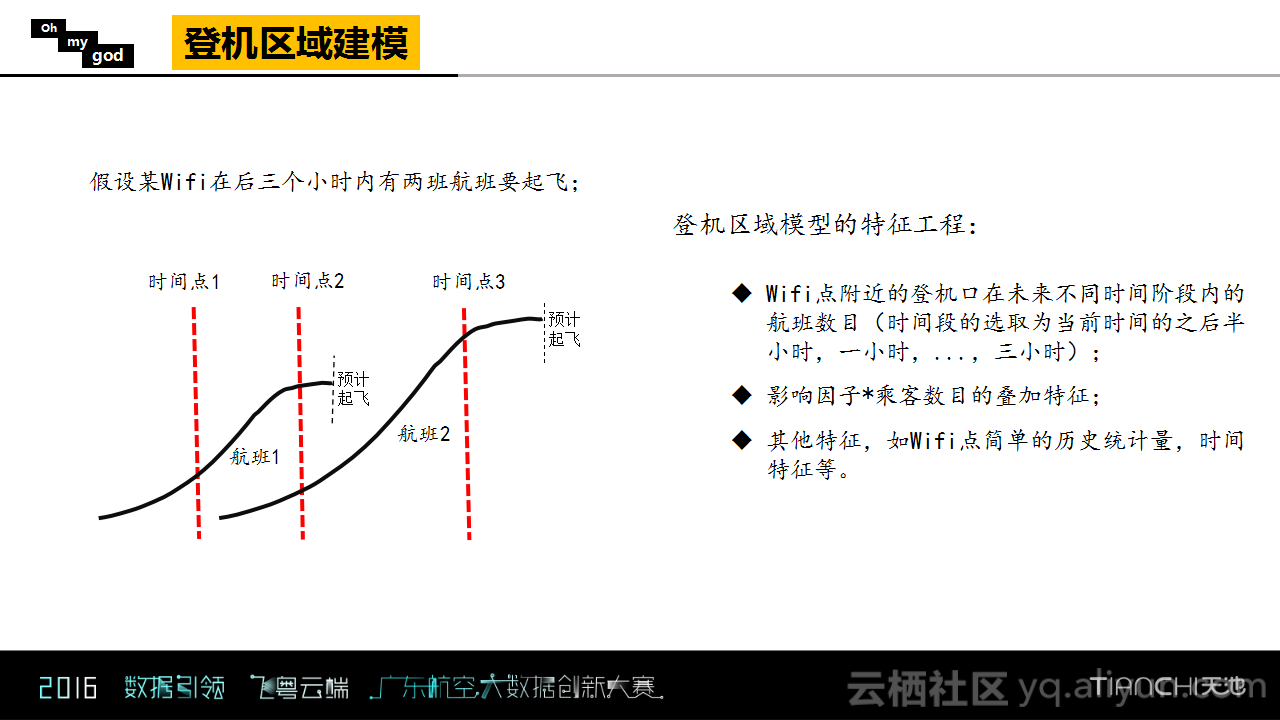
对于特征工程而言,以3个小时作为时间跨度,每半个小时为粒度,统计了WIFI点附近登机口在未来不同时间段内的航班数目以及不同航班的乘客数目,根据乘客数目以及影响因子做了叠加的特征。除了以上两点之外,还使用了历史统计量等其他特征。在特征工程建立完成之后,Oh my god团队使用了GBDT对这一部分进行了回归,并完成了登机区域的建模。
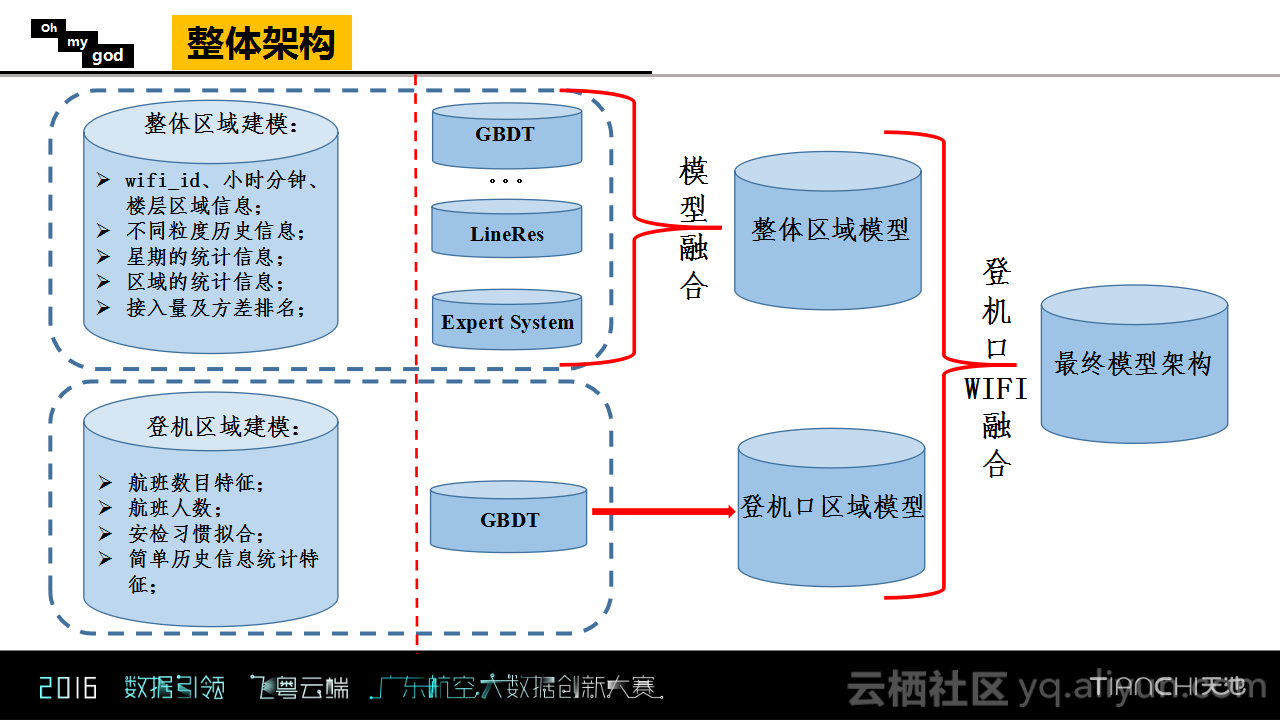
总而言之,在整体架构上而言,就是将问题模型的构建分成了两部分。一部分是整体建模,另一部分是对于登机区域进行建模,对于整体进行建模考虑的是历史统计信息以及对于业务逻辑的理解,构建了专家系统和机器学习方法,将预测结果进行了融合作为最终整体区域建模的结果;对于登机区域而言,则考虑了安检信息和航班信息进行建模。Oh my god团队认为自己的方法优势在于整体区域建模能够比较好地把握WIFI点在某一个时间点的平均水平,而登机区域建模能够比较好地利用登机信息以及乘客的登机习惯对于登机口区域WIFI的波动做出比较好的拟合,两个模型结合起来可以进行优势互补,起到比较好的结果。
赛后总结
Oh my god团队谈到在经过了整个比赛,团队和成员都收获了很多,也得到了成长,并且也对于真实的业务数据有了更好的理解。他们感触比较深的就是充分认识到了业务的重要性,好的方法来源于对数据的分析和对于业务的理解,构造特征的过程就是刻画业务的过程。而在团队合作中也体会到了责任与担当,同时,Oh my god团队还谈到要感谢天池大数据平台和白云机场给了他们接触真实业务的机会,并且希望天池大数据平台能够越来越好。
本文整理自获得2016“数据引领 飞粤云端”广东航空大数据创新大赛获得极客奖的Oh my god团队的答辩视频。Oh my god团队中的三名成员都是西安电子科技大学研二的学生,同时也都是数据挖掘的爱好者,以下为团队简介:
- 赛题背景
- 数据分析
- 解决方案
- 赛后总结
正如赛题介绍中所描述的,对于机场客流量的预测其实是非常有意义的。而本次大赛为比赛团队提供了白云机场两个月的数据记录,包括WIFI连接记录、安检记录以及航班排班表等数据信息,并要求对于未来两个整天,也就是11月11号以及11月12号每个WIFI点10分钟内的平均设备的数量进行预测,测评的公式如下图所示。

在数据分析阶段,Oh my god团队将白云机场划分成了5个区域,分别是最中间的航站楼以及东西两边各有的两片登记区域,以及连接航站楼和登机区域的两片走廊。对于这些区域进行简单的可视化分析发现不同区域的客流量的均值和波动性存在很大的差别,登机区域的客流量波动是比较大的,同时业务量也是比较大的;相比而言,航站楼区域和走廊区域的客流量就比较稳定,并且Oh my god团队对此提供了数据统计来支撑这一观点。
Oh my god团队首先对于整体区域进行建模,这部分使用了两种方法进行,一种是专家系统,也就是规则方法,另外一种是机器学习方法。Oh my god团队在进行数据分析时考虑了以下的影响因素,首先是WIFI历史连接量的统计信息,这个统计信息对于平均量的把握是非常有意义的,而且因为预测的是每十分钟的接入量,所以时段的影响也必须要考虑,除此之外还考虑了星期、节假日以及楼层区域的影响,加上数据信息以及对于业务的理解就构建了这样的一个专家系统。并且基于这些信息,提取了特征并且构建了机器学习方法,而且该模型使用的机器学习方法包含了两种,一种是GBDT,另外一种则是线性回归。最后,将规则结果以及机器学习的结果进行了融合,得到最终整体区域建模的结果。
对于星期的相关性而言,需要预测的两天11号和12号分别是周五和周六,一般而言这两天的业务量会比较大,所以星期的影响也必须要考虑进去。最后一点是不同楼层,不同区域的WIFI点对于时间的敏感程度不一致,这一点无论是通过线上测试还是天池对于成绩的反馈都给出一个感觉:3楼业务量大,波动也大,对于时间的敏感程度也比较高,所以在进行分析时,时间跨度取得短一些比较好;而1,2楼业务量比较稳定,所以时间跨度可以取长一些。Oh my god团队的模型就是基于以上的这些业务逻辑来做的,换句话说也就是以业务为本的。
划分完数据集、做完特征工程之后,Oh my god团队使用了GBDT和线性回归来进行预测,并结合刚才所提到的规则方法,将结果进行融合并作为整体区域建模的最终结果。
登机口区域的业务量比较大,其波动也比较大,所以对其进行了单独的分析建模,而这里分析的重点就是要找出隐藏在这些波动背后的原因究竟是什么。其实登机口区域有很多的休息座椅区,一般情况下,乘客都是根据航班起飞的时间提前到达登机口区域进行候机的,所以候机口在飞机起飞前非常容易汇集乘客。根据以上的分析以及WIFI坐标点信息,Oh my god团队对于登机口以及WIFI进行了对应,再基于航班的信息表提取了相应的特征,并且使用GDBT进行回归分析。
赛后总结
Oh my god团队谈到在经过了整个比赛,团队和成员都收获了很多,也得到了成长,并且也对于真实的业务数据有了更好的理解。他们感触比较深的就是充分认识到了业务的重要性,好的方法来源于对数据的分析和对于业务的理解,构造特征的过程就是刻画业务的过程。而在团队合作中也体会到了责任与担当,同时,Oh my god团队还谈到要感谢天池大数据平台和白云机场给了他们接触真实业务的机会,并且希望天池大数据平台能够越来越好。
这篇关于2016“数据引领 飞粤云端”广东航空大数据创新大赛极客奖:Oh my god团队的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





