本文主要是介绍【异步爬虫】圆我四大名著《西游记》之梦,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
名著《西游记》爬虫实战
- 前言
- 1. 获取所有章节cid
- 2. 获取单个章节内容
- 3. 完整代码
前言
一直都想找个机会好好读读四大名著,今天我下载了 《西游记》 全部章节,一起开始阅读吧!
1. 获取所有章节cid
名著所在网址:https://dushu.baidu.com/pc/detail?gid=4306063500
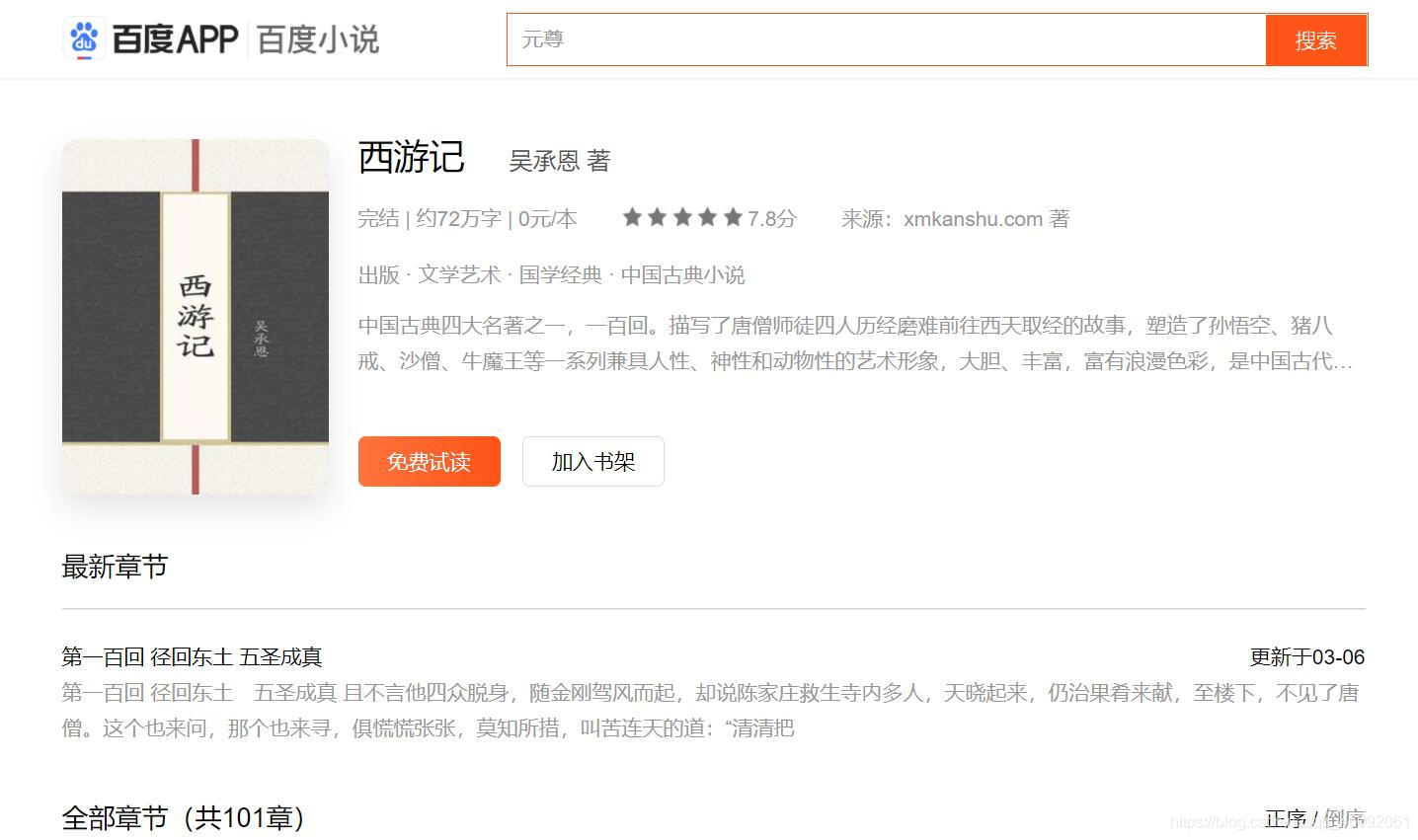
- 当我们检查网页源代码时,未发现章节信息,所以该数据可能是服务器二次发送的。
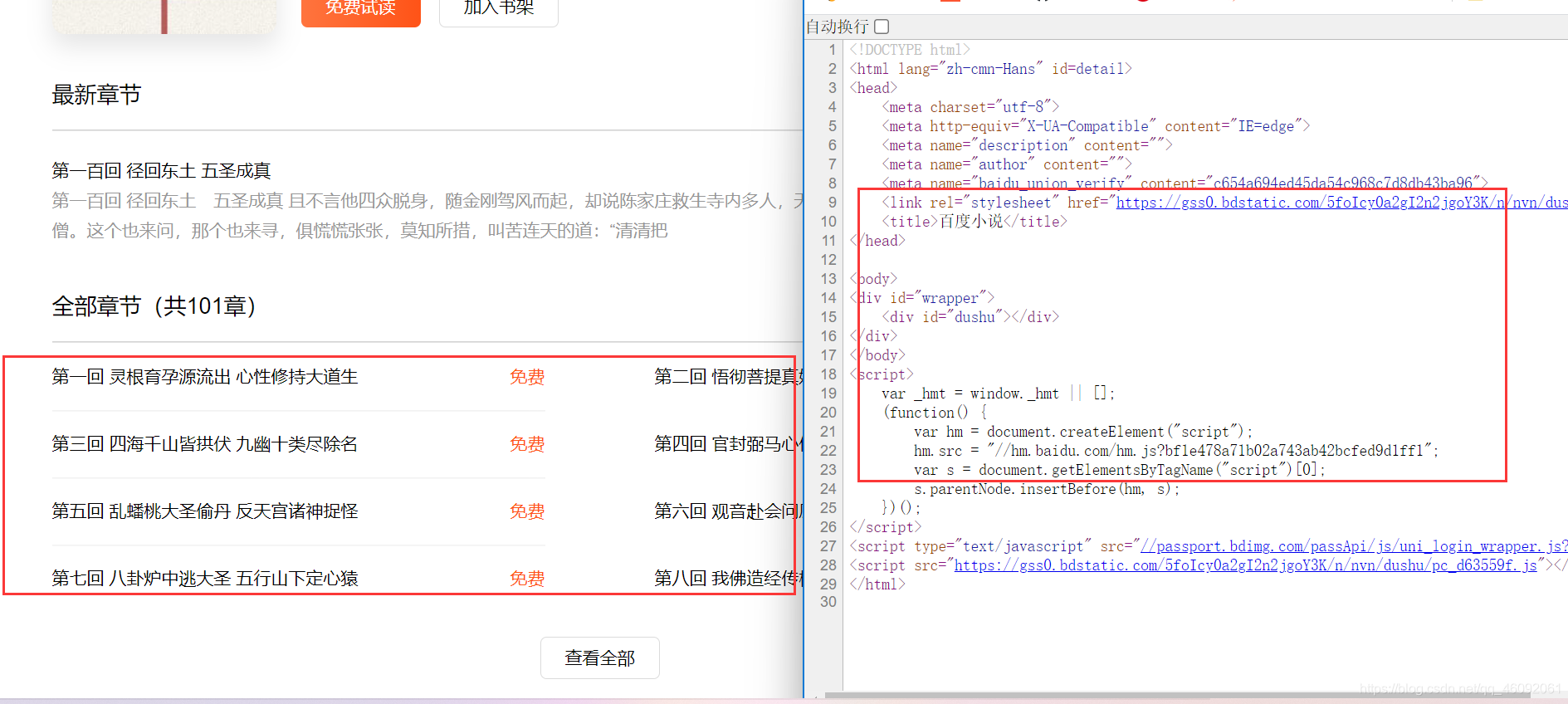
F12,打开开发者工具,Network,刷新进行Fetch/XHR数据抓包。
- 找到章节信息后,copy
URL,可以看到请求小说的章节数据与book_id有关

# 获取所有章节的cid
async def getCatalog(url):resp = requests.get(url)dict = resp.json()# 创建任务列表tasks = []for item in dict['data']['novel']['items']: # item就是对应每一个章节的名称和cidtitle = item['title']cid = item['cid']print(title, cid)tasks.append(aiodownload(book_id, cid, title))await asyncio.wait(tasks)
在这里用到异步协程,提高效率,方法前用async修饰,await,线程阻塞,释放CPU资源。
2. 获取单个章节内容
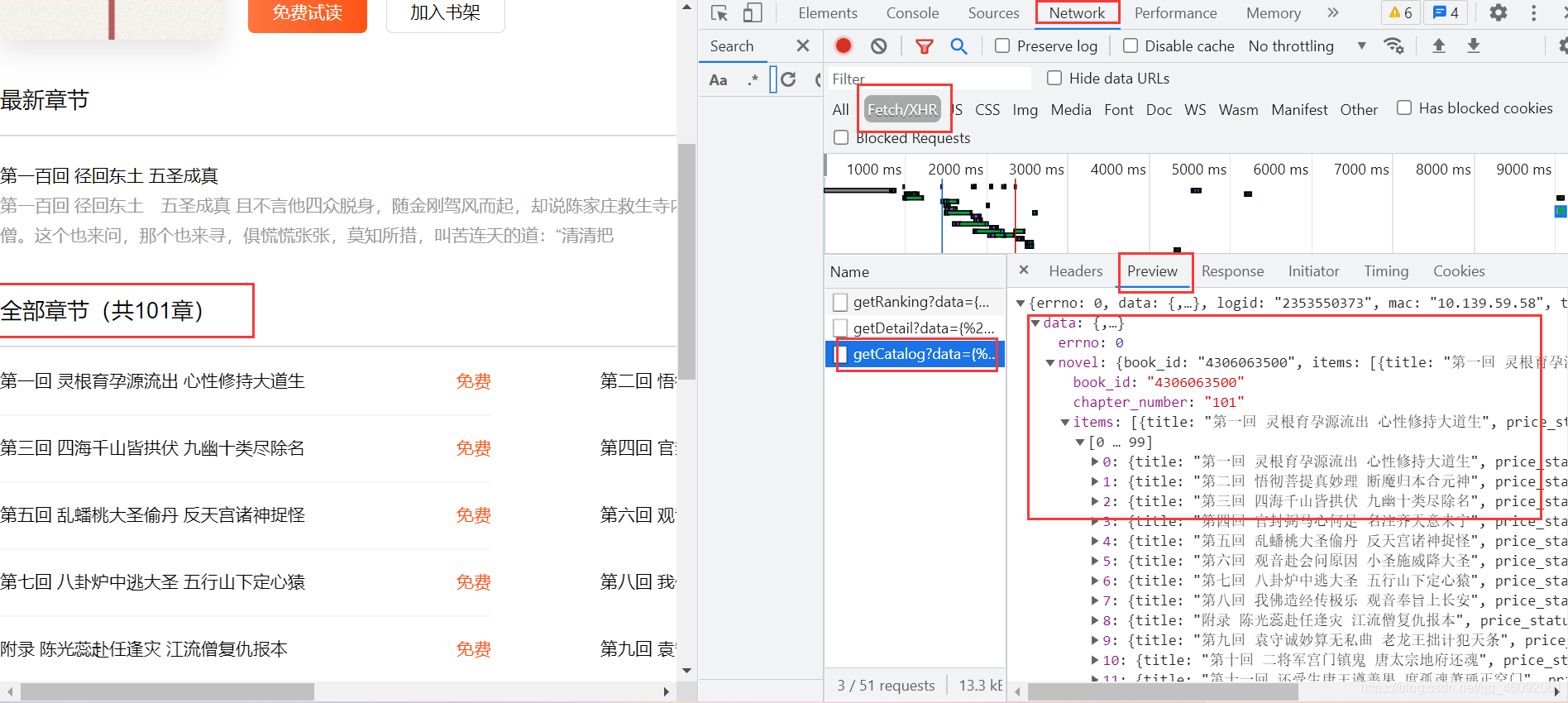
- 进入某一章节,进行分析,同样
F12,Network,数据抓包,进行缜密分析,终于找到文本内容。

- 进入
Headers,copyURL,获取requests.get().json()的数据。

# 准备异步任务
async def aiodownload(book_id, cid, title):data = {"book_id": book_id,"cid": f"{book_id}|{cid}","need_bookinfo": 1}# data需要为json()data = json.dumps(data)url = f"https://dushu.baidu.com/api/pc/getChapterContent?data={data}"# 获取协程请求对象async with aiohttp.ClientSession() as session: # requestsasync with session.get(url) as resp:dic = await resp.json() # 阻塞# 获取异步io文件流async with aiofiles.open('./novels/'+title+'.txt', mode='w', encoding='utf-8') as f:await f.write(dic['data']['novel']['content']) # 把小说内容写出print(title, '下载完成!')
3. 完整代码
# 小说url
# url = 'https://dushu.baidu.com/api"/pc/getCatalog?data:{"book_id":"4306063500"}' =>所有章节名称链接
# 章节内部内容url
# url = https://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500", "cid":"4306063500"|11348571","need_bookinfo":"1"}import requests
import asyncio
import aiohttp
import aiofiles
import json
"""
1. 同步操作,访问getCatalog 拿到所有章节的cid和名称
2. 异步操作,访问getChapterContent 下载所有的文章内容
"""# 准备异步任务
async def aiodownload(book_id, cid, title):data = {"book_id": book_id,"cid": f"{book_id}|{cid}","need_bookinfo": 1}# data需要为json()data = json.dumps(data)url = f"https://dushu.baidu.com/api/pc/getChapterContent?data={data}"# 获取协程请求对象async with aiohttp.ClientSession() as session: # requestsasync with session.get(url) as resp:dic = await resp.json() # 阻塞# 获取异步io文件流async with aiofiles.open('./novels/'+title+'.txt', mode='w', encoding='utf-8') as f:await f.write(dic['data']['novel']['content']) # 把小说内容写出print(title, '下载完成!')# 获取所有章节的cid
async def getCatalog(url):resp = requests.get(url)dict = resp.json()# 创建任务列表tasks = []for item in dict['data']['novel']['items']: # item就是对应每一个章节的名称和cidtitle = item['title']cid = item['cid']print(title, cid)tasks.append(aiodownload(book_id, cid, title))await asyncio.wait(tasks)if __name__ == '__main__':# book_idbook_id = "4306063500" # 西游记url = 'https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + book_id + '"}'# 启动协程asyncio.run(getCatalog(url))

加油!
感谢!
努力!
这篇关于【异步爬虫】圆我四大名著《西游记》之梦的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




