本文主要是介绍数据集笔记:杭州 上海 地铁客流数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据集地址:PVCGN/data at master · liuwj2000/PVCGN (github.com)
1 数据集介绍
- 从5:15到23:30的地铁乘客流量预测
- 使用前四个时间间隔(15分钟 x 4 = 60分钟)的地铁乘客流量(进/出流量)来预测未来四个时间间隔(15分钟 x 4 = 60分钟)的地铁乘客流量(进/出流量)
- 5:15-6:15 -- 预测 -> 6:15-7:15
- 5:30-6:30 -- 预测 -> 6:30-7:30
- ...
- 21:15-22:15 -- 预测 -> 22:15-23:15
- 21:30-22:30 -- 预测 -> 22:30-23:30
- 每天可以分为66个时间片段
- 使用前四个时间间隔(15分钟 x 4 = 60分钟)的地铁乘客流量(进/出流量)来预测未来四个时间间隔(15分钟 x 4 = 60分钟)的地铁乘客流量(进/出流量)
- 杭州和上海每个数据集,各有六个pkl文件
- 三个用于地铁乘客流量数据
- 一个训练集、一个验证集和一个测试集
- 三个用于地铁图信息
- graph_conn.pkl: 地铁的物理图
- graph_sml.pkl: 地铁的相似性图
- graph_conn.pkl: 地铁的相关图
- 三个用于地铁乘客流量数据
2 数据读取
2.1 流量数据
2.1.1 训练数据
import pickle
import os
os.chdir('data/shanghai/')f=open('train.pkl','rb')a=pickle.load(f)
a


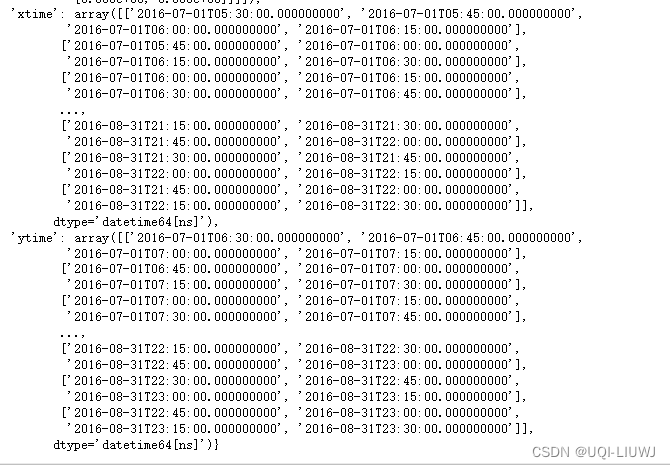
字符串5:30表示从5:15到5:30的时间间隔
a['x'].shape,a['y'].shape
#((4092, 4, 288, 2), (4092, 4, 288, 2))a['xtime'].shape,a['ytime'].shape
#((4092, 4), (4092, 4))- 可以看到,这个数据是一个由4个ndarray组成的字典
- x: 前四个时间间隔的地铁乘客流量(进/出流量)
- 其形状是[T, n, N, D]
- T是时间片段的数量(62天)
- n是输入序列的长度(这里是4)
- N是地铁站的数量
- D是 inflow 和 outflow,所以为2
- 其形状是[T, n, N, D]
- y: 下四个时间间隔的地铁乘客流量(进/出流量)
- 其形状也是[T, m, N, D]
- m是输入序列的长度(这里是4)
- 其形状也是[T, m, N, D]
- xtime: x的时间戳。其形状是[T, n]
- ytime: y的时间戳。其形状是[T, m]
- x: 前四个时间间隔的地铁乘客流量(进/出流量)
2.1.2 测试数据
import picklef=open('val.pkl','rb')a=pickle.load(f)
a['x'].shape,a['y'].shape,a['xtime'].shape,a['ytime'].shape
#((594, 4, 288, 2), (594, 4, 288, 2), (594, 4), (594, 4))2.1.3 训练数据
import picklef=open('test.pkl','rb')a=pickle.load(f)
a['x'].shape,a['y'].shape,a['xtime'].shape,a['ytime'].shape
#((1386, 4, 288, 2), (1386, 4, 288, 2), (1386, 4), (1386, 4))2.2 地图数据
2.2.1 地铁站的物理图
import picklef=open('graph_sh_conn.pkl','rb')a=pickle.load(f)
a,a.shape
'''
(array([[1., 1., 0., ..., 0., 0., 0.],[1., 1., 1., ..., 0., 0., 0.],[0., 1., 1., ..., 0., 0., 0.],...,[0., 0., 0., ..., 1., 1., 0.],[0., 0., 0., ..., 1., 1., 1.],[0., 0., 0., ..., 0., 1., 1.]]),(288, 288))
'''2.2.2 地铁站的相关图
import picklef=open('graph_sh_cor.pkl','rb')a=pickle.load(f)
a,a.shape
'''
(array([[0. , 0.01539433, 0.02738432, ..., 0. , 0. ,0. ],[0. , 0. , 0. , ..., 0. , 0. ,0. ],[0. , 0.01502989, 0. , ..., 0. , 0. ,0. ],...,[0. , 0. , 0. , ..., 0.01615014, 0. ,0.03536008],[0. , 0. , 0. , ..., 0. , 0.0092369 ,0. ],[0. , 0. , 0. , ..., 0.03341621, 0.00712248,0.01228689]]),(288, 288))
'''2.2.3 地铁站的相似性图
import picklef=open('graph_sh_sml.pkl','rb')a=pickle.load(f)
a,a.shape
'''
(array([[1. , 0. , 0.13627907, ..., 0. , 0. ,0. ],[0. , 1. , 0. , ..., 0. , 0. ,0. ],[0.13627907, 0. , 1. , ..., 0. , 0. ,0. ],...,[0. , 0. , 0. , ..., 1. , 0. ,0. ],[0. , 0. , 0. , ..., 0. , 1. ,0. ],[0. , 0. , 0. , ..., 0. , 0. ,1. ]]),(288, 288))
'''这篇关于数据集笔记:杭州 上海 地铁客流数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






