本文主要是介绍论文阅读《Modeling Semantic Compositionality with Sememe Knowledge》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读《Modeling Semantic Compositionality with Sememe Knowledge》——基于义素知识的语义组合性建模
文章目录
- 摘要
- 1 引言
- 2 用义原测量SC程度
- 2.1 基于义原的SCD计算公式
- 2.2 SCD计算公式的评估
- 3 义原整合SC模型
- 3.1 仅包含义原
- 3.2 加入组合规则
- 3.3 Training
- 4 实验
- 4.1 数据集
- 4.2 实验设置
- 4.3 MWE相似性计算
- 4.4 MWE义原预测
摘要
Semantic Compositionality(SC)是指一个复杂的语言单元可以由其组成成分的意思构成。大部分研究多采用复杂的组合函数对SC建模,没有考虑外部知识。本文通过一个验证性实验验证了人类语言最小语义单位义原(sememes)在SC建模中的有效性。在此基础上,我们首次尝试将义原知识整合到SC模型中,并将义原整合模型应用到SC的典型任务——多词表达multiword expression(MWE)。在实验中,我们结合了著名的义原知识库HowNet中的知识来实现我们的模型,并进行了内部和外部评估。实现结果表明,与不考虑义原知识的baseline相比,我们的模型取得了显著的性能提升。我们进一步进行了定量分析和案例研究,证明了义原知识在SC建模中的有效性。
1 引言
大多数关于SC的文献都关注于使用基于向量的语义分布模型来学习多次表达式MWE的表示,即短语或复合词的嵌入。这项任务的整体框架为: p = f ( w 1 , w 2 , R , K ) p = f(w_1,w_2,R,K) p=f(w1,w2,R,K) 其中,f式组合性函数,p表示MWE的嵌入,w1和w2表示MWE的两个成分的嵌入,R表示组合规则,K表示构造MWE语义所需的附加知识。
但目前大部分工作忽视了R和K。HowNet(知网)是一个广泛认可的义原知识库,它定义了约2000个义原,并用这些义原注释了10万多个中文单词及其英文译文。义原和知网已成功应用于各种自然语言处理任务,包括情感分析、词汇表征学习、语言建模等。
这篇文章首先假设义原对SC建模有效。为了证明这点,首先设计了一个简单的SC degree(SCD)测量实验,发现用基于简单义原的公式计算出的MWE的SCD与人类的判断高度相关。作者提出两个结合义原的SC模型来学习MWE的嵌入,即聚合义原语义组合性Semantic Compositionality with Aggregated Sememe(SCAS)模型和相互义原注意语义组合性Semantic Compositionality with Mutual Sememe Attention(SCMSA)模型。
2 用义原测量SC程度
2.1 基于义原的SCD计算公式

作者设计的SCD计算公式,如Table 1所示,共定义了四个SCD,分别用3,2,1,0表示,越大的数字表示越高的SCDs。Sp,Sw1,Sw2分别代表MWE的义原集合,它的第一个和第二个组成。(1)SCD 3,MWE的义原集等于两个成分义原集的结合,这意味着MWE的意义与两个成分的意义的结合是完全相同的。因此,MWE在语义上是完全复合的,应该具有更高的SCD。(2)SCD 0,MWE的义原与其成分完全不同,这意味着MWE的意义不能从成分的意义中派生出来。因此,MWE是完全非组合的,它的SCD应该是最低的。
2.2 SCD计算公式的评估
作者构建了一个人工注释的SCD数据集用于评估。评估了基于义原规则计算的数据集中的MWE的SCD与人工给出的SCD之间的相关性。Pearson相关系数达到0.75,Spearman秩相关系数为0.74。
3 义原整合SC模型
SCAS模型简单地将MWE成分及其义原的embedding连接起来,而SCMSA模型则考虑了一个成分的义原与另一个成分的义原之间的attention。
3.1 仅包含义原
1. SCAS Model
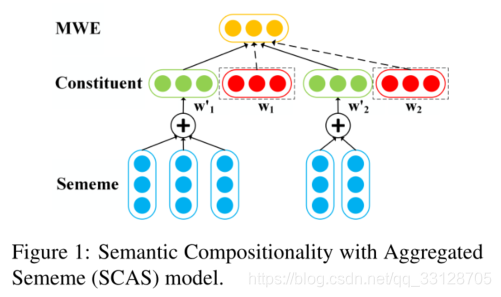
SCAS model 只是简单将其成分的word embedding与成分义原的embedding相融合。 w 1 ′ = ∑ s i ∈ S w 1 s i , w_1^\prime = \sum_{s_i\in S_{w_1} }s_i , w1′=si∈Sw1∑si, w 2 ′ = ∑ s j ∈ S w 2 s j w_2^\prime= \sum_{s_j\in S_{w_2} }s_j w2′=sj∈Sw2∑sj其中w1’和w2‘分别代表w1和w2聚合的义原embedding p = t a n h ( W c [ w 1 + w 2 ; w 1 ′ + w 2 ′ ] + b c ) p = tanh(W_c[w_1 + w_2;w_1^\prime + w_2^\prime] + b_c) p=tanh(Wc[w1+w2;w1′+w2′]+bc)
2. SCMSA Model
由于一个成分的意义可能因其他成分而异,因此,当成分与不同成分结合时,成分的义原应该有不同的权重。SCMSA模型采用相互注意力机制动态赋予义原权重。

e 1 = t a n h ( W a w 1 + b a ) , e_1 = tanh(W_aw_1 + b_a), e1=tanh(Waw1+ba), a 2 , i = e x p ( s i ⋅ e 1 ) ∑ s j ∈ S w 2 e x p ( s j ⋅ e 1 ) , a_{2,i} = \frac{exp(s_i\cdot e_1)}{\sum_{s_j\in S_{w_2}} exp(s_j\cdot e_1)}, a2,i=∑sj∈Sw2exp(sj⋅e1)exp(si⋅e1), w 2 ′ = ∑ s i ∈ S w 2 a 2 , i s i w_2^\prime = \sum_{s_i\in S_{w_2}}a_{2,i}s_i w2′=si∈Sw2∑a2,isi w1’同理可得
3.2 加入组合规则
上一部分仅加入了K,这一部分加入R,即 p = f ( w 1 , w 2 , K , R ) p = f(w_1,w_2,K,R) p=f(w1,w2,K,R)对于不同组合规则的MWE,可以使用完全不同的组合矩阵: W c = W c T , r ∈ R s W_c=W_c^T, r\in R_s Wc=WcT,r∈RsRs指包含MWE语法规则的组合规则集,如形容词=名词,名词-名词。但是,因为作者认为合成矩阵除了包含特定于组合规则的合成信息外,还应该包含共同的合成信息。因此, W c = U r V r + W c c W_c=U^rV^r+W_c^c Wc=UrVr+Wcc其中,Ur、Vr是低秩矩阵。
3.3 Training
在下游任务中使用上述SC模型得到的MWE嵌入。针对不同的任务,我们采用不同的训练策略和损失函数。
MWE相似性计算训练
对于MWE相似性计算任务,我们使用平方欧氏距离损失: L p = ∣ ∣ p c − p r ∣ ∣ 2 2 L_p=||p^c-p^r||^2_2 Lp=∣∣pc−pr∣∣22其中pc是由SC模型得到的p的embedding,pr相应的reference embedding,它可以通过将MWE看作一个整体并应用词表示学习方法得到。总体的Loss方程: L = ∑ p ∈ P t L p + λ 2 ∑ θ ∈ Θ ∣ ∣ θ ∣ ∣ 2 2 L=\sum_{p\in P_t}L_p+\frac{\lambda}{2}\sum_{\theta\in\Theta}||\theta||^2_2 L=p∈Pt∑Lp+2λθ∈Θ∑∣∣θ∣∣22其中, P t P_t Pt是训练集, Θ \Theta Θ是包括 W c W_c Wc和 W a W_a Wa的参数集, λ \lambda λ是正则化参数。
MWE义原预训练
义原预测旨在从所有义原集合中为未标注的词或短语选择合适的义原。现有的研究将义原预测问题建模为一个多标签分类问题,将义原看作是单词和短语的标签。为了做MWE义原预测,作者采用单层感知器作为分类器: y ^ p = σ ( W s ⋅ p ) \widehat{y}_p=\sigma(W_s\cdot p ) y p=σ(Ws⋅p)其中 σ \sigma σ是sigmoid函数, [ y ^ p ] i [\widehat{y}_p]_i [y p]i是 y ^ p \widehat{y}_p y p的第i元素,表示第i个义原的预测得分,得分越高,选择义原的可能性越大。 W s W_s Ws是所有义原的embedding。
对于分类器的训练损失,考虑到词义在词上的分布相当不均衡,我们采用加权交叉熵损失: L = ∑ p ∈ P t ∑ i = 1 ∣ S ∣ ( k × [ y p ] i l o g [ y ^ p ] i + ( 1 − [ y p ] i ) l o g ( 1 − [ y ^ p ] i ) ) L=\sum_{p\in P_t}\sum^{|S|}_{i=1}(k\times[y_p]_ilog[\widehat{y}_p]_i+(1-[y_p]_i)log(1-[\widehat{y}_p]_i)) L=p∈Pt∑i=1∑∣S∣(k×[yp]ilog[y p]i+(1−[yp]i)log(1−[y p]i))
4 实验
作者在两个任务上评估了语义整合SC模型,包括MWE相似度计算和MWE义素预测。对于后者,还进行了进一步的定量分析和案例研究。
4.1 数据集
选择HowNet作为义原知识的来源。在HowNet中共有118346个汉字注释,2138个义原。根据之前的工作,作者过滤了认为不重要的低频义原。最终义原为1335。使用预先训练好的MWE embedding(MWE相似性任务中的训练所需)和有关成分embedding,这个由GloVe在Sogou-T预料上进行训练。作者利用一个基于义原的词表示学习模型的结果得到的预训练义原embedding。
作者建立了一个由51034个中文MWE组成的数据集,每个MWE和它的两个组成部分都在HowNet中用义原标注,并且同时进行了预训练词嵌入。将数据集按8:1:1的比例随机分成训练集、验证集和测试集。
4.2 实验设置
Baseline Methods
(1)ADD和MUL,简单的加法和元素乘法模型
(2)RAE,递归自动编码器模型
(3)RNTN,递归神经张量网络
(4)TIM,张量指数模型
(5)SCAS-S,是SCAS模型的老版本,他去除了sememe knowledge。
这些所有baseline均为考虑任何知识。
Combination Rules
为了简单起见,将数据集中的所有MWE分为四种组合类型,即形容词-名词、名词-名词、动词-名词和其它,他们的实例数位1302,8276,4242和37214。作者采用后缀+R表示将组合规则集成到模型中。
Hyper-parameters and Training
根据经验,单词和义原的embedding设置为200维,hr设置为5,正则化参数为 1 0 − 4 10^{-4} 10−4,loss中k为100。在训练方面,使用随机梯度下降SGD,两个任务的学习率初始化为0.01和0.2,每次迭代衰减1%。在训练过程中,MWE成分的embedding被固定,义原embedding进行fine-tuned。对于基线方法,均使用相同的预训练word
embedding,它们的超参数调整到验证集中的最佳值,同时也使用SGD。
4.3 MWE相似性计算
评估数据集和协议
使用两个流行的中文词汇相似性数据集,即WordSim-240和WordSim-297,以及一个新建立的COS960,所有这些数据集由单词对和人类指定的相似性分数组成。

实验结果:
(1)通过与义原结合,SCAS和SCMSA都实现了整体性能的提高。
(2)进一步集成组合规则后,两个SC模型表现出更好的性能除了WS240。
(3)比较SCAS和SCMAS以及他们的变体+R,考虑注意力的SCMAS模型比简单的SCAS没有明显的优势,可能是训练不足,因为SCAMS有更多的参数。
4.4 MWE义原预测
一个词或者一个MWE的义原可以很好的刻画这个词的语义。另一方面,一个词的高质量嵌入(MWE)也被认为是准确地表示该词的意义(MWE)。因此,我们认为嵌入效果越好,它能预测的义原也就越好。更具体地说,SC模型是否能够预测MWE的正确义原反映了SC模型学习MWE表示的能力。相应地,我们认为MWE义原预测是对SC模型可靠的外在评价。
评估数据集和协议
我们使用上述测试集进行评估。在评价方案上,我们采用了平均准确度(MAP)和F1评分。由于我们的SC模型和基线方法为整个义原集中的每个义原生成一个分数,因此我们选择分数高于δ的义原来计算F1分数,其中δ是一个超参数,并且在验证集中也调整到最佳。

实验结果:
(1)通过与基线方法的比较,特别是通过SCAS及其消义版本SCAS-S的比较,再次明确地证明了义位知识在SC建模中的有效性。此外,我们的模型中的组合规则集成变体的性能优于相应的原始模型,这一点也得到了验证使组合规则的作用更加明显。
(2)我们的两个考虑相互注意的模型,即SCMSA和SCMSA+R模型,与SCAS和SCAS+R模型进行了比较,结果显示了相互注意机制的优点。
Effect of SCD
在这个实验中,探讨了SCD对义原预测性能的影响。我们根据MWE的SCD将测试集分成四个子集,这是由表1中基于义原的SCD方法计算的。然后我们评估了我们的模型在这四个子集上的义原预测性能。从表4所示的结果中,我们发现:
(1)SCDs越高的MWE具有更好的义原预测性能;
(2)无论是否整合组合规则,共同注意模型都比聚合义素模型有更好的表现。

Effect of Combination Rules
在本实验中,研究了组合规则对义原预测性能的影响。表5显示了我们的模型在不同组合规则的MWE上的映射。

无论使用哪种组合规则,将组合规则集成到SC模型中都有利于MWE的义原预测。此外,义原的预测性能随组合规则的变化而变化。
Case Study
在这里,给出了一个包含多义成分的MWE义原预测的例子。

汉语中的“参”有“连接”、“参”、“弹劾”三个义项,它们的义原不同。对于MWE参战。它的意思是“参加一个战争”,“参”表达了它的第一个意思“加入”。在SC模型的前5个预测义原中,前四个是HowNet中注释的义原,包括来自“参”的义原“从事|engage”。此外,第五个义原“政治”也与MWE的意义有关。另一个意思是“红丹参”,一种类似人参的红色中草药,这里的意思是“人参”。作者的模型正确的预测了HowNet中注释到的“参”的两个义原“药物|medicine”和“花草|FlowerGrass”。此外,模型给出的其他预测义原如“红|red”和“中国|China”也是合理的。
这篇关于论文阅读《Modeling Semantic Compositionality with Sememe Knowledge》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
