本文主要是介绍python自动化办公之爬取HTML目录样式写入word文档实战(含NO pandoc was found报错解决),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python自动化办公之爬取HTML目录样式写入word文档实战
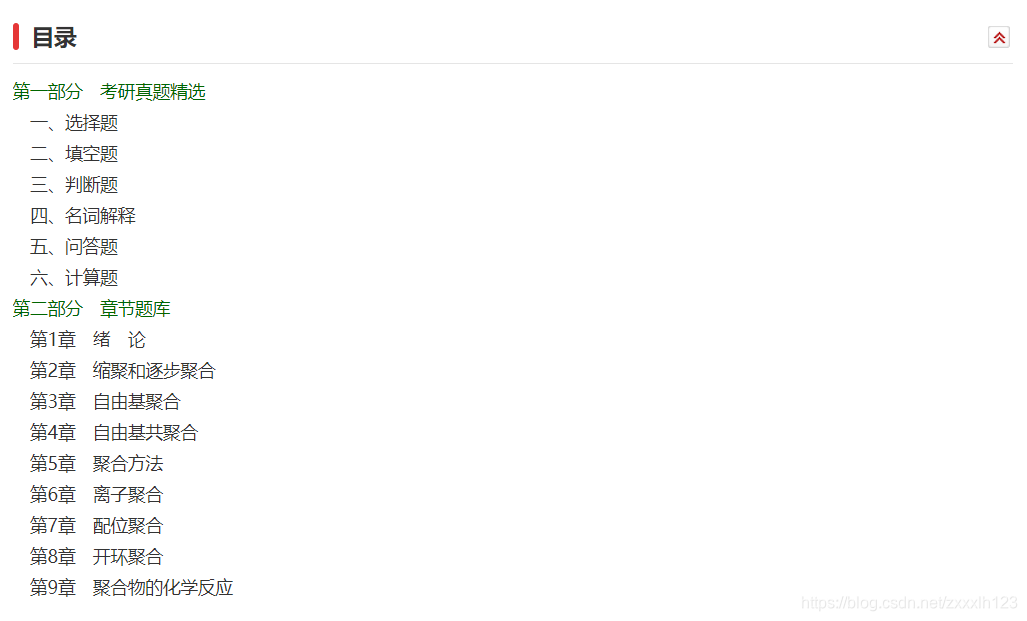
看见朋友每天重复地从网页里把目录复制粘贴到word里,觉得很不智能。于是想到用Python的自动化办公功能,来解救他!比如,下面这个图就是HTML里的内容,我要把它提取出来写入到word里面,还要带上这本书的标题,给word命名。写好了就可以批量处理!!!是不是很妙o( ̄︶ ̄)o
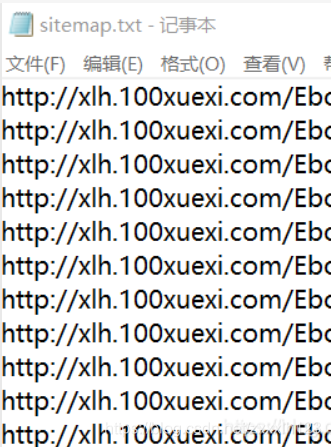
还好朋友会用一个sitemapX工具,把网页中的目标路径都写入到一个txt文件中。为了保护别人的网站,我还是不给链接给大家了。
调用的库:
import time
import re
import urllib.request
import os
import pypandoc
from docx.oxml.ns import qn
from docx import Document
这个小项目做起来,还是有几个重点需要注意的地方:
(1)每次解析30个HTML文件,之后需要更新原来的txt文件,不然每次处理的都是前30个HTML文件。
#获取网页列表
def input_html(txtname):with open(txtname,'r') as f:content = f.read()s1 = content.split('\n')#讲字符串转为列表html_num = len(s1)#链接总个数print('该文件含有{}个链接'.format(html_num))s2 = s1[30:]#剩下的链接new_html = '\n'.join(s2)#更新new_html_num = len(s2)#链接总个数print('完成这次任务,还剩{}个链接'.format(new_html_num))return new_html#创建新的文档,以时间作为区分
import time
nowtime = time.strftime("%Y%m%d%H%M%S", time.localtime())#当前时间作为新的文件表示
with open("sitemap" + nowtime + ".txt", "w", encoding='utf-8') as f:f.write(input_html("sitemap.txt"))f.close()

(2)读取HTML文件,提取其中所需要的的内容,需要使用正则表达式,主要提取两部分,一个是标题,一个是带有目录的内容。
import re
import urllib.request #导入request模块
def Parse_html(url):res = urllib.request.urlopen(url) #调用urlopen()从服务器获取响应界面html = res.read().decode('utf-8') #对返回的响应数据解码,并赋值给htmlreturn html
html=Parse_html(url)
#提取源文件一部分作为内容部分
str1=re.findall('<div class="DetailInfo">([\s\S]*?)<div class="Column ElectronicIntro"',html)#取两者之间的部分
str1[0]=str1[0].replace('<div class="Column ColumnCatalog" id="columnCatalog" style="display: none">','<div class="Column ColumnCatalog" id="columnCatalog" style="">')
str1_1=re.sub('</span>[\s]*?<li>','</span>\n</li><li>',str1[0])#补缺失在部分</li>
str1_2=re.sub('</span>[\s]*?</ul>','</span>\n</li></ul>',str1_1)#补缺失在部分</li>
#提取源文件一部分作为标题部分
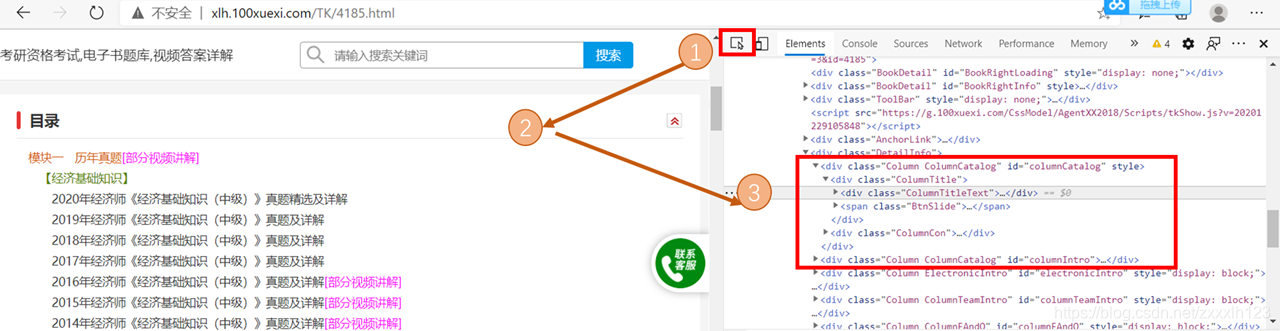
str2=re.findall("<h1[\s\S]*?</h1>",html)#匹配含换行符[\s\S]*?,之间匹配任何字符,含换行符怎样查看网页对应的目标图片链接呢?使用chrome浏览器打开上述网页,然后按F12,就会在右边看到这个网页的源代码,按照我下图的三步走,点击小箭头后,把鼠标移动到目标图片,悬浮即可,这个时候右边会高亮显示对应这个目标部分的网页源代码。就可以看到我用红色框框起来的部分,src后面引号的部分就是这个图片的连接。
这中间还是遇到了两个问题,一个是的缺失,会导致一部分内容不可显示;另外一个问题style=“display: none"这个部分会把目录隐藏,所以,需要将它替换成style=”"。这部分就涉及到了HTML的结构和正则表达式。
(3)把提取的内容拼接起来,重新形成一个HTML文件。
import os
def write_html(title,content):html1 = open("n.html", "w")#写成htmlhtml1.write(title)#标题html1.write(content)#内容html1.close()
#把处理好的内容写入HTML文件
write_html(str2[0],str1_2)(4)将HTML文件写入Word
import pypandoc
def html_docx(html_path,docx_path):f = open(html_path,"r",encoding='gbk')html1 = f.read()output = pypandoc.convert_text(html1, 'docx', 'html', outputfile=docx_path) # 将 html 代码转化成docx
#把新的HTML文件写入Word,自带格式
html_docx("n.html","file1.docx")
这个阶段有个难点,就是pypandoc的导入,在公司用的服务器,调试起来没有问题,但是在家里的电脑报错了NO pandoc was found。具体见下图:

在网上找了很多方法尝试,主要是按照报错的指引去做的,可是都没有得到改善。最后找到一篇帖子https://blog.csdn.net/qq_43741748/article/details/105454719,《下载和安装Pandoc(Windows和Mac版本)》从Pandoc的官网下载https://www.pandoc.org/installing.html,直接运行安装问题就解决了。

(5)根据需求进一步调整Word内容,主要是字体调成微软雅黑,增加页脚,用内容的标题给文件命名,存储下来。
#修改word样式,给文件命名,增加页脚
from docx import Document
document = Document('file1.docx')
document.paragraphs[0].text=document.paragraphs[0].text.replace("[题库]","")
document.paragraphs[0].text=document.paragraphs[0].text.replace("[电子书]","")
f=document.paragraphs[0].text
filename=f#取文件名
sec = document.sections# word文档中章节 section 对象sec0 = sec[0] # 获取章节对象
font0 = sec0.footer # 返回页脚对象
#print(font0)
# 设置页脚
#print(font0.paragraphs)
font0_par = font0.paragraphs[0]
font0_par.add_run(' 星蓝海学习网-考研资格考试,电子书题库,视频答案详解')
from docx.oxml.ns import qn
document.styles['Normal'].font.name = u'微软雅黑'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑') # 将段落中的所有字体
document.save('{}.docx'.format(filename))
对第一步的列表还需要循环遍历,属于基础就没有再赘述了,还有就是在循环遍历的时候,需要增加异常处理的部分。处理结果贴给大家看看,

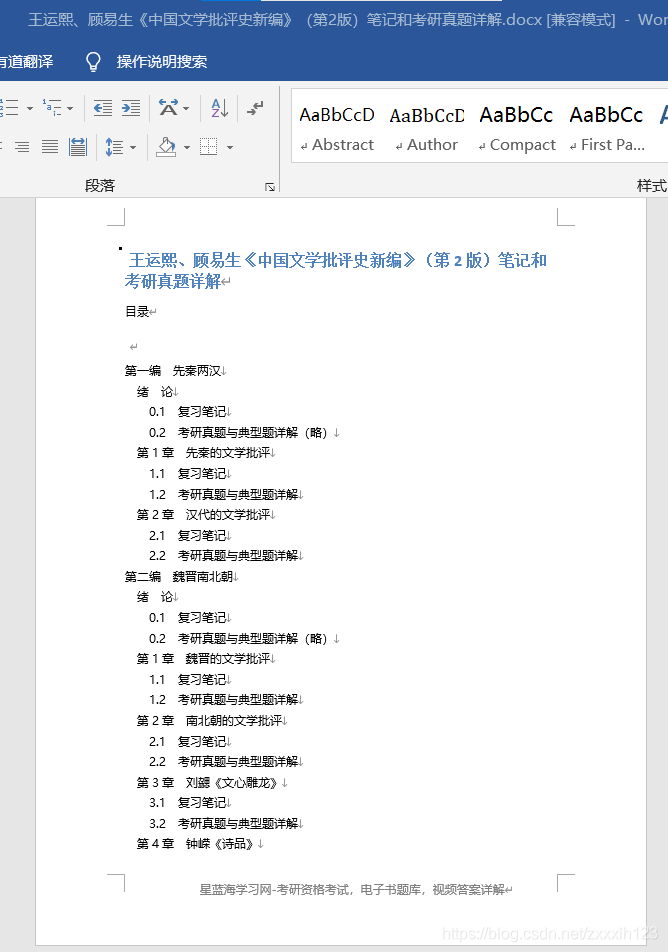
在docx文档处理的部分,标题还不能更改样式,日后还需要进一步完善!
**整理内容不易,走过路过觉得课程内容不错,请帮忙点赞、收藏!Thanks♪(・ω・)ノ****如需转载,请注明出处
参考文献:**
1.csdn.net/qq_43741748/article/details/105454719
2.https://www.pandoc.org/installing.html
这篇关于python自动化办公之爬取HTML目录样式写入word文档实战(含NO pandoc was found报错解决)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






