本文主要是介绍强化学习-论文调研-experience replay,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
experience replay 论文调研
一 论文概要
1 Hindsight Experience Replay(2017 NeurIPS)
在奖励稀疏的情况下,要用强化学习算法训练是很困难的. 本文提出一种通过增设不同的目标, 增加状态转移中获得奖励的次数,从而使得原本不能或者难以训练的稀疏奖励问题变得可训练,易训练. 具体是现实 在每个transaction项中增加一项目标项g,在后续训练中,将初始目标g 替换为阶段目标g', 并重新计算r' .以新的状态转移五元组(st, at, st+1,rt',g') 去训练Q和Π.
在机械臂操控实验中,结果显示使用HER的算法效果有显著提升(相关性?)

二 Model-based Hindsight Experience Replay(2021 NeurIPS)
Hindsight Experience Replay 是一种通过设置不同的目标,改变在buffer中数据的reward,从而克服稀疏回报问题的一种算法。 而model-based Hindsight Experience Replay 则是先建立环境的model,再通过model 从已有的buffer里生成虚拟数据,最后用虚拟数据去更新Q函数和策略的方法

三 Attentive Experience Replay(2020 AAAI)
算法动机出于,认为当前访问次数多的状态对优化策略有更重要的意义。算法从replay buffer中随机选取λ*k个样本(k是minibatch 的大小),分别计算与当前状态St 的相似度, 最终从λ * k个样本中挑出最相似的k个样本用于计算和更新策略的参数权重。状态的相似度计算可以用余弦相似度实现。

四 Revisiting Fundamentals of Experience Replay (ICML 2020)
具体探讨了replay buffer 中各种参数对性能影响的好坏和参数 buffer capacity是通过什么机制影响实验效果好坏的。(1)当replay capacity增加时性能增加,当老数据占比下降时性能增加(2) 即buffer capacity通过影响 n-step return 影响参数好坏。 n-step return 定义如下, 它是DQN的几个重要改进之一。 作者通过对照试验发现, 在DQN上分别只添加加 PER,Adam,C51,和 n-step 四种改进中的一种,只有当添加 n-step 改进时,增大 buffer capacity 才会明显提升性能。并且,当分别从rainbow中去除四种改进中的一种,只有当去除 n-step return 后,增大buffer capacity 性能不会得到提升。
五 Prioritized Experience Replay(ICLR 2016)
在选取transaction时训练网络时, TD-error大的求出的偏导更大,对网络影响更大,TD-error小的求出的偏导更小,对网络的影响更小, 基于此PER算法给TD-error 大的项目更高的权重,使其更高的概率被选中. 同时为了避免过多使用相同数据训练造成过拟合,也要保证优先级低的数据也有一个非零的概率被选中.
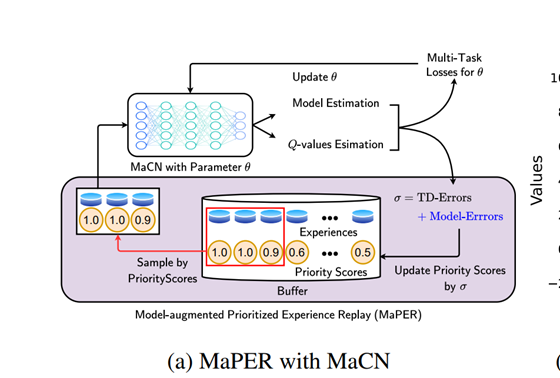
六 Model-augmented Prioritized Experience Replay(ICLR 2021)
用model-based 方式强化PER, PER 是一种基于TD-error的优先级回放的方法,即在从replay buffer 里采样时,TD-error大的transaction有更多的机会被选中,以利于即使优化模型降低TD-error。 Model-augmented Prioritized Experience Replay 即在model-base条件下加强PER方法。 首先需要对环境建模,由于R(s,a)和T(s,a)有相同的输入,文中对其使用了参数共享方法建模。 将critic net的损失从Q 的TDerror的均方差,转变为Q 的TDerror的均方差,R的均方差和Transaction的均方差的加权和。这个改进称为model-augmented Critic Network (MaCN)。 文中另一个改进是
用Q函数的TD-error的均方差 , R函数的均方差 和T函数的均方差 加权之和作为transaction的优先级。 通过这种方法,可以选到对模型长期有益和短期有益的经验,且这种方法计算耗时较per更小。这个改进就称为Model-augmented Prioritized Experience Replay MaPER.
此方法适用于所有含critic net的off-policy 算法.
7 Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learnin(ICML 2017)
在多智能体强化学习中,以IQL为例,由于环境变换受多个智能体的影响, 因此从单个智能体视角来看,环境是不稳定的,即在智能体replay buffer里的由环境生成的数据不再反映当前环境状态转移的动力. 但只用最近的经验会造成样本效率低的问题,为解决这个问题文中提出 Multi-Agent Importance Sampling . 对于IQL 因为我们指导在各个训练阶段智能体的策略,我们能环境变化的方向, 并用重要度采样来修复它. 为推导出这个重要度采样,文中重新定义了状态空间(加入了其他智能体的动作-观察),用这个状态空间重新定义了观察方程和回报方程和状态转移方程。 让不稳定环境变得稳定的另一方法是让其他智能体的参数对本智能体可见,但这使得本智能体的观察空间太大,因此需要找一个低微的能代表其他智能体参数状态的参数,文中选择了 迭代次数e 和退火的时间 ε,简单的设置在实验中得到了不错的效果。
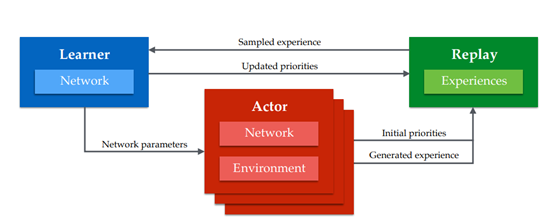
八 DISTRIBUTED PRIORITIZED EXPERIENCE REPLAY
动机:更大模型,更多数据已经在深度学习上被证明有效,所以本文提出一种通过分布式生成数据和优先选取数据的方法扩大深度强化学习。
多个actor 同时与环境进行交互积攒replay buffer中的数据,然后定期将数据传给learner 进行训练,learner 根据经验的优先级训练之后将定期参数复制给actor进行执行 。该架构在dqn和ddpg上效果有显著提升
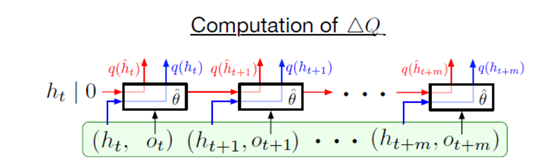
九 Recurrent Experience Replay in Distributed Reinforcement Learning(2019 ICLR)
动机:强化学习 在完全可观测的问题中取得很多成功,但是在部分可观测中需要更好的基于记忆的表征来提升性能
本文证明了经验回放在参数滞后的作用而导致的表征偏移和周期性的状态衰退的问题,本文提出的R2D2模型与Ape-x相似名单时在卷积层后加了LSTM,并且还改replay buffer 存固定长80的(s,a,r)的序列且相邻序列重叠40步
为了让rnn能学到长期的状态表征,前人提出两种方法1.在经验吃采样的序列开头,用全零状态初始化网络 2.回放整个轨迹 本文认为第一种方法虽然足以在全观察的问题上收敛但是,却组织了网络学到真正的长依赖的信息。
为此提出了两种方法从随机抽样回访序列训练一个循环网络。1.存储状态:将rnn的隐藏状态存在经验池,并用它在训练时初始化网络。 2.燃烧:让网络用一部分的序列信息来制造网络开始状态,甚于部分再在这个基础上更新rnn。
实验结果显示, 用了burn-in和 store-state 比直接全零初始化状态网络效果更好。
十 A Deeper Look at Experience Replay(2015 ICMR)
动机:自从经验回放被提出后,经验池大小对训练的影响一直被低估。本文研究了经验池大小对模型效果,得出结论,过大的经验池对训练有害,并提出了一个时间复杂度为O(1)的方法来减弱这种危害。
作者对比了三种方法 Online-Q(即Q-learning) Buffer-Q(带replay buffer) 和 Combined-Q(即CER,每个batch既用当前的转移又用buffer 里的转移训练)
这种方法在一些简单任务中表现出很大的提升。在一些复杂任务上提升较小。
十一 Selective Experience Replay for Lifelong Learning(2018 AAAI)
动机:深度强化学习中的网络常常表现出遗忘性,本文提出一种结合了FIFO和长期选择的replay buffer的方法改善这个问题。
文中提出了四种选择的策略:1.基于surprise 2.基于reward 3.distribution matching 和 4.coverage maximization。并分析了效果最好的两种,3和4之间的权衡
十二 Curriculum-guided hindsight experience replay(2019 NeurIPS)
动机:出于人类思维方式,有课程的学习可以提高学习效率。 在HER中所有的目标都被平等的对待,作者认为这是不合理的:1.并非所有失败的经验都对改进智能体有平等的作用(虽然这对模型泛化性更好),2.相似的目标重复学习是多余的
因此文中提出一种动态的自适应的控制“探索与利用”的算法来控制HER中经验的选择。具体由两点 1.逐渐改变以达到目标和实际目标的距离度量方式 2.基于多样性的好心策略:用来使目标更加多样化。
二 归纳总结
除第四篇讨论参数作用,第七篇讨论多智能体情况外,其余论文关系结构如下所示。可根据经验获得方式分为两大类,集中式和分布式。集中式中又分为HER和PER两大类,MHER是基于HER对环境建模的改进,MPER是基于PER对环境建模的改进,AER是继承PER排序的思想,变换排序依据的改进。 分布式中R2D2 是基于 Ape-x 对部分可观测条件下的改进。
这篇关于强化学习-论文调研-experience replay的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








