本文主要是介绍clm5制作地表数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
已整理
目录)
- 制作地表数据
- 一、Create SCRIP grid files (if needed)
- 1. 第一步
- 2. 第二步
- 二、Create mapping files for use by mksurfdata_map with mkmapdata
- 重点: 在这里可以看到要什么文件
- 三、domain文件
- 重点
- 四、Create surface datasets with mksurfdata_map
制作地表数据
指路教程
(这个大佬的教程不见了,给我整不会了)
指路官网
建议官网看流程,教程看具体操作
感谢我的大腿!!!
感谢我的大腿!!!
感谢我的大腿!!!
一、Create SCRIP grid files (if needed)
有个问题, 没有安装ncl—解决方法:module 下来
用source filename 运行filename文件中的命令
这些是要用到的,缺啥补啥,这里可能会出现就是ncl和nco的安装问题
module load nco/version ncl/version #不要直接复制,version要根据自己的版本
下面这种就是出现问题的例子,这只是其中一种

一般制作地表数据工具在…/cesm_2.1.3/components/clm/tools/中
但是是单点模拟的话要改一下
1. 第一步
cd mkmapgrids/
vim mkscripgrid.ncl
把原来的注释后加上:
lonCenters = lonW + delX/2.d0
latCenters = latS + delY/2.d0
2. 第二步
cd ../mkmapdata
export CSMDATA=.../inputdata #这个是输入文件放的路径
export GRIDNAME=xxx #自己的名字哈,都可以哦
export CDATE=‘date + %y%m%d’
./mknoocnmap.pl -p lat,lon -n $GRIDNAME #lat,lon 根据自己的哈

成功生成了相应文件哈,在哪里会路径上有
二、Create mapping files for use by mksurfdata_map with mkmapdata
缺少esmf的话 module有哦,可以直接module一个
#这个路径根据自己的esmf找一下
export ESMFBIN_PATH=/public1/soft/esmf/8.0.1-intel20/bin/binO/Linux.intel.64.intelmpi.default/
export GRIDFILE=$CESMPATH/components/clm/tools/mkmapgrids/SCRIPgrid_${GRIDNAME}_nomask_c$CDATE.nc
./mkmapdata.sh -r $GRIDNAME -f $GRIDFILE -t regional >& filename.log
- 如果对为什么-t 后面选择regional有疑问,是因为其实单点也不是单纯的一个点,是个超级小的区域而已
当然这里我没有探索过,在上一步是不是也可以不用改ncl文件,只是在区域设定的时候遵循极小区域的设定,大神路过可以指教一下,万分感谢! - … >& filename.log 这个是将输出日志,到 filename.log这个文件,名字随便哈,主要是方便查询运算结果
 这里有缺少libssl.so.1.0.0的问题
这里有缺少libssl.so.1.0.0的问题
执行下module unload anaconda/3-Python-3.6.5-phonopy
可以解决

看到sucessful了吗?啊啊啊啊啊啊啊啊
重点: 在这里可以看到要什么文件
- 在这个路径下下载哦
- 下载的文件是mkmapdata.sh 后面加上–list就可以看到需要下载的文件了
- BTW 这个有点大,提前下好比较好啊
三、domain文件
如果是第一次使用要先编译一下
路径是 …/cesm_2.1.3/cime/tools/mapping/gen_domain_files/src
修改Makefile文件
将:LDFLAGS += $(USER_LDFLAGS)
改为:LDFLAGS += -L$(LIB_LDFLAGS) -lnetcdf


!!! 这里注意一下,除了看教程,也要看他的报错哦,如下,改对了就行
usage: configure [-h] [-d] [-v] [-s] [–machine MACHINE]
[–machines-dir MACHINES_DIR]
[–macros-format {Makefile,CMake}] [–output-dir OUTPUT_DIR]
[–compiler COMPILER] [–mpilib MPILIB] [–clean]
但是有个大问题,我不知道setting之后是不是就成功了
就当成功了吧,之后有问题再说吧
这就是个大坑啊,人在坑底起不来
重点
gmake 是有奇奇怪怪的东西出现,好像是编译了f90文件,没看到error和warning,所以我就不管了哈哈哈
!!! 来了就很迷,我都不知道还能这样,我的**mapfile是在mkmapgrids下面而不是在mkmapdata下,**所以导致我找了很久…
export MAPFILE=/public1/home/sc91286/cesm_2.1.3/components/clm/tools/mkmapgrids/map_xxx_noocean_to_xxx_nomask_aave_da_210527.nc
./gen_domain -m $MAPFILE -o $GRIDNAME -l $GRIDNAME

麻麻我成了!救命
这里有个问题
CSMDATA(这个东西输入数据的位置 )这个路径没有更改,这里环境变量还是要改的,所以直接在pl里面改了
my $CSMDATA = "/glade/p/cesm/cseg/inputdata";
改为自己路径哈 这里又又又要下文件了,加油加油
my $CSMDATA="/public1/home/sc91286/cesm_2.1.3/inputdata/lnd/clm2/rawdata/";
艰难的下载,今天又是做不完的一天,还没有找到相应的下载文件,大佬路过就告知一下,有咩有列出来的需要什么文件,我现在是报错一个下一个,真心不容易,菜狗流下了不学无术的泪水~~
好的我又来了,经过大概3-4天的下载,报错的出来的文件应该是下载完了!
四、Create surface datasets with mksurfdata_map
# module load hdf5/1.10.4-intel20 netcdf/4.4.1-icc17
# module unload intel/17.0.5 hdf5/1.8.13-icc17
# 以上两步仅供参考,如果出现了netcdf或hdf的报错,可以试试
cd ${CESMPATH}/components/clm/tools/mksurfdata_map
./mksurfdata.pl -r usrspec -usr_gname $GRIDNAME -usr_gdate $CDATE -usr_mapdir $MAPDIR -y $YEARS
#这个years可以自己设置的哈
在最后一步的报错上出现了问题
ERROR in mksurfdata_map: 34304

 害不害怕,就在successfully的上一个!
害不害怕,就在successfully的上一个!
这时候,还是感谢我的大腿的救命
事实上,还有很多的文件需要补充,而且目前来说他是不报错的!
所以需要及时看log文件,看看有没有缺少的,这个就需要自己寻找了
目前,我正在补文件,所以具体之后会怎么样也不知道
PS:这里涉及到几个环境的设置,良好的移植环境设置是非常重要的
这里感谢超算的技术支持,毕竟靠我这个学术垃圾要下辈子了!!!
报错nefcdf和hdf的问题可以参考一下,不过这个主要还是自己的环境
source /public1/soft/modules/module.sh
module purge
module load hdf5/1.10.4-intel20 netcdf/4.4.1-icc17
module unload intel/17.0.5 hdf5/1.8.13-icc17
log文件重要,仔细找就可以找到缺失的
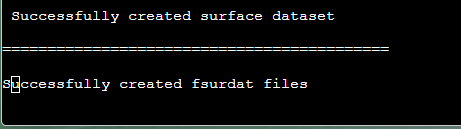
生成以下文件(如果没有报相应缺少的文件,可以查看log文件,里面有)

我成功了!!!啊啊啊啊啊啊啊啊啊啊
5月26日-6月4号!!!
感谢我的大腿!!!
8月12日整理
这篇关于clm5制作地表数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





