本文主要是介绍c语言程序设计实验报告——西安电子科技大学(存在问题,仅供参考),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《程序设计基础课程设计》 实验报告
题目一:基础编程
(1)题目描述:假设平面上有1~N(x,y)个坐标点,编程判断这N(x,y)个点能组成多少个有效三角形。
(2)题目&算法分析:本题的算法思路很好想:用number来表示可以形成的三角形数,用if条件判断,满足则:number++,最后格式化输出number即可,注意if条件句嵌套在for循环中。
本题关键在于满足三角形的判断方法,我给出的算法如下:
当三个点A、B、C的坐标分别为A(x1,y1)、B(x2,y2)、C(x3、y3)时,若满足:(x1-x2)/(y1-y2)!=(x2-x3)/(y2-y3) ——1
此时三点构成一个三角形,这算是数学问题,可以自行验证。
1式就是判断式。
(3)代码展示:
#include <stdio.h>
int main()
{int n,i,j,k,number=0;float a[1000],b[1000],s;scanf("%d",&n);for(i=0;i<n;i++){scanf("%f %f",&a[i],&b[i]);}for(i=0;i<n-2;i++){for(j=i+1;j<n-1;j++){for(k=j+1;k<n;k++){if((a[i]-a[j])/(b[i]-b[j])!=(a[j]-a[k])/(b[j]-b[k])){number=number+1;}elsecontinue;}} }printf("%d",number);return 0;}
(4)代码解读
①本题使用c语言编写
②本题不需要设置专门函数(至少我认为没有必要),头文件,main函数中先开a[1000],b[1000]两个数组用于储存输入点的x、y坐标,设定int 型的i、j、k用于遍历时的参数,然后开int 型的number用于储存搜索到的三角形数量,scanf标准输入点的数量n,还有每个点的坐标,if语句中套公式判断就行了,注意在连续的三个for循环中完成。最后printf标准输出number。
(5)测试数据:
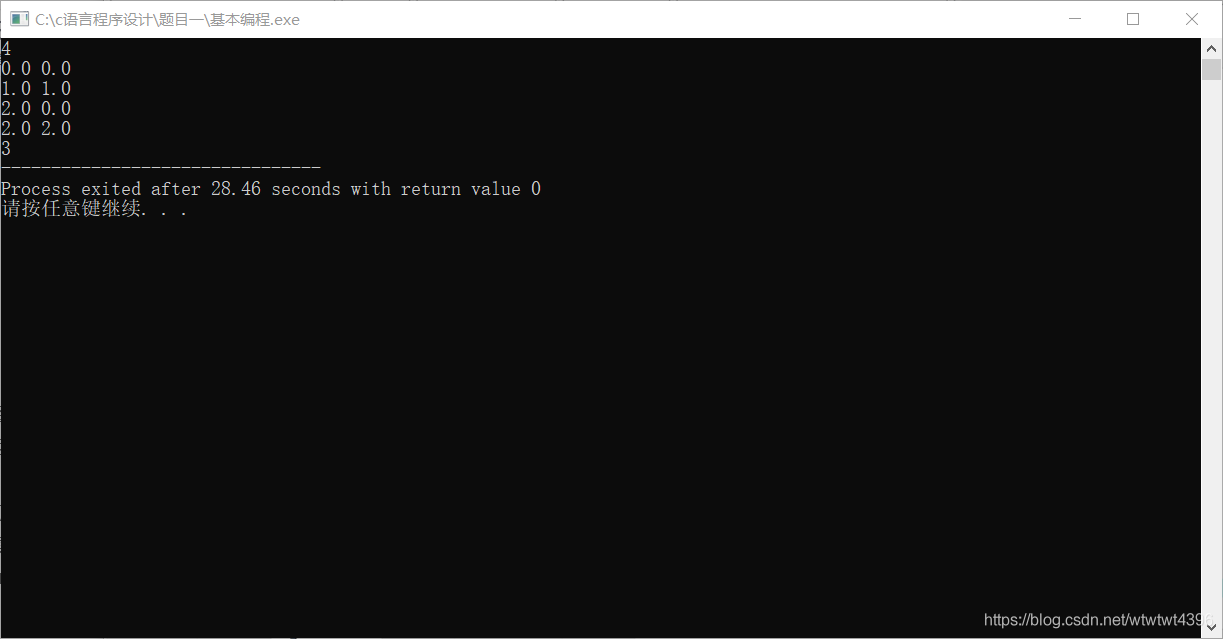
题目二:高精度计算
(1)题目描述:用整型数组表示10进制大整数(超过2^32的整数),数组的每个元素存储大整数的一位数字,实现大整数的加减法。
(2)题目&算法分析:本题为高精度算法中加减法的实现,我们要知道,以c语言为例,每种特定的数据形式,如int float double都是有特定的范围,然而一旦我们想计算的数超过了它们能表示的范围,就无法得到结果。因此我们需要设计高精度算法,比如本题我们是完成整数类的高精度算法。
我们回想加法和减法的竖式计算法:加法的进位,最多为位数最多的数的位数加1,比较简单,但是减法就要考虑借位和正负号的问题了,稍微麻烦一些;
思路上:先说加法,两个大整数的和位数为最大的加1,前面有说,所以关键是后面的进位;而减法如果出现被减数小于减数的,我们可以改为大减小,再添加负号(-),
编程中,我们将输入的两个数都用字符串的形式输入,然后将每一个数字字符转换成整数储存在两个不同的数组a[100],b[100]中,我们再开一个c[100]来表示a和b的和,然后做进位处理:
c[i+1] += c[i]/10 ; ——2
同时要确保新的数组c,即答案数组的每一位都小于10:
c[i]%=10; ——3
记得用if语句判断如果比最大数数位还多1时的数组更新。
接下来是减法,我们要先比较两个数的大小,可以在存入数组后借助compare()函数比较,当然需要我们自己编写。由于还要判断正负,我们可以借助一个f变量,根据a[],b[]的大小给出对应的值,并根据f的值判断符号为+还是-。减法借位和加法进位基本可以同理写出。
(3)代码展示:
#include<stdio.h>
#include<string.h>
int max(int a,int b)
{if(a>b){return a;} else return b;
}
int compare(int a[],int b[])
{int i;if(a[0]>b[0]) {return 1;}if(a[0]<b[0]) {return 0;} for(i=a[0];i>0;i--){if(a[i]>b[i]) {return 1;}if(a[i]<b[i]) {return 0;}}return 0;
}
int main()
{char m[100],n[100];int a[101]={0},b[101]={0},c[102]={0},d[101]={0};int i,temp,f;printf("请输入计算的数: ") ; scanf("%s%s",m,n);a[0]=strlen(m);b[0]=strlen(n);for(i=1;i<=a[0];i++){a[i]=m[a[0]-i]-'0';}for(i=1;i<=b[0];i++){b[i]=n[b[0]-i]-'0';}temp=max(a[0],b[0]);for(i=1;i<=temp;i++){c[i]=a[i]+b[i];}for(i=1;i<=temp;i++){c[i+1]+=c[i]/10;c[i]%=10;}if(c[temp+1]>0) {temp++;}printf("高精度加法:\n");for(i=temp;i>0;i--){printf("%d",c[i]);}printf("\n");f=compare(a,b);printf("高精度减法: \n");if(f==0) {printf("0");}else if(f==1){for(i=1;i<=a[0];i++){if(a[i]<b[i]){a[i+1]--;a[i]+=10;}d[i]=a[i]-b[i];}while(d[a[0]]==0) {a[0]--;} for(i=a[0];i>0;i--){printf("%d",d[i]);}}else if(f==0){for(i=1;i<=b[0];i++){if(a[i]>b[i]){b[i+1]--;b[i]+=10;}d[i]=b[i]-a[i];}while(d[b[0]]==0){ b[0]--;} printf("-"); for(i=b[0];i>0;i--){printf("%d",d[i]);}}return 0;
}
(4)代码解读:
①本题使用c语言编写
②首先是头文件,除去标准的头文件,由于需要得到输入字符串的位数,我们用:#include<string.h>。
我们先编写简单的max和compare函数,分别用于输出两个数的较大者和比较两个已经存入数组的数。
主函数main()中,定义char m[100],n[100]储存输入的两个数,int型的a[102],b[102],c[102],d[102],分别储存:输入的数a的数组形式,输入b的数组形式,加法的结果,减法的结果,为了编码的方便,可以数组可以空出0位,用于储存m、n的长度,即:
a[0]=strlen(m); b[0]=strlen(n);
还有标准输入scanf()输入m、n。
加法中的进位处理就是上面题目分析的2、3式。
然后标准输出printf(“%d”,c[])
计算减法之前,先把compare(a,b)的结果存到f,如果f==0,两数相等直接输出0;
若f==1,且如果a[i]<b[i]即当前被减数的这一位数字大于减数,那么:
a[i+1]-- ; a[i]+=10;
完成借位操作。如果a[i]>b[i]出现负值,若是出现在开头,再输出一个负号就行了。最后标准输出printf(“%d”,d[])。
(5)测试数据:

题目三:堆栈模拟
(1)题目描述:编写一个程序模拟堆栈,要求能够模拟入栈、出栈、返回栈顶元素等基本操作。栈中元素可用整数代替。不能使用C++模板库预定义的类型。程序运行中可输入多组入栈、出栈操作,每次操作后展示栈中元素。
(2)题目分析:本题是一个手动模拟栈结构的题目。
我们首先要知道栈的基本的定义,栈是一种限定在表尾进行插入和删除的线性表,允许插入和删除的一端叫栈顶(top),另一端叫做栈尾(bottom)。栈是一种后进先出的数据结构,简称LIFO结构。
还有就是进栈操作(push)和出栈操作(pop),也就是我们常说的"压栈”和“弹栈”操作,在实际的编写过程中,我们也可以就使用push和pop表示这两种操作,此外,题目要求能够展示栈的内容,所以我们就再设置一个display函数,来完成整个栈的内容输出。
结构体定义stack表示栈,top和bottom分别表示栈顶和栈底。进栈操作就相当于把当前的参数作为栈顶放入栈中,而出栈操作就是将当前的栈顶元素作为返回值。展示栈中元素只需要从顶端不断的循环输出栈中的数即可。
(3)代码展示:
#include <stdio.h>
#include <stdlib.h>
typedef struct stack
{char data[100];int top;int buttom;
} stack;
stack * CreateStack()
{stack * st = (stack*)malloc(sizeof(stack));st->top = st->buttom = 0;return st;
}
void pop(stack * st,char data)
{int n = st->top;while(n != st->buttom){if(st->data[n-1]==data){st->top = n-1;break;}n--;}}
void push(stack * st,char data)
{st->top++;st->data[st->top] = data;
}
void display(stack * st)
{int n = st->top;while(n!=st->buttom){printf("%c ",st->data[n-1]);n--;}printf("\n");
}
int main()
{int l,i,j,k,m,num[100],a[100];stack * st;st = CreateStack();printf("本次输入的栈组数为:");scanf("%d",&l);printf("本次栈的容积分别为:");for(i=0;i<l;i++){scanf("%d",&num[i]);} for(k=0;k<l;k++){i = num[k];j = num[k];for(m=i;m>0;m--){scanf("%d",&a[m]);push(st,a[m]);printf("%c入栈后,栈内元素为:",a[m]);display(st);}for(m=1;m<=j;m++){pop(st,a[m]);printf("%c出栈后,栈内元素为: ",a[m]);display(st);}}return 0;
}
(4)代码解读:
①本题使用c语言编写。
②头文件中除去#include<stdio.h>,还是用到#include<stdlib.h>。
首先结构体定义stack栈,定义栈的数据位data[],同时定义顶部top和尾部bottom。接下来定义函数pop和push参考数据结构中栈的表示,使用链表比较方便。pop和push的参数都设为一个数组(栈)和一个字符(表示需要操作的数或字符)。
push的关键在于,栈不满时:将栈顶指针加1,再将新的插入元素赋值给栈顶空间。
s->top++;s->data[s->top] = e;
e为需要操作的字符;
pop同理:在栈不满时:将要删除的栈顶元素赋值给e,再将栈顶减1
*e = s->data[s->top];s->top--;
题目四:BMP位图压缩解压缩
(1)题目描述:编写一个程序,可以在命令行输入参数,完成指定文件的缩放,并存储到新文件,命令行参数如下:
zoom file1.bmp 200 file2.bmp
第一个参数为可执行程序名称,第二个参数为原始图像文件名,第三个参数为缩放比例(百分比),第四个参数为新文件名。
(2)题目分析&代码解读:做这道题,我们首先要知道BMP文件它的存储方式,参考网上的解答:
BMP图片的存储:
1:位图头文件数据结构,它包含BMP图像文件的类型、显示内容等信息;2:位图信息数据结构,它包含有BMP图像的宽、高、压缩方法,以及定义颜色等信息;3:调色板,这个部分是可选的,有些位图需要调色板,有些位图,比如真彩色图(24位的BMP)就不需要调色板;4:位图数据,这部分的内容根据BMP位图使用的位数不同而不同,在24位图中直接使用RGB,而其他的小于24位的使用调色板中颜色索引值。
编写时,我们分别编写一个存储头文件数据结构的结构体
tagBITMAPFILEHEADER
接着编写的是存储位图信息的结构体
tagBITMAPINFOHEADER
详细的每个功能在注释中有,我参考了CSDN上的博文,链接:
https://blog.csdn.net/JTang_TYX/article/details/78940234
图片缩小的原则就是按照一定的比例从范围内的像素点中抽去像素点。而放大的原则正好相反,将一个或多个像素点按照比例复制在其周围。
我们定义的函数:
Bmp_Bigger_And_Smaller
用来完成BMP位图的放大(bigger)和缩小(smaller),在该函数中,我们通过fopen得到两张BMP位图,通过一开始的结构体中的old_width,old_height获取到图片原来的宽和高。新图片的宽和高就是
比例*原宽和高代码中:new_height = bili * old_height;new_width = bili * old_width;
然后将修改过后的头信息写入新照片,通过
memcpy(pucDest+j*3,pucSrc+dwsrcX*3,3);
进行数据拷贝。
其实这种算法是已经成为定式了,属于那种通用的算法。
第四题和第五题都要在命令行中完成参数输入,我们通过给main函数赋参数:
int main(int argc, char* argv[])
第一个argc表示传入参数的数目,argv[]表示传入的是哪些参数。本题中我们是要按照 zoom.exe file1.bmp bili file2.bmp的格式输入,由于Bmp_Bigger_And_Smaller函数最后两个参数是文件名,我们就给它传argv[1]和argv[3],前面两个参数为old_head,old_info,即原图的头文件数据结构体和位图信息。
3)代码展示:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include <stdlib.h>
#pragma pack(1)
typedef struct tagBITMAPFILEHEADER
{unsigned short bfType; //保存图片类型。 'BM'(1-2字节) unsigned long bfSize; //位图文件的大小,以字节为单位(3-6字节,低位在前)unsigned short bfReserved1;//位图文件保留字,必须为0(7-8字节)unsigned short bfReserved2;//位图文件保留字,必须为0(9-10字节)unsigned long bfOffBits; //RGB数据偏移地址,位图数据的起始位置,以相对于位图(11-14字节,低位在前)
}BITMAPFILEHEADER;
typedef struct tagBITMAPINFOHEADER
{unsigned long biSize; //本结构所占用字节数(15-18字节)unsigned long biWidth; //位图的宽度,以像素为单位(19-22字节)unsigned long biHeight; //位图的高度,以像素为单位(23-26字节)unsigned short biPlanes; //目标设备的级别,必须为1(27-28字节)unsigned short biBitCount;unsigned long biCompression;unsigned long biSizeImage; unsigned long biXPelsPerMeter;//位图水平分辨率,每米像素数(39-42字节)unsigned long biYPelsPerMeter;//位图垂直分辨率,每米像素数(43-46字节)unsigned long biClrUsed; //位图实际使用的颜色表中的颜色数(47-50字节)unsigned long biClrImportant;
}BITMAPINFOHEADER;
void Bmp_Bigger_And_Smaller(BITMAPFILEHEADER head,BITMAPINFOHEADER info,double bili,char *a,char *b)
{FILE *fpr1=fopen(a,"rb");FILE *fpw2=fopen(b,"wb");if(fpr1==NULL||fpw2==NULL){printf("打开失败!\n");return ;}fread(&head,sizeof(BITMAPFILEHEADER),1,fpr1);fread(&info,sizeof(BITMAPINFOHEADER),1,fpr1);unsigned int old_width=info.biWidth;unsigned int old_height=info.biHeight;unsigned char *src_data=(unsigned char *)malloc(old_width*old_height*3);fseek(fpr1,54,SEEK_SET); fread(src_data,old_width*old_height*3,1,fpr1);unsigned int new_width,new_height;new_width=(int)(bili*old_width+0.5);new_height=(int)(bili*old_height+0.5);head.bfSize=new_width*new_height*3+54;info.biWidth=new_width;info.biHeight=new_height;fwrite(&head,sizeof(BITMAPFILEHEADER),1,fpw2);fwrite(&info,sizeof(BITMAPINFOHEADER),1,fpw2);int i=0,j=0;unsigned long dwsrcX,dwsrcY;unsigned char *pucDest;unsigned char *pucSrc;unsigned char *dest_data=(unsigned char *)malloc(new_width*new_height*3);for(i=0;i<new_height;i++){dwsrcY=i/bili;pucDest=dest_data+i*new_width*3; pucSrc=src_data+dwsrcY*old_width*3;for(j=0;j<new_width;j++){dwsrcX=j/bili;memcpy(pucDest+j*3,pucSrc+dwsrcX*3,3);}}fseek(fpw2,54,SEEK_SET); fwrite(dest_data,new_width*new_height*3,1,fpw2);printf("成功!\n");free(dest_data);free(src_data);fclose(fpr1);fclose(fpw2);
}
int main(int argc, char* argv[])
{BITMAPFILEHEADER old_head;BITMAPINFOHEADER old_info;memset(&old_head,0,sizeof(BITMAPFILEHEADER));memset(&old_info,0,sizeof(BITMAPINFOHEADER));double bili = atof(argv[2])/100.0;printf("%f",bili);Bmp_Bigger_And_Smaller(old_head,old_info, bili,argv[1],argv[3]);return 0;
}
(4)结果展示:

由于原图上传难以看出区别,就不放图片,文件夹中有原图。
题目五:RLE压缩解压缩算法
(1)题目描述:编写一个程序,可以在命令行输入参数,完成指定文件的压缩解压,命令行参数如下:
rle file1 –c(-d) file2
第一个参数为可执行程序名称,第二个参数为原始文件名,第三个参数为压缩或解压缩选项,第四个参数为新文件名
(2)题目分析&代码解读:先介绍一下什么是RLE:
游程编码(Run-Length Encoding, RLE)又称行程长度编码或者变动长度编码法,在控制理论中对于二值图像而言是一种编码方法,对连续的黑,白向像素以不同的码字进行编码。游程编码是一种简单的无损压缩方法,其特点是压缩和解压缩都非常快。该方法是用重复字节和重复次数来简单的描述重复的字节,也就是将一串连续的相同数据转换为特定的格式来达到压缩的目的。
RLE是一种简单的压缩算法,主要用于压缩图像中连续的重复的颜色块。当然RLE并不是只能应用于图像压缩上,RLE能压缩任何二进制数据。原始图像文件的数据有一个特点,那就是有大量连续重复的颜色数据,RLE正好是用来压缩有大量连续重复数据的压缩编码,但对于其他二进制文件而言,由于文件中相同的数据出现概率较少,使用RLE压缩这些数据重复性不强的文件效果不太理想,有时候压缩后的数据反而变大了。
RLE压缩方案是一种极其成熟的压缩方案,其特点是无损失压缩。
代码方面:
1、isrepetition() 函数判断从 src 开始的数据是否是连续重复数据。根据算法要求,只有数裾重复出现两次以上才算作连续重复数据,因此 isrepetitioni() 函数检査连续的3字节是否是相同的数据,如果是则判定为出现连续重复数据。之所以要求至少要 3 字节的重复数据才判定为连续重复数据,是为了尽量优化对短重复数据间隔出现时的压缩效率。
2、如果是连续重复数据,则调用 repetitionlen() 函数计算出连续重复数据的长度,将长度属性字节的最高位罝 1 并向输出缓冲区写入一个字节的重复数据。
3、如果不是连续重复数据,则调用 nonrepetitionlen() 函数计算连续非重复数据的长度,将长度属性字节的极高位罝 0 并向输出缓冲区复制连续的多个非重复数据。
4、rle_decode() 函数是解压缩算法的实现代码,rle_encode实现压缩。
本算法参考的CSDN文章链接,如下:
毕竟和第四题一样,都是通用算法了,而且也没有上课,就参考的文章和算法,如有雷同,纯属意外。 https://blog.csdn.net/zimuzi2019/article/details/106583064
(3)代码展示:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
typedef unsigned char ux;
const ux REPEAT = 0x80; // 1000 0000
const ux FOR_COUNT = 0x7f; // 0111 1111
const int MAX_LEN = 0x7f;int isrepeated(ux* buf, int size)
{// 如果还剩加不到三个,则视为非重复if (size < 3) { return 0;}if ((buf[0] == buf[1]) && (buf[1] == buf[2]))return 1;return 0;
}int repeatedlen(ux* buf, int size)
{int tar = buf[0];int len = 1;while (len < size && len < MAX_LEN && buf[len] == tar) ++len;return len;
}int nonrepeatedlen(ux* buf, int size)
{if (size < 3) return size;int len = 2;int a = buf[0], b = buf[1]; while (len < size && len < MAX_LEN && ((a != b) || (b != buf[len]))){a = b;b = buf[len];++len;}return len;
}
int rLE_encode(ux* inbuf, int insize, ux* outbuf, int outsize){ux* src = inbuf; int inleft = insize; int count = 0; int out_poi = 0; while (inleft > 0){if (isrepeated(src, inleft)){if (out_poi + 2 > outsize) return -1;count = repeatedlen(src, inleft);outbuf[out_poi++] = count | REPEAT;outbuf[out_poi++] = *src;src += count;}else{count = nonrepeatedlen(src, inleft);if (out_poi + count >= outsize) return -1;outbuf[out_poi++] = count;for (int i = 0; i < count; i++)outbuf[out_poi++] = *src++;}inleft -= count;}return out_poi;
}int exe(char* in_name, char* out_name, int ty){FILE *in = fopen(in_name, "rb");FILE *out = fopen(out_name, "wb");if (in == NULL || out == NULL)return -1;ux *inbuf, *outbuf;inbuf = (ux*) malloc((sizeof(ux)) * 1024);outbuf = (ux*) malloc((sizeof(ux)) * 2048);size_t len;if (ty == 0){while ((len = fread(inbuf, sizeof(ux), 1024, in)) != 0){int tmp = rLE_encode(inbuf, len, outbuf, 2048);fwrite(outbuf, sizeof(ux), tmp, out);}}else { while (fread(inbuf, sizeof(ux), 1, in)){int count = (*inbuf) & FOR_COUNT;if ((*inbuf) & REPEAT){fread(inbuf, sizeof(ux), 1, in);for (int i = 0; i < count; i++)outbuf[i] = *inbuf;}else{fread(inbuf, sizeof(ux), count, in);for (int i = 0; i < count; i++)outbuf[i] = inbuf[i];}fwrite(outbuf, sizeof(ux), count, out);}}fclose(in);fclose(out);return 0;
}
int main(int argc, char* argv[]){// 参数错误预判断if (argc != 4){printf("输入格式错误!");return 0;}// 判断操作int ty;if (strcmp(argv[2], "-c") == 0) ty = 0;else if (strcmp(argv[2], "-d") == 0) ty = 1;else {printf("输入格式错误—2");return 0;}int t = exe(argv[1], argv[3], ty);if (t == -1){printf("找不到文件!\n");}else{printf("成功!\n");}return 0;
}
(4)结果展示:
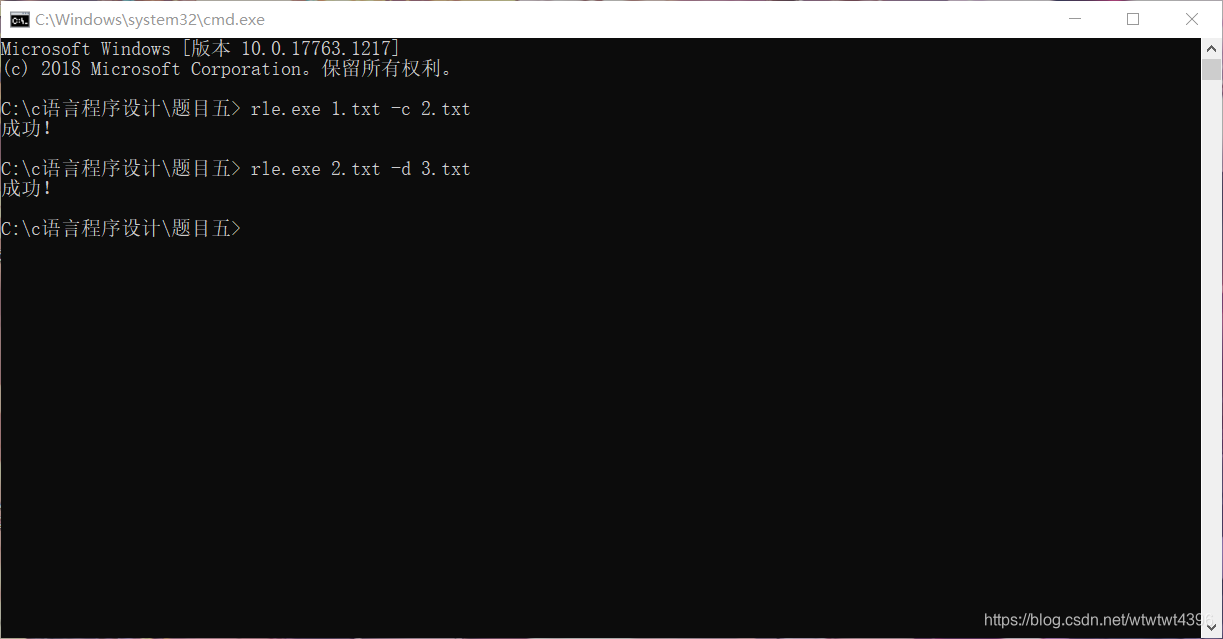
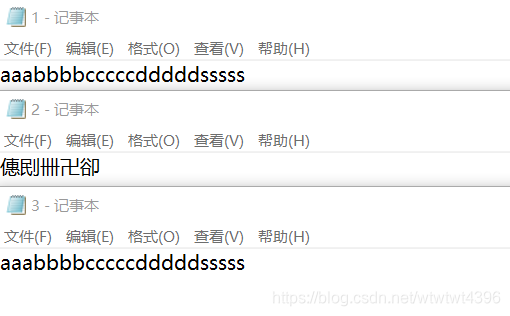
题目六:图书馆管理系统
(1)题目描述:编写一个程序模拟图书管理系统。用户分为管理员和读者两类,分别显示不同文本格式菜单,通过菜单项对应数字进行选择。读者菜单包括借书、还书、查询等功能。管理员菜单包括图书和读者信息录入、修改和删除。图书信息至少应包括:编号、书名、数量,读者信息至少应包括:编号、姓名、所借图书。可根据图书名称或编号进行图书信息查询,可查询某本书现在被哪些读者借走。
命令行参数如下:
Libsim –a(-u) xxxx
第一个参数为可执行程序名称;第二个参数为用户身份,-a表示管理员,-u表示读者;第三个参数为用户名
(2)题目&算法分析:本题并无明确算法,主要是结构体的定义和函数的编写,定义的结构体有Book,Reader,Admin,分别表示图书,读者,管理员,函数方面主要就是借书还书,图书信息的修改与删除,还有图书的查询等等。代码编写的思想就是完成一个一个的函数,主函数中:
int main(int argc, char *argv[])
根据argv[1]是“-a”还是“-u”来决定进入哪一个菜单界面,然后一次根据选项调用函数即可,
本次用的较多的是字符串函数: strcmp和strcpy,分别用来比较字符串和复制字符串,具体用途都学过,在判断输入的书名或人名和库内的书名人名是否相同时,strcmp比较好用。
本代码使用数组完成,语法单一,主要就是调用函数,for循环的遍历,甚至没有出现几次嵌套。就不再赘述。
题目难度不大,但是非常繁琐,如果想要实现更多的操作还要有更多的考虑,本人在此代码中实现了题目要求的内容。
(3)代码展示:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct Book{char bookname[10];char booknumber[10];int bookcount;
}; //定义书籍
typedef struct Reader{char readername[10];char readernumber[10];Book Bookborrow; int borrownum;
};//定义读者
typedef struct Admin{char adminame[10];char adminumber[10];
};//定义管理员
Book books[10];
Reader readers[10];
Admin admin;
//设定的书籍、读者、管理员数量
int numbk=1,numreader=1;
FILE *booklist;
FILE *readerlist;
FILE *borrowlist;
//预设的函数
void log();//登录界面
void readermenu();//读者菜单
void admimenu(); //管理员菜单
void bkborrow();//借书
void bkreturn();//还书
void bksearch();//图书查询
void adbk();//图书添加
void adreader();//用户添加
void chbk();//图书修改
void debk();//图书删除
void rebooklist();
void rereaderlist();
void reborrowlist();
void upbooklist();
void upreaderlist();
void upborrowlist();
void logad()
{int c;printf("输入您的选择: \n");printf("1.进入管理员操作界面 \n");printf("2.退出 \n");scanf("%d",&c);if(c==1){admimenu();return;}else if(c==2){exit(0);}
}
void logreader()
{int c;printf("输入您的选择: \n");printf("1.进入读者操作界面 \n");printf("2.退出 \n");scanf("%d",&c);if(c==1){readermenu();}else if(c==2){exit(0);}
}
void readermenu()
{int x;printf("*****************\n");printf("* 请输入你的选择: *\n");printf("* 1.图书查询 *\n");printf("* 2.图书归还 *\n");printf("* 3.图书借阅 *\n");printf("* 4.返回 *\n");printf("*****************\n");scanf("%d",&x);switch(x){case 1:bksearch();return;case 2:bkreturn();return;case 3:bkborrow();return;case 4:return;}
}
void admimenu()
{int x;printf("******************\n");printf("* 请选择你的操作: \n");printf("* 1.图书信息录入 *\n");printf("* 2.读者信息录入 *\n");printf("* 3.图书信息修改 *\n");printf("* 4.图书信息删除 *\n");printf("* 5.返回 *\n"); printf("******************\n");scanf("%d",&x); switch(x){case 1:adbk();return;case 2:adreader();return;case 3:chbk();return;case 4:debk();return;case 5:return;}return;}
void bkborrow()
{char s1[10],s2[10];int x=numbk,y=numreader;int i;system("cls");printf("请输入您的编号或姓名:\n");scanf("%s",s1);for(i=0;i<y;i++){if((strcmp(readers[i].readername,s1)==0)||(strcmp(readers[i].readernumber,s1)==0)){break;}} printf("请输入您所借图书的编号或书名: \n");scanf("%s",&s2);for(i=0;i<x;i++){if((strcmp(books[i].booknumber,s2)==0)||(strcmp(books[i].bookname,s2)==0)){if(books[i].bookcount>0){books[i].bookcount--;readers[i].Bookborrow=books[i];printf("成功!\n");}else{printf("失败,有可能数量为0 \n");}return;}}return;
}
void bkreturn()
{char s1[10],s2[10];int x=numbk,y=numreader;int i,j;system("cls");printf("请输入您的编号或姓名:\n");scanf("%s",&s1);for(i=0;i<y;i++){if((strcmp(readers[i].readername,s1)==0)||(strcmp(readers[i].readernumber,s1)==0)){break;}} printf("请输入您所还图书的编号或书名: \n");scanf("%s",&s2);for(i=0;i<x;i++){if((strcmp(books[i].booknumber,s2)==0)||(strcmp(books[i].bookname,s2)==0)){if(books[i].bookcount>0){books[i].bookcount++;readers[j].Bookborrow.bookcount=0;memset(&readers[j].Bookborrow.bookname,0,sizeof(readers[j].Bookborrow.bookname));memset(&readers[j].Bookborrow.booknumber,0,sizeof(readers[j].Bookborrow.booknumber));printf("成功!\n");}else{printf("失败,有可能数量为0 \n");}return;}}return;
}
void bksearch()
{char s[10];int i,j;int x=numbk,y=numreader;system("cls");printf("请输入想查询的书名: \n");scanf("%s",s);for(i=0;i<x;i++){if(strcmp(books[i].bookname,s)==0){printf("信息:书名:%s 编号:%s 数量:%d \n",books[i].bookname,books[i].booknumber,books[i].bookcount);for(j=0;j<y;j++){if(strcmp(readers[j].Bookborrow.bookname,books[i].bookname)==0){printf("借阅者: \n");printf("%s\n",readers[j].readername);}}return;}}printf("未找到。 \n");return;}
void adbk()
{char s[10];int i,x=numbk;system("cls");printf("请输入你要添加的图书编号: \n");scanf("%s",&s);for(i=0;i<x;i++){if(strcmp(books[i].booknumber,s)==0){printf("已使用! \n");return;}}if(x<10){strcpy(books[x].booknumber,s);printf("输入书名: \n");scanf("%s",&books[x].bookname);printf("输入数量: \n");scanf("%d",&books[x].bookcount);printf("成功! \n");x++;return;}return;
}
void adreader()
{char s[10];int i,x=numreader;system("cls");printf("请输入您要添加的读者编号: \n");scanf("%s",&s);for(i=0;i<x;i++){if(strcmp(readers[i].readername,s)==0){printf("已使用! \n");return ;}}if(x<10){strcpy(readers[x].readernumber,s);printf("输入姓名: \n");scanf("%s",&readers[x].readername);printf("成功! \n");x++;}
}
void chbk()
{char s[10];int i,x=numbk,a;system("cls");printf("请输入修改的图书编号: \n");scanf("%s",&s);for(i=0;i<x;i++){if(strcmp(books[i].booknumber,s)==0){printf("信息:",books[i].bookname,books[i].booknumber,books[i].bookcount);}printf("请输入修改的内容: \n");printf("1.编号 \n");printf("2.书名 \n");printf("3.数量 \n");scanf("%d",&a);switch(a){case 1:{printf("新编号: \n");scanf("%s",&books[i].booknumber);}case 2:{printf("新书名: \n");scanf("%s",&books[i].bookname);}case 3:{printf("新数量: \n");scanf("%s",&books[i].bookcount);}}}return;
}
void debk()
{char s[10];int i,j,x=numbk;system("cls");printf("请输入想要删除的图书编号: \n");scanf("%s",&s);for(i=0;i<x;i++){if(strcmp(books[i].booknumber,s)==0){for(j=i;j<x;j++){books[j]=books[j+1];}}}memset(&books[x].bookname,0,sizeof(books[x].bookname));memset(&books[x].booknumber,0,sizeof(books[x].booknumber));books[x].bookcount=0;printf("成功! \n");x--;return;
}
void first()
{int i;strcpy(readers[0].readernumber,"001");strcpy(readers[0].readername,"tom");readers[0].Bookborrow.bookcount=0;memset(&readers[0].Bookborrow.bookname,0,sizeof(readers[0].Bookborrow.bookname,0));memset(&readers[0].Bookborrow.booknumber,0,sizeof(readers[0].Bookborrow.booknumber,0));for(i=1;i<10;i++){memset(&readers[i].readername,0,sizeof(readers[i].readername));memset(&readers[i].readernumber,0,sizeof(readers[i].readernumber));readers[0].Bookborrow.bookcount=0;memset(&readers[i].Bookborrow.bookname,0,sizeof(readers[i].Bookborrow.bookname));memset(&readers[i].Bookborrow.booknumber,0,sizeof(readers[i].Bookborrow.booknumber));}strcpy(books[0].booknumber,"001");strcpy(books[0].bookname,"book1");books[0].bookcount=5;for(i=1;i<10;i++){memset(&books[i].bookname,0,sizeof(books[i].bookname));memset(&books[i].booknumber,0,sizeof(books[i].booknumber));} strcpy(admin.adminumber,"001");strcpy(admin.adminame,"jack");return;
}
void rebooklist()
{booklist=fopen("books.txt","r");while(fscanf(booklist,"%s %s %d\n",books[numbk].booknumber,books[numbk].bookname,&books[numbk].bookcount)!=EOF){numbk++;} fclose(booklist);
}
void rereaderlist()
{readerlist=fopen("readers.txt","r");while(fscanf(readerlist,"%s %s %d\n",readers[numreader].readernumber,readers[numreader].readername,&readers[numreader].borrownum)!=EOF){numreader++;}fclose(readerlist);
}
void reborrowlist()
{int i,j;for(i=0;i<numreader;i++){readers[i].borrownum=0;for(j=0;j<100;j++){memset(&readers[i].Bookborrow.booknumber,0,sizeof(readers[i].Bookborrow.booknumber));memset(&readers[i].Bookborrow.bookname,0,sizeof(readers[i].Bookborrow.bookname));}}borrowlist=fopen("borrow.txt","r");char bookname[200];char readername[200];while(fscanf(borrowlist,"%s %s\n",bookname,readername)!=EOF){for(i=0;i<numreader;i++){if(strcmp(readers[i].readername,readername)==0){strcpy(readers[i].Bookborrow.bookname,bookname);readers[i].borrownum++;} }}fclose(borrowlist);
}
void upbooklist()
{int i,j;booklist=fopen("books.txt","w");for(i=0;i<numbk;i++){fprintf(booklist,"%s %s %d\n",books[i].booknumber,books[i].bookname,books[i].bookcount);}fclose(booklist);
}void upreaderlist()
{int i;readerlist=fopen("readers.txt","w");for(i=0;i<numreader;i++){fprintf(readerlist,"%s %s %d\n",readers[i].readernumber,readers[i].readername,readers[i].borrownum);}fclose(readerlist);
}
void upborrowlist()
{int i,j;borrowlist=fopen("borrow.txt","w");for(i=0;i<numreader;i++){for(j=0;j<readers[i].borrownum;j++){fprintf(borrowlist,"%s %s\n",readers[i].Bookborrow.bookname,readers[i].readername);}}fclose(borrowlist);
}
int main(int argc , char *argv[])
{ first();if(strcmp(argv[1],"-a")==0){while(1){rebooklist();rereaderlist();reborrowlist();logad();upbooklist();upreaderlist();upborrowlist();} }else if(strcmp(argv[1],"-u")==0){while(1){rebooklist();rereaderlist();reborrowlist();logreader();upbooklist();upreaderlist();upborrowlist();}}else{printf("错误参数!");}return 0;
}
(4)结果展示
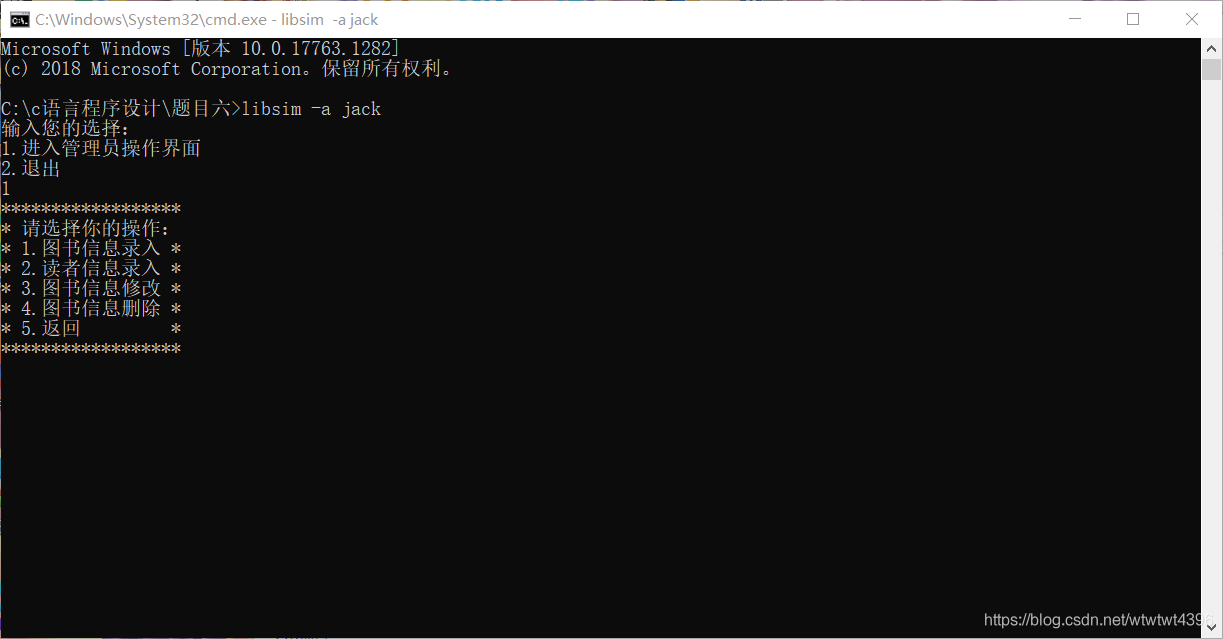
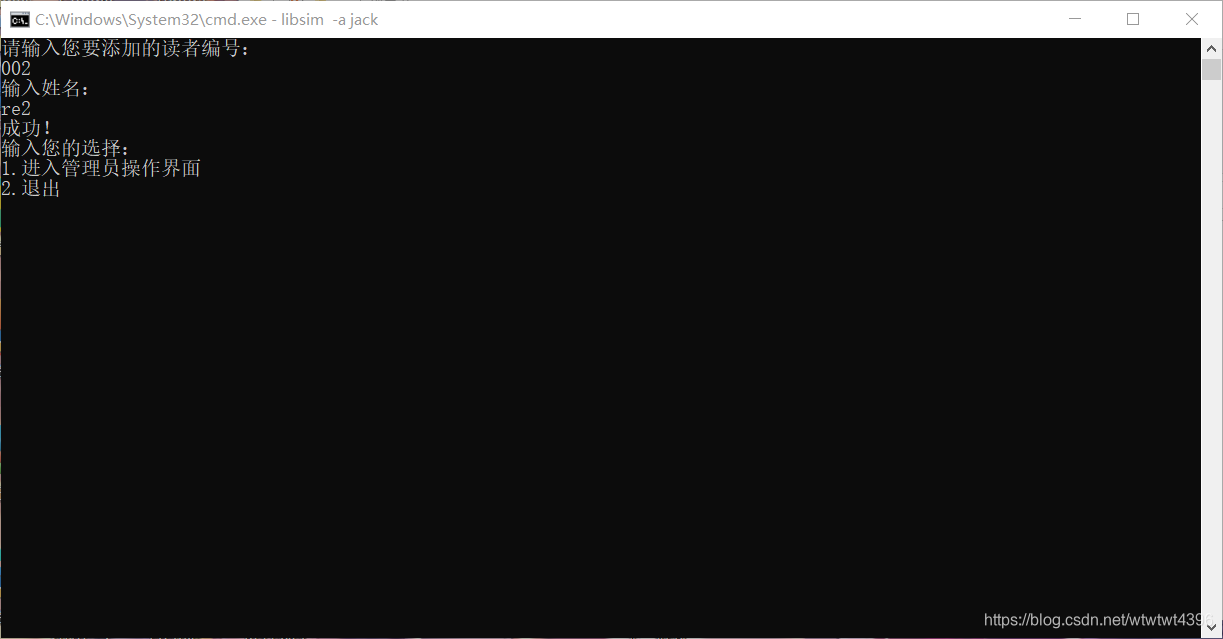
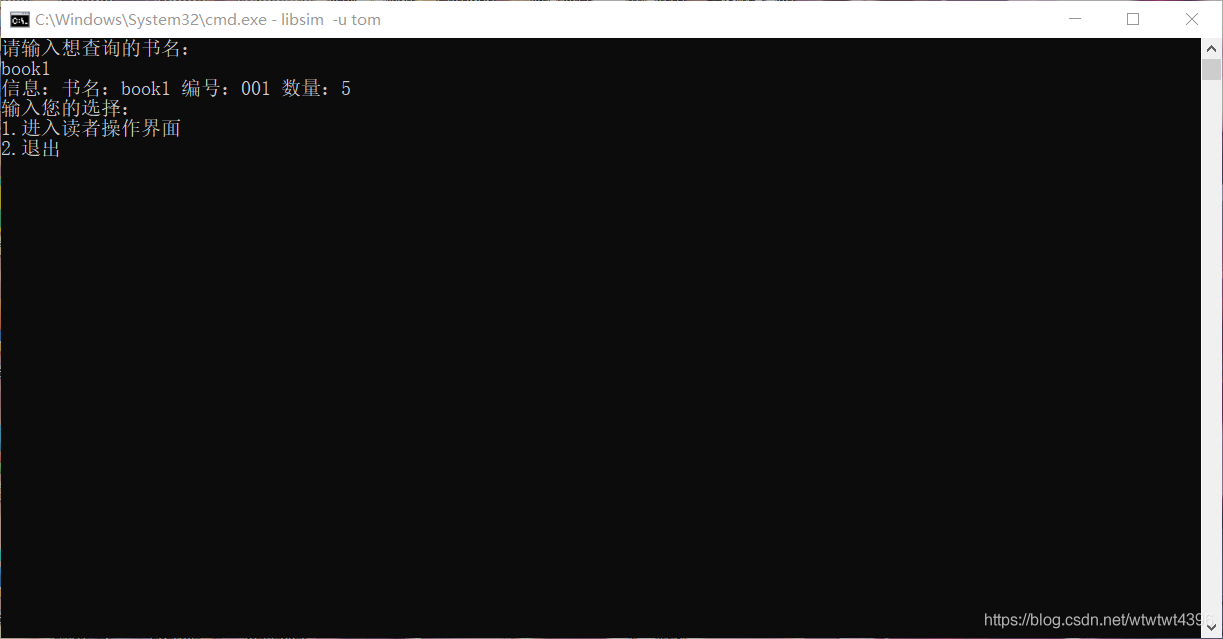
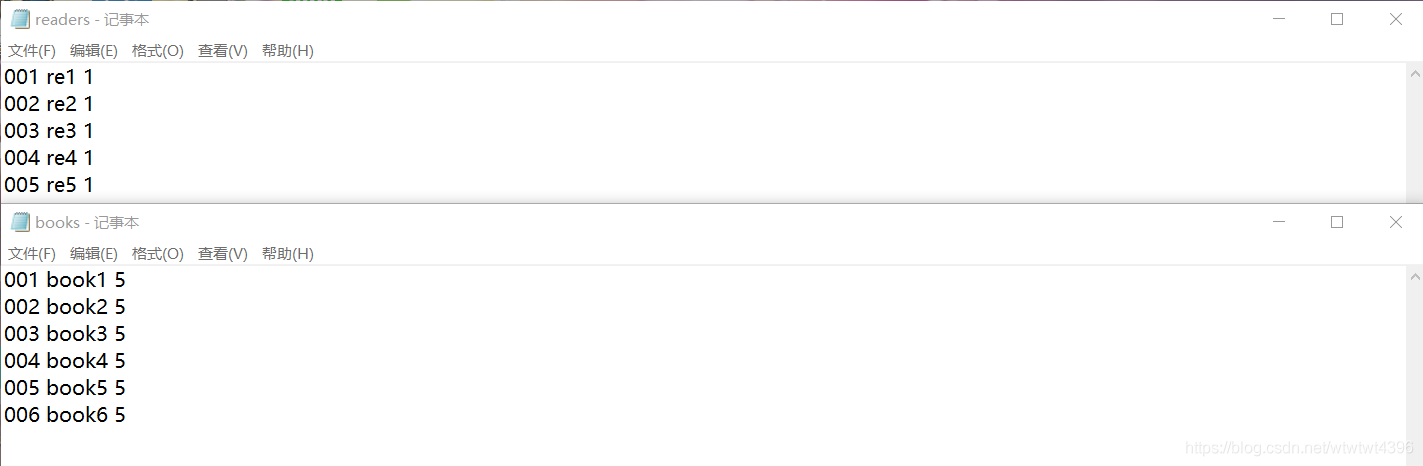
方式较多无法全部展示,具体展示已在验收时完成,这里就挑选了几个功能展示。
《课程设计》总结
本次课程设计让我接触到了一些比较深层次的算法和知识点,算是对上学期部分内容的补充,由于本学期主要在学习Python,我甚至一开始都对c语言的内容有些遗忘,还是要多自己编写代码,多练习才能有所进步。
这篇关于c语言程序设计实验报告——西安电子科技大学(存在问题,仅供参考)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







