本文主要是介绍2003-2022年地级市-财政收支明细数据(企业、个人所得税、科学、教育、医疗等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2003-2022年地级市-财政收支明细数据(企业、个人所得税、科学、教育、医疗等)
1、时间:2003-2022年
2、指标:行政区划代码、年份、地区、一般公共预算收入、一般公共预算-税收收入、一般公共预算-税收收入-增值税收入、一般公共预算-税收收入-企业所得税收入
一般公共预算-税收收入-企个人所得税收入、一般公共预算支出、一般公共预算-科学支出、一般公共预算-教育支出、一般公共预算-社会保障和就业支出、一般公共预算-医疗卫生与计划生育支出、
3、来源:地方统计局
4、范围:290个地级市
5、缺失情况:个别城市存在缺失,内含原始数据、线性插值、回归填补三个版本
具体缺失情况参看下面链接内数据预览,缺失值已标黄:
链接:https://pan.baidu.com/s/1xwN4HeSLcy5JnD1SzxVvVQ
提取码:dy9q
6、下载链接:
2003-2022年全国各地级市财政收支明细数据(企业、个人所得税、科学、教育、医疗等)https://download.csdn.net/download/m0_71334485/88492900![]() https://download.csdn.net/download/m0_71334485/88492900
https://download.csdn.net/download/m0_71334485/88492900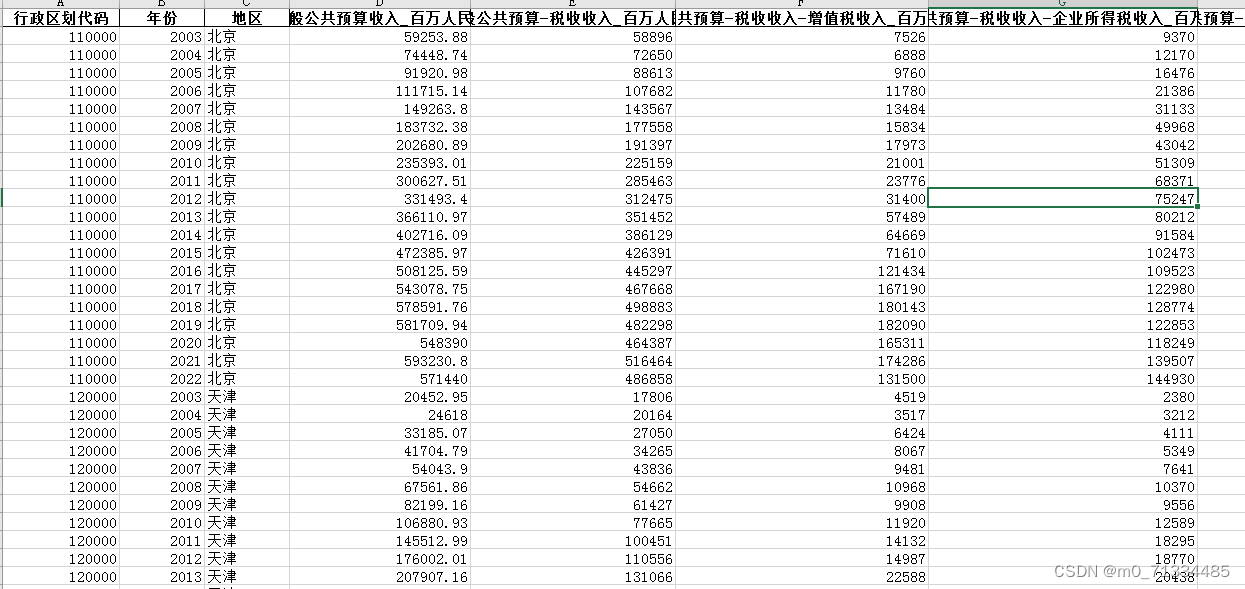
这篇关于2003-2022年地级市-财政收支明细数据(企业、个人所得税、科学、教育、医疗等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







