本文主要是介绍湖大2022秋数据挖掘期末作业,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注意一下:要求用图神经网络,但是我没写过图神经网络,用的是普通的神经网络,所有的层都是全连接层。
实验内容
基于知识图谱(Knowledge Graph)的基因关系预测
知识图谱主要目标是用来描述真实世界中存在的各种实体和概念,以及他们之间的关系,因此可以认为是一种语义网络。从发展的过程来看,知识图谱是在NLP的基础上发展而来的。知识图谱和自然语言处理NLP有着紧密的联系,都属于比较顶级的AI技术。知识图谱可以用来更高的查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。
1. 了解知识图谱的目的,内容以及构建流程
2. 对给定数据集进行图神经网络的特征学习及特征表征
3. 掌握知识图谱和图神经网络的关系预测方法,编程实现合成致死数据集的关系预测。
4. 针对数据集实现知识图谱的关系预测方法性能分析及比较。
对给定数据集构建神经网络完成预测,并进行性能评估:
数据集分析:
共4个文件,其中gene_list中显示了所有的基因编号,共计6375个基因
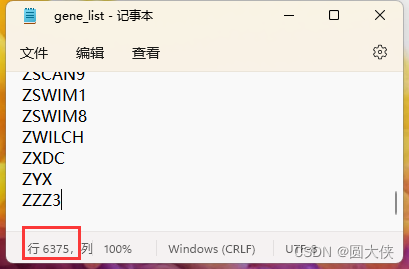
还有两个文件展示了基因的相似度,分别是PPI相似度和GO相似度。它们各占6375行和6375列,这与基因的数量是一致的,因此可以推测它们和每个基因是一一对应的,可以用来表征基因的特征。
以下是GO相似度的部分数据:
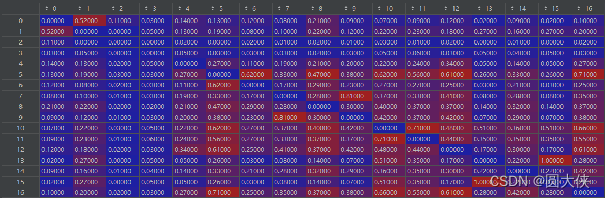
可以发现这是一个对称阵,因为相似程度符合对称性,即如果A与B的相似性为x,那么B与A的相似性也为x。
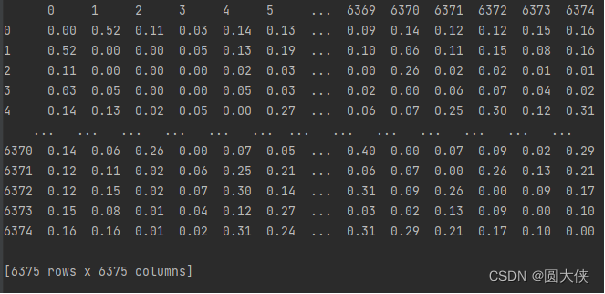
GO相似性的全貌,一个6375*6375的对称矩阵,对角线元素为0
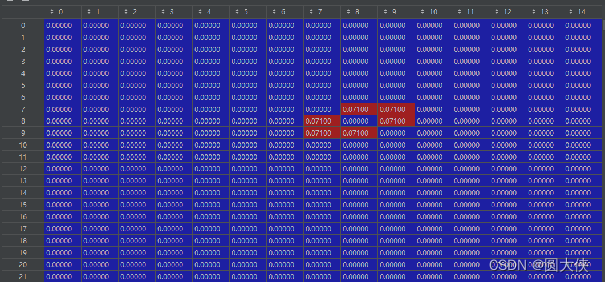
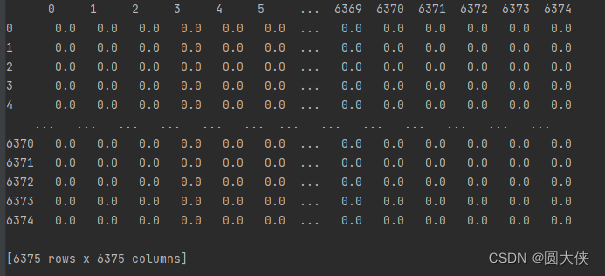
上图是PPI相似度,与GO相似度不同的是,PPI矩阵的绝大部分位置取值为0。
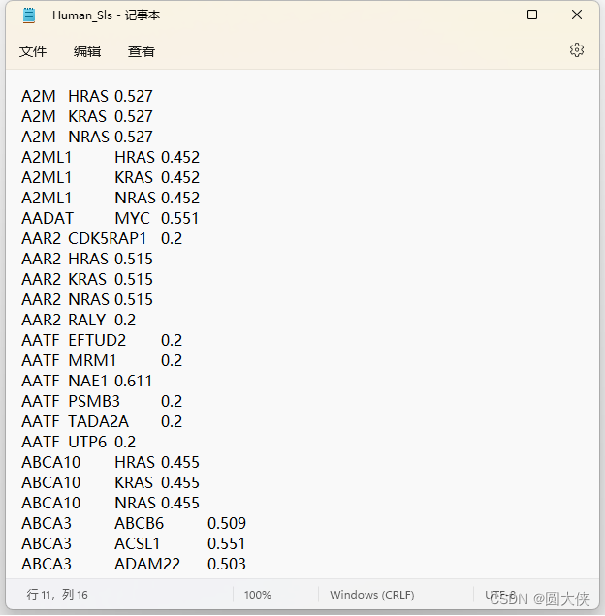
最后一个文件如上图所示,表示了两个基因相互作用对癌细胞的致死性,但是这只给出了部分基因之间的致死性,共计19667个,而全部基因的组合有6375*6374/2=20317125个,已知的基因组合仅占全部组合的不到千分之一。我们的目的就是从已知的基因组合推测出未的知基因组合的致死性,从而大大减少人力物力。
我设计了如下神经网络来解决这个问题:
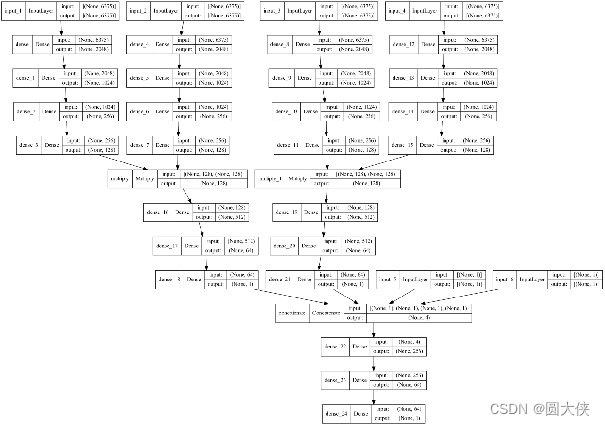
神经网络的全局图
下面我逐步讲解其组成。
该神经网络包括6个输入层,如图所示的input_1到input_6共计6层。
其中input_1和input_2输入的是基因1和基因2的GO特征,是一个长度为6375的向量。随后进入4个全连接层进行特征提取,最后输出长度为128的向量,如下图所示:
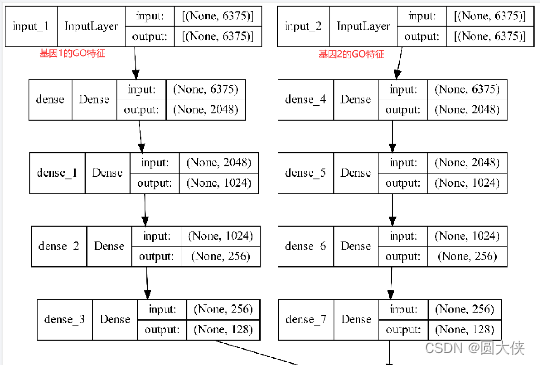
input_3和input_4与上图类似,它输入的是基因1和基因2的PPI特征。除了输入值的含义不同,其网络结构与上图完全一致。
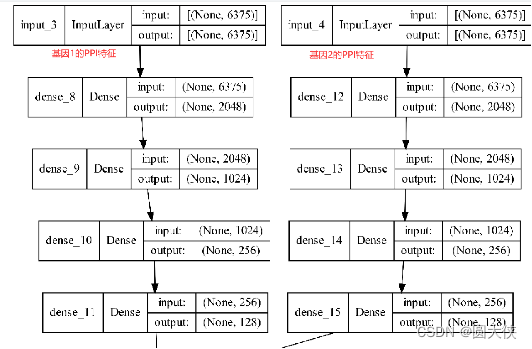
由于input_1和input_2最终产生的128维特征向量反映了两个基因之间的联系,且两者的网络结构是对称的,输入向量的含义也是对称的,所以可以将两者的结果相乘,使得基因1和基因2的内在联系能够被网络所识别。
Input3_和input_4进行完全相同的操作。同时为了进一步提取特征,我们将相乘后的结果送入3个全连接层,最后得到一个数值。如下图所示:
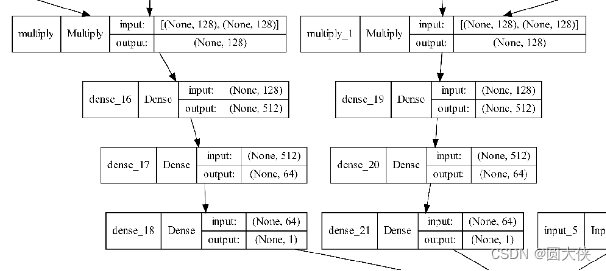
到目前为止,基因1、基因2与其他全部基因的GO相似度、PPI相似度中所包含的信息就被提取出来了。为了进一步提取基因1和基因2之间的联系,我将基因1与基因2的GO相似度和PPI相似度作为一个数值单独输入模型,即输入给模型的输入层input_5和input_6,至此为止,模型所有的输入层就都被用上了。
我将前面提取到的两个特征和input_5与input_6做连接,形成一个长度为4的向量,最后通过全连接层的拟合,得到一个长度为1的向量,即最终预测的致死率:
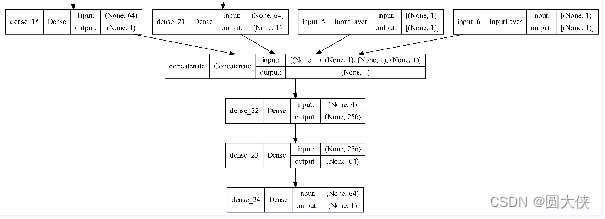
构建好模型后,划分数据集,设置好超参数,就可以训练模型了。
模型除了最后一层的激活函数为 “sigmoid”外,其余层的激活函数都为”relu”。最后一层设置为sigmoid是合理的,因为我们致死率的预测值位于0~1之间,而sigmoid的值域也落在(0,1)
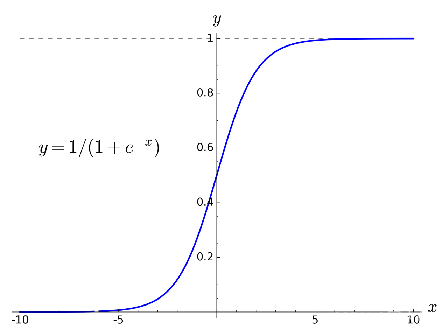
Sigmoid的图像,其值域为(0,1)
我将数据集划分为80%的训练集和20%的测试集,用训练集训练模型,并用测试集来评估模型的性能。使用mse和mae指标来评估模型的性能,选择mse作为损失函数,使用adam优化器进行梯度下降算法的优化。
本人采用的CPU是英特尔的12700,采用的显卡是英伟达的3090Ti,训练时间非常短,一个epoch在10ms左右,仅使用CPU训练所花费的时间也是可接受的,CPU完成一个epoch预计在1s内,完成全部训练可能需要耗费数分钟。为了节约计算资源,采用早停法进行训练,最大训练次数设置为50次,实际上在训练了30-40次左右就会停下来。
下图是训练过程中的MAE变化趋势:
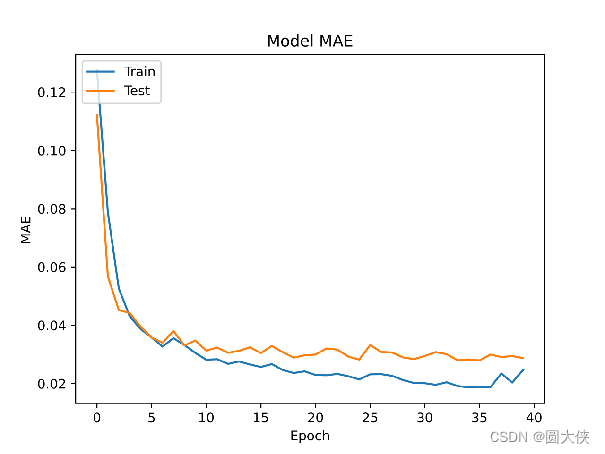
以下是训练过程中MSE,即损失函数的变化趋势。
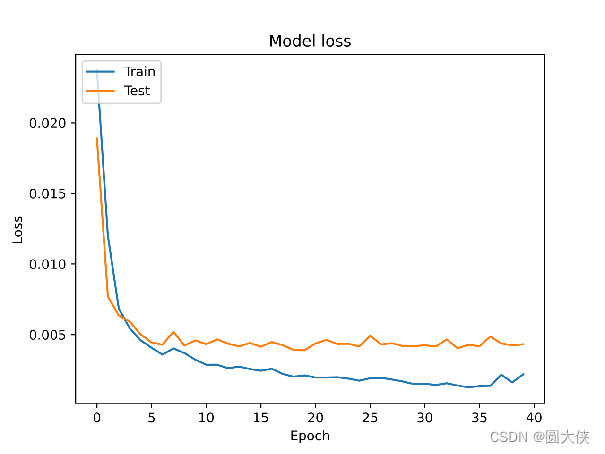
虽然有轻微的过拟合,但训练的效果非常好,预测致死率的平均误差在4%以内。
为了更直观的看到预测值和真实的差距,以下是部分真实值对应的预测值,其中第一行是真实的致死率,第二行是预测的致死率:

![]()
可以直观的看到,绝大部分预测值和真实值是几乎一致的。说明我的模型取得了成功的预测效果。
附上代码:
import pandas as pd
from keras.layers import *
from keras.models import Model
from tensorflow.keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
from sklearn.model_selection import train_test_split
from keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as pltdef get_model(input_shape):input_layers=[]for item in input_shape:x=Input(shape=item)input_layers.append(x)out_layers=[]for i in range(4):x=input_layers[i]x=Dense(units=2048,activation='relu')(x)x=Dense(units=1024,activation='relu')(x)x=Dense(units=256,activation='relu')(x)x=Dense(units=128,activation='relu')(x)out_layers.append(x)x1=Multiply()([out_layers[0],out_layers[1]])x1=Dense(units=512,activation='relu')(x1)x1=Dense(units=64,activation='relu')(x1)x1=Dense(units=1)(x1)x2=Multiply()([out_layers[2],out_layers[3]])x2=Dense(units=512,activation='relu')(x2)x2=Dense(units=64,activation='relu')(x2)x2=Dense(units=1)(x2)x=Concatenate()([x1,x2,input_layers[-2],input_layers[-1]])x=Dense(units=256,activation='relu')(x)x=Dense(units=64,activation='relu')(x)outputs=Dense(units=1,activation='sigmoid')(x)model=Model(input_layers,outputs)model.compile(Adam(),'mse',['mae'])return modelPPI = pd.read_csv('dataset1/Gene_PPI_similarity.txt',header=None,sep=' ')
#读取PPI数据集GO = pd.read_csv('dataset1/Gene_GO_similarity.txt',header=None,sep=' ')
#读取GO数据集f=open('dataset1/gene_list.txt')
GENE=dict([])
for i,line in enumerate(f):GENE[line.strip()]=i
#读取基因编号和序号的映射关系f=open('dataset1/Human_Sls.txt')
labels=[]for line in f:g1,g2,v0=line.strip().split('\t')v0=float(v0)labels.append((GENE[g1],GENE[g2],v0))
#读取标签X=[]
Y=[]for item in labels:(g1,g2,v0)=itemtemp=[GO[g1].to_numpy(),GO[g2].to_numpy(),PPI[g1].to_numpy(),PPI[g2].to_numpy(),GO[g1][g2],PPI[g1][g2]]X.append(temp)Y.append(v0)#生成样本X和标签Yx_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.2,random_state=42)temp=[]
for i in range(6):temp.append(np.array([item[i] for item in x_train]))x_train={}
for i in range(6):x_train[f'input_{i+1}']=temp[i]temp=[]
for i in range(6):temp.append(np.array([item[i] for item in x_test]))x_test={}
for i in range(6):x_test[f'input_{i+1}']=temp[i]y_train=np.array(y_train)
y_test=np.array(y_test)
#生成训练集和测试集的样本和标签model=get_model([(6375,),(6375,),(6375,),(6375,),(1,),(1,)])plot_model(model,to_file="model.png",show_shapes=True,dpi=1000)monitor=EarlyStopping(patience=20,restore_best_weights=True)
history=model.fit(x_train,y_train,batch_size=128,epochs=50,validation_data=(x_test,y_test),callbacks=[monitor])# 绘制训练 & 验证的MAE
plt.plot(history.history['mae'])
plt.plot(history.history['val_mae'])
plt.title('Model MAE')
plt.ylabel('MAE')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.savefig('2.jpg',dpi=800)
plt.show()# 绘制训练 & 验证的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.savefig('3.jpg',dpi=800)
plt.show()这篇关于湖大2022秋数据挖掘期末作业的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









