本文主要是介绍【日常记录】关于LinkedHashMap中key为数字字符串根据compareTo排序的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天在修复Bug的时候,在项目中发现有这样一段代码(为了方便,下面用一个例子进行演示)。
项目中使用了LinkedHashMap key为Long类型,value为String类型。
并且,LinkedHashMap 使用Stream流 对key进行升序的排列,看了代码貌似没有什么问题。
LinkedHashMap<Long, String> linkedHashMap = new LinkedHashMap<>();linkedHashMap.put(12L, "测试1");linkedHashMap.put(26L, "测试2");linkedHashMap.put(8L, "测试3");linkedHashMap.put(120L, "测试4");linkedHashMap.put(4L, "测试5");LinkedHashMap<Long, String> resLinkHashMap = linkedHashMap.entrySet().stream().sorted((o1, o2) -> {String key1 = o1.getKey().toString();String key2 = o2.getKey().toString();return key1.compareTo(key2);}).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));System.out.println("resLinkHashMap = " + resLinkHashMap);
运行后结果是这样的:
resLinkHashMap = {12=测试1, 120=测试4, 26=测试2, 4=测试5, 8=测试3}
发现结果并没有按照key进行从小到大的规则进行排序。
于是下面分析了String中的compareTo方法 排序规则到底是怎样的,特地记录一下:
在Java中,我们通常使用String类的compareTo()函数来比较两个字符串的大小。compareTo()函数返回一个整数值,用于表示两个字符串的大小关系。
String 类 compareTo() 方法按字典顺序将给定字符串与当前字符串进行比较。它是根据字符串中每个字符的 Unicode 值比较字符串的,它返回正数、负数或 0。
比较规则如下:
-
如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的差值。
-
如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符作比较,也是返回差值。
-
由此此类推,直至比较的字符或被比较的字符有一方全比较完,这时就比较字符的长度,返回他们长度的差值。
从源码角度分析compareTo()方法:
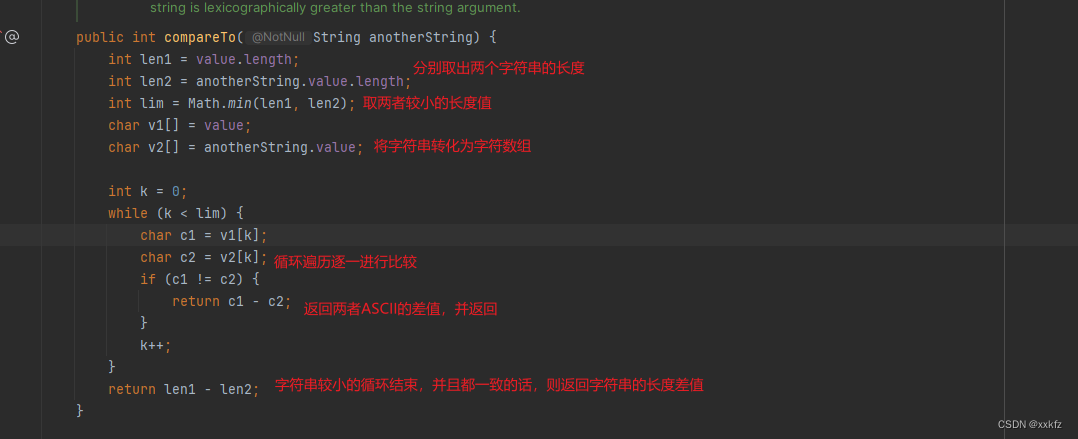
知道了上述的排序规则后,我们进行简单测试下:
int i = "10".compareTo("3");System.out.println("i = " + i);
i = -2
根据返回排序规则,上面返回了-2 ,是字符 1、字符3 的ASCII的值: 65 - 67 = -2 的结果,结果却小于0。 导致10 < 3。这就是上面LinkedHashMap 根据key 转化为String 后使用compareTo 排序的问题所在。
注意:对于字符串长度不能的数字字符串不能使用compareTo进行比较。
对上面的排序方法进行修改如下:
LinkedHashMap<Long, String> resLinkHashMap = linkedHashMap.entrySet().stream().sorted(Comparator.comparingInt(o -> o.getKey().intValue())).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));System.out.println("resLinkHashMap = " + resLinkHashMap);
resLinkHashMap = {4=测试5, 8=测试3, 12=测试1, 26=测试2, 120=测试4}
这篇关于【日常记录】关于LinkedHashMap中key为数字字符串根据compareTo排序的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





