本文主要是介绍可转债代码交流第四期:利用Python获取理杏仁数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
突然发现该系列已经好久没有更新了....
前几期内容都是分享利用python获取(爬取)数据的方法,可能有些“暴力”且耗时,本期内容分享“温柔”且快速获取数据的方法——利用API接口获取。
前三期内容传送门:
第一期:可转债代码交流第一期:利用Python获取宁稳网数据
(包含基本的环境搭建与Python编辑器安装方法)
第二期:可转债代码交流第二期:利用Python获取集思录数据
(包含基本的模拟登录方法)
第三期:可转债代码交流第三期:利用Python获取集思录可转债单独页面数据(包含页面跳转方法)
本人并非计算机专业出身,所有python知识均为自学,所写代码如有不规范的地方,还望指正。
废话不多说,直接上代码!
第一步:导入库(导入各个模块,为了让代码成功运行)
ps:所有的库安装好之后先导入下试试,测试下是否安装成功
import requests
import datetime
import pandas as pd
from pandas.io.json import json_normalize
today = datetime.datetime.today().date()第二步:获取公司财务数据
1.准备工作,设置好相应参数,方便后面获取数据
#设置自己的Token,下文有说明怎么查看自己的Token
token = "19*****8-06**-***9-94**-*******7f383"#设置获取的数据的时间跨度,时间跨度不要超过10年!!!
start_date = '2014-03-31'#起始日期
end_date = '2023-03-31'#结束日期,理杏仁上的财务数据以报告为准,如果一季度报还未发布,那么无法获取到一季度的数据,只能将时间改为上一季度末#设置需要获取的股票代码,统一存入列表,方便提取,不要一次性放入太多股票代码
lst_stock = ['002439','300369','300454'
]#上面几项都为准备工作,下面才开始真正设置数据参数
#可根据自己需求,增减下面列表中的参数
#需要获取相应的财务数据,都可在理杏仁上查看,下文会做详细补充
#注意这里使用t。获取累计数据
lst_metrics = ['q.cfs.ncffoa.t', # 经营活动产生的现金流量净额'q.cfs.ncffia.t', # 投资活动产生的现金流量净额'q.cfs.ncfffa.t', # 筹资活动产生的现金流量净额"q.m.fcf.t",#自由现金流量"q.cfs.cpfpfiaolta.t",#十年资本开支总和"q.ps.npadnrpatoshaopc.t", #净利润'q.m.m_ds.t', #净营业周期'q.ps.oi.t', # 营业收入'q.bs.ta.t_y2y',#总资产同比变化'q.ps.toi.t_y2y',#营业总收入同比变化'q.ps.oc.t',#营业成本'q.bs.nraar.t', #应收票据及应收账款'q.bs.afc.t', #预收账款'q.m.crfscapls_oi_r.t', #销售收现率'q.m.wroe.t',#归属于母公司普通股股东的加权ROE'q.ps.gp_m.t',#毛利率GM'q.m.np_s_r.t',#销售净利率'q.m.ta_to.t',#资产周转率'q.m.l.t',#杠杆倍数'q.bs.lwi_ta_r.t',#有息负债率'q.m.tl_ta_r.t',#资产负债率'q.m.c_r.t',#流动比率'q.m.q_r.t',#速动比率'q.ps.npatoshopc.t',#归属于母公司普通股股东的净利润'q.bs.tetoshopc.t',#归属于母公司普通股股东权益合计'q.bs.tetoshopc_ps.t',#归属于母公司普通股股东的每股股东权益'q.ps.npatshaoehopc.t',#归属于母公司股东及其他权益持有者的净利润'q.bs.tsc.t',#总股本'q.bs.mc.t',#市值'q.ps.tp.t',#利润总额'q.bs.fa.t',#固定资产'q.bs.cip.t',#在建工程'q.bs.es.t',#工程物资'q.bs.ia.t',#无形资产'q.bs.fa.t',#固定资产'q.ps.se_r.t',#销售费用率'q.ps.ae_r.t',#管理费用率'q.ps.rade_r.t',#研发费用率'q.ps.fe_r.t',#财务费用率'q.bs.d_pe_ttm.t',#PE-TTM(扣非) 'q.bs.dyr.t',#股息率'q.bs.npaap.t'#应付票据及应付账款
]# 设置字典列名对应中文解释
# 这里设置的都是上面lst_metrics列表中的数据
# 该步骤是为了后面显示的时候将所有上面财务数据代号改为中文显示,方便阅读
col_map = {'name':'公司名称','stockCode':'股票代码','standardDate':'日期','year':'年份','q.ps.oc.t':'营业成本','q.cfs.ncffoa.t': '经营活动产生的现金流量净额','q.cfs.ncffia.t': '投资活动产生的现金流量净额','q.cfs.ncfffa.t': '筹资活动产生的现金流量净额','q.m.fcf.t': '自由现金流','q.cfs.cpfpfiaolta.t': '资本开支','q.ps.npadnrpatoshaopc.t': '净利润','xx_basic':'小熊基本值','xx_increase': '小熊增长值','q.m.m_ds.t': '净营业周期','q.m.crfscapls_oi_r.t': '销售收现率','q.bs.nraar.t':'应收票据及应收账款','q.bs.afc.t': '预收账款','q.ps.oi.t': '营业收入','rec_ratio' : '白条率','adp_ratio' : '预收率','q.m.wroe.t':'归母加权ROE','q.ps.gp_m.t':'毛利率','q.m.np_s_r.t':'销售净利率','q.m.ta_to.t':'资产周转率','q.m.l.t':'杠杆倍数','q.bs.lwi_ta_r.t':'有息负债率','q.m.tl_ta_r.t':'资产负债率','q.m.c_r.t':'流动比率','q.m.q_r.t':'速动比率','q.ps.npatoshopc.t':'归母净利润','q.bs.tetoshopc.t':'净资产','q.bs.tetoshopc_ps.t':'归母权益','q.ps.se_r.t':'销售费用率','q.ps.ae_r.t':'管理费用率','q.ps.rade_r.t':'研发费用率','q.ps.fe_r.t':'财务费用率','q.bs.ta.t_y2y':'总资产同比变化','q.ps.toi.t_y2y':'营业总收入同比变化','q.bs.npaap.t':'应付账款','q.ps.npatshaoehopc.t':'归属于母公司股东及其他权益持有者的净利润','q.bs.tsc.t':'总股本','q.bs.mc.t':'市值','q.bs.fa.t':'固定资产','q.ps.fe_r.t':'财务费用','q.bs.d_pe_ttm.t':'PE-TTM(扣非)' ,'q.bs.dyr.t':'股息率','symbol':'现金流肖像'}# 设置字体为黑体,不然制图的时候显示中文会乱码
font_name = 'SimHei'ps:
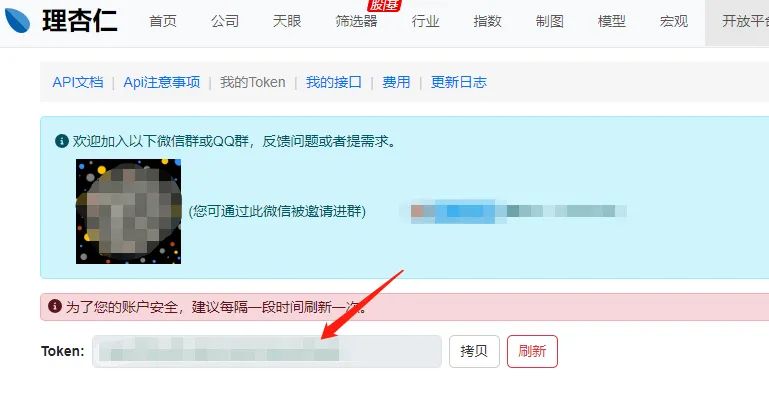
1.1如何查看自己的Token
打开https://www.lixinger.com/open/api/token,登录即可查看,如下图:
1.2怎么获取想要的数据
登录理杏仁,点击开放平台,选择“大陆”-“公司接口”-“财务报表”-“非金融”,如下图:
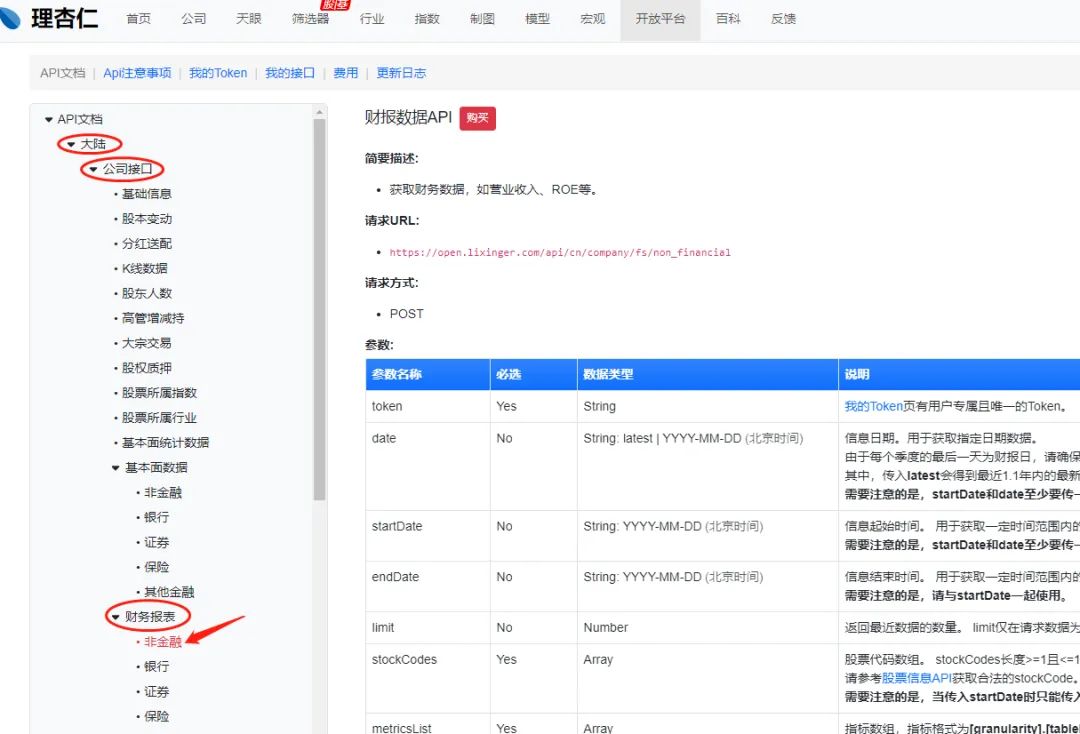
然后查看右侧,有对应的财务数据获取格式,需要哪个就点开对应选项
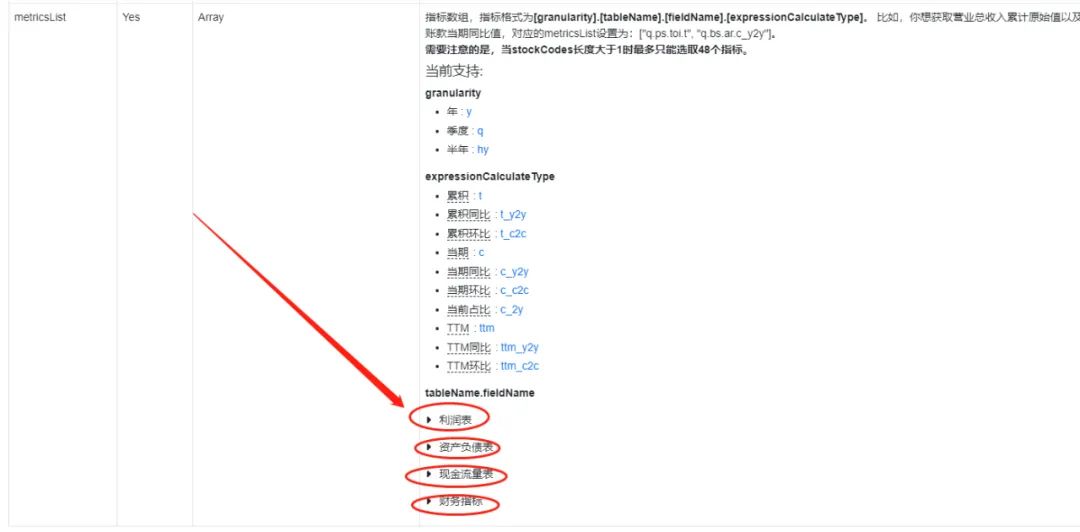
点开以后就是下面的情况,找到自己需要的数据即可

填入的格式:“q.需要的数据格式.t”。例如:q.m.fcf.t,获取的是以季度累计起来的自由现金流量,如果想要获取其它格式,可参考下图:

2.获取财务数据
数据获取的格式如下图:理杏仁上可先进行测试,看看是否有报错
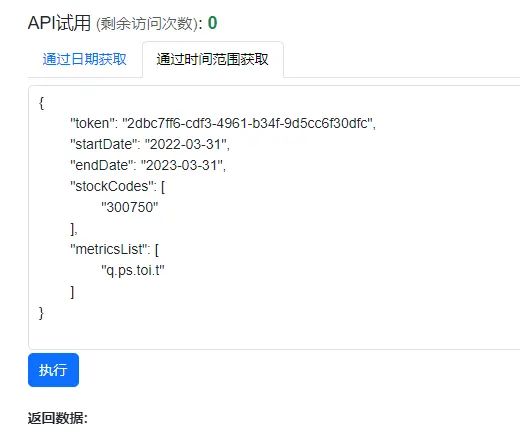
#获取指定财务数据
#本身获取单个数据就不需要用循环,因为获取了多家公司的财务数据,用循环直接合并数据更省心
#这里的参数上面都已经设置好了,只要填入相应位置即可
for i, stock in enumerate(lst_stock):# 将所有的参数传入datasdatas = {"token": token,# 上面已经设置好"startDate": start_date,# 上面已经设置好"endDate": end_date,# 上面已经设置好"stockCodes": [stock],# 上面已经设置好"metricsList": lst_metrics# 上面已经设置好}#设置好参数,开始获取数据,注意获取的网址!!!r = requests.post('https://open.lixinger.com/api/cn/company/fs/non_financial',json = datas)# 将数据直接转成DataFrame格式df_temp = json_normalize(r.json()['data'])# 合并获取的DataFrame, 第一次获取数据直接存入df_data,后面获取的数据合并到df_data中if i == 0:df_data = df_tempelse:df_data = pd.concat([df_data, df_temp])ps:
2.1上面的第15行代码一定要注意自己的网址,如果获取的是公司的财务数据就不需要改,如果获取的是其它数据,就需要改成相应的网址。

第三步:获取公司信息
#获取公司基本信息
#方法和上面获取财务数据类似,但是需要设置的参数比较少
datas = {"token": token,"industryType": "non_financial"
}#注意网址,第二步中有讲过
r = requests.post('https://open.lixinger.com/api/a/company',json = datas)df_company = json_normalize(r.json()['data'])第四步:数据整理
#把日期转换成日期数据类型
df_data['standardDate'] = df_data['standardDate'].map(lambda x: x[:10])
df_data['standardDate'] = pd.to_datetime(df_data['standardDate'])#生成年列
df_data['year'] = df_data['standardDate'].map(lambda x: x.year)#只需要年报数据
df_data = df_data[df_data['reportType'] == 'annual_report'].reset_index(drop=True)
# last_year 是最近一年
last_year = df_data['year'].iloc[0]# first_year是有数据的第一年, 条件判断是看是否有缺少值。
df_test = df_data.loc[:, ['stockCode','year','q.m.fcf.t', #自由现金流量'q.ps.npadnrpatoshaopc.t', #归母净利润'q.m.m_ds.t' #净营业周期]]
#去除df_test中有NAN的行
df_test = df_test.dropna(axis=0, how='any')#查询出 有数据的最早年份
i = 0
list_y = []
while 1:if i == df_test.shape[0]-1:breakelif df_test.iat[i,0] != df_test.iat[i+1,0]:list_y.append(i)i += 1list_y.append(df_test.shape[0]-1)#list_y记录最早年份的位置
list_firsttyear = []#list_firsttyear取出所有公司的最早年份for each in list_y:list_firsttyear.append(df_test.iat[each,1])
first_year = max(list_firsttyear)# 查找df_data中上市时间最短股票的上市年
df_data = df_data[df_data['year']>= first_year].reset_index(drop=True)第五步:合并表格,形成资产情况表格进行测试
# 合并表格,添加股票名称 name
df_data = pd.merge(df_data,df_company, on = 'stockCode', how = 'left')#判断公司属于重资产还是轻资产=(利润总额/(固定资产+在建工程+工程物资+无形资产))
df_temp = df_data.loc[:, ['stockCode','name','year','q.ps.tp.t',#利润总额'q.bs.fa.t',#固定资产'q.bs.cip.t',#在建工程'q.bs.es.t',#工程物资'q.bs.ia.t'#无形资产]]
df_temp['Asset_value'] = df_data['q.ps.tp.t']/(df_data['q.bs.fa.t']+df_data['q.bs.cip.t']+df_data['q.bs.es.t']+df_data['q.bs.ia.t'])def assets_judge(x):Asset_type = '重资产'if x['Asset_value']>0.1:Asset_type = '轻资产'return Asset_typedf_temp['Asset_type'] = df_temp.apply(assets_judge,axis=1)
df_temp1 = df_temp.pivot(index = 'name', columns = 'year', values = 'Asset_type')
df_temp1.index.name = '公司名称'
df_temp1.columns.name = '年份'
df_temp1#不是用jupyter notebook运行代码的话,将此语句改为“print(df_temp1)”第六步:选取需要的列
#选取需要的列df_data = df_data.loc[:, ['stockCode','name','standardDate','year','q.cfs.ncffoa.t','q.cfs.ncffia.t','q.cfs.ncfffa.t','q.m.fcf.t', #自由现金流量'q.cfs.cpfpfiaolta.t', #资本开支'q.ps.npadnrpatoshaopc.t', #归母净利润'q.ps.oi.t','q.bs.ta.t_y2y',#总资产同比变化'q.ps.toi.t_y2y',#营业总收入同比变化'q.ps.oc.t',#营业成本'q.m.m_ds.t','q.m.crfscapls_oi_r.t',#销售收现率'q.m.wroe.t','q.ps.gp_m.t','q.m.np_s_r.t','q.m.ta_to.t','q.m.l.t','q.bs.lwi_ta_r.t',#有息负债率'q.m.tl_ta_r.t',#资产负债率'q.m.c_r.t',#流动比率'q.m.q_r.t',#速动比率'q.ps.npatoshopc.t',#归属于母公司普通股股东的净利润'q.bs.tetoshopc.t',#归属于母公司普通股股东权益合计'q.bs.tetoshopc_ps.t',#归属于母公司普通股股东的每股股东权益'q.ps.npatshaoehopc.t',#归属于母公司股东及其他权益持有者的净利润'q.bs.tsc.t',#总股本'q.bs.mc.t',#市值'q.bs.fa.t',#固定资产'q.ps.se_r.t',#销售费用'q.ps.ae_r.t',#管理费用'q.ps.rade_r.t',#研发费用'q.ps.fe_r.t',#财务费用'q.bs.d_pe_ttm.t',#PE-TTM(扣非) 'q.bs.dyr.t',#股息率'q.bs.npaap.t'#应付票据及应付账款]]第七步:现金流肖像判断
#初步判断所选股票的自由现金流情况
# 现金流肖像
def judgee(x):symbol = '其他'if x['q.cfs.ncffoa.t']<0:symbol = '危险' elif(x['q.cfs.ncffoa.t']>0) & (x['q.cfs.ncffia.t']<0) & (x['q.cfs.ncfffa.t']<0):symbol = '奶牛型'elif(x['q.cfs.ncffoa.t']>0) & (x['q.cfs.ncffia.t']>0) & (x['q.cfs.ncfffa.t']<0):symbol = '母鸡型'elif(x['q.cfs.ncffoa.t']>0) & (x['q.cfs.ncffia.t']<0) & (x['q.cfs.ncfffa.t']>0):symbol = '蛮牛型'return symboldf_data['symbol'] = df_data.apply(judgee,axis=1)
df_temp = df_data.pivot(index = 'name', columns = 'year', values = 'symbol')
df_temp.index.name = '公司名称'
df_temp.columns.name = '年份'
df_temp#连续两年以上‘危险’(即经营活动没赚到钱),就要避开
#不是用jupyter notebook运行代码的话,将此语句改为“print(df_temp)”第八步:更改列名
#将列名称更改为中文显示,需要注意的是,列名一旦改变,在调用的时候不能再向上面一样调用,需要用中文列名调用
df_data.columns =df_data.columns.map(lambda x: col_map[x])
df_data
#不是用jupyter notebook运行代码的话,将此语句改为“print(df_data)”完整代码如下:
import requests
import datetime
import pandas as pd
from pandas.io.json import json_normalize
today = datetime.datetime.today().date()#设置自己的Token,下文有说明怎么查看自己的Token
token = "19*****8-06**-***9-94**-*******7f383"#设置获取的数据的时间跨度,时间跨度不要超过10年!!!
start_date = '2014-03-31'#起始日期
end_date = '2023-03-31'#结束日期,理杏仁上的财务数据以报告为准,如果一季度报还未发布,那么无法获取到一季度的数据,只能将时间改为上一季度末#设置需要获取的股票代码,统一存入列表,方便提取,不要一次性放入太多股票代码
lst_stock = ['002439','300369','300454'
]#上面几项都为准备工作,下面才开始真正设置数据参数
#可根据自己需求,增减下面列表中的参数
#需要获取相应的财务数据,都可在理杏仁上查看,下文会做详细补充
#注意这里使用t。获取累计数据
lst_metrics = ['q.cfs.ncffoa.t', # 经营活动产生的现金流量净额'q.cfs.ncffia.t', # 投资活动产生的现金流量净额'q.cfs.ncfffa.t', # 筹资活动产生的现金流量净额"q.m.fcf.t",#自由现金流量"q.cfs.cpfpfiaolta.t",#十年资本开支总和"q.ps.npadnrpatoshaopc.t", #净利润'q.m.m_ds.t', #净营业周期'q.ps.oi.t', # 营业收入'q.bs.ta.t_y2y',#总资产同比变化'q.ps.toi.t_y2y',#营业总收入同比变化'q.ps.oc.t',#营业成本'q.bs.nraar.t', #应收票据及应收账款'q.bs.afc.t', #预收账款'q.m.crfscapls_oi_r.t', #销售收现率'q.m.wroe.t',#归属于母公司普通股股东的加权ROE'q.ps.gp_m.t',#毛利率GM'q.m.np_s_r.t',#销售净利率'q.m.ta_to.t',#资产周转率'q.m.l.t',#杠杆倍数'q.bs.lwi_ta_r.t',#有息负债率'q.m.tl_ta_r.t',#资产负债率'q.m.c_r.t',#流动比率'q.m.q_r.t',#速动比率'q.ps.npatoshopc.t',#归属于母公司普通股股东的净利润'q.bs.tetoshopc.t',#归属于母公司普通股股东权益合计'q.bs.tetoshopc_ps.t',#归属于母公司普通股股东的每股股东权益'q.ps.npatshaoehopc.t',#归属于母公司股东及其他权益持有者的净利润'q.bs.tsc.t',#总股本'q.bs.mc.t',#市值'q.ps.tp.t',#利润总额'q.bs.fa.t',#固定资产'q.bs.cip.t',#在建工程'q.bs.es.t',#工程物资'q.bs.ia.t',#无形资产'q.bs.fa.t',#固定资产'q.ps.se_r.t',#销售费用率'q.ps.ae_r.t',#管理费用率'q.ps.rade_r.t',#研发费用率'q.ps.fe_r.t',#财务费用率'q.bs.d_pe_ttm.t',#PE-TTM(扣非) 'q.bs.dyr.t',#股息率'q.bs.npaap.t'#应付票据及应付账款]# 设置字典列名对应中文解释
# 这里设置的都是上面lst_metrics列表中的数据
# 该步骤是为了后面显示的时候将所有上面财务数据代号改为中文显示,方便阅读
col_map = {'name':'公司名称','stockCode':'股票代码','standardDate':'日期','year':'年份','q.ps.oc.t':'营业成本','q.cfs.ncffoa.t': '经营活动产生的现金流量净额','q.cfs.ncffia.t': '投资活动产生的现金流量净额','q.cfs.ncfffa.t': '筹资活动产生的现金流量净额','q.m.fcf.t': '自由现金流','q.cfs.cpfpfiaolta.t': '资本开支','q.ps.npadnrpatoshaopc.t': '净利润','xx_basic':'小熊基本值','xx_increase': '小熊增长值','q.m.m_ds.t': '净营业周期','q.m.crfscapls_oi_r.t': '销售收现率','q.bs.nraar.t':'应收票据及应收账款','q.bs.afc.t': '预收账款','q.ps.oi.t': '营业收入','rec_ratio' : '白条率','adp_ratio' : '预收率','q.m.wroe.t':'归母加权ROE','q.ps.gp_m.t':'毛利率','q.m.np_s_r.t':'销售净利率','q.m.ta_to.t':'资产周转率','q.m.l.t':'杠杆倍数','q.bs.lwi_ta_r.t':'有息负债率','q.m.tl_ta_r.t':'资产负债率','q.m.c_r.t':'流动比率','q.m.q_r.t':'速动比率','q.ps.npatoshopc.t':'归母净利润','q.bs.tetoshopc.t':'净资产','q.bs.tetoshopc_ps.t':'归母权益','q.ps.se_r.t':'销售费用率','q.ps.ae_r.t':'管理费用率','q.ps.rade_r.t':'研发费用率','q.ps.fe_r.t':'财务费用率','q.bs.ta.t_y2y':'总资产同比变化','q.ps.toi.t_y2y':'营业总收入同比变化','q.bs.npaap.t':'应付账款','q.ps.npatshaoehopc.t':'归属于母公司股东及其他权益持有者的净利润','q.bs.tsc.t':'总股本','q.bs.mc.t':'市值','q.bs.fa.t':'固定资产','q.ps.fe_r.t':'财务费用','q.bs.d_pe_ttm.t':'PE-TTM(扣非)' ,'q.bs.dyr.t':'股息率','symbol':'现金流肖像'}# 设置字体为黑体,不然制图的时候显示中文会乱码
font_name = 'SimHei'#获取指定财务数据
#本身获取单个数据就不需要用循环,因为获取了多家公司的财务数据,用循环直接合并数据更省心
#这里的参数上面都已经设置好了,只要填入相应位置即可
for i, stock in enumerate(lst_stock):# 将所有的参数传入datasdatas = {"token": token,# 上面已经设置好"startDate": start_date,# 上面已经设置好"endDate": end_date,# 上面已经设置好"stockCodes": [stock],# 上面已经设置好"metricsList": lst_metrics# 上面已经设置好}#设置好参数,开始获取数据,注意获取的网址!!!r = requests.post('https://open.lixinger.com/api/cn/company/fs/non_financial',json = datas)# 将数据直接转成DataFrame格式df_temp = json_normalize(r.json()['data'])# 合并获取的DataFrame, 第一次获取数据直接存入df_data,后面获取的数据合并到df_data中if i == 0:df_data = df_tempelse:df_data = pd.concat([df_data, df_temp])#获取公司基本信息
#方法和上面获取财务数据类似,但是需要设置的参数比较少
datas = {"token": token,"industryType": "non_financial"
}#注意网址,第二步中有讲过
r = requests.post('https://open.lixinger.com/api/a/company',json = datas)df_company = json_normalize(r.json()['data'])#把日期转换成日期数据类型
df_data['standardDate'] = df_data['standardDate'].map(lambda x: x[:10])
df_data['standardDate'] = pd.to_datetime(df_data['standardDate'])#生成年列
df_data['year'] = df_data['standardDate'].map(lambda x: x.year)#只需要年报数据
df_data = df_data[df_data['reportType'] == 'annual_report'].reset_index(drop=True)
# last_year 是最近一年
last_year = df_data['year'].iloc[0]# first_year是有数据的第一年, 条件判断是看是否有缺少值。
df_test = df_data.loc[:, ['stockCode','year','q.m.fcf.t', #自由现金流量'q.ps.npadnrpatoshaopc.t', #归母净利润'q.m.m_ds.t' #净营业周期]]
#去除df_test中有NAN的行
df_test = df_test.dropna(axis=0, how='any')#查询出 有数据的最早年份
i = 0
list_y = []
while 1:if i == df_test.shape[0]-1:breakelif df_test.iat[i,0] != df_test.iat[i+1,0]:list_y.append(i)i += 1list_y.append(df_test.shape[0]-1)#list_y记录最早年份的位置
list_firsttyear = []#list_firsttyear取出所有公司的最早年份for each in list_y:list_firsttyear.append(df_test.iat[each,1])
first_year = max(list_firsttyear)# 查找df_data中上市时间最短股票的上市年
df_data = df_data[df_data['year']>= first_year].reset_index(drop=True)# 添加一列股票名称 name
df_data = pd.merge(df_data,df_company, on = 'stockCode', how = 'left')#判断公司属于重资产还是轻资产=(利润总额/(固定资产+在建工程+工程物资+无形资产))
df_temp = df_data.loc[:, ['stockCode','name','year','q.ps.tp.t',#利润总额'q.bs.fa.t',#固定资产'q.bs.cip.t',#在建工程'q.bs.es.t',#工程物资'q.bs.ia.t'#无形资产]]
df_temp['Asset_value'] = df_data['q.ps.tp.t']/(df_data['q.bs.fa.t']+df_data['q.bs.cip.t']+df_data['q.bs.es.t']+df_data['q.bs.ia.t'])def assets_judge(x):Asset_type = '重资产'if x['Asset_value']>0.1:Asset_type = '轻资产'return Asset_typedf_temp['Asset_type'] = df_temp.apply(assets_judge,axis=1)
df_temp1 = df_temp.pivot(index = 'name', columns = 'year', values = 'Asset_type')
df_temp1.index.name = '公司名称'
df_temp1.columns.name = '年份'
df_temp1
---------------------------------------------------------
#到此需要单独显示!!!下图图1
----------------------------------------------------------#选取需要的列
df_data = df_data.loc[:, ['stockCode','name','standardDate','year','q.cfs.ncffoa.t','q.cfs.ncffia.t','q.cfs.ncfffa.t','q.m.fcf.t', #自由现金流量'q.cfs.cpfpfiaolta.t', #资本开支'q.ps.npadnrpatoshaopc.t', #归母净利润'q.ps.oi.t','q.bs.ta.t_y2y',#总资产同比变化'q.ps.toi.t_y2y',#营业总收入同比变化'q.ps.oc.t',#营业成本'q.m.m_ds.t','q.m.crfscapls_oi_r.t',#销售收现率'q.m.wroe.t','q.ps.gp_m.t','q.m.np_s_r.t','q.m.ta_to.t','q.m.l.t','q.bs.lwi_ta_r.t',#有息负债率'q.m.tl_ta_r.t',#资产负债率'q.m.c_r.t',#流动比率'q.m.q_r.t',#速动比率'q.ps.npatoshopc.t',#归属于母公司普通股股东的净利润'q.bs.tetoshopc.t',#归属于母公司普通股股东权益合计'q.bs.tetoshopc_ps.t',#归属于母公司普通股股东的每股股东权益'q.ps.npatshaoehopc.t',#归属于母公司股东及其他权益持有者的净利润'q.bs.tsc.t',#总股本'q.bs.mc.t',#市值'q.bs.fa.t',#固定资产'q.ps.se_r.t',#销售费用'q.ps.ae_r.t',#管理费用'q.ps.rade_r.t',#研发费用'q.ps.fe_r.t',#财务费用'q.bs.d_pe_ttm.t',#PE-TTM(扣非) 'q.bs.dyr.t',#股息率'q.bs.npaap.t'#应付票据及应付账款]]#初步判断所选股票的自由现金流情况
# 现金流肖像
def judgee(x):symbol = '其他'if x['q.cfs.ncffoa.t']<0:symbol = '危险' elif(x['q.cfs.ncffoa.t']>0) & (x['q.cfs.ncffia.t']<0) & (x['q.cfs.ncfffa.t']<0):symbol = '奶牛型'elif(x['q.cfs.ncffoa.t']>0) & (x['q.cfs.ncffia.t']>0) & (x['q.cfs.ncfffa.t']<0):symbol = '母鸡型'elif(x['q.cfs.ncffoa.t']>0) & (x['q.cfs.ncffia.t']<0) & (x['q.cfs.ncfffa.t']>0):symbol = '蛮牛型'return symboldf_data['symbol'] = df_data.apply(judgee,axis=1)
df_temp = df_data.pivot(index = 'name', columns = 'year', values = 'symbol')
df_temp.index.name = '公司名称'
df_temp.columns.name = '年份'
df_temp#连续两年以上‘危险’(即经营活动没赚到钱),就要避开---------------------------------------------
#到此需要单独显示!!!下图图2
---------------------------------------------#将列名称更改为中文显示,需要注意的是,列名一旦改变,在调用的时候不能再向上面一样调用,需要用中文列名调用
df_data.columns =df_data.columns.map(lambda x: col_map[x])
df_data
#下图图3显示结果例图:
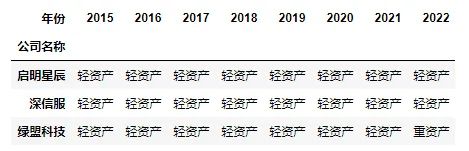
图1
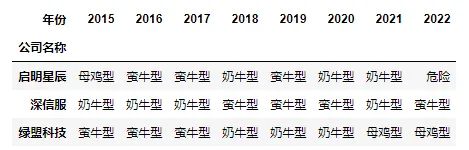
图2
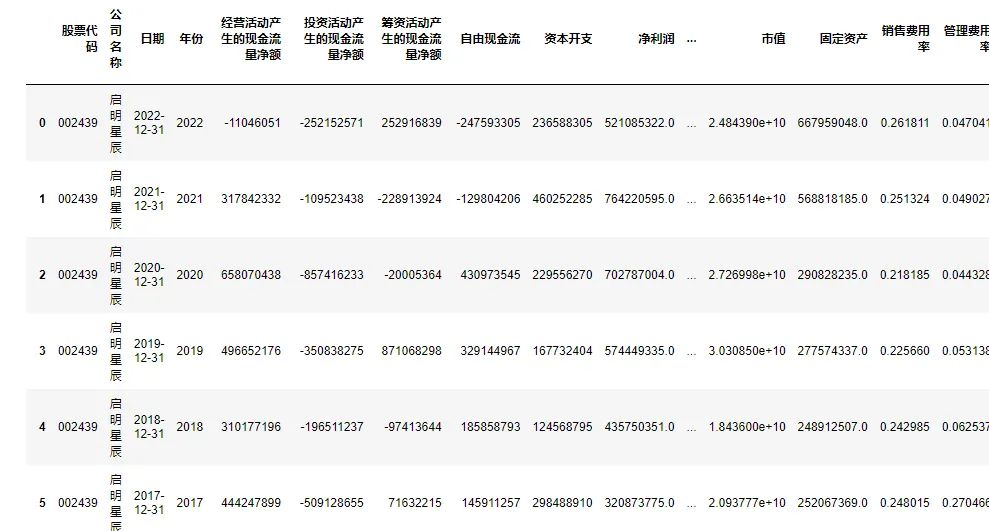
图3
本期内容和上期内容如有侵权行为,请及时联系本人,第一时间删除各平台文章。
您的点赞分享就是我更新的动力
这篇关于可转债代码交流第四期:利用Python获取理杏仁数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






