本文主要是介绍Python | 计算中国5°×5°方格 年总降水,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.写在前面
继续学习站点数据处理ing,这是上周第一个任务,一共三个,写三篇(或者四篇)来记录。
任务一:将中国和部分周围区域划分为5°×5°的格子,计算每个格子内的年降水。
难点:依次读取文件夹中数据
解决办法:遍历每天的站点,找到他属于哪个方格,先计算每天每方格内所有站点的平均,再把每天的降水二维数组加起来(365天)
所用数据:2014年365天SURF_CHN_MUL_DAY_2014****格式数据,每个文件是每天所有站点的气象要素记录
1.代码解析
1.1 主函数
path = r"D:2014-2020\2014"
files= os.listdir(path)k=1 #k可以用来控制读取文件数量
yearsum=np.zeros([5,14],dtype=float,order='C') #yearsum用来记录总降水
for filename in files: #依次读取文件夹中的文件df = pd.read_table(os.path.join(path,filename),sep='\t',header=None)day=dave(df) #dave函数用来求每天的平均降水(对站点降水求平均)yearsum=yearsum+dayk=k+1draw(yearsum) #draw函数负责可视化年降水
1.2 dave函数
def dave(df):lat = df[64]del lat[0] #lat[0]是表头,要删掉,自己摸索的时候可以一步一步输出试试lat=lat.astype(float) #改变数据格式lon = df[66]del lon[0]lon=lon.astype(float)pre=df[72]del pre[0]pre=pre.astype(float) #999999是缺测,不算降水,0算daypre=np.zeros([5,14],dtype=float,order='C') #每个小方格站点总降水daysta=np.zeros([5,14],dtype=float,order='C') #站点数,缺测不算for m in range(1,(len(lat)+1)): #遍历一天内所有站点if lat[m]<55 and lat[m]>=30 and lon[m]>=70 and lon[m]<140:a=lat[m]i=4-int(((a-30)//5))b=lon[m]j=int(((b-70)//5))if pre[m]<500: #如果没有缺测daysta[i][j]=daysta[i][j]+1daypre[i][j]=daypre[i][j]+pre[m]dayave=np.zeros([5,14],dtype=float,order='C') #每天平均降水for i in range(0,5):for j in range(0,14):if daysta[i][j]!=0:dayave[i][j]=daypre[i][j]/daysta[i][j]return dayave 1.3 draw函数
def draw(ave): #还是之前的老一套,有疑问可评论fig = plt.figure(1, figsize=[16, 9])proj = ccrs.PlateCarree()ax = plt.subplot(1, 1, 1, projection=proj)extent = [70, 140, 30, 55]ax.set(xlim=(70,140),ylim=(30,55))ds = xr.open_dataset(r"D:\地形图\ETOPO2v2c_f4.nc")lon = np.linspace(min(ds['x'].data), max(ds['x'].data), len(ds['x'].data)) # 经度lat = np.linspace(min(ds['y'].data), max(ds['y'].data), len(ds['y'].data)) # 纬度dem = ds['z'].data# 构建经纬网格lon, lat = np.meshgrid(lon, lat)ax.set(xlim=(70,140),ylim=(30,55))
# 创建底图,设置地图投影为World Plate Carrée,分辨率为高分辨率levels = [-8000, -6000, -4000, -2000, -1000, -200, -50, 0, 50,200, 500, 1000, 1500, 2000, 3000, 4000, 5000, 6000, 7000, 8000]# 创建分级color = ['#084594', '#2171b5', '#4292c6', '#6baed6', '#9ecae1', '#c6dbef', '#deebf7', '#006837','#31a354', '#78c679', '#addd8e', '#d9f0a3', '#f7fcb9', '#c9bc87', '#a69165', '#856b49','#664830', '#ad9591', '#d7ccca'] # 设置色带,19个颜色cf = ax.contourf(lon, lat, dem, levels=levels, colors=color, extend='both',zorder=1)china = shpreader.Reader(r"D:\bou2_4l\bou2_4l.dbf").geometries()plt.title('2014年降水总量', fontsize=20,pad=20)ax.add_geometries(china, ccrs.PlateCarree(),facecolor='none', edgecolor='black', zorder=2) ax.add_geometries(Reader(r"D:\1~5级水系矢量图\river\1级河流.shp").geometries(), ccrs.PlateCarree(), facecolor='none', edgecolor='RoyalBlue', linewidth=0.4) c=np.ones([5,14],dtype=float,order='C')alpha=np.where(ave!=0,c*0.7,0) #这里是把没有降水的地方透明度设为0了,作图就不显示plt.imshow(ave,cmap='rainbow',extent=(70,140,30,55),alpha=alpha,zorder=3)cb=plt.colorbar(shrink=0.5)cb.set_label('单位:mm',fontsize=12)ax.set_xticks(np.arange(extent[0], extent[1]+1, 10), crs=proj)ax.set_yticks(np.arange(extent[-2], extent[-1]+1, 5), crs=proj)ax.xaxis.set_major_formatter(LongitudeFormatter(zero_direction_label=False))ax.yaxis.set_major_formatter(LatitudeFormatter())plt.tick_params(labelsize=12)plt.show()2. 完整代码
from importlib.resources import path
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from cartopy.io.shapereader import Reader
from cartopy.io import shapereader as shpreader
from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
import cartopy.crs as ccrs
import time
import xarray as xrtime_start = time.time()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef dave(df):lat = df[64]del lat[0]lat=lat.astype(float)lon = df[66]del lon[0]lon=lon.astype(float)pre=df[72]del pre[0]pre=pre.astype(float)daypre=np.zeros([5,14],dtype=float,order='C')daysta=np.zeros([5,14],dtype=float,order='C') for m in range(1,(len(lat)+1)): if lat[m]<55 and lat[m]>=30 and lon[m]>=70 and lon[m]<140:a=lat[m]i=4-int(((a-30)//5))b=lon[m]j=int(((b-70)//5))if pre[m]<500:daysta[i][j]=daysta[i][j]+1daypre[i][j]=daypre[i][j]+pre[m]dayave=np.zeros([5,14],dtype=float,order='C') for i in range(0,5):for j in range(0,14):if daysta[i][j]!=0:dayave[i][j]=daypre[i][j]/daysta[i][j]return dayave def draw(ave):fig = plt.figure(1, figsize=[16, 9])proj = ccrs.PlateCarree()ax = plt.subplot(1, 1, 1, projection=proj)extent = [70, 140, 30, 55]ax.set(xlim=(70,140),ylim=(30,55))ds = xr.open_dataset( r"D:\地形图\ETOPO2v2c_f4.nc")lon = np.linspace(min(ds['x'].data), max(ds['x'].data), len(ds['x'].data)) # 经度lat = np.linspace(min(ds['y'].data), max(ds['y'].data), len(ds['y'].data)) # 纬度dem = ds['z'].datalon, lat = np.meshgrid(lon, lat)ax.set(xlim=(70,140),ylim=(30,55))levels = [-8000, -6000, -4000, -2000, -1000, -200, -50, 0, 50,200, 500, 1000, 1500, 2000, 3000, 4000, 5000, 6000, 7000, 8000]color = ['#084594', '#2171b5', '#4292c6', '#6baed6', '#9ecae1', '#c6dbef', '#deebf7', '#006837','#31a354', '#78c679', '#addd8e', '#d9f0a3', '#f7fcb9', '#c9bc87', '#a69165', '#856b49','#664830', '#ad9591', '#d7ccca'] # 设置色带,19个颜色cf = ax.contourf(lon, lat, dem, levels=levels, colors=color, extend='both',zorder=1)china = shpreader.Reader(r"D:\bou2_4l\bou2_4l.dbf").geometries()plt.title('2014年降水总量', fontsize=20,pad=20)ax.add_geometries(china, ccrs.PlateCarree(),facecolor='none', edgecolor='black', zorder=2) ax.add_geometries(Reader(r"D:\1~5级水系矢量图\river\1级河流.shp").geometries(), ccrs.PlateCarree(), facecolor='none', edgecolor='RoyalBlue', linewidth=0.4) c=np.ones([5,14],dtype=float,order='C')alpha=np.where(ave!=0,c*0.7,0)plt.imshow(ave,cmap='rainbow',extent=(70,140,30,55),alpha=alpha,zorder=3)cb=plt.colorbar(shrink=0.5)cb.set_label('单位:mm',fontsize=12)ax.set_xticks(np.arange(extent[0], extent[1]+1, 10), crs=proj)ax.set_yticks(np.arange(extent[-2], extent[-1]+1, 5), crs=proj)ax.xaxis.set_major_formatter(LongitudeFormatter(zero_direction_label=False))ax.yaxis.set_major_formatter(LatitudeFormatter())plt.tick_params(labelsize=12)plt.show()path = r"D:\2014-2020\2014"
files= os.listdir(path)
k=1
yearsum=np.zeros([5,14],dtype=float,order='C')
for filename in files:df = pd.read_table(os.path.join(path,filename),sep='\t',header=None)day=dave(df)yearsum=yearsum+dayk=k+1draw(yearsum)time_end = time.time() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print('运行时间:',time_sum)成图:
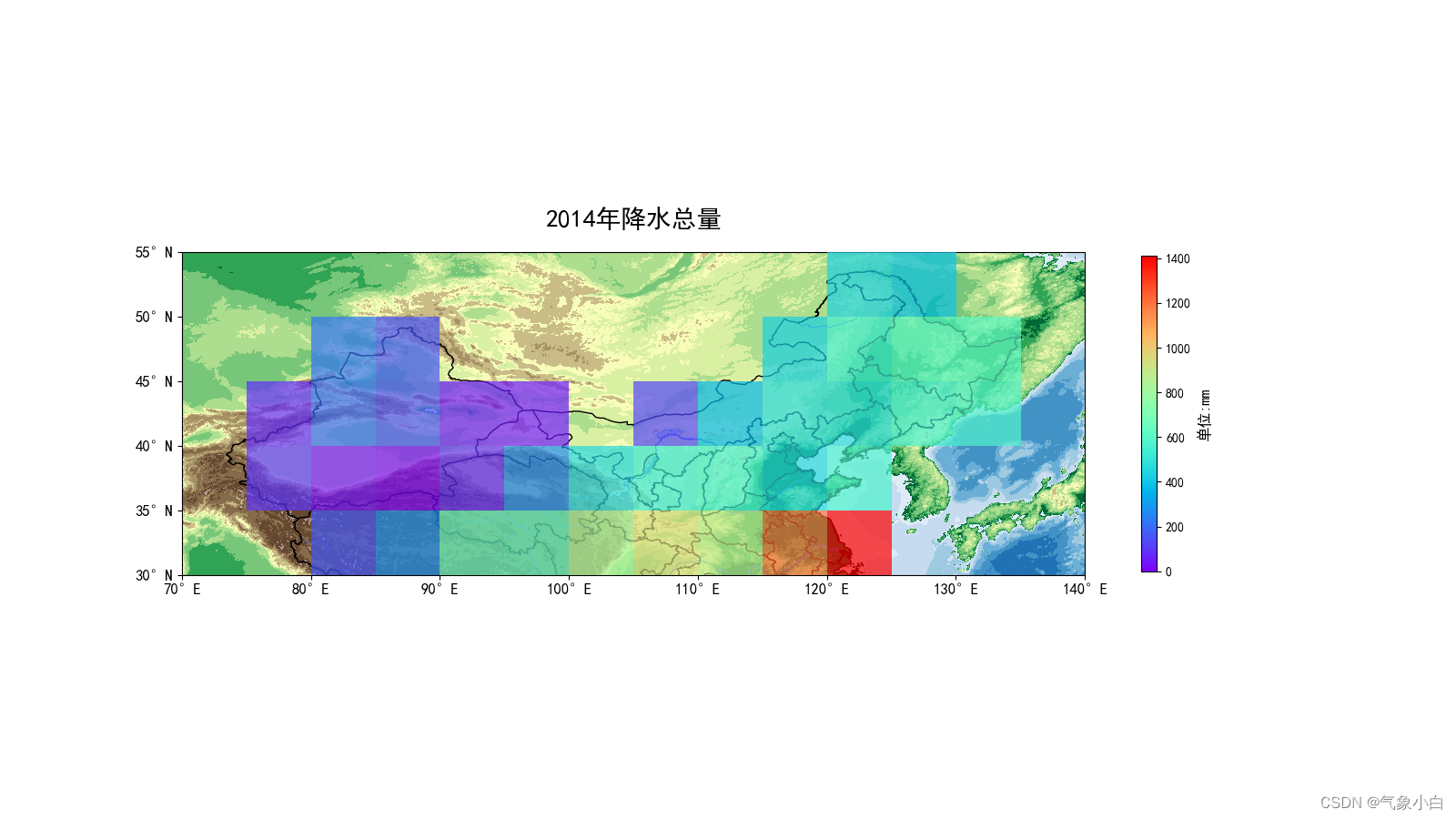
这篇关于Python | 计算中国5°×5°方格 年总降水的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





