本文主要是介绍KaiwuDB 内核解析 - SQL 查询的生命周期,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、概述
KaiwuDB 内核解析系列共分上下两部分,本文是该系列的第一部分,主要涵盖了网络协议到 SQL 执行器,解释 KaiwuDB 如何执行 SQL 查询,包括系统各个组件的执行路径(网络协议、SQL 会话管理、解析器、执行计划及优化、执行器、KV 引擎、事务管理等),目的是为各个组件的结构及其之间的关系提供一个高层次的统一视图。
下图是 KaiwuDB SQL 查询执行概览。左侧是 gateway 节点,负责接收 SQL Client 的 SQL 查询,生成查询计划(逻辑计划和物理计划),构造分布式执行引擎需要的 FlowSpec 并发送到被查询数据所在的节点。每个节点会根据接收到的 FlowSpec 构造物理计划中的算子并执行,然后把数据通过网络返回到 gateway 节点。接下来我们就详细讨论一下各个组件是如何工作的。

二、PostgreSQL Wire Protocol
SQL 查询通过 Postgres Wire 协议发送到 KaiwuDB(使用 Postgres 协议是为了与现有的客户端驱动和应用程序兼容)。这个组件实现了与 Postgres wire 协议相关的功能接口。用户连接后会首先进行鉴权,鉴权通过后,就会初始化一个循环,不断地读取 SQL 语句、执行并返回结果(通过封装 golang 的 net.Conn)。
这个协议是面向消息的(PostgreSQL 消息类型,见执行器部分):在当前连接的生命周期内,会读取一个或多个包含 SQL 语句的消息,并将其传递给 SQL 执行器执行;一旦 SQL 语句执行完毕并生成结果,就会将其序列化并返回给客户端。
PostgreSQL Wire Protocol Server 是在 KaiwuDB 启动的同时初始化的。详细的初始化流程如下图所示。首先,KaiwuDB 的 start 命令会通过 server.Start 方法调用 startServeSQL 来初始化 ServConn。ServConn 负责解析 SQL 客户端的请求、检查连接的安全性并处理连接参数,然后调用 pgServer.ServConn 方法来处理 SQL Statement。

三、SQL 执行器
KaiwuDB 使用一个端口同时处理 pg/http/grpc 三种协议。在 start 阶段,KaiwuDB 实例化 pgServer 来处理 Postgres wire 协议的请求。pgServer 会实例化 KaiwuDB 的 SQL 执行器处理用户查询。
SQL 执行器会作为生产者( Producer),持续读取用户输入并调用 parser 解析 SQL 为 statement,解析的结果会保存到 Statement buffer(StmtBuf)中。同时,还会创建一个 go routine 作为消费者(Consumer),按序处理 StmtBuf 中的 SQL statements。
SQL 执行器的具体处理流程如下图所示。首先,它会通过 serverImpl 调用 processCommandsAsync 创建一个新的 goroutine,来认证客户端连接和处理 Statement buffer(StmtBuf)中的命令(上文提到的消费者)。
其返回值是一个用来标示 goroutine 是否结束的 channel。需要注意的是,这个 channel 中的任何错误信息都会被忽略,因为期间发生的任何错误的详细信息已经通知了 SQL 客户端。processCommandsAsync 还会进行鉴权工作,如果鉴权失败,这个 goroutine 就会结束,并且会调用 cancelConn 关闭整个连接。
接下来,serverImpl 会初始化一个 for loop 来接收 SQL 客户端的输入,直到连接关闭或者发生错误。此处的 for loop 是作为生产者,首先验证 SQL Client 的权限,通过后,会根据客户端发送的消息类型调用不同的方法。
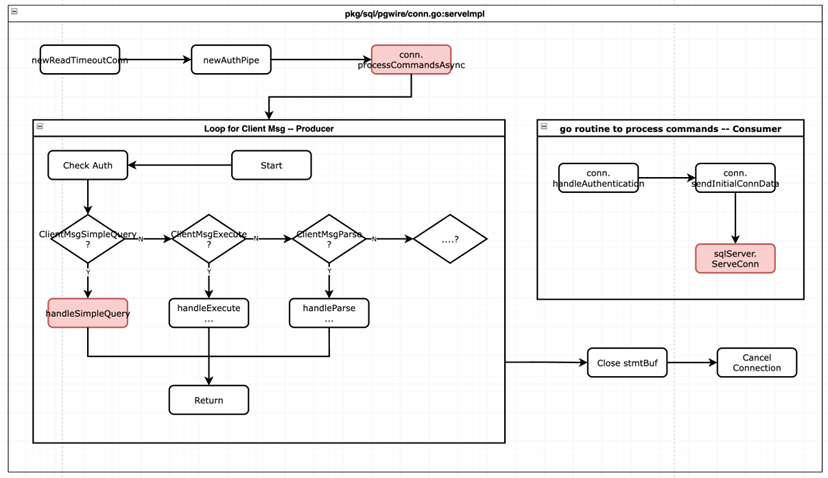
消息类型定义请参考>>https://www.postgresql.org/docs/9.4/protocol-message-formats.html
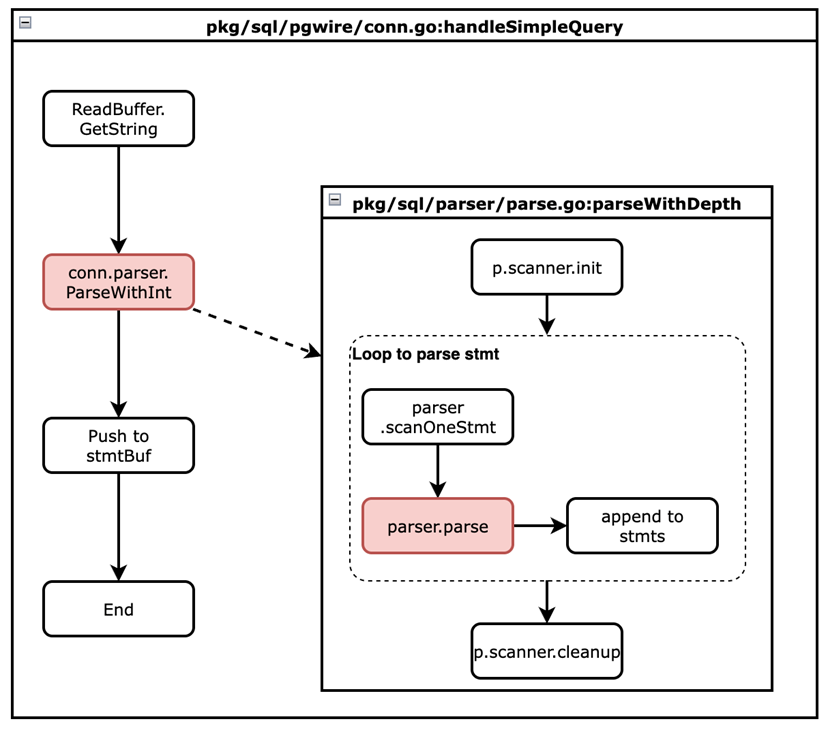
下面的章节会以 handleSimpleQuery 方法为例,来说明 SQL 执行器处理 SQL 的过程。
1. SQL 接收与解析
handleSimpleQuery 的目的是用来处理简单 SQL。首先,它会从 PostgreSQL Wire Protocol 的缓存中读取一个字符串。如果读取成功,这个字符串就会发送给 KaiwuDB 的 SQL parser(SQL 解析器)。
KaiwuDB 的解析器最初复制于 PostgresSQL,随着支持更多的 SQL 语法而逐渐增强。SQL 解析器的输出为 AST(抽象语法树)数组,每个 SQL 语句一个。AST 的节点是由 pkg/sql/sem/tree 中定义的 tree.Statement 结构组成:
Go
type Statement interface {fmt.StringerNodeFormatterStatementType() StatementType// StatementTag is a short string identifying the type of statement// (usually a single verb). This is different than the Stringer output,// which is the actual statement (including args).// TODO(dt): Currently tags are always pg-compatible in the future it// might make sense to pass a tag format specifier.StatementTag() string
}KaiwuDB 实现了使用 tree.Statement 的子类抽象了 SQL 语句的各个子句。比如,tree.SelectClause 结构抽象了 SQL 中的 SELECT 子句,包括 SELECT 的 From 和 Where 子句。同时,AST 树中的许多部分会包含一个或多个 tree.Expr 结构,用来表示诸如 l_extendedprice * (1 - l_discount)这样的算术表达式。
Go
type SelectClause struct {Distinct boolDistinctOn DistinctOnExprs SelectExprsFrom FromWhere *WhereGroupBy GroupByHaving *WhereWindow WindowTableSelect bool
}type BinaryExpr struct {Operator BinaryOperatorLeft, Right ExprtypeAnnotationfn *BinOp
}SQL 解析成功后,会被添加到 Statement bufer 中等待执行器处理。
下面我们以 TPCH 中的 Q7 为例,展示一下 KaiwuDB 中 AST 的结构。
TPCH 的 Q7 是用来查询两个特定国家之间(此处为法国和德国)在某段时间内(1995-01-01 到 1996-12-31)的货物运输总价值。
SQL
SELECTsupp_nation,cust_nation,l_year, sum(volume) AS revenue
FROM (SELECTn1.n_name AS supp_nation,n2.n_name AS cust_nation,extract(year FROM l_shipdate) AS l_year,l_extendedprice * (1 - l_discount) AS volumeFROMsupplier,lineitem,orders,customer,nation n1,nation n2WHEREs_suppkey = l_suppkeyAND o_orderkey = l_orderkeyAND c_custkey = o_custkeyAND s_nationkey = n1.n_nationkeyAND c_nationkey = n2.n_nationkeyAND ((n1.n_name = 'FRANCE' AND n2.n_name = 'GERMANY')or (n1.n_name = 'GERMANY' AND n2.n_name = 'FRANCE'))AND l_shipdate BETWEEN DATE '1995-01-01' AND DATE '1996-12-31') AS shipping
GROUP BYsupp_nation,cust_nation,l_year
ORDER BYsupp_nation,cust_nation,l_year;下图即为 KaiwuDB 中 TPCH Q7 的 AST(为了方便展示做了简化处理)。每个节点中的白色部分代表空值(nil),表示当前节点不包含该结构;紫色部分代表该结构可以展开,即指向下个子节点;绿色部分代表叶节点。
因为 Q7 是 SELECT 语句,其根节点是 tree.Statement 的子类 tree.Select。Q7 中每个 Statement 都被抽象为一个具体的节点,比如 ORDER BY 被表示为 tree.OrderBy,WHERE 子句被表示为 tree.Where 等。

2. SQL 语句执行
上文提到,SQL 执行器的消费者 goroutine 会不断地从 Statement buffer 中读取 SQL 的 AST 并执行,这个功能是通过 sqlServer.ServeConn 调用 connExecutor 的 execCmd 来实现的,其主要流程见下图。

execCmd 方法会不断地读取 stmtBuf 中的内容并执行。每个 SQL 客户端连接初始化的时候,KaiwuDB 都会初始化一个用来执行 SQL 的有限状态机(FSM),它有 5 种状态:
-
stateNoTxn – 用来处理 BEGIN 语句或隐式事务(为其开启一个新的事务)
-
stateOpen – 用来执行普通的 SQL 语句
-
stateAborted – 用来处理 ROLLBACK 语句
-
stateCommitWait – 用来处理 COMMIT 语句
-
stateInternalError – 用来处理各种错误,比如 eventNonRetriableErr, stateInternalError 等
stmtBuf 的 SQL 指令被添加到状态机后,会根据其类型分别处理。普通 SQL 被定义为 ExecStmt 类型,会通过调用 connExecutor 的 execStmt 方法运行,如上图中所示。
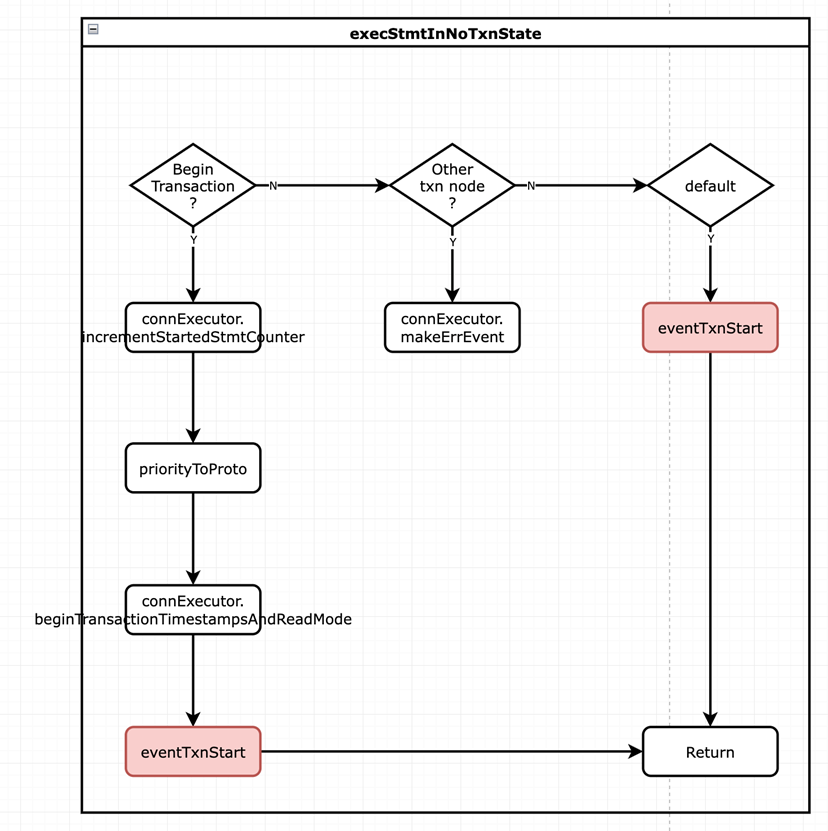
execStmt 方法会首先判断当前状态机的状态,如果是 BEGIN 语句,则会执行 connExecutor 的 execStmtInNoTxnState 方法创建新的事务;如果是普通的 SQL 则会调用 connExecutor 的 execStmtInOpenState 运行。
下图为 execStmtInNoTxnState 创建新事物的过程。如果当前语句是 BEGIN,则会开始一个新的事物。如果是 tree.CommitTransaction, tree.ReleaseSavepoint, tree.RollbackTransaction, tree.SetTransaction 或 tree.Savepoint 中的任何一个,则会报错;其它情况(即普通的 SQL 语句),则会转换状态机的状态到 stateOpen 并创建一个隐式事务。
事务创建成功并且状态机的状态转换为 stateOpen 后,SQL 就会进入执行阶段,这部分内容会在后续文章中详细介绍。
这篇关于KaiwuDB 内核解析 - SQL 查询的生命周期的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





