本文主要是介绍ECAPA-TDNN,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实现流程
ECAPA-TDNN由三部分组成:
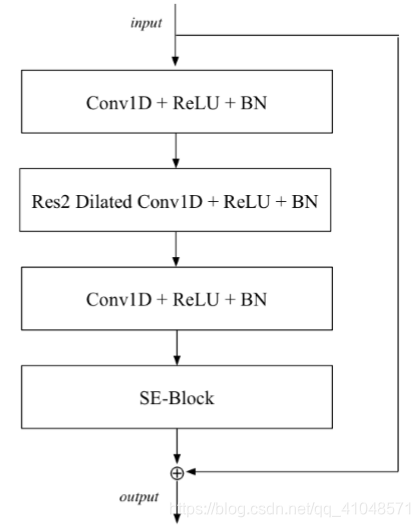
1-Dimensional Squeeze-Excitation Res2Blocks
传统的x-vector的frame-layers只考虑了15帧的信息,而我们想要其考虑全局的信息,因此使用了 Squeeze-Excitation (SE) blocks首先是squeeze操作:
将每一帧 frame-level features按时间取平均,输入特征为[N, C, L], 其中N为batch size,L为特征帧数, C为channel数,则通过求平均值,将特征压缩成[N,C,1]:
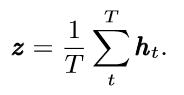
之后是excitation操作:
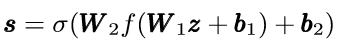
最后再将其与输入点乘相当于每个通道分别乘上一个权值。
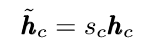
整个Res2Blocks如图
Multi-layer feature aggregation and summation
有两种实现方式:
1. 将每一个Res2Blocks的输出连接起来,再与全连接层连接。
2. 将每一个Res2Blocks的输出求和,而不是连接,从而减小参数量
第一种实现如图所示:

Channel-and context-dependent statistics pooling
通过注意力机制,赋予每一帧不同的权重
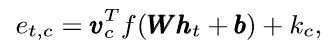
其中ht代表t时刻的帧,得到权重后,将其归一化
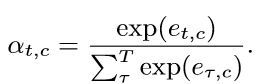
平均值计算为
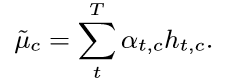
标准差计算为
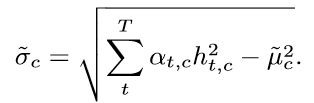
输出将平均值与标准差连接起来即可
实验
使用Voxceleb2数据集,AAM-softmax用来对输出进行分类,分类的个数是说话人的数量(输入之前应先通过一个线形层)。
提取最后的全连接层作为说话人的embedding,使用余弦相似度进行打分。

这篇关于ECAPA-TDNN的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



