本文主要是介绍各省、286个地级市、2850个县PM2.5浓度 空气质量数据(2014-2021),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
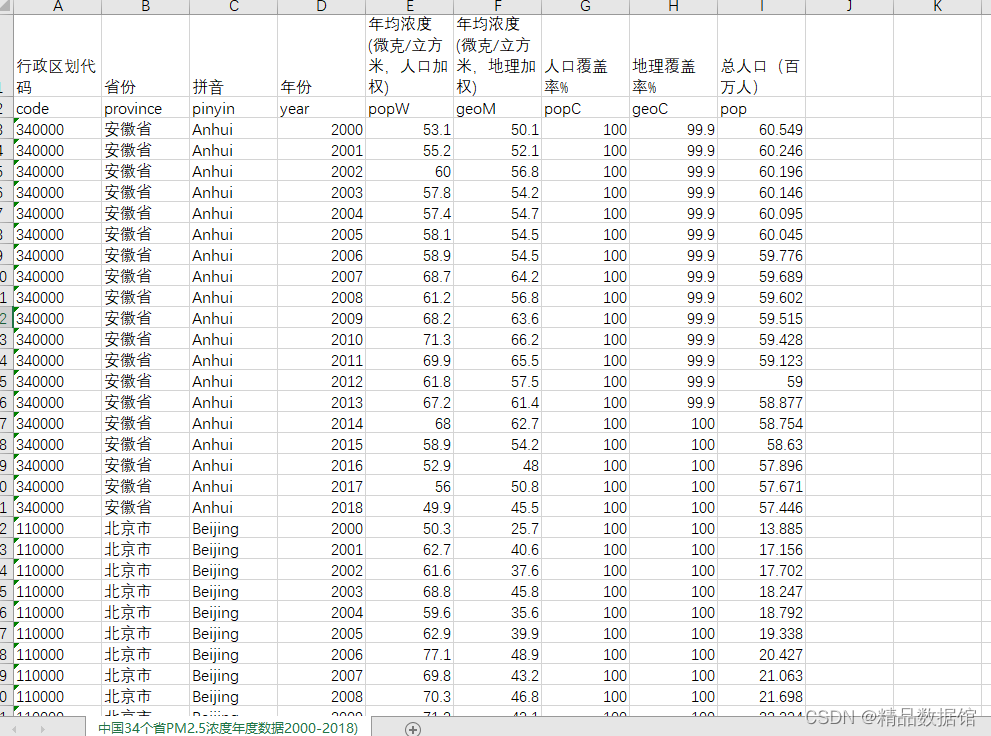
一、中国各省级PM2.5年均浓度
1、数据来源:来自Washington University的Atmospheric Composition Analysis Group对全球地表PM2.5浓度的测算数据。
2、时间跨度:2000-2018
3、区域范围:全国各省
4、指标说明:包括行政区划代码,省份,年份,年均浓度(微克/立方米,人口加权),年均浓度(微克/立方米,地理加权),人口覆盖率%,地理覆盖率%,总人口(百万人)
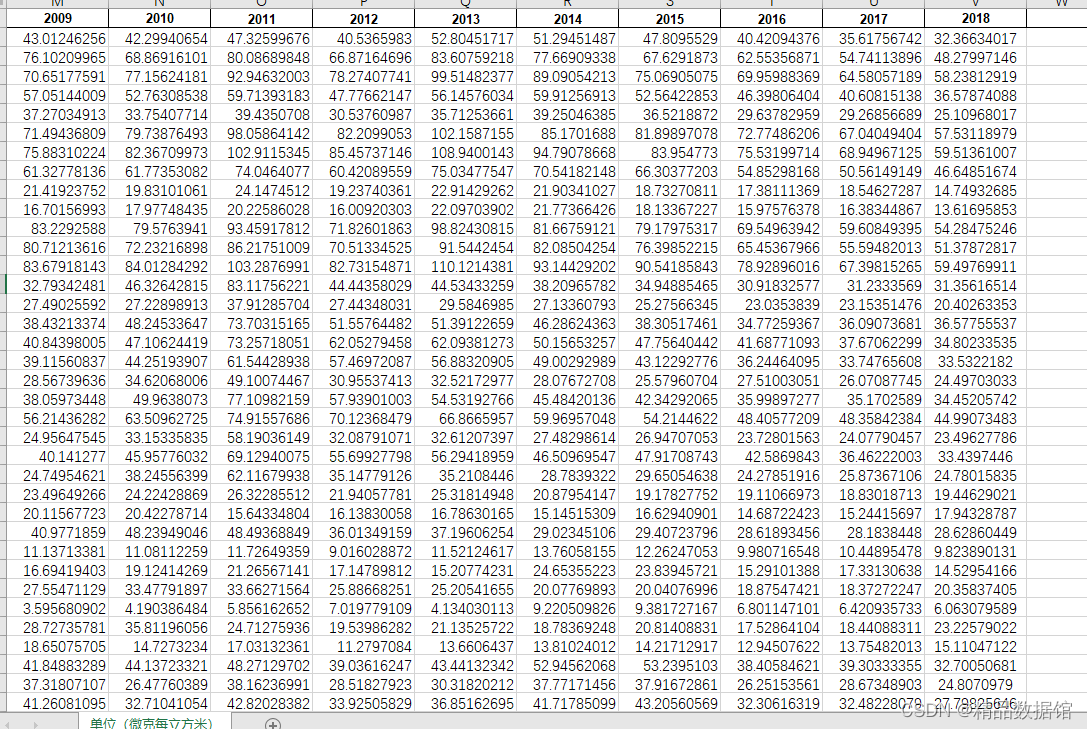
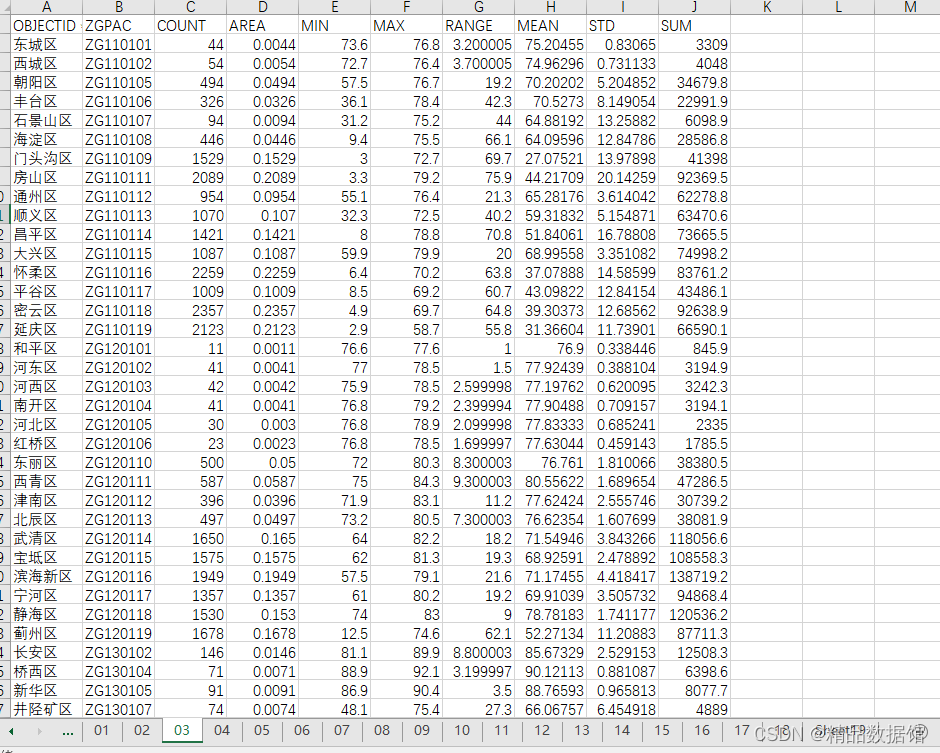
二、286个地级市PM2.5数据
1、数据来源:
达尔豪斯大学大气成分分析组
2、时间跨度:2000-2018年
3、区域范围:全国
4、指标说明:
分享的数据为经栅格处理,匹配286地级市矢量地图后的浓度均值数据。数据精度很高,并保证了统计口径的一致性,适用于长时序分析。
部分数据截图如下:
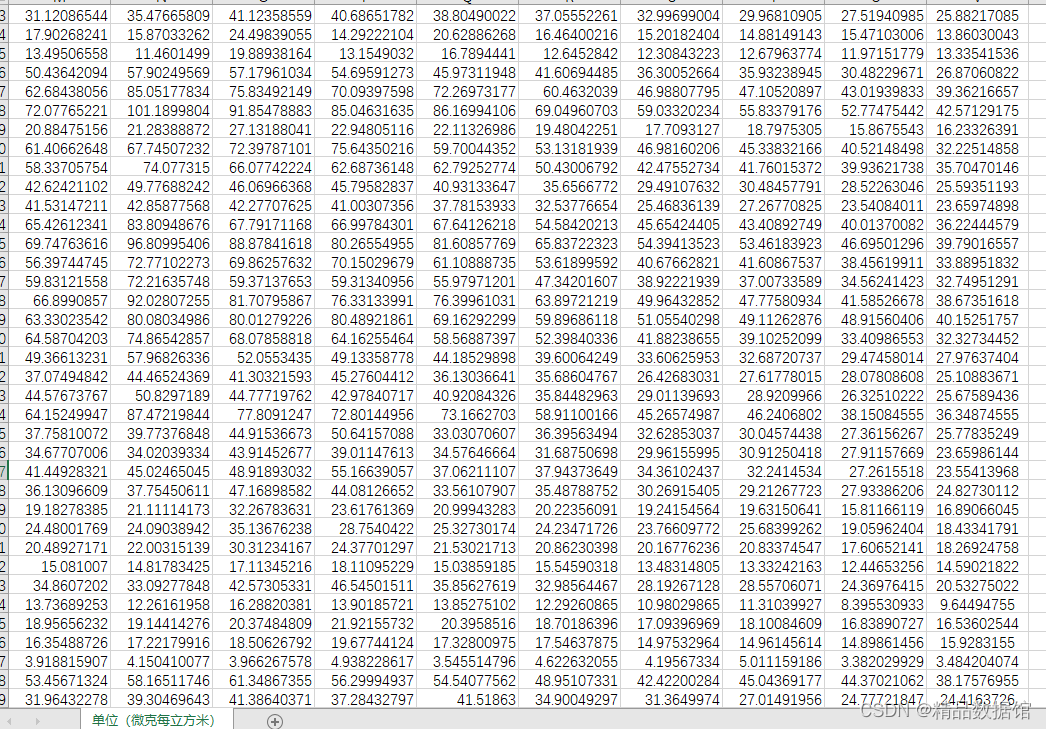
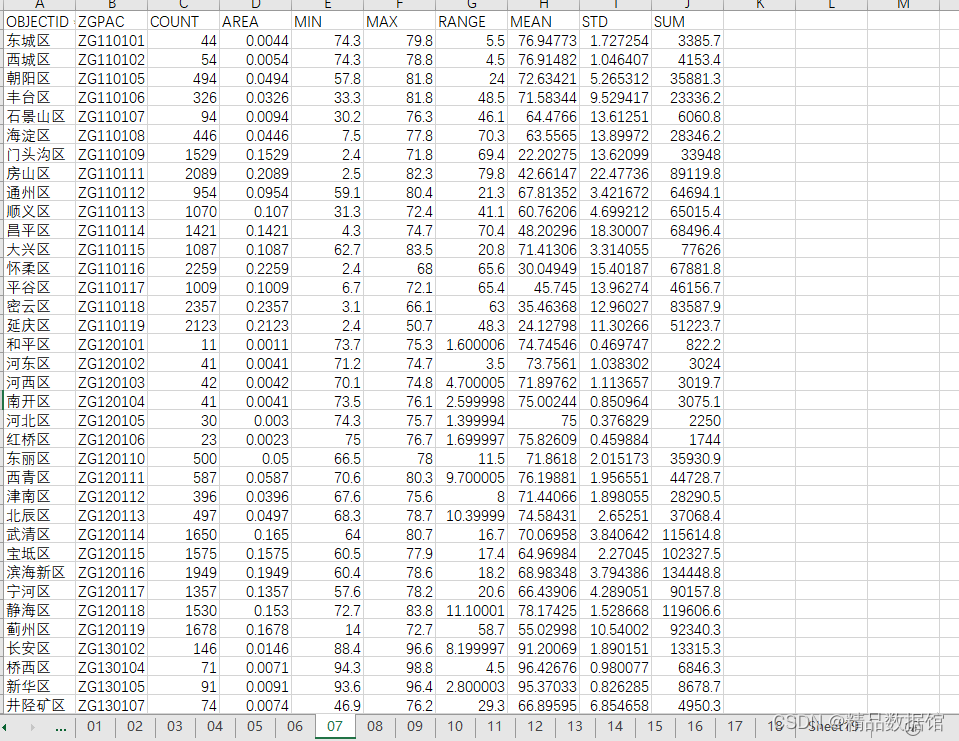
三、中国2850个县PM2.5数据
1、数据来源:
达尔豪斯大学大气成分分析组
2、时间跨度:2000-2018年
3、区域范围:全国2850个县
4、指标说明:
部分数据如下
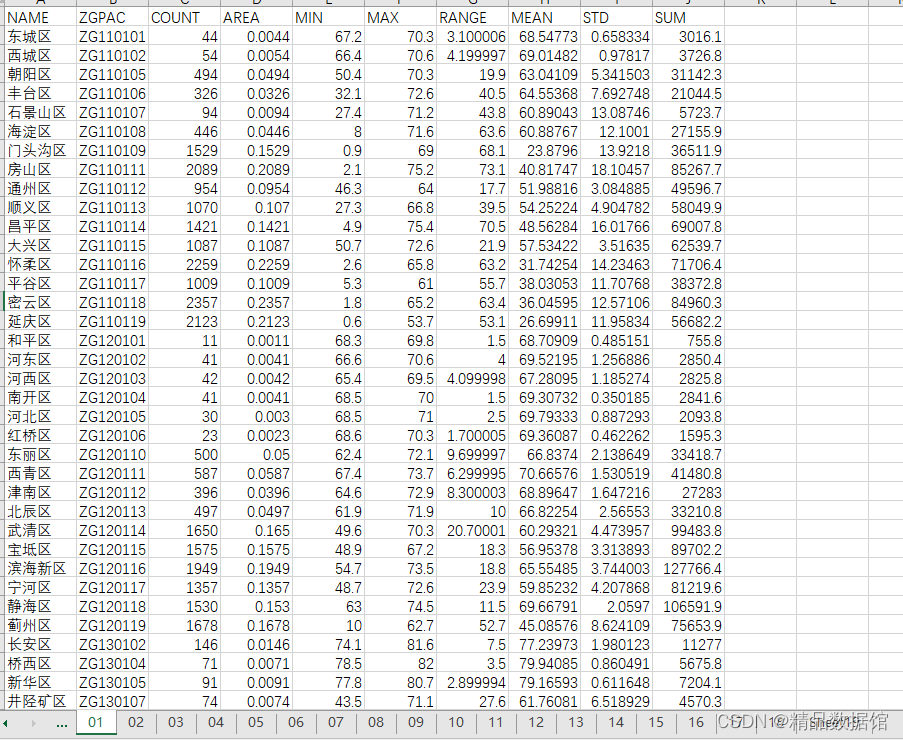
四、中国空气质量历史数据
1、数据来源:
| 中国气象历史数据 |(quotsoft.net)
2、时间跨度:历史数据更新至2021年8月
3、区域范围:全国
4、指标说明:
包括PM2.5、PM10、SO2、NO2、O3、CO六类大气污染物
(1)数据格式说明
全国监测点列表(CSV/XLSX格式,下载见网盘“站点列表-20xx.xx.xx起.csv”)
第一列为监测点编码,第二列为监测点名称,第三列为所属城市,第四、五列为经纬度。
(2)数据格式说明
type 数据类型 单位
AQI AQI实时值 N/A
PM2.5 PM2.5实时浓度 (微克/立方米)
PM2.5_24h PM2.5 24小时滑动均值 (微克/立方米)
PM10 PM10实时浓度 (微克/立方米)
PM10_24h PM10 24小时滑动均值 (微克/立方米)
SO2 SO2实时浓度 (微克/立方米)
SO2_24h SO2 24小时滑动均值 (微克/立方米)
NO2 NO2实时浓度 (微克/立方米)
NO2_24h NO2 24小时滑动均值 (微克/立方米)
O3 O3实时浓度 (微克/立方米)
O3_24h O3 24小时最大值 (微克/立方米)
O3_8h O3 8小时滑动均值 (微克/立方米)
O3_8h_24h O3 8小时滑动均值 的24小时最大值 (微克/立方米)
CO CO实时浓度 (毫克/立方米)
CO_24h CO 24小时滑动均值 (毫克/立方米)
(3)乱码处理
数据所提供的所有CSV都是采用UTF-8编码,有几种情况可能遇到乱码:
如果直接用Excel打开CSV,会看到汉字乱码,数字显示正常。正确的打开方法是:在Excel中点击“数据”-“文本”,选择CSV文件,选中“分隔符号”,编码选择UTF-8,下一步,勾选“逗号”,去掉“Tab键”。这样打开后就能显示汉字了。
如果是用程序处理CSV文件,注意读文件内容时使用UTF-8编码。
如果下载的单日CSV文件乱码乱得一塌糊涂,连数字都看不出来,那可能是下载工具或浏览器的问题。请换个下载工具,或直接到网盘下载打包数据。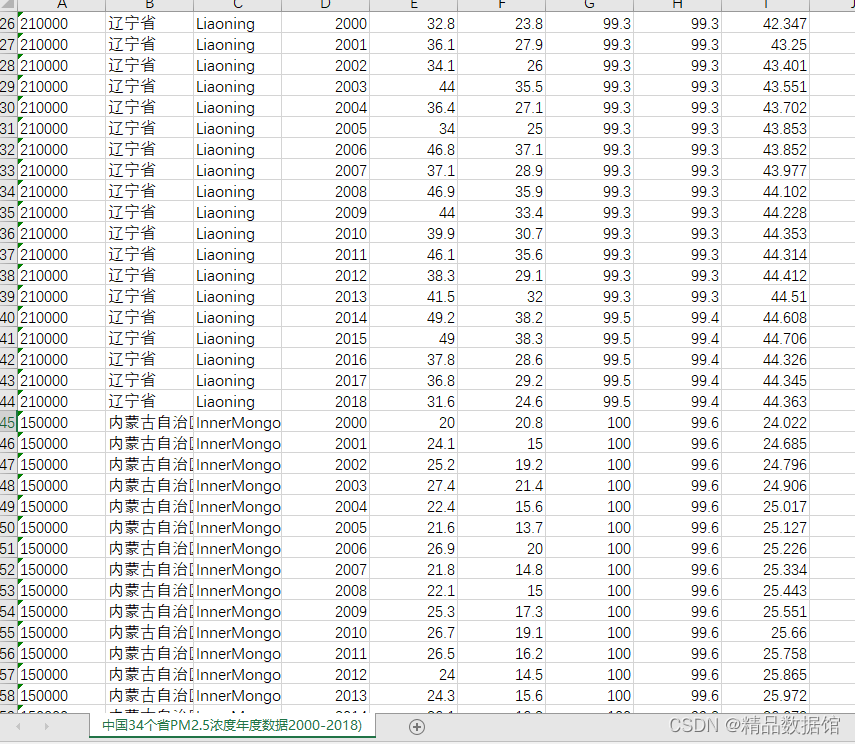


这篇关于各省、286个地级市、2850个县PM2.5浓度 空气质量数据(2014-2021)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








