本文主要是介绍BEVfusion环境配置笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文文章:BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
论文代码:bevfusion
下载项目
原文推荐用nvidia docker,其实可以不用,直接:
cd home && git clone https://github.com/mit-han-lab/bevfusion && cd bevfusion
python setup.py develop
环境搭建
这个环境可能与新的mmdetection3d冲突,最好创建一个新的虚拟环境。
新环境不知道要下载什么,可以用sublime打开Dockerfile,对着来下载就可以了

注意:只用管pip和conda就可以了。但是OpenMPI是不能用pip和conda下载的,需要参考这篇文章下载
数据预处理
项目的数据预处理不能直接用mmdet3d处理好的,要用它自己tools/create_data.py重新处理一次。之前直接用mmdetection3d(版本v1.0.0rc4)处理好的数据来训练,直接报错

但是按照它的预处理代码来的话,还是会报错:
File "bevfusion/tools/data_converter/create_gt_database.py", line 275, in create_groundtruth_databaseimage_idx = example["sample_idx"]
KeyError: 'sample_idx'
这里参考了github上别人的帖子,在mmdet3d/datasets/nuscenes_dataset.py里面get_data_info函数的实现里头添加sample_idx=info['token']即可。见下图红框:
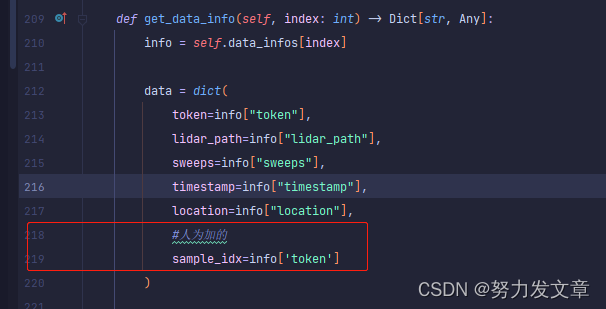
假如还有camera_intrinsics关键字错误的话,请参考github的帖子。
最后把数据集文件夹data/放在bevfusion/下面,可以创建软链接。
关于训练
这么下来之后,训练单模态应该是没问题的。参考了另外一篇文章(感谢这位老哥),它里面有多模态训练命令,但用的是自己写的单gpu训练文件。参考他的命令,得到了自己的多模态模型训练命令:
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml --run-dir bev_result/
在运行的过程中会报错:
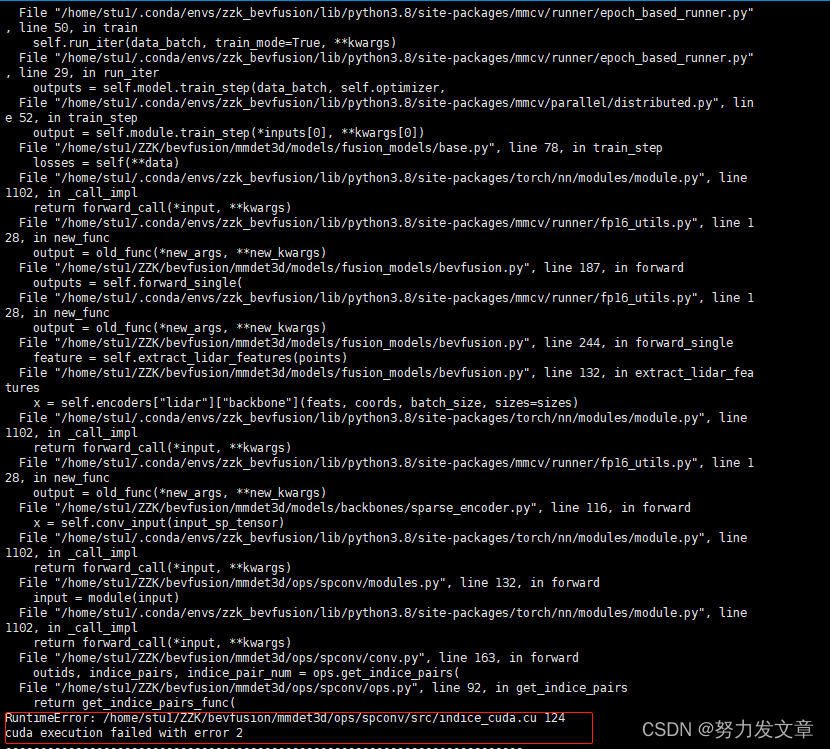
参考这个帖子里面作者说他们用的是spconv-1.2.0,如果下的是spconv 2.x版本的话会不行。建议在没有spconv 2.x的环境下重新编译:
python setup.py develop
但这个方法对于我来说不行。后来我在里面看到有位老哥的方法,试了下成功了:
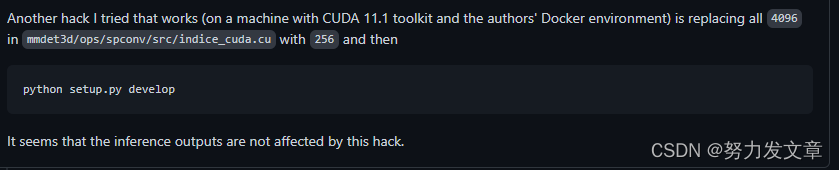
具体做法是:把mmdet3d/ops/spconv/src/indice_cuda.cu文件里面所有的4096改为256。
我的CUDA是11.3,没有用docker。更改之后进行编译,最后代码跑通。
这篇关于BEVfusion环境配置笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






