本文主要是介绍jboss规则引擎KIE Drools 6.3.0-高级讲授篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在生产环境怎么用BRMS
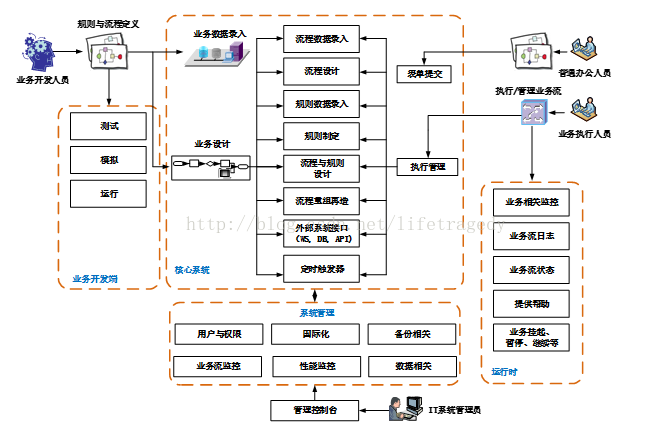
回溯BRMS开发教程中的那张“业务变现加速器”架构图,考虑下面的问题
- 业务开发人员开发规则
- IT人员提供FACT
- 关键在于“全动态”
- SQL语句改了怎么办?不重启
- DAO层改了怎么办?不重启
- Mybatis的配置文件改了怎么办?不重启
按照上次的《jboss规则引擎KIE Drools 6.3.0 Final 教程》,一起来看一个实际的场景
如何熊掌与鱼兼得?

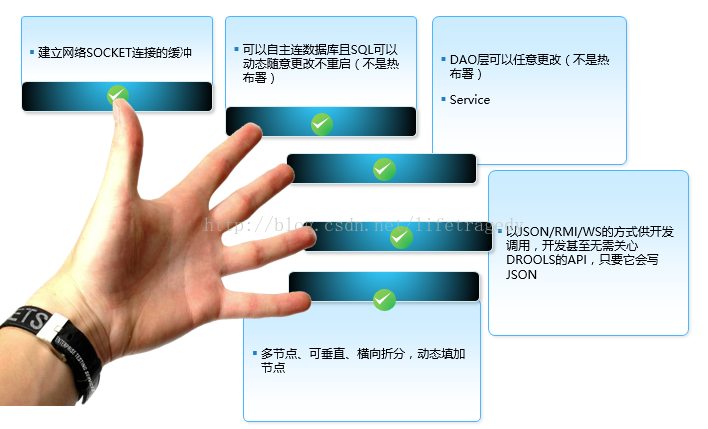
做到以下几点是否就可以“全得”?
- 规则更改不重启,即改即用
- SQL可随意更改,即改即用
- Service可以随意更改,即改即用
- 开发人员不需要关心底层API,他只需要懂JSON(加快开发)
Drool上生产需要具备的条件
Drools能做到上述这些吗?
延续上一个教程内的课后作业:
- 制作一FACTS
- 使其可以带有访问数据库的功能如:访问某张表里的数据
- 访问数据库表并通过相关的get/set方法传送数据给规则并用于判断
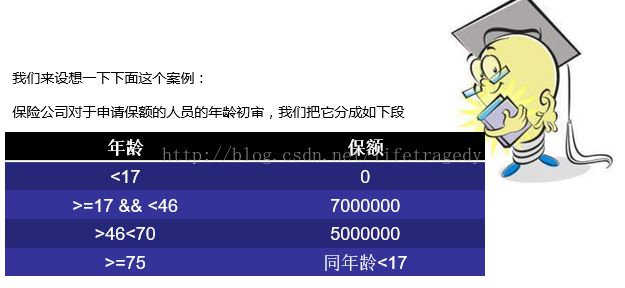
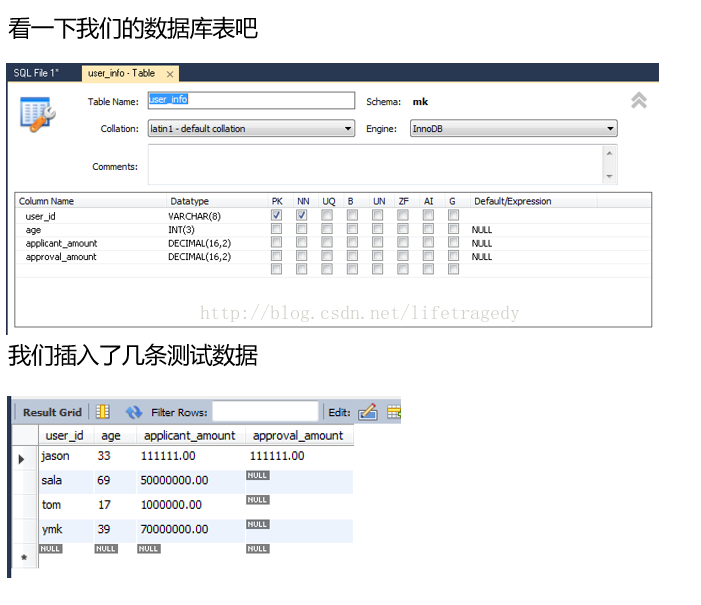
保额申请案例制作要求
- 某个前台录入系统会传入一个user_id
- 通过数据库表user_info中的user_id可以选取该user_id的年龄
- 运用规则来运算保额申请条件并得出申请人可以申请保额的具体数目
先考虑如何让规则读取数据库
对于我们来说,我们把工作按照“业务规则”和“因子”相分离的原则来进行设计。
先设计“因子”,我们一开始想把mybatis功能加入Kie Drools可以动态上传的因子中,这样我们的因子只要业务在发生变化时,每次重新上传一个新的因子,我们的规则就可以使用新的因子了,因此我们的SQL、DAO、SERVICE似乎都可以做到动态了。
但是,我们又想到了使用Spring + MyBatis来结合,这样不是更好吗?那么我们先不来说Drools是否可以启用Spring + MyBatis的功能,要让Drools使用外部jar,Drools是有这个功能的。
Drools是基于Maven Repository来实现发布或者是和外部jar进行交互的。
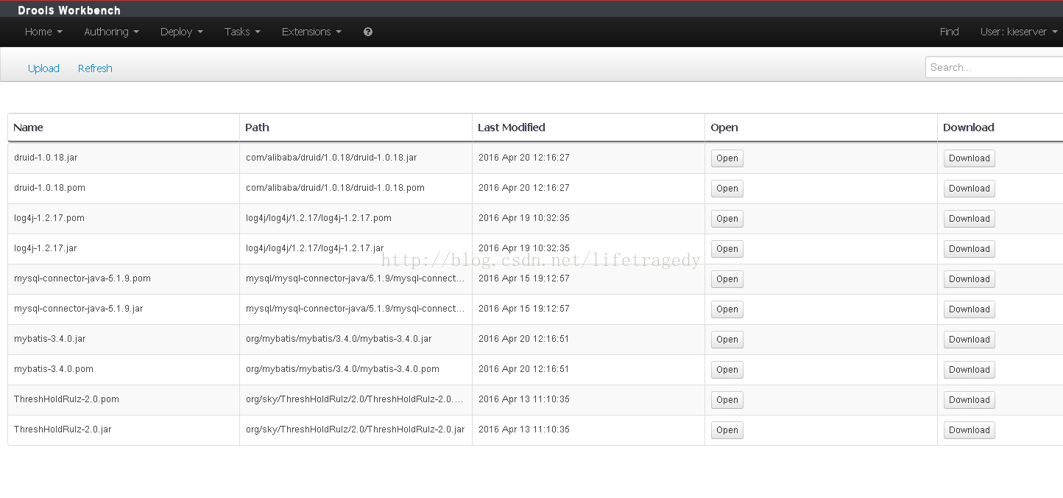
先考虑如何让规则读取数据库-使用外部文件
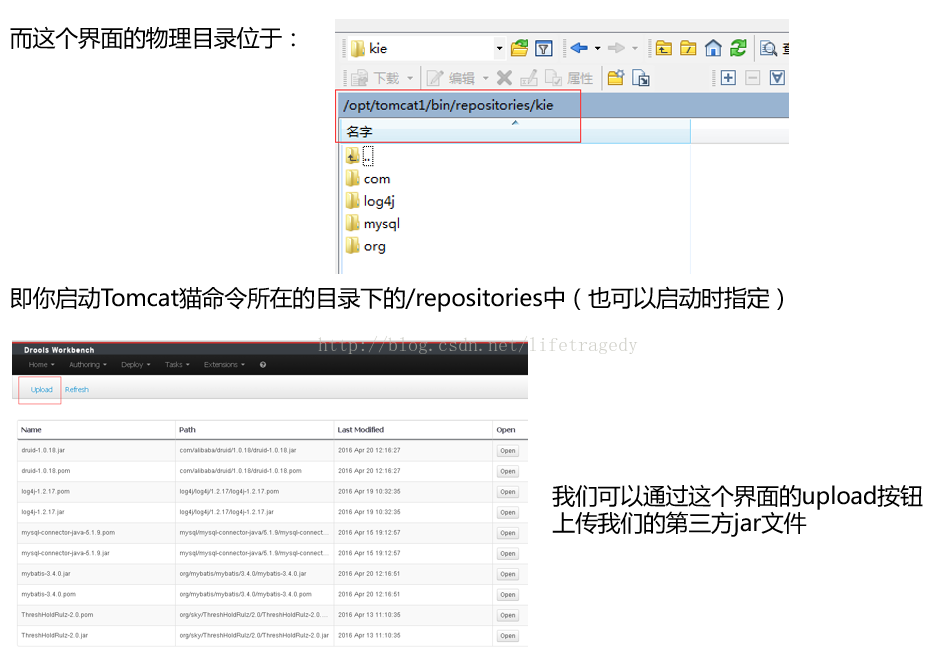
上传完后就可以用了吗?
NO,错!
因为上传完后,你上传的第三方jar只是跑到了以下这个目录里去了
和eclipse一样,要想在工程中使用它们,你还需要在你的工程中引用它们

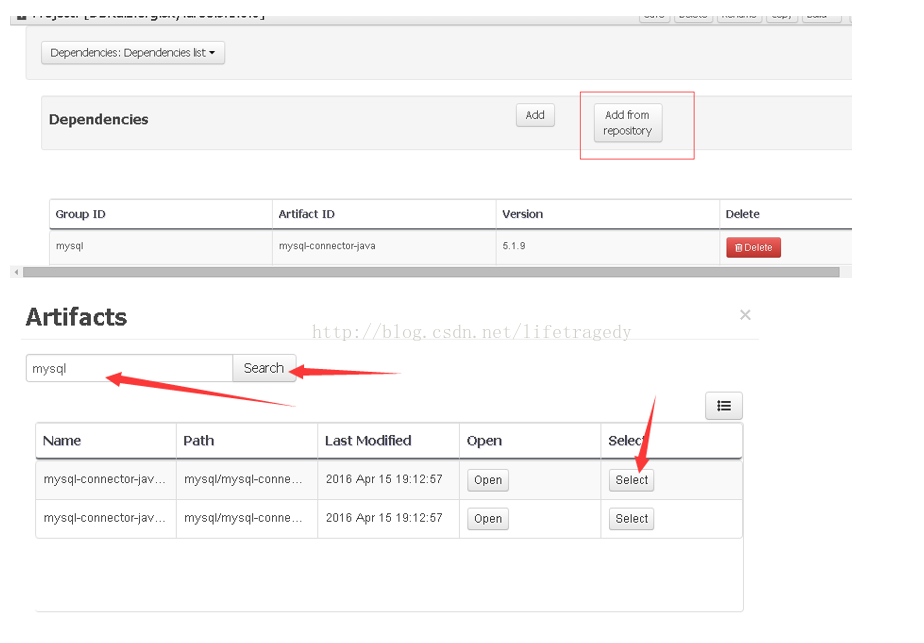
开发数据库功能
我们有了这些个jar文件,我们就可以让我们的规则中的因子具有读取数据库的能力了是不是?
那我们来开发一个使用mybatis功能来读取数据库的例子吧。
当然,这很简单,不少人会说了,因此很快我们把spring + mybatis结合了一下然后我们在代码里使用
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(
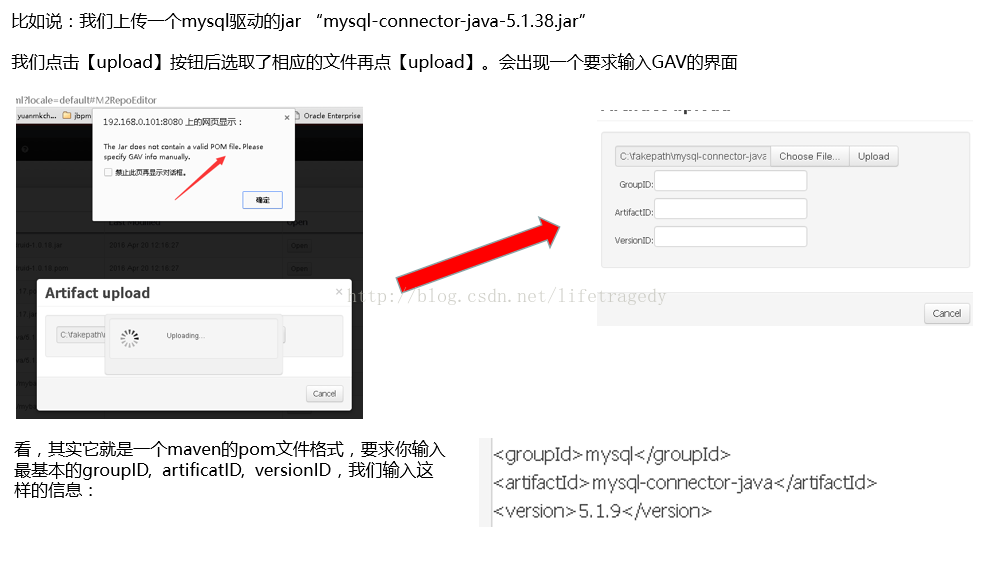
"classpath:/spring/xxx-conf.xml");这样的代码就可以驱动起我们的mybatis了,因此理所当然的我们再需要把spring相关的依赖包上传入drools,于是我们打开了drools中的上传界面,开始上传。。。。。。
可是,你会发觉,你几乎无法上传任何关于spring的jar包。
因为,drools里自带的一些jar和spring所依赖的相关的jar产生了冲突,因此到目前为止你不能在drools WB(workbench)项目中使用spring,而只能拿spring来简化你在前一篇教程中调用KieSession时进行集成(由如jdbcTemplate功能)。
这使得我们的设计进入了一个僵局。。。。。。
打破僵局!
那我们换一种思路来考虑:
在规则中我们主要的还是使用select,不可能在规则中对DB进行INSERT、UPDATE、DELETE操作,这直接违反了“迪米特法则”-即封装原理。
而如果使用mybatis对我们写sql来说比较有宜,但是如果不结合spring仅使用mybatis我们需要注意的一个是session pool的使用和线程安全的问题,另一个就是要在finally块中及时close mybatis的session。
因此。。。我们需要做的就是让开发人员:
- 不用关心从mybatis获取一个session是否是本地线程安全的
- 开发人员只需要调用mapper.selectXXX这样的语句,而不需要关心何时开启和关闭session(万一忘关了那是致命的)
有了迷你AOP,我们只需要在我们的Service中加入一个Session,如:

注意:
脱离了Spring后直接取myBatis的session是“非线程安全的”,因此我们在取session时来作一个小小的处理:
session = SqlSessionManager.newInstance(sqlSessionFactory);这个SqlSessionManager是mybatis自带的并且产生的是“线程安全的session”。

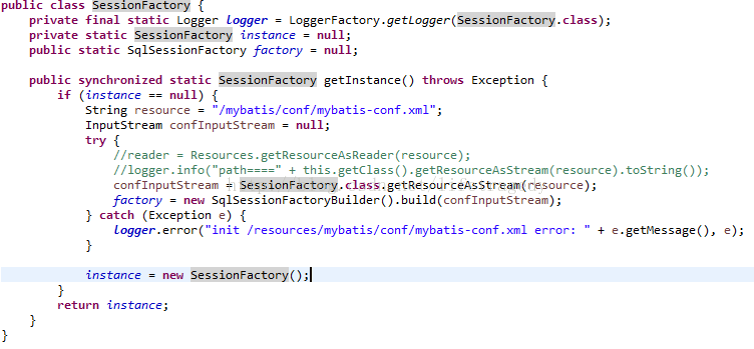
SessionFactory代码
package org.sky.drools.sql.datasource;import java.io.InputStream;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class SessionFactory {private final static Logger logger = LoggerFactory.getLogger(SessionFactory.class);private static SessionFactory instance = null;public static SqlSessionFactory factory = null;public synchronized static SessionFactory getInstance() throws Exception {if (instance == null) {String resource = "/mybatis/conf/mybatis-conf.xml";InputStream confInputStream = null;try {//reader = Resources.getResourceAsReader(resource);//logger.info("path====" + this.getClass().getResourceAsStream(resource).toString());confInputStream = SessionFactory.class.getResourceAsStream(resource);factory = new SqlSessionFactoryBuilder().build(confInputStream);} catch (Exception e) {logger.error("init /resources/mybatis/conf/mybatis-conf.xml error: " + e.getMessage(), e);}instance = new SessionFactory();}return instance;}
}
有了SessionFactory后我们的Session取得就很方便了,而且不用每个Request进来都会重新访问一下mybatis-conf.xml文件重新获得一下。
回过头来再一起来看我们的“迷你AOP”
package org.sky.drools.dao.proxy;import java.lang.reflect.Field;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionManager;
import org.sky.drools.sql.datasource.IsSession;
import org.sky.drools.sql.datasource.SessionFactory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class DAOProxyFactory implements InvocationHandler {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
private Object targetObject;public Object createProxyInstance(Object targetObject) {this.targetObject = targetObject;
return Proxy.newProxyInstance(this.targetObject.getClass().getClassLoader(),
this.targetObject.getClass().getInterfaces(), this);
}public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
这个类是一个implements了InvocationHandler的实现类,关键在于:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
。。。。。。
}方法内的实现
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {SqlSessionFactory sqlSessionFactory = null;Object result = null;SqlSession session = null;try {Field[] fields = targetObject.getClass().getDeclaredFields();if (fields.length > 1) {throw new Exception("[mybatis]--->Expected only 1 myBatis SqlSession in [" + targetObject.getClass() + "] but found more than 1");}for (int i = 0; i < fields.length; i++) {if (fields[i].isAnnotationPresent(IsSession.class)) {Field field = fields[i];String fieldName = field.getName();StringBuffer methodName = new StringBuffer();methodName.append("set");methodName.append(fieldName.substring(0, 1).toUpperCase() + fieldName.substring(1));logger.debug("[mybatis]--->init mybatis session start......");logger.debug("[mybatis]--->the methodName [" + methodName.toString()+"] will be set mybatis session");Method m = targetObject.getClass().getMethod(methodName.toString(), SqlSession.class);sqlSessionFactory = SessionFactory.getInstance().factory;logger.debug("[mybatis]--->get db connection from connection pool");session = SqlSessionManager.newInstance(sqlSessionFactory);logger.debug("[mybatis]--->get db connection done");session = sqlSessionFactory.openSession();m.invoke(targetObject, session);logger.debug("[mybatis]--->Done mybatis session......");}}logger.debug("[mybatis]--->open mybatis session and begin Query......");result = method.invoke(targetObject, args);} catch (Exception e) {throw new Exception("[mybatis]--->Init SqlSession Error:" + e.getMessage(), e);} finally {try {session.close();logger.debug("[mybatis]--->close mybatis session");} catch (Exception e) {}}return result;}
以上这个类就是我们实现了完成的“迷你”AOP的功能,它可以很好的满足我们对于:
不用关心从mybatis获取一个session是否是本地线程安全的
开发人员只需要调用mapper.selectXXX这样的语句,而不需要关心何时开启和关闭session(万一忘关了那是致命的)
来看开发人员在执行myBatis的具体mapper时的调用吧:
应用层->
DAOProxyFactory factory = new DAOProxyFactory();
StudentService aopService = (StudentService) factory.createProxyInstance(new StudentServiceImpl());
int age = aopService.getAge("ymk");Service层
public int getAge(String userId) throws Exception {UserInfoMapper userMapper = batisSession.getMapper(UserInfoMapper.class);int age = userMapper.selelctUser(userId);return age;
}Dao层->myBatis哪有Dao层

<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="org.sky.drools.sql.datasource.DruidDataSourceFactory">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url"
value="jdbc:mysql://192.168.0.101:3306/mk?useUnicode=true&characterEncoding=UTF-8" />
<property name="username" value="mk" />
<property name="password" value="aaaaaa" />
<property name="maxActive" value="20" />
<property name="initialSize" value="5" />
<property name="minIdle" value="1" />
<property name="testWhileIdle" value="true" />
<property name="validationQuery" value="SELECT 1" />
<property name="testOnBorrow" value="true" />
<property name="testOnReturn" value="true" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mybatis/mapper/UserInfoMapper.xml" />
<mapper resource="mybatis/mapper/ApplicantListMapper.xml" />
</mappers>
</configuration>
- 我们在此使用了阿里的Druid连接池
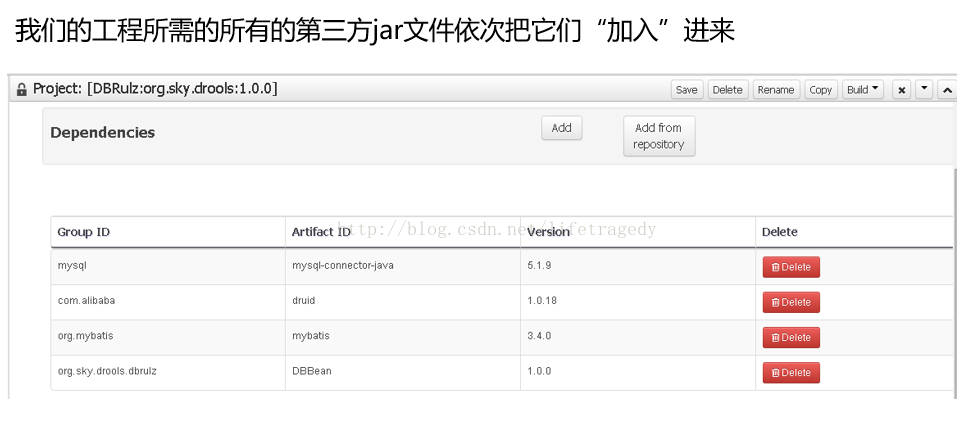
- 我们可以直接在此文件中写上值而不是“替换符”,因为对于drools上传一个jar包是无需重启服务的,上传完毕该jar后,KIE WB内部即发生了更改。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.sky.drools.dao.mapper.UserInfoMapper">
<select id="selelctUser" parameterType="String" resultType="int">
SELECT age FROM user_info WHERE user_id=#{userId}
</select>
</mapper>
把业务、因子做成全动态
public class UserInfoBean implements Serializable
private int age = 0;
private String applicant;
private String userId;
private boolean validFlag = false;
}没什么好多说的,我们为这个Bean提供了一组field,同时我们会为每个私有成员生成一对set/get方法。关键在于getAge()方法的覆盖:public int getAge() throws Exception {
int age = 0;try {
DAOProxyFactory factory = new DAOProxyFactory();
UserInfoService stdService = (UserInfoService) factory.createProxyInstance(new UserInfoServiceImpl());
age = stdService.getAge(userId);
System.out.println(age);
} catch (Exception e) {System.err.println(e.getMessage());throw new Exception("mybatis error: " + e.getMessage(), e);
}
return age;
}
我们提供一个Service->UserInfoService
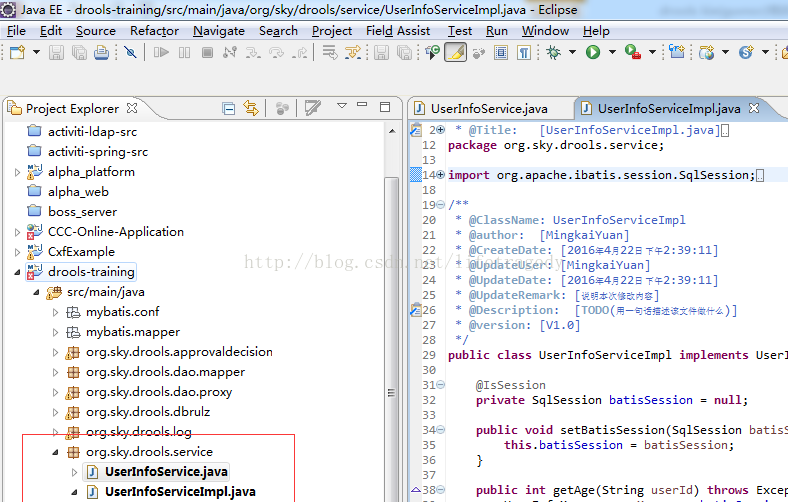
package org.sky.drools.service;import org.apache.ibatis.session.SqlSession;
import org.sky.drools.dao.mapper.ApplicantListMapper;
import org.sky.drools.dao.mapper.UserInfoMapper;
import org.sky.drools.sql.datasource.IsSession;public class UserInfoServiceImpl implements UserInfoService {@IsSessionprivate SqlSession batisSession = null;public void setBatisSession(SqlSession batisSession) {this.batisSession = batisSession;}public int getAge(String userId) throws Exception {UserInfoMapper userMapper = batisSession.getMapper(UserInfoMapper.class);int age = userMapper.selelctUser(userId);return age;}public int existInList(String userId) throws Exception {ApplicantListMapper listMapper = batisSession.getMapper(ApplicantListMapper.class);int result = listMapper.selelctUserInApplicant(userId);return result;}}
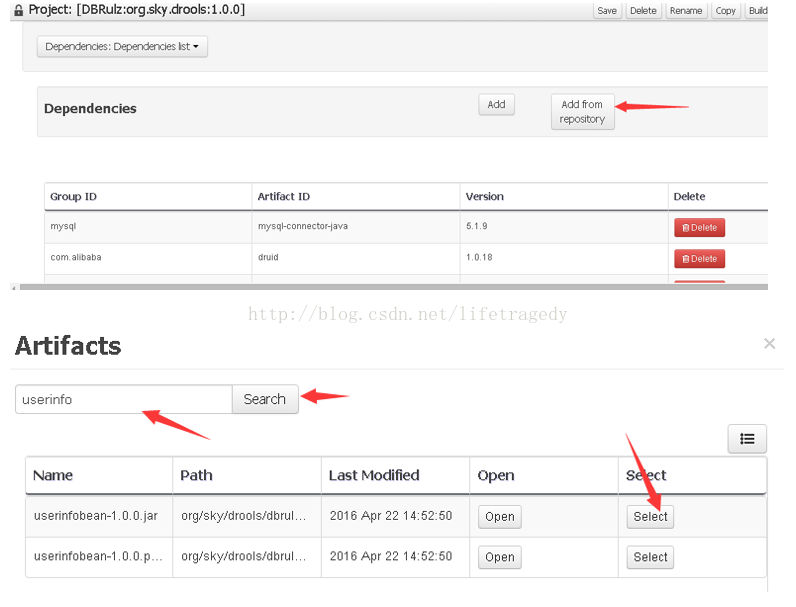
把因子打包上传至规则引擎
别忘了在工程中引用该上传的包
package org.sky.drools.dbrulz;no-loopdeclare Userage : int;validFlag : boolean;
endrule "init studentbean"
salience 1000whenu : UserInfoBean()thenUser user=new User();user.setAge(u.getAge());System.out.println("valid applicant for["+u.getUserId()+"] and validFlag is["+u.isValidFlag()+"]");insert(user);
endrule "less than < 17"whenu : User ( age <17); facts : UserInfoBean()thenfacts.setApplicant("0");
endrule "less than < 45"whenu : User ( age <46 && age >=17); facts : UserInfoBean()thenfacts.setApplicant("7000000");
endrule "less than < 70"whenu : User ( age <70 && age >=46); facts : UserInfoBean()thenfacts.setApplicant("5000000");
end
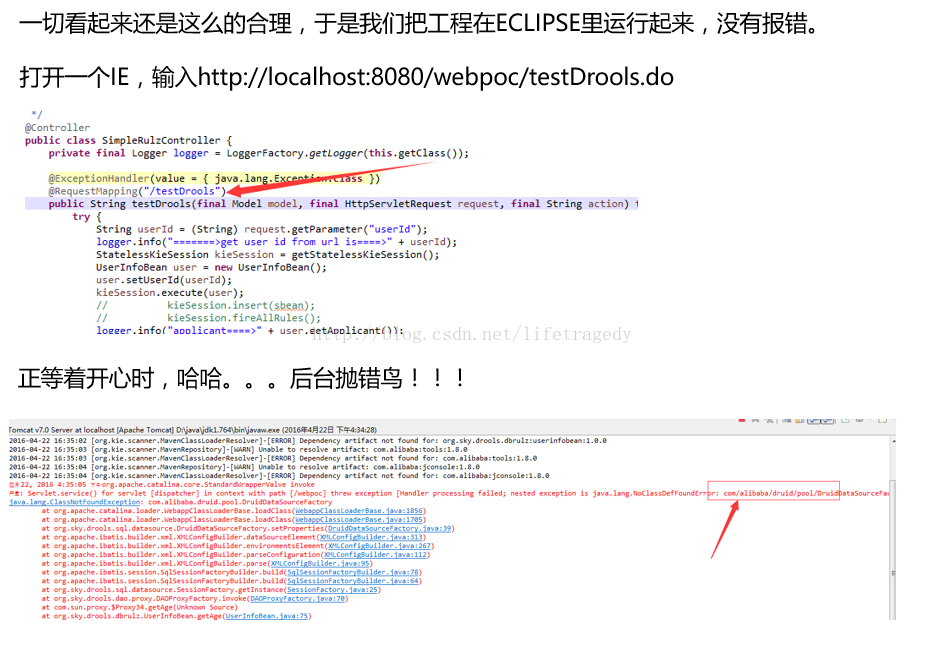
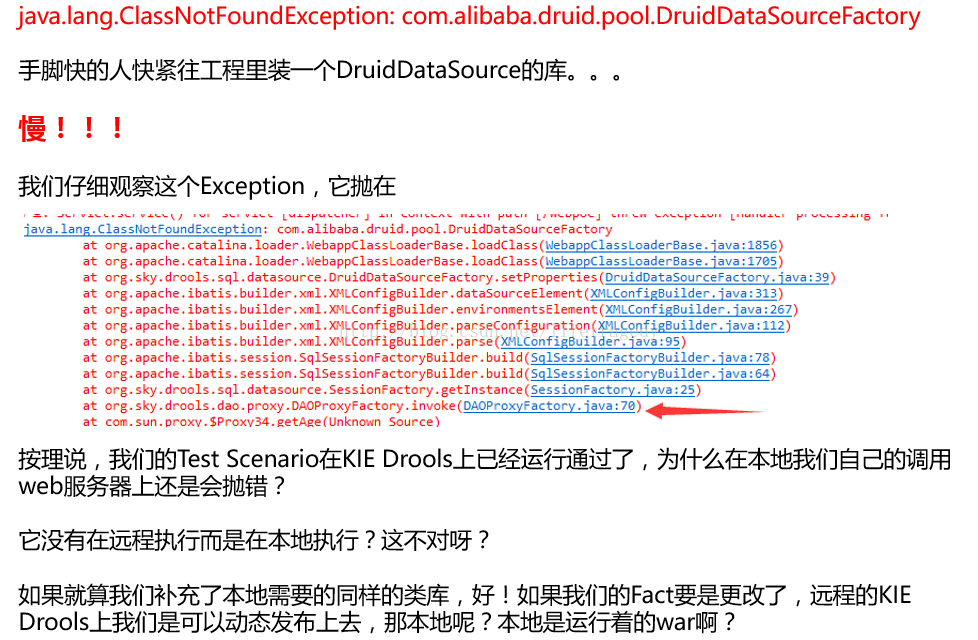
一切似乎那么着美好,一切似乎那么的顺利,我们把这个工程build一下然后来制作我们的调用端吧。
制作客户端
我们使用spring mvc制作了一个标准的web工程



嵌入式运行与独立运行
按照业务、因子动态分离的原则我们上述的行为是做不到全动态的,我们顶多只能算是一个嵌入式的应用。
但是。。。我们的努力还是没有白费!!!
因为我们的业务已经可以做到全动态了。
所以,我们的想法就是要让规则真正的运行在远程,而对于调用者来说,只需要传入一个状态、一个message得到一个返回值好可,一切规则相关的运行不应该在本地应用(业务应用web服务器)。
于是,我们发觉了DROOLS的另一个套件 KIE-SERVER。
KIE-SERVER
KIE组件真正有用的,其实是3个:

- drools-distribution-6.3.0.Final.zip-这是一个规则引擎,它可以解析.drool文件,是一个嵌入式的应用
- kie-drools-wb-6.3.0.Final-tomcat7.war-即KIE WorkBench
- kie-server-distribution-6.3.0.Final.zip-这个才是真正可以独立使用的KIE SERVER
我们要了解的就是这个kie-server-distribution-6.3.0.Final。
KIE套件默认全部用于装载于jboss eap6.x或者是jboss wildfly(8.x)中,但它也可以用于TOMCAT中的应用安装。
我们把kie-server-distribution-6.3.0.Final.zip解压开后会得到3个文件

我们把kie-server-6.3.0.Final-webc.war提练出来,它就是用于安装于tomcat7下的可独立运行的KIE-SERVER。(webc=web container-即container模式又指可用于tomcat安装)
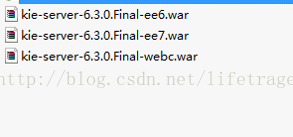
把kie-server-6.3.0.Final-webc.war扔到tomcat7的webapp目录下。
清理tomcat7 lib目录下所需的缺失的那些个jar
之前我们装过KIE-WB(WorkBench),因此我们找到tomcat/conf目录下的resources.properties文件。
这个文件里之前我们使用的是h2即一个内存数据库,现在我们来把它改成正式环境吧,
resources.properties文件内容如下:
resource.ds1.className=bitronix.tm.resource.jdbc.lrc.LrcXADataSource
resource.ds1.uniqueName=jdbc/jbpm
resource.ds1.minPoolSize=10
resource.ds1.maxPoolSize=20
#resource.ds1.driverProperties.driverClassName=org.h2.Driver
#resource.ds1.driverProperties.url=jdbc:h2:mem:jbpm
#resource.ds1.driverProperties.user=sa
#resource.ds1.driverProperties.password=
resource.ds1.driverProperties.driverClassName=com.mysql.jdbc.Driver
resource.ds1.driverProperties.url=jdbc:mysql://192.168.0.101:3306/drools?useUnicode=true&characterEncoding=UTF-8
resource.ds1.driverProperties.user=kie
resource.ds1.driverProperties.password=aaaaaaresource.ds1.allowLocalTransactions=true
找到tomcat/conf/server.xml文件,找到如下这段:
<Realm className="org.apache.catalina.realm.LockOutRealm" ><Realm className="org.apache.catalina.realm.UserDatabaseRealm"resourceName="UserDatabase"/></Realm>修改成如下:
<Realm className="org.apache.catalina.realm.LockOutRealm" lockOutTime="1" failureCount="999999"><Realm className="org.apache.catalina.realm.UserDatabaseRealm"resourceName="UserDatabase"/></Realm>修改原因:
因为KIE-SERVER一旦启动后,它会带着用户在游览器的COOKIE不断的去和KIE-WB同步,而有些用户的机器上装着360,会过一阵把用户的cookie给清除掉,一旦KIE-SERVER与KIE-WB间同步时用户名和密码失效时。。。它会造成TOMCAT的默认用户锁机制,即5次登录失败用户被锁5分钟。
到时开发者一旦碰到这种情况,就会有种丈二和尚摸不着头脑的感觉了。
找到tomcat/conf/tomcat-user文件,找到如下这段:
增加一个角色为kie-role,如下:
<?xml version='1.0' encoding='utf-8'?><tomcat-users><role rolename="admin"/><role rolename="analyst"/> <role rolename="user"/><role rolename="kie-server"/><user username="kieserver" password="aaaaaa" roles="kie-server,admin"/><user username="tomcat" password="tomcat" roles="admin,manager,manager-gui,kie-server,analyst"/>
</tomcat-users>
一定要给到相关用户kie-server这个角色。。。一定要给!!!
修改catalina.sh文件
export CATALINA_OPTS=“-Dbtm.root=$CATALINA_HOME -Dorg.jbpm.cdi.bm=java:comp/env/BeanManager \ -Dbitronix.tm.configuration=$CATALINA_HOME/conf/btm-config.properties \ -Djbpm.tsr.jndi.lookup=java:comp/env/TransactionSynchronizationRegistry \ -Djava.security.auth.login.config=$CATALINA_HOME/webapps/kie-drools/WEB-INF/classes/login.config \ -Dorg.kie.server.persistence.ds=java:comp/env/jdbc/jbpm \ -Dorg.kie.server.persistence.tm=org.hibernate.service.jta.platform.internal.BitronixJtaPlatform \ -Dorg.kie.server.id=kie-server \ -Dorg.kie.server.controller.user=kieserver \ -Dorg.kie.server.controller.pwd=aaaaaa \ -Dorg.kie.server.location=http://192.168.0.101:8080/kie-server/services/rest/server \ -Dorg.kie.server.controller=http://192.168.0.101:8080/kie-drools/rest/controller \ -Dorg.jbpm.server.ext.disabled=true -Dorg.kie.demo=false"
此处,比原有安装KIE-WB时多出了几个参数:
此处,比原有安装KIE-WB时多出了几个参数:-Dorg.kie.server.persistence.ds 告诉KIE-SERVER和KIE-WB使用一个数据源,并启用了基于bitronix的分布式事务
-Dorg.kie.server.id=kie-server 告诉JVM,KIE SERVER的实例名
-Dorg.kie.server.controller.user=kieserver 不解释了(看tomcat-user.xml)
-Dorg.kie.server.controller.pwd=aaaaaa 不解释了(看tomcat-user.xml)-Dorg.kie.server.location=http://192.168.0.101:8080/kie-server/services/rest/server 你的tomcat\webapp下kieserver工程的所在 把/services/rest/server照抄-Dorg.kie.server.controller=http://192.168.0.101:8080/kie-drools/rest/controller 你的tomcat\webapp下kie-wb的所在 把/rest/controller照抄,controller与kie的rest/server会进行心跳同步-Dorg.jbpm.server.ext.disabled=true 在kie-web中不启用jbpm功能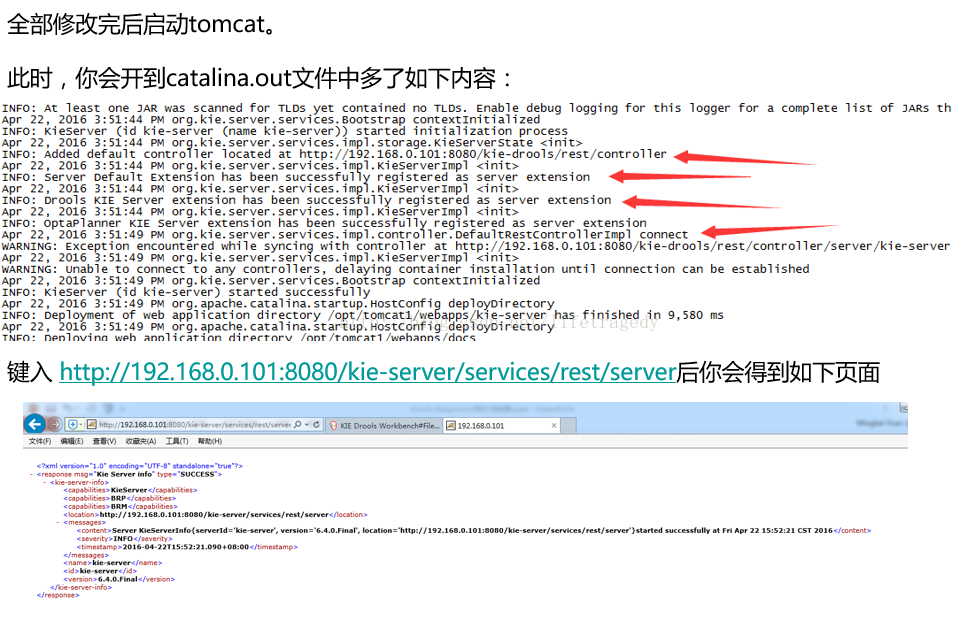
让我们打开KIE-WB来一探kie-drools + kie-server的究竟吧。
输入 http://192.168.0.101:8080/kie-drools/,你可以键入你在tomcat-user.xml中有kie-server角色的用户的登录信息。
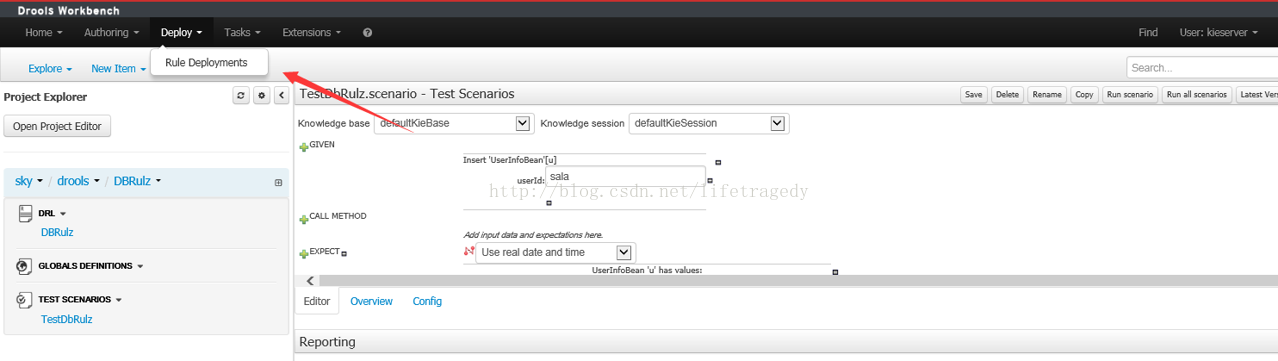
此时,在这里面你可以看到。。。咦,我们怎么多了一个KIE-SERVER出来?

你可以动态注册一个KIE SERVER通过
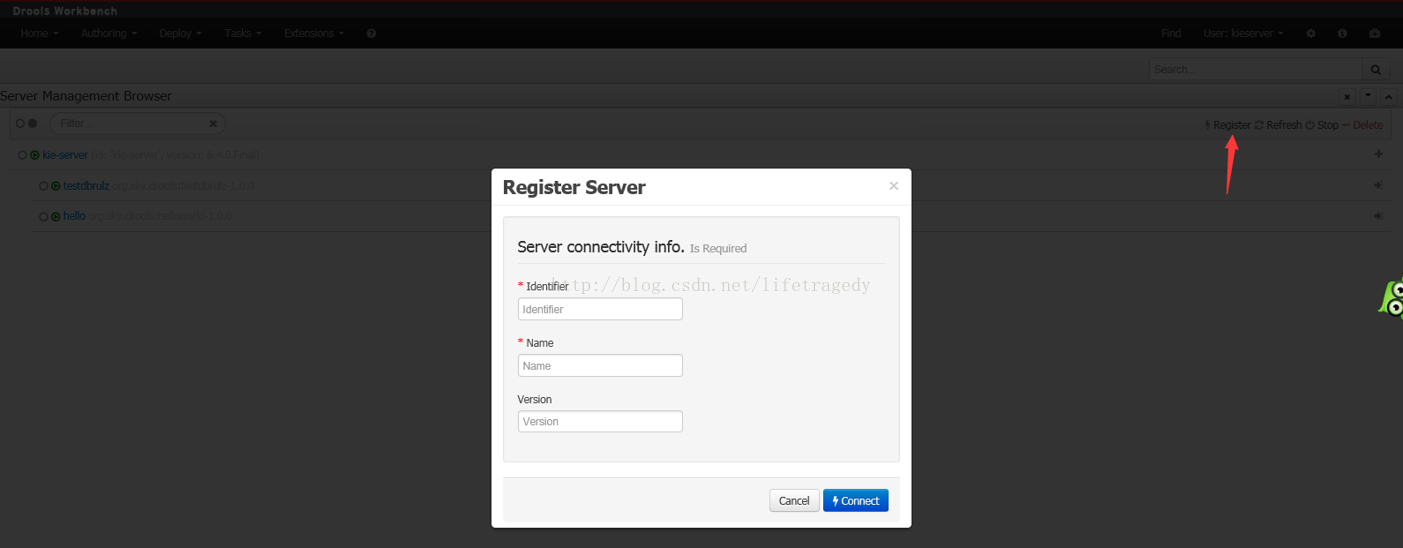
此处的信息请参照:http://192.168.0.101:8080/kie-server/services/rest/server 显示的信息

现在因为有了KIE SERVER,于是我们直接在此规则上多加一步
在规则开始处修改如下:
declare Userage : int;validFlag : boolean;
endrule "init studentbean"
salience 1000when$u:UserInfoBean(userId!=null)//$u:UserInfoBean();thenSystem.out.println("valid applicant for["+$u.getUserId()+"] and validFlag is["+$u.isValidFlag()+"]");User userVO=new User();userVO.setAge( $u.getAge());userVO.setValidFlag($u.isValidFlag());insert(userVO);End以下这段加在原有规则最后:
rule "not a valid applicant"whenuser:User(!validFlag) && u:UserInfoBean(userId!=null)//u : UserInfoBean( !validFlag ); thenu.setApplicant("0");
endpackage org.sky.drools.dbrulz;
declare Userage : int;validFlag : boolean;
end
rule "init studentbean"
salience 1000when$u:UserInfoBean(userId!=null)
thenSystem.out.println("valid applicant for["+$u.getUserId()+"] and validFlag is["+$u.isValidFlag()+"]");User userVO=new User();userVO.setAge( $u.getAge());userVO.setValidFlag($u.isValidFlag());insert(userVO);
end
rule "less than < 17"whenuser: User(age<17) && u:UserInfoBean(userId!=null)thenu.setApplicant("0");
end
rule "less than < 45"when(user: User(age<46 && age>=17)) && u:UserInfoBean(userId!=null)
thenSystem.out.println("set applicant for "+u.getUserId()+" to 7000000");u.setApplicant("7000000");
end
rule "less than < 70"when(user:User(age<70 && age>=46)) && u:UserInfoBean(userId!=null)
thenSystem.out.println("set applicant for "+u.getUserId()+" to 5000000");u.setApplicant("5000000");
endrule "not a valid applicant"whenuser:User(!validFlag) && u:UserInfoBean(userId!=null)
thenu.setApplicant("0");
end
规则解释:
其实这个规则很简单,关键之处在于我们更改了Fact中的getAge(),那么它会在每一个规则处进行一次数据库操作。
虽然,我们的数据库操作用的是myBatis,在取得SessionFactory和Session时都已经做成了POOL和SINGLETON且ThreadSafe了。
但是每个getAge()它还是会作一次“迷你AOP”和一次数据库的DAO操作,对不对?
那么我们来说,我们取得一个输入人的UserId,拿到了它的年龄即可以用规则来计算它的保额了,所以我们说:通过userId取getAge()仅应该做一次数据库操作,对不对?
因此我们这边使用了Drools的declare语法,预声明了一个Object,该Object会运行在一条:
rule “init studentbean”且salience 1000的规则中。
这条规则中的salience 1000代表(salience后的数字越高运行优先级最高-即默认“主方法”),在这条规则中我们作了一件 事:
通过用户转入的fact的userId然后调用getAge()进行一次数据库操作并赋给declare的User,以后就用这个User进行全局规则匹配即可。
这是一个技巧。
看看我们是如何改变UserInfoBean中的validFlag的。
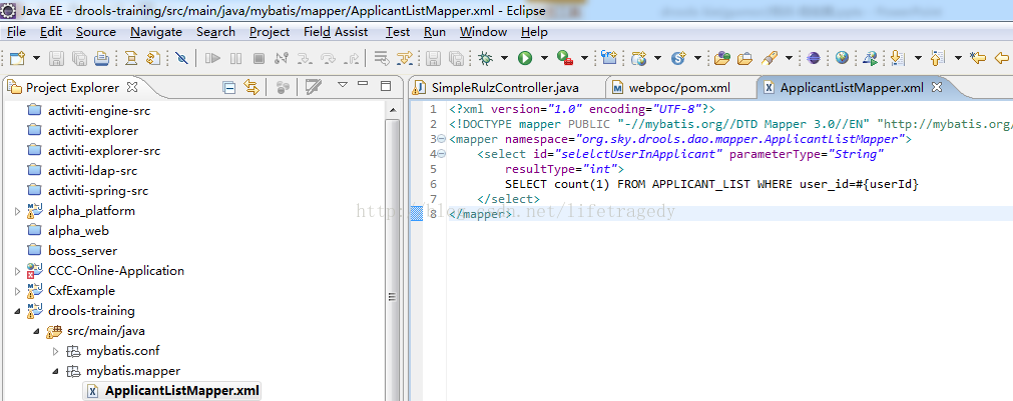
我们先是加了一个mapper,它会从数据库表applicant_list中根据user_id进行count(),以下是isValidFlag的具体实现
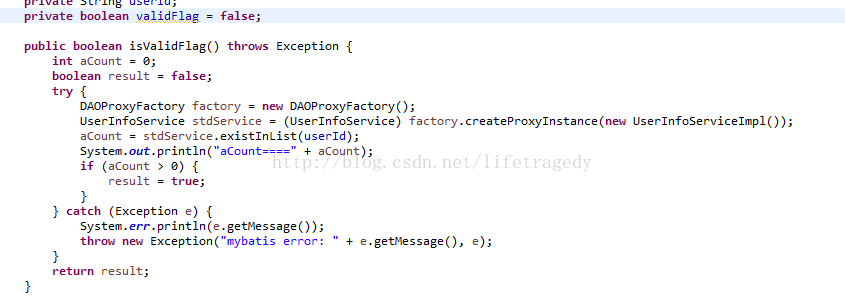
因此,我们实现了:假如一个申请人即使他的年龄符合年龄审核规则,但是如果它并不存在于applicant_list表中的话那么他可以申请的保额依旧为“0”元这样的一个规则。
当然,我们也可以不用做两个mapper + 2个service方法而是在原有的mapper中加入一条:
SELECT COUNT(1) FROM USER_INFO
WHERE USER_ID='ymk'
AND EXISTS (SELECT USER_ID FROM APPLICANT_LIST WHERE USER_ID='ymk');
来搞定,此处我这么做只是为了验证-迷你AOP中“一个service中有多个mapper共享session的原理是否正确”
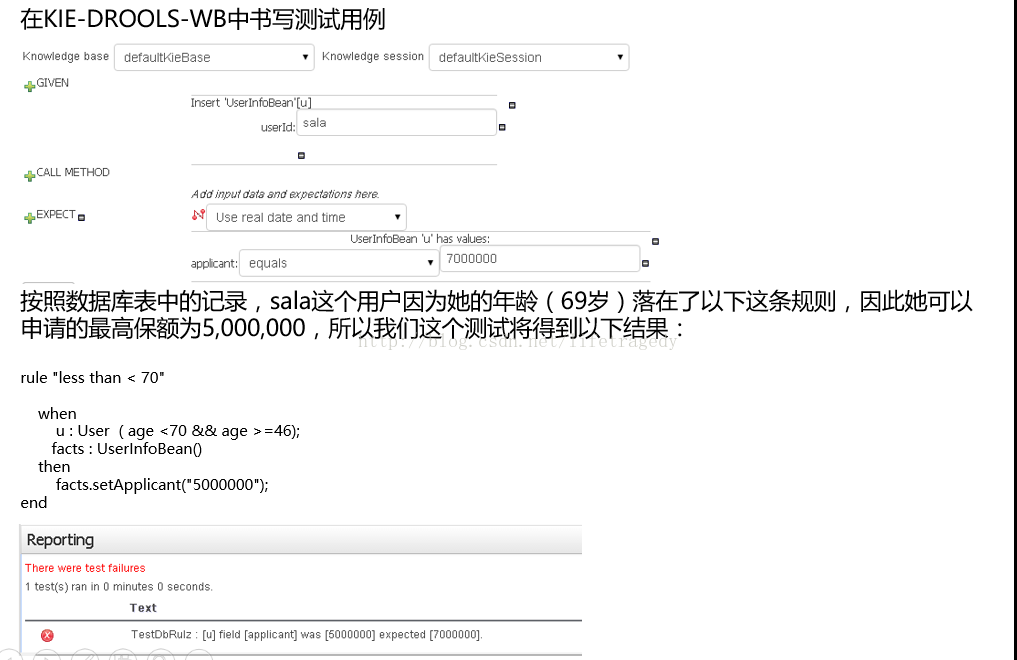
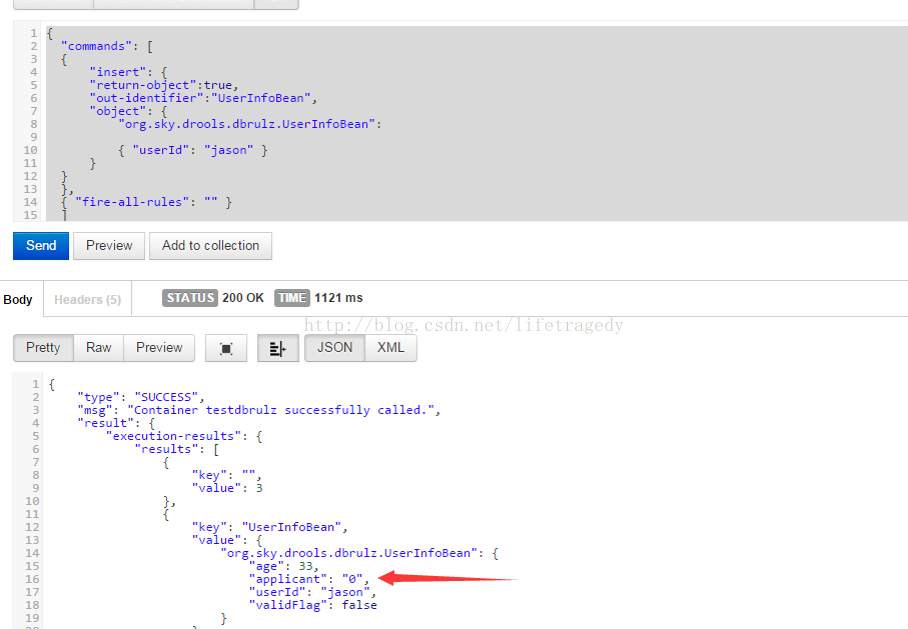
全部做完后:上传因子->引入原有工程->使用Test Scenario测试其正确性,可以看到jason符合年龄段为7,000,000的保额申请标准,但是jason却不在applicant_list表中,因此它最终可以申请的保额还是为“0”
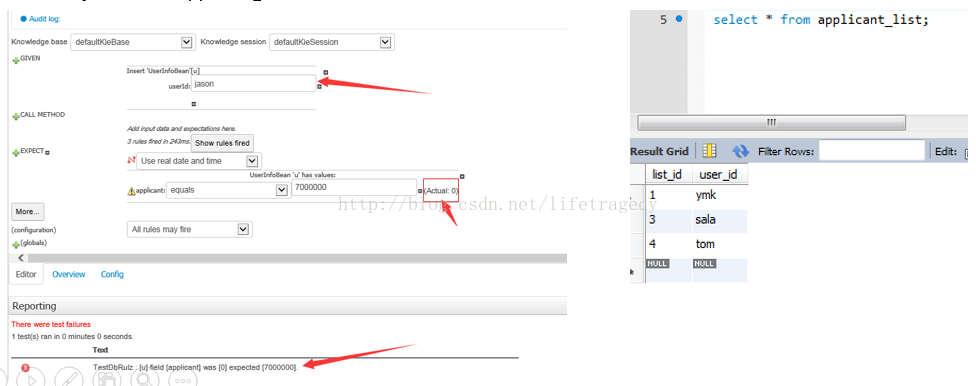
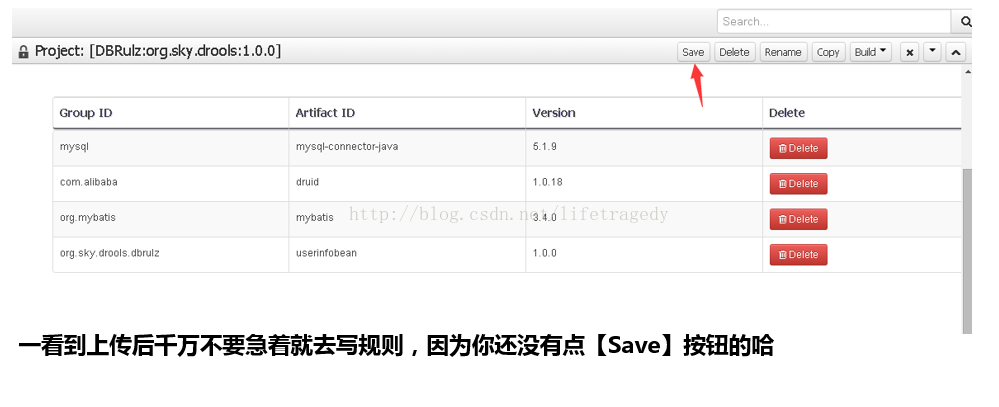
别忘了save你的工程
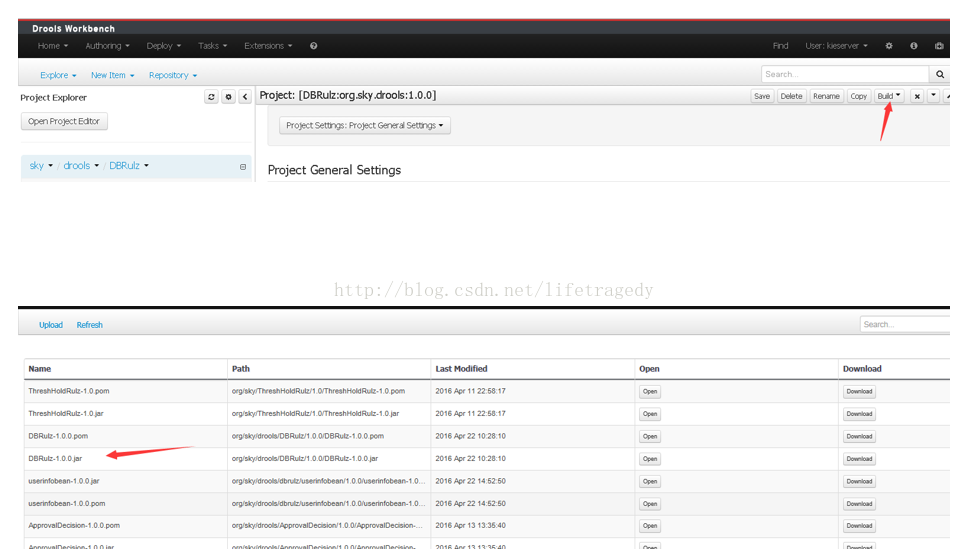
BUILD(build时把请把版本改成2.0.0)
开始创建KIE SERVER的CONTAINER
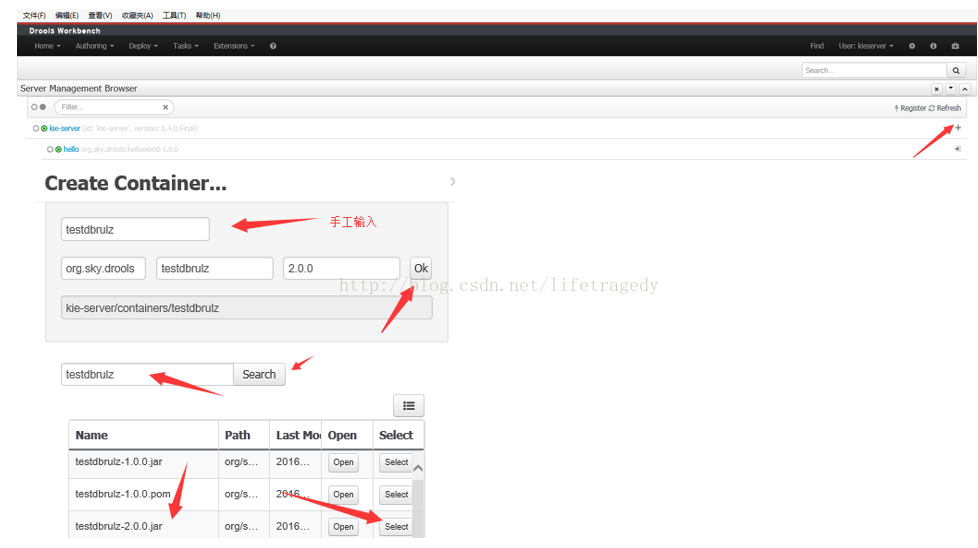
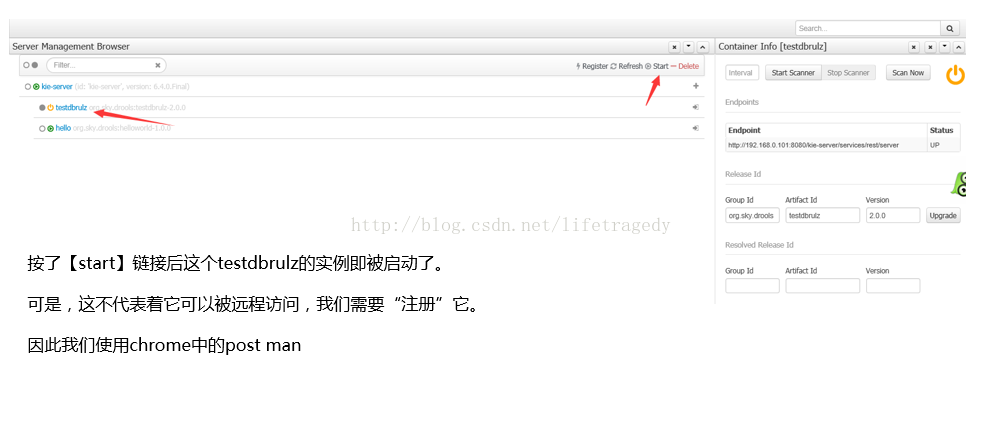
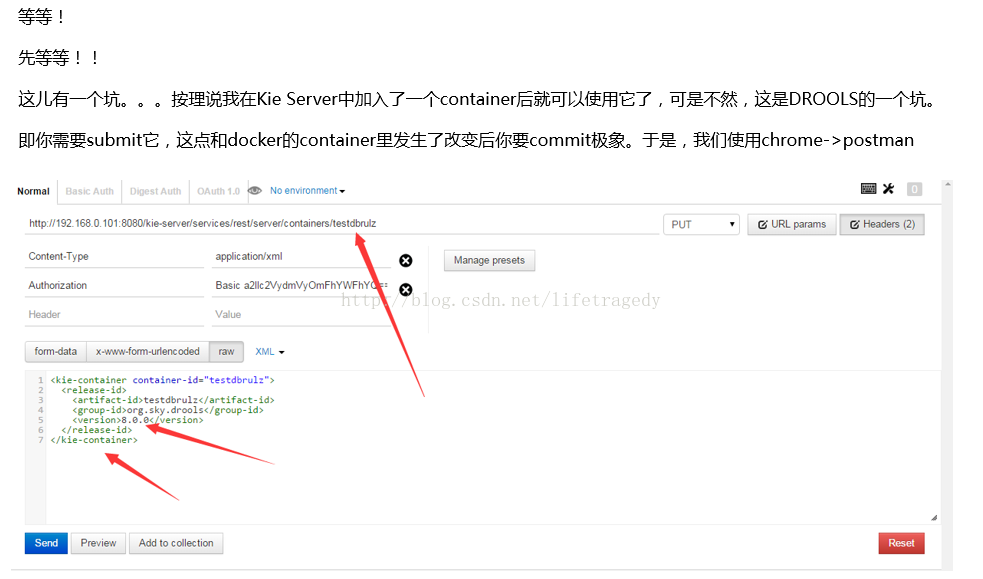
看到postman 输出SUCCESS字样后,我们输入如下的网址:
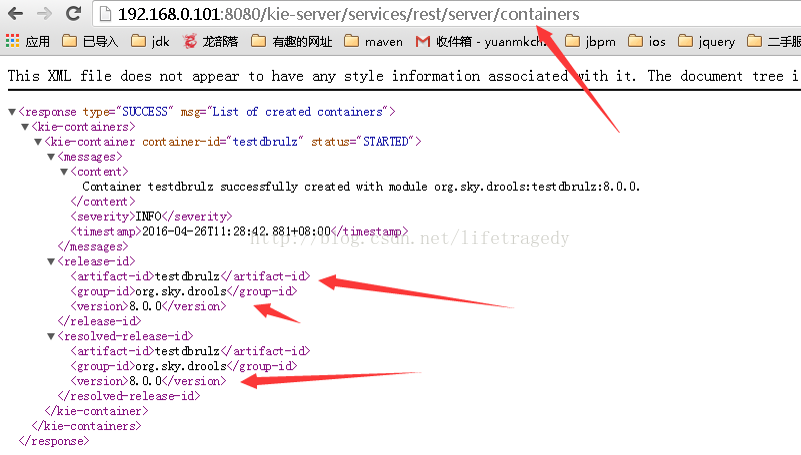
http://192.168.0.101:8080/kie-server/services/rest/server/containers
看到以下信息即宣告我们的container布署成功。接下去我们就可以使用postman来发请求了。
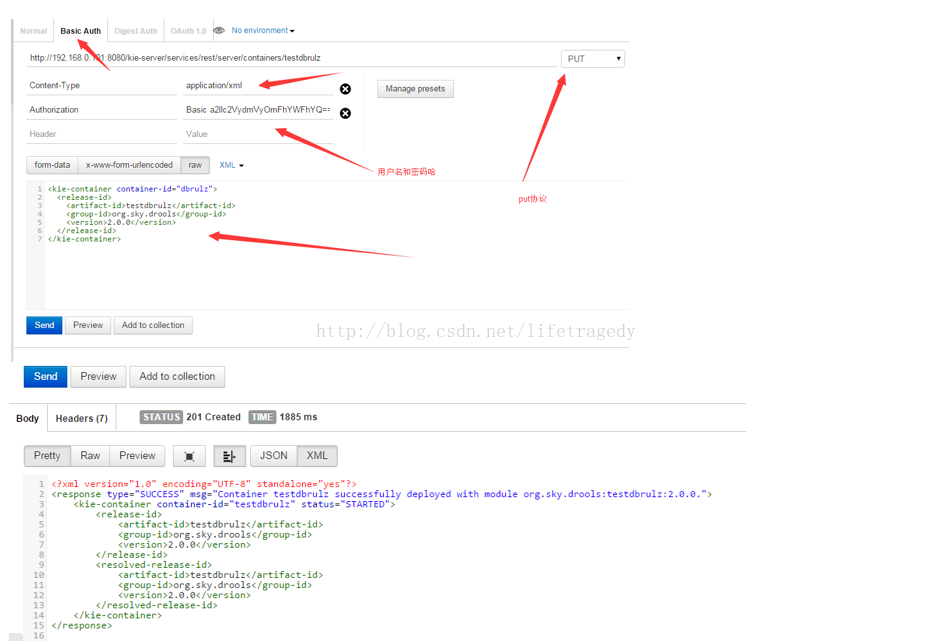
在你看到注册成功后,依旧使用chrome->postman来真正运行我们的远程规则吧
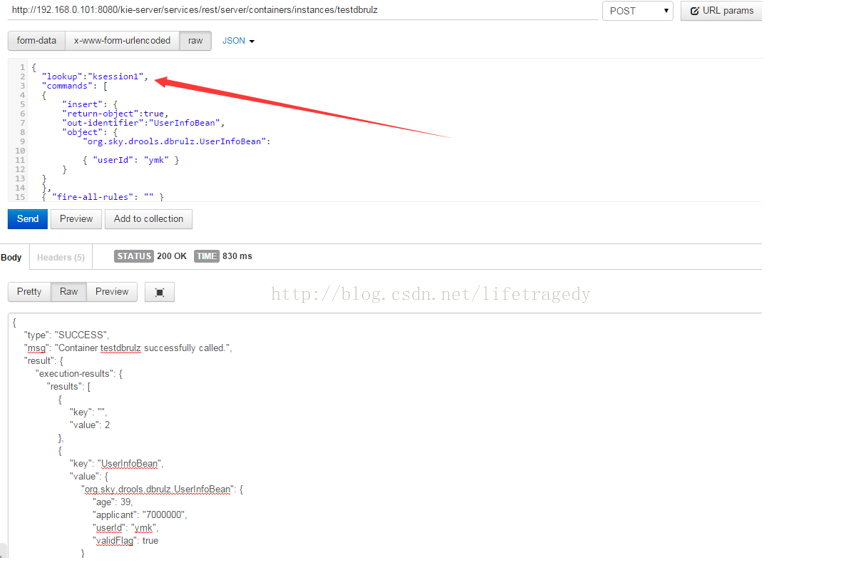
POST请求的JSON报文如下:
{"commands": [{"insert": {"return-object":true,"out-identifier":"UserInfoBean","object": {"org.sky.drools.dbrulz.UserInfoBean":{ "userId": "jason" }}}},{ "fire-all-rules": "" }]
}
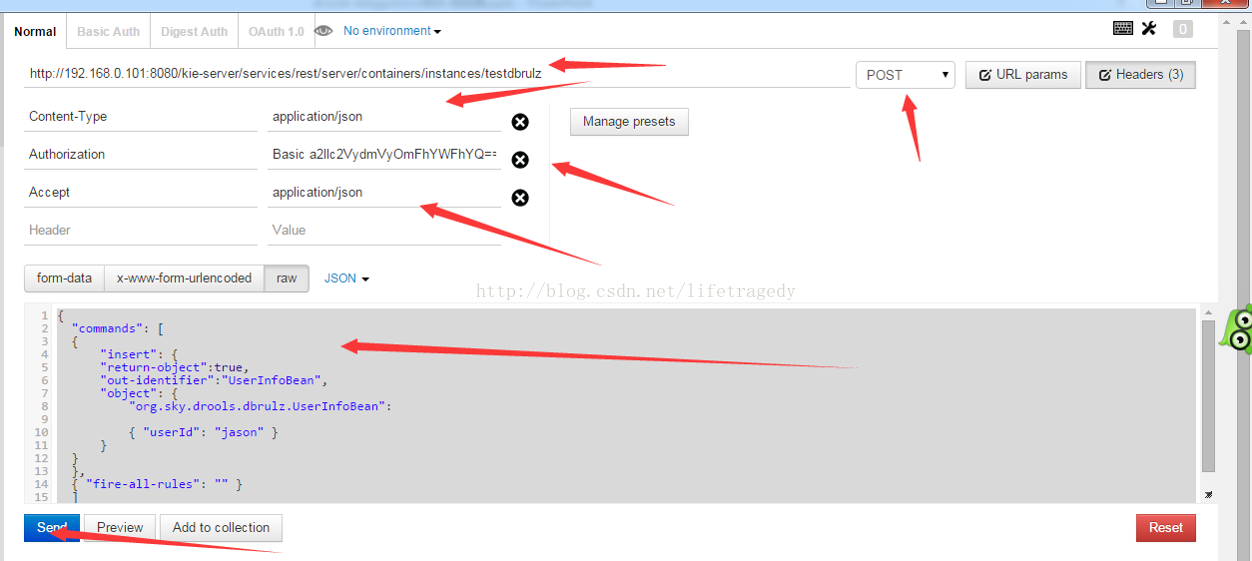
Kie Server中的container即可以commit也可以delete,如果我们需要重新STOP,STAR一个Container,不仅仅是需要在KIE SERVER中

同时,还需要使用postman发送一个json请求,请注意下面的截图
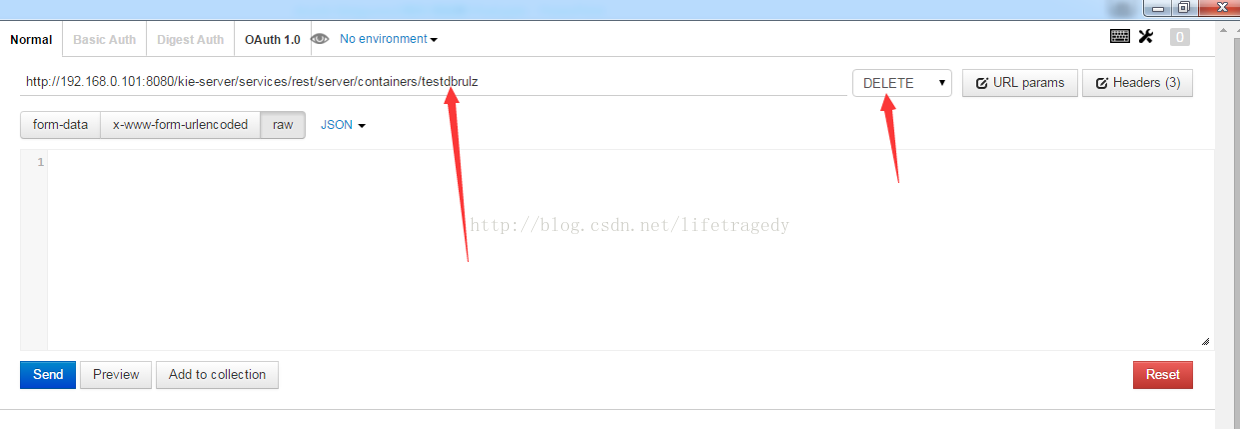
Container更新请按照如下几步:
- SAVE更改过的工程
- BUILD工程
- 在KIE SERVER UI界面中STOP, DELETE相关CONTAINER
- 使用JSON客户端具DELETE该Container
- 使用KIE SERVER UI界面中+一个Container
- 使用JSON客户端 POST一个建Container的请求
我们接着把userId分别换成 ymk, sala2个名字,我们都得到了相应的结果,关键的是来看后台的日志。
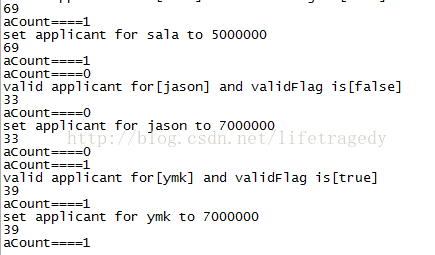
由于我们在后台加入了相应的日志,每次调用getAge()时都会有一个输出,可以清楚的看到,我们的DB调用为3次,因为我们进行了3次POST请求。
如果DB操作为15次(5条规则被触发了3次)那就不对了。
什么叫真正的业务可以实现24*7
刚才我们这一系列的步骤全部在服务器完成,而在修改规则、上传FACT甚至包括对DAO层、SEVICE层“大修”,我们的规则服务器始终是不需要重启的。
而调用该规则服务仅仅是通过下面这样的JASON
{"commands": [{"insert": {"return-object":true,"out-identifier":"UserInfoBean","object": {"org.sky.drools.dbrulz.UserInfoBean":{ "userId": "jason" }}}},{ "fire-all-rules": "" }]
}
那么此处的userId和userId的具体值呢?来自于业务系统前面的web界面带进来的。。。所以,由此我们真正实现了“IT快速响应业务的随时变更,真正做到了24*7的Service”。
再谈Stateless Session和Stateful Session
如果有人忽略了这一章,那么你会犯一个巨大的错误。
来看什么叫Stateless Session和Stateful Session。
即有状态和无状态。
通过以上章节,我们使用的是Rest API来访问的规则,换句话说就是使用的是http来访问的。
那么我们来说,有一群人在访问规则,有一堆Legacy System在访问规则。
假设我们使用的是Stateful Session,我们来看这样的一个场景:
A、B、C同时访问我们的规则,使用的是Stateful(如果你的工程不做任何设置,那么它BUILD和Deploy出来的东东就是Stateful Session访问)来访问我们的规则。
A传入了userId=“ymk”(可申请的保额应为7,000,000)
B传入了UserId=“sala” (可申请的保额应为5,000,000)
C传入了userId=“Jason” (可申请的保额应为0-因为不在applicant_list名单中)
接下来的事情好玩了,A可能得到可申请保额为0,B可能得到可申请保额为5,000,000。
为什么会这样乱窜?
原因是你的工程没有做任何设置,它默认提供给REST API访问时启用的是Stateful Session,即所有请求共享Session。
而面对Http场景的应用,我们需要的是Session隔离,即Stateless Session。
那我们就来看如何把我们的工程真正的设置成Stateless Session吧。
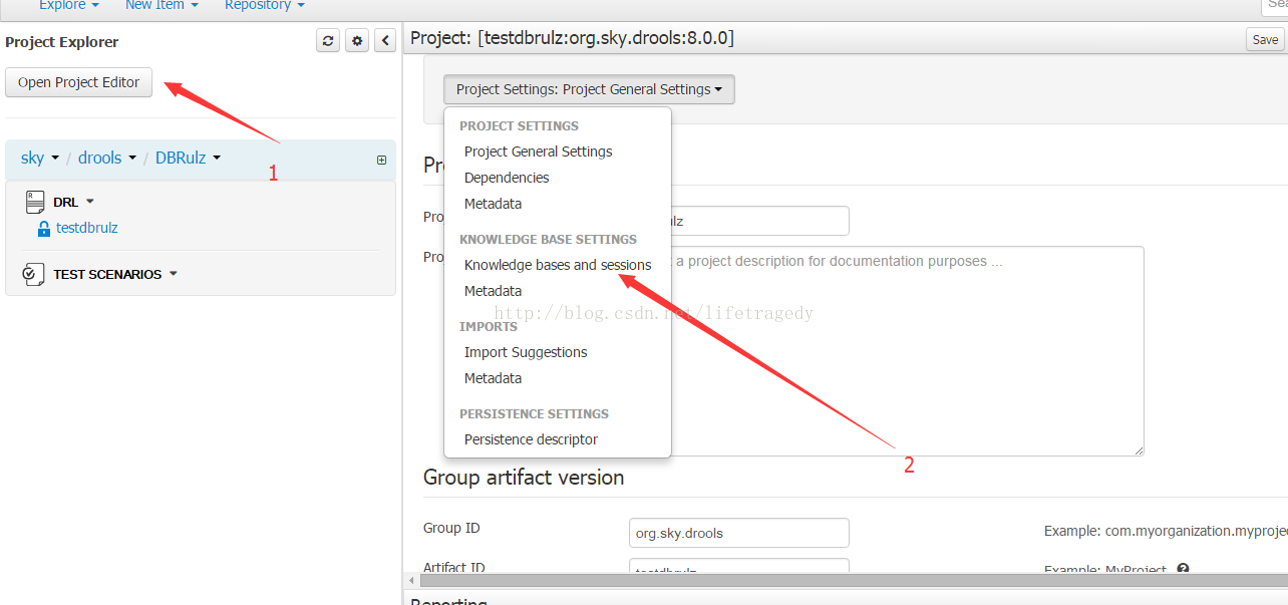
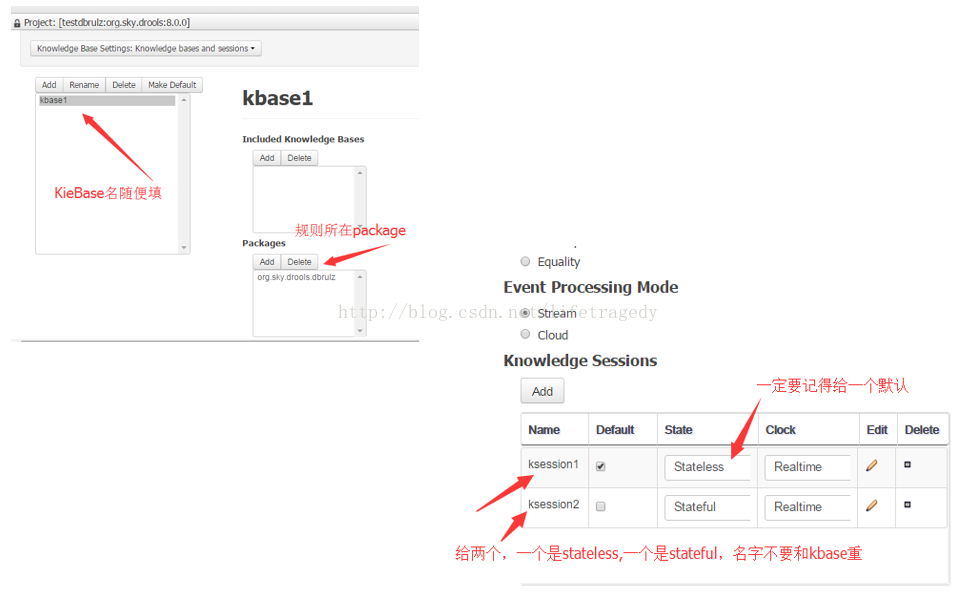
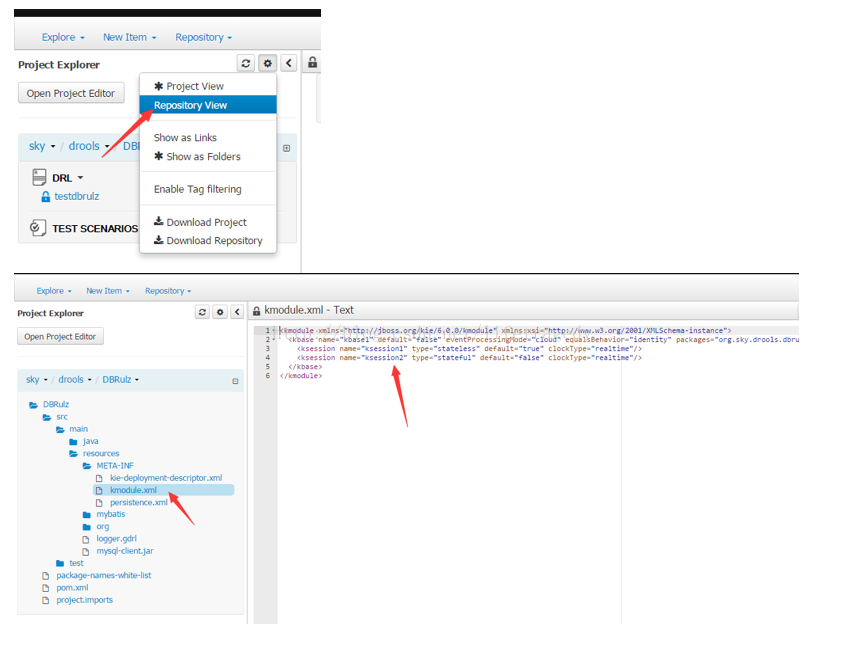
我们的工程布署成了“兼顾Stateless Session”和“Stateful Session”后我们的POST的JSON变成如下格式
第一步: 上传slf4j至KIE DROOLS
第二步: 在规则中设置一个全局变量,在规则中的最开始,package下如此声明:
global org.slf4j.Logger logger
然后你就可以在规则中到处logger.info了。
但是,这边有一个前提!!!
即:此规则如果在KIE的Test Scenario中运行的话,此处logger.info调用会抛空指针异常,要让规则中的logger.info正常使用,你必须使用JAVA代码的方式如下调用:
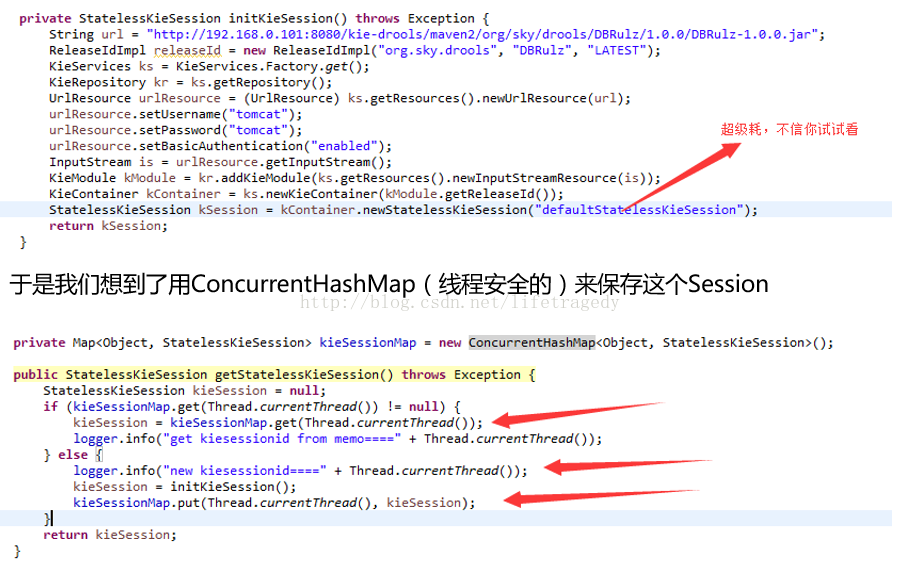
private final Logger logger = LoggerFactory.getLogger(this.getClass());StatelessKieSession kieSession = getStatelessKieSession();kieSession.setGlobal(logger);;kieSession.execute();
drools语言学习教程
Drools Expert语言(MVL解释语言)学习资料
Drools REST API大全
这篇关于jboss规则引擎KIE Drools 6.3.0-高级讲授篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



