本文主要是介绍论文阅读Personalized Image Aesthetics Assessment with Rich Attributes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.PIAA&GIAA
2.数据集 "PARA"
2.1.图片收集
2.2 标签设计
2.3 人员选择
2.4 主观实验
3.数据分析
4.基准(benchmark)
5.结论
6.专业术语
1.PIAA&GIAA
GIAA:只反映了平均观点,忽视了美感评估的高度主观性
PIAA:捕获独一无二的审美偏好
PIAA 模型产生于通用美学评价模型(GIAA),区别之处在于:使用个人数据微调,强调学习个性化偏好。相比无条件的 PIAA 模型,条件 PIAA 建模时分别添加了三种条件信息,包括个体性格、美学经验和摄影经验。
2.数据集 "PARA"
从以人为方向和以图片为方向的两个方面设计标签,尤其,除了图片美感特征,也收集了主观评价:1.内容偏好2.评估难度3.情感4.分享意愿
数据集制作分为四步:图片收集、标签设计、人员选择以及主观实验
2.1.图片收集
AES:第一个用于PIAA的数据集
FLICKR-AES:不是由图片的拥有者提供的
REAL-CUR:小规模数据集,通常用作测试集
AADB:提供了11个美学评估注释和美学分数
2.2 标签设计
13个标签:13个属性标签包含 9个客观属性(例如图像美学、情感等),4个主观属性(例如内容偏好、分享意愿等)
2.3 人员选择
人员选择的原则是保证被试人员的质量和多样性,研究员从健康状况、标注经历、用户画像以及培训考核等方面选择“入库人群”。例如,只有具有一定标注经验,身心健康的个体,且通过每日的标注培训和考核后,才可以进行数据标注。
2.4 主观实验
主观实验遵循心理学主观实验规范。研究员将整个数据库分成 446 个标注会话,每个标注会话包含 70 张待标记的图像,5 张有标记的图像(提前多人标注作为标准图校验标注是否符合通用标准),以及 5 张重复的图像(需要打两次标注的,从而测试标注的一致性)
3.数据分析

在(4,5] 区间,美学评分比起其他区间具有更低的方差,这意味着对 "什么是美 "有共同的认知,但存在不同的审美观点。

表明图片的质量能很大程度影响美学评分;当人们喜欢图片内容的时候会更容易分享图片
4.基准(benchmark)
 由于 PIAA 是一个典型的小样本问题,研究员们参考零样本学习以及之前的相关工作进行实验设置,例如分为三组:无微调组(“对照组”)、10-shot 组、100-shot 组
由于 PIAA 是一个典型的小样本问题,研究员们参考零样本学习以及之前的相关工作进行实验设置,例如分为三组:无微调组(“对照组”)、10-shot 组、100-shot 组
结果:
- 10-shot 组、100-shot 组PIAA胜过无微调组(“对照组”)
- 更多的个性化训练数据能更好的提升微调表现
- 在PIAA模型上利用主观特征信息能够提升模型表现
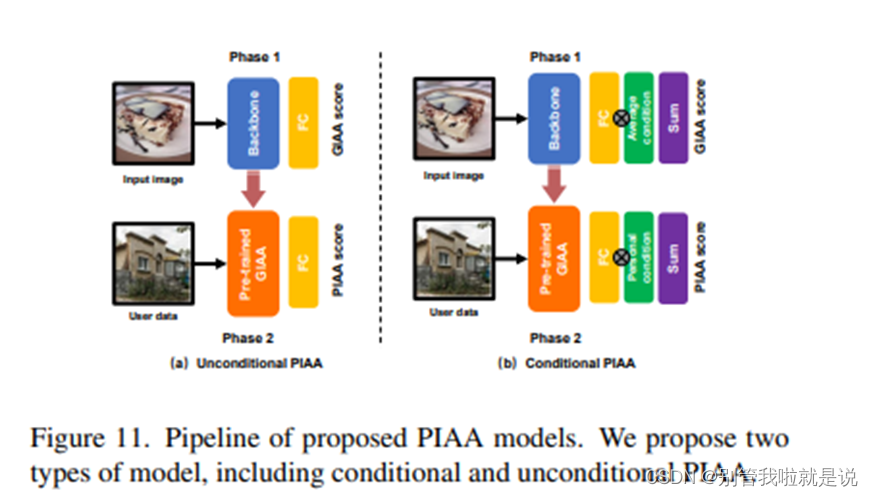
Unconditional PIAA:训练一个GIAA模型,直接利用个人数据来学习个性化偏好直接微调GIAA模型
Conditional PIAA:构建模型时添加了3类条件信息——个性特征、美术经历、摄影经历
5.结论
- 一个心得PIAA数据集“PARA”:13个维度,9个客观属性(例如图像美学、情感等),4个主观属性(例如内容偏好、分享意愿等)
- 实验结果表明个性化美学偏好能映射出主观特征
- 增加主观信息能更好地构建个性化美学偏好模型
6.专业术语
- collaborative learning:协同学习是指使用一个资源丰富的模态信息来辅助另一个资源相对贫瘠的模态进行学习,比如迁移学习(Transfer Learning)就是属于这个范畴
- meta-learning:元学习,又称为learning to learn,该算法旨在让模型学会“学习”,能够处理类型相似的任务,而不是只会单一的分类任务。
- Personalized Image Aesthetics Assessment:个性化图像美学评估
- Ground truth:在有监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注,正确的t标注是ground truth, 错误的标记则不是。(也有人将所有标注数据都叫做ground truth)
- Few-shot Learning:少样本学习,用很少的样本去做分类或者回归,是 Meta Learning 在监督学习领域的应用,few-shot learning与传统的监督学习算法不同,它的目标不是让机器识别训练集中图片并且泛化到测试集,而是让机器自己学会学习
论文原文:08388.pdf (xidian.edu.cn)
这篇关于论文阅读Personalized Image Aesthetics Assessment with Rich Attributes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








