本文主要是介绍RT-2(robotics-transformer2)论文翻译——2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:
ChatGPT等基于Transformer的大语言模型(LLM)的成功带给了人们巨大的震撼,其表现的few-shot甚至zero-shot能力仿佛让人们看到了通用人工智能(AGI)的曙光。而CLIP等跨模态模型打通了NLP和CV的界限,这些VLM模型将AGI发展继续向前推进。
AGI在机器人领域同样有很大的提升空间。试想如果机器人拥有了LLM般的思考能力,那世界将变得多么智能!届时的机器人不是只能机械执行预先设定好的程序,而是能够真的读懂人类,和人类自然交互。
RT2是谷歌deepmind团队今年7月底结合VLM和机器人控制技术研发的横跨语言-视觉-动作三模态的大模型。真正赋予了机器人的泛化能力!
——————————————————————————————————————————
本文包括论文的实验、不足、结论及附录的节选翻译;论文其他部分翻译和解读见本专栏其他文章。翻译仅供参考。
论文地址:arxiv.org/pdf/2307.15818.pdf
翻译:ChatGPT
Experiments
我们的实验重点关注RT-2的现实世界泛化和新兴能力,并旨在回答以下问题:
- RT-2在已知任务上的表现如何,更重要的是,它如何在新对象、背景和环境上进行泛化?
- 我们能否观察和衡量RT-2的任何新兴能力?
- 泛化效果如何随参数数量和其他设计决策而变化?
- RT-2是否能像视觉-语言模型一样展现出链式思维推理的迹象?
通过实验和定量评估,我们可以回答这些问题,深入了解RT-2的性能、能力和泛化特点。这些问题的回答将有助于我们对于将大规模视觉-语言模型与机器人控制相结合的方法和效果有更全面的理解。
我们在各种条件下对我们的方法和几种基线模型进行了约6,000个评估轨迹的评估,这些条件将在以下各节中进行描述。除非另有说明,我们使用一个7自由度的移动操纵器,其动作空间在第3.2节中有所描述。我们还在项目网站上展示了RT-2在实际执行中的示例:robotics-transformer2.github.io。我们训练了两种特定的RT-2实例,它们利用了预训练的VLMs:(1)RT-2-PaLI-X是由5B和55B的PaLI-X(Chen等,2023a)构建的,(2)RT-2-PaLM-E是由12B的PaLM-E(Driess等,2023)构建的。
在训练过程中,我们利用了Chen等人(2023a)和Driess等人(2023)的原始网络规模数据,其中包括视觉问答、图像描述以及非结构化的交织图像和文本示例。我们将这些数据与Brohan等人(2022)的机器人演示数据相结合,该数据在办公室厨房环境中通过13个机器人在17个月内收集而来。每个机器人演示轨迹都用自然语言指令进行了注释,该指令描述了所执行的任务,包括描述技能的动词(例如,“pick”、“open”、“place into”)以及描述操作的一个或多个名词(例如,“7up can”、“drawer”、“napkin”)(有关所使用数据集的更多详细信息,请参见附录B)。对于所有RT-2的训练过程,我们采用了原始的PaLI-X(Chen等,2023a)和PaLM-E(Driess等,2023)论文中的超参数,包括学习率调度和正则化。更多的训练细节可以在附录E中找到。
基线。我们将我们的方法与多个挑战我们方法不同方面的最新基线进行比较。所有的基线都使用完全相同的机器人数据。为了与最先进的策略进行比较,我们使用了RT-1(Brohan等,2022),这是一个拥有35M参数的基于Transformer的模型。为了与最先进的预训练表示进行比较,我们使用了VC-1(Majumdar等,2023a)和R3M(Nair等,2022b),通过训练RT-1骨干以将它们的表示作为输入来实现策略。为了与其他使用VLM的架构进行比较,我们使用了MOO(Stone等,2023),它使用VLM创建了一个额外的图像通道用于语义地图,然后将其馈送到RT-1骨干中。更多信息请参见附录C。
RT-2在已知任务上的表现如何,及它如何在新对象、背景和环境上进行泛化?
为了评估内分布的性能以及泛化能力,我们将RT-2-PaLI-X和RT-2-PaLM-E模型与前文提到的四个基线进行比较。对于“已知任务”类别,我们使用了与RT-1(Brohan等,2022)中相同的一组已知指令,其中包括超过200个任务:36个用于拾取物体,35个用于撞击物体,35个用于将物体放置直立,48个用于移动物体,18个用于打开和关闭各种抽屉,以及36个用于从抽屉中取出和放置物体。然而,需要注意的是,即使在这些“内分布”评估中,物体的放置以及诸如一天中的时间和机器人位置等因素仍然会变化,这要求模型具有在环境中的实际变化中进行泛化的能力。
我们将泛化评估分为三种未知类别(物体、背景和环境),并进一步分为简单和困难情况。对于未知物体,困难情况包括更难抓取和更独特的物体(例如玩具)。对于未知背景,困难情况包括更多变化的背景和新颖的物体。最后,对于未知环境,困难情况对应于一个更具视觉特色的带有监视器和配件的办公桌环境,而较简单的环境是一个厨房水槽。这些评估涵盖了超过280个任务,主要关注在许多不同情境下的拾取和放置技能。未知类别的指令列表在附录F.2中有详细说明。
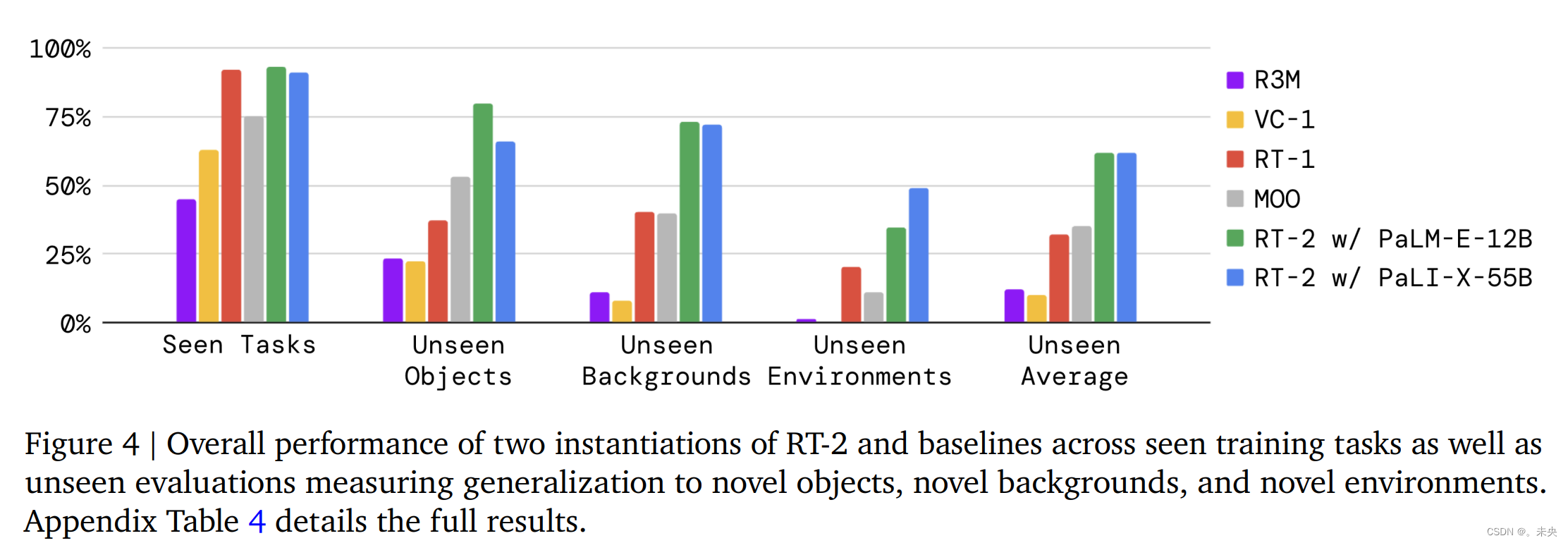
评估结果显示在图4和附录表4中。在已知任务上,RT-2模型和RT-1的性能相似,而其他基线的成功率较低。在各种泛化实验中,RT-2模型与基线之间的差异最为显著,这表明视觉-语言-动作模型的优势在于从其互联网规模的预训练数据中转移更具有泛化性的视觉和语义概念。在这里,平均而言,RT-2的两种实例表现相似,相对于RT-1和MOO,它们的改进约为2倍,而相对于其他基线,改进约为6倍。RT-2的PaLM-E版本在更困难的泛化场景中表现似乎优于RT-2-PaLI-X,但在较简单的场景中表现不佳,导致了类似的平均表现。
开源Language-Table基准测试。为了提供使用开源基线和环境的额外比较,我们利用了Lynch等人(2022)的开源语言表格模拟环境。我们在Language-Table数据集上对一个较小的PaLI 3B模型进行了联合微调,包括在领域VQA任务中进行了预测,然后在模拟环境中评估了生成的策略。对于动作预测任务,我们将动作离散化并编码为格式为“X Y”的文本,其中X和Y在{-10,-9,...,+9,+10}之间变化,表示末端执行器的2D笛卡尔设置点的增量。由于其尺寸较小,生成的模型可以以类似的速率(5 Hz)运行推断,就像其他基线一样。这个实验的结果在表1中呈现。我们观察到使用我们的模型与基线相比,在不同的机器人模拟环境中,可以获得显著的性能提升,这表明基于VLM的预训练结合大型PaLI模型的表达能力在其他场景中也可能是有益的,例如这种情况下的模拟。我们还在图5中展示了实际的现实世界外分布行为,展示了新的推动任务以及以前在该环境中未见过的目标。关于语言表格实验的更多细节可以在附录B和D中找到。
我们能否观察和测量RT-2的任何新兴能力呢?
除了评估视觉语言动作模型的泛化能力之外,我们还旨在评估这些模型在多大程度上能够通过从网络传递知识来实现超出机器人数据中所示能力的新功能。我们将这种能力称为新兴能力,因为它们通过从互联网规模的预训练中获得而出现。我们并不指望这种传递能够实现新的机器人动作,但我们确实期望语义和视觉概念,包括关系和名词,在传统机器人数据中没有看到的情况下,能够有效地传递。
定性评估:首先,我们使用RT-2-PaLI-X模型进行实验,以确定从视觉语言概念中传递过来的各种新兴能力。我们在图2中展示了一些这样的互动示例。通过我们的探索,我们发现RT-2在语义理解和基本推理方面继承了新的能力,这些能力是在场景上下文中得以实现的。例如,完成“将草莓放入正确的碗中”的任务需要对草莓和碗的理解,以及在场景上下文中进行推理,以了解草莓应该与相似的水果一起放置。对于任务“拿起即将从桌子上掉下来的包”,RT-2展示出了物理理解,以消除两个包之间的歧义,并识别出摆放不稳定的物体。在这些情景中测试的所有互动行为在机器人数据中从未见过,这指向了从视觉语言数据中传递的语义知识。
定量评估:为了量化这些新兴能力,我们选择前面评估中的前两个基线,即RT-1和VC-1,并将它们与我们的两个模型进行比较:RT-2-PaLI-X和RT-2-PaLM-E。为了减少这些实验的方差,我们使用A/B测试框架(Fisher, 1936)对所有方法进行评估,其中四个模型都在完全相同的条件下一个接一个地进行评估。
我们将RT-2的新兴能力分为三个类别,涵盖了推理和语义理解的不同方面(每个类别的示例在附录图8中显示)。第一个类别我们称之为符号理解,明确测试RT-2策略是否能够传递从视觉语言预训练中获得的语义知识,而这些知识在任何机器人数据中都不存在。该类别中的示例指令包括“将苹果移动到3”或“将可乐罐推到心脏上方”。第二个类别我们称之为推理,这展示了将底层VLM的各种推理能力应用于控制任务的能力。这些任务需要视觉推理(“将苹果移动到颜色相同的杯子上”)、数学推理(“将X移动到两加一的和附近”)以及多语言理解(“mueve la manzana al vaso verde”)。我们将最后一个类别称为人类识别任务,包括“将可乐罐移动到佩戴眼镜的人身边”等任务,以展示对人类的理解和识别。用于此评估的完整指令列表在附录F.2中详细说明。
我们在图6a中呈现了此实验的结果,所有数值结果都在附录H.2中。我们观察到,我们的VLA模型在所有类别上都显著优于基线,我们最好的RT-2-PaLI-X模型在平均成功率上超过了次佳的基线(RT-1)3倍以上。我们还注意到,虽然基于较大的PaLI-X的模型在符号理解、推理和人物识别性能上平均表现更好,但基于较小的PaLM-E的模型在涉及数学推理的任务上具有优势。我们将这一有趣的结果归因于PaLM-E中使用的不同预训练混合,这导致该模型在数学计算方面比主要依赖视觉预训练的PaLI-X更具能力。
模型表现如何随参数规模和设计细节变化?
在这个比较中,我们选择使用RT-2-PaLI-X模型,因为它在模型大小方面具有灵活性(由于PaLM-E的性质,RT-2-PaLM-E仅限于特定大小的PaLM和ViT模型)。具体来说,我们比较了两种不同的模型大小,即5B和55B,以及三种不同的训练方式:从头开始训练模型,不使用任何VLM预训练的权重;仅使用机器人动作数据对预训练模型进行微调;以及本研究中主要使用的联合微调(co-fine-tuning),其中我们同时使用原始的VLM训练数据和机器人数据来进行VLM微调。由于我们主要关注这些模型的泛化方面,因此我们从这组实验中排除了已见任务的评估。
实验的结果在图6b和附录表6中呈现。首先,我们观察到从头开始训练一个非常大的模型会导致性能非常差,即使对于5B模型也是如此。鉴于这个结果,我们决定跳过对从头开始训练更大的55B PaLI-X模型的评估。其次,我们注意到,联合微调模型(无论其大小如何)的泛化性能要优于仅使用机器人数据进行微调。我们将这归因于保留在微调部分训练中的原始数据,使得模型不会忘记在VLM训练期间学到的先前概念。最后,不太出人意料的是,我们注意到模型的增加大小会导致更好的泛化性能。
RT2是否展现了类似其他视觉-语言模型的思维链能力?
受到LLM(语言模型)中链式思维提示方法的启发(Wei等人,2022),我们微调了一种RT-2的变体,使用PaLM-E进行了几百个梯度步骤的微调,以增加其同时利用语言和动作的能力,希望能引发更复杂的推理行为。我们扩充了数据,包括一个额外的“计划”步骤,该步骤首先用自然语言描述机器人即将采取的动作的目的,然后跟随实际的动作标记,例如“指令:我饿了。计划:挑选rxbar巧克力。动作:1 128 124 136 121 158 111 255。”这种数据增强方案在VQA数据集(视觉推理)和操作数据集(生成动作)之间起到了桥梁的作用。
我们在定性上观察到,具有链式思维推理的RT-2能够更好地执行更复杂的命令,因为它首先可以使用自然语言计划其动作。这是一个有希望的方向,为我们提供了一些初步的证据,表明将LLM或VLM用作规划器(Ahn等人,2022; Driess等人,2023)可以与单个VLA模型中的低级策略相结合。RT-2链式思维推理的模拟结果在图7中展示,附录I中也有更多相关内容。

Limitations
尽管RT-2展现出有希望的泛化特性,但这种方法还存在多个限制。首先,尽管我们展示了通过VLM的Web规模预训练可以提升对语义和视觉概念的泛化能力,但机器人并没有因为包含了这种额外的经验而获得执行新动作的能力。该模型的物理技能仍然受限于机器人数据中所见的技能分布(请参见附录G),但它学会了以新的方式应用这些技能。我们认为这是由于数据集在技能轴上的变化不足造成的。未来研究的一个令人兴奋的方向是研究如何通过新的数据收集范式(例如人类视频)获得新的技能。
其次,虽然我们展示了可以实时运行大型VLA模型,但这些模型的计算成本很高,而且在需要高频控制的情况下,实时推断可能成为一个主要瓶颈。未来研究的一个激动人心的方向是探索量化和蒸馏技术,可能使这些模型能够以更高的速率运行或在更低成本的硬件上运行。这也与另一个当前的限制有关,即只有少数几个通常可用的VLM模型可以用来创建RT-2。我们希望会有更多的开源模型可用。
Conclusions
在本文中,我们描述了如何通过将视觉语言模型(VLM)的预训练与机器人数据相结合来训练视觉-语言-动作(VLA)模型。然后,我们介绍了基于PaLM-E和PaLI-X的两种VLA实例,分别称为RT-2-PaLM-E和RT-2-PaLI-X。这些模型通过机器人轨迹数据进行协同微调,以输出机器人动作,这些动作以文本令牌的形式表示。我们展示了我们的方法导致了非常出色的机器人策略,并且更重要的是,它在泛化性能和从Web规模视觉语言预训练中继承的新能力方面表现出显著优势。我们相信,这种简单而通用的方法展示了机器人学习可以直接从更好的视觉语言模型中受益,从而使机器人学习领域在其他领域的进步中处于战略地位,进一步得到改进。
Appendix
数据集
本工作中使用的视觉-语言数据集基于Chen等人(2023b)和Driess等人(2023)的数据集混合物。这些数据集组合了各种来源,包括WebLI数据集,其中包含大约10亿对跨109种语言的图像-文本对。WebLI数据集经过筛选,包括排名前10%的跨模态相似性示例,从而获得约10亿个训练示例。此外,还包括其他字幕和视觉问答数据集。关于数据集混合物的更详细信息可以在Chen等人(2023b)的RT-2-PaLI-X部分和Driess等人(2023)的RT-2-PaLM-E部分找到。值得注意的是,在对RT-2-PaLI-X进行协同微调时,不使用Chen等人(2023a)中描述的Episodic WebLI数据集。
本工作中使用的机器人数据集基于Brohan等人(2022)的数据集。该数据集包括使用移动操纵机器人收集的演示情节。每个演示都与自然语言指令相关联,对应于七种技能之一,如“Pick Object”、“Move Object Near Object”、“Place Object Upright”、“Knock Object Over”、“Open Drawer”、“Close Drawer”、“Place Object into Receptacle”和“Pick Object from Receptacle and place on the counter”。有关机器人数据集的更详细信息,可以参考Brohan等人(2022)。
在对RT-2-PaLI-X进行协同微调时,机器人数据集的权重约占训练混合物的50%,而RT-2-PaLM-E将机器人数据集的权重设置为训练混合物的约66%。
关于Language-Table基准相关的结果,该模型是在Lynch等人(2022)的Language-Table数据集上进行训练的。该模型在各种预测任务上进行了协同微调,包括(1)在给定连续图像帧和文本指令的情况下预测动作,(2)预测在给定图像帧中的指令,(3)在给定图像帧中预测机器人臂位置,(4)在给定图像帧之间预测时间步数,(5)在给定图像帧和指令的情况下预测任务能否成功。
测试基准
我们将我们的方法与多个挑战我们方法不同方面的最先进基线进行了比较,所有这些基线都使用了完全相同的机器人数据。
- RT-1:Robotics Transformer 1(Brohan等,2022)是一种基于Transformer的模型,在类似的任务套件上取得了最先进的性能。该模型不使用基于VLM的预训练,因此它提供了一个重要的数据点,用于证明基于VLM的预训练是否重要。
- VC-1:VC-1(Majumdar等,2023a)是一种视觉基础模型,使用专门针对机器人任务设计的预训练视觉表示。我们使用VC-1 ViT-L模型的预训练表示。由于VC-1不包括语言条件,我们通过将语言命令单独嵌入到通用句子编码器(Universal Sentence Encoder,Cer等,2018)中,从而使其能够与我们的方法进行比较。特别地,我们将生成的语言嵌入标记与VC-1生成的图像标记连接起来,然后通过标记学习器(token learner,Ryoo等,2021)传递连接的标记序列。标记学习器产生的标记序列然后被RT-1的解码器部分使用,以预测机器人动作标记。我们在训练过程中对VC-1基线进行端到端训练,并在训练过程中解冻VC-1的权重,因为这比使用冻结的VC-1权重效果要好得多。
- R3M:R3M(Nair等,2022b)是与VC-1类似的方法,R3M使用预训练的视觉-语言表示来改进策略训练。在这种情况下,作者使用Ego4D数据集(Grauman等,2022)的人类活动数据来学习表示,并将该表示用于策略。VC-1和R3M都测试了不同的最先进表示学习方法,作为使用VLM的替代方法。为了从R3M预训练表示中获得语言条件策略,我们按照上述VC-1的描述进行相同的步骤,只是我们使用R3M ResNet50模型来获得图像标记,并在训练过程中解冻它。
- MOO:MOO(Stone等,2023)是一种以物体为中心的方法,首先使用VLM来指定原始图像中感兴趣的物体,形式是一个单独的、彩色的像素。然后,将修改后的图像与端到端策略一起训练,以完成一组操作任务。这个基线对应于使用VLM作为单独的模块来增强感知,但其表示不用于策略学习。
RT2用到的视觉-语言模型
PaLI-X模型的架构包括一个ViT-22B(Dehghani等,2023)用于处理图像,它可以接受n个图像序列,每个图像有n×k个标记,其中푘是每个图像中的分块数量。图像标记通过投影层后,由一个32B参数和50层的编码器-解码器骨干网络(类似于UL2,Tay等,2023)来处理,这个网络以嵌入形式联合处理文本和图像,以自回归方式生成输出标记。文本输入通常包括任务类型和任何额外的上下文(例如,用于描述字幕任务的"Generate caption in hlangi",或用于VQA任务的"Answer in lang: question for VQA tasks")。
在表格1中训练的PaLI-3B模型使用较小的ViT-G/14(Zhai等,2022)(2B参数)来处理图像,以及UL2-3B(Tay等,2023)用于encoder-decoder网络。
PaLM-E模型基于一个仅解码的LLM,将机器人数据(例如图像和文本)投影到语言标记空间,并输出文本,如高级计划。在使用的PaLM-E-12B模型中,将图像投影到语言嵌入空间的视觉模型是ViT-4B(Chen等,2023b)。将连续变量与文本输入串联起来,使得PaLM-E可以完全多模态地接受各种输入,如多种传感器模态、以物体为中心的表示、场景表示和物体实体引用。
训练细节
我们对来自PaLI-X(Chen等,2023a)5B和55B模型、PaLI(Chen等,2023b)3B模型以及PaLM-E(Driess等,2023)12B模型的预训练模型进行协同微调。对于RT-2-PaLI-X-55B,我们使用学习率1e-3和批量大小2048,在80K个梯度步骤内进行协同微调。对于RT-2-PaLI-X-5B,我们使用相同的学习率和批量大小,在270K个梯度步骤内进行协同微调。对于RT-2-PaLM-E-12B,我们使用学习率4e-4和批量大小512,在100万个梯度步骤内进行协同微调。这两个模型都是使用下一个标记预测目标进行训练,这对应于机器人学习中的行为克隆损失。对于在表格1中用于Language-Table结果的RT-2-PaLI-3B模型,我们使用学习率1e-3和批量大小128,在300K个梯度步骤内进行协同微调。
这篇关于RT-2(robotics-transformer2)论文翻译——2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

