本文主要是介绍【EMR】HBase替换现有底层存储hdfs为oss,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
HBase on OSS架构优势如下:
-
简化了数据迁移和恢复
HBase的数据文件和表的元数据持久存储在集群外部的OSS上,HBase数据迁移和恢复时无需再使用快照等复杂的方式。
-
方便扩容
- 目前基于
Core Node扩容HBase计算时会同步扩容HDFS,但是本文中的HDFS集群本身只用于存储WAL(Write Ahead Log),需要的存储空间较少,所以实际是能够通过计算需求而非存储需求来调整EMR集群大小,同时OSS作为云存储服务,扩容操作也比较简单。
与其说是Hbase替换现有底层存储hdfs为oss,不如说是hbase替换底层存储hdfs为oss-hdfs。
环境准备:
- 目前基于
-
EMR 5.6.0大数据集群(正常运行) -
oss服务环境(正常运行)
组件hbaseosszookeeperhdfs
操作步骤
具体的操作分为以下几个步骤:
- 联系主账号管理员,并确认
oss开通了hdfs的服务,开通方式请参考:开通并授权访问OSS-HDFS服务
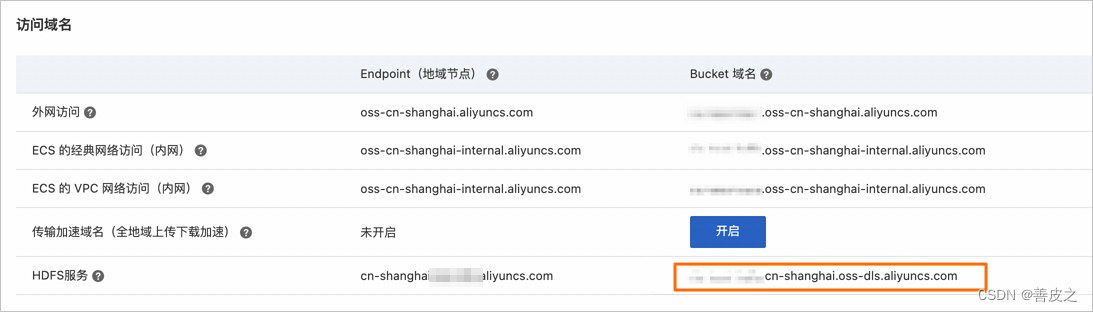
此时应该获取得到形如红框内的
oss-hdfs地址,可以通过命令hdfs -ls ${oss-hdfs_path}来验证一下这个地址是否可用。
2. 停止hbase服务:
登录阿里云的控制台,找到emr的服务,点击进入集群服务找到hbase服务,点击停止。
3. 迁移hbase数据:
停止了hbase之后,将hbase的数据目录迁移到oss-hdfs上。迁移的方式: 从HDFS迁移数据到OSS 。
如果数据量不多的话,那就像我这样做吧:将
hbase的数据从hdfs下载到本地,使用命令:hdfs fs -get /hbase ./
将本地的hbase的目录上传到oss-hdfs,使用命令hdfs fs -put ./ oss://${oss-hdfs_path}- 配置hbase:
主要修改两个配置:hbase.rootdir和hbase.wal.dir
hbase.rootdir:
HBase数据存储目录,配置为OSS路径,配置格式为oss://${oss_bucket}.${endpoint}/${hbase-root-dir}。例如,oss://test_bucket.cn-shanghai.oss-dls.aliyuncs.com/hbase
说明 其中,需要替换的参数:- ${oss_bucket}:您在OSS控制台上创建的Bucket名称。
- ${endpoint}:您在步骤2中获取到的HDFS服务域名。
- ${hbase-root-dir}:HBase的根目录。
hbase.wal.dir:
hdfs://${namespace}/${hbase-wal-dir}
配置一个hdfs的路径,例如:hdfs://emr-header-1:9000/hbase/wal_log
依据第3点的描述,将hbase的路径进行配置。配置完成之后,需要点击一下部署客户端配置。将修改好的配置同步更新到各个节点上去。-
删除
zookeeper的hbase旧的元数据目录
登陆对应集群的gateway节点或者集群中的zookeeper的client端。使用命令zkCli.sh进到zookeeper的控制台。使用命令deleteall /hbase删除hbase在zookeeper中的元数据。 -
启动
hbase
在aliyun的EMR控制台中,找到hbase的服务,点击启动即可。 -
hbase的校验
等待hbase启动完毕之后,需要校验一下hbase的读写功能是否正常。
总结:
整体步骤如上所述,亲测ok!
参考文档:
- 使用OSS作为HBase的底层存储 - 开源大数据平台E-MapReduce - 阿里云
这篇关于【EMR】HBase替换现有底层存储hdfs为oss的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






