本文主要是介绍3、k8s工作负载-replicaset详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
k8s工作负载-replicaset详解
- K8S 工作负载架构
- ReplicaSet
- ReplicaSet 的工作原理
- 何时使用 ReplicaSet
- RC/RS控制器
- 示例
- 删除rs
- 自愈能力
- 扩容能力
K8S 工作负载架构

从图中可以知道POD是k8s中最下的单位,ReplicaSet简称rs,是用于自动化部署使用,它是对pod自动化部署的定义,而deployment是对rs的更上一层抽象,也就是deployment是管理rs,而rs是管理pod的,rc的功能和rs差不多,现在基本上已经不使用了。
Pod: smallest K8s compute resource containing 1…containers
Pod:最小的K8s计算资源,包含1…个容器
init container: container executing startup tasks, like e.g.database migration
init container:执行启动任务的容器,例如数据库迁移
container: container with main or sidecar application
容器:主要或侧车应用的容器
Horizontal Pod autoscaler: scales the number of Pods based on various metrics
Horizontal Pod autoscaler:根据各种度量标准缩放Pod的数量
ReplicationController: predecessor of deployment, don’t use it anymore
ReplicationController:部署的前身,不要再使用它了
StatefulSet: creates Pods while handling the needs of stateful applications
StatefulSet:在处理有状态应用程序的需求时创建pod
Deployment: creates a ReplicaSet and takes care of rollouts and rollbacks
部署:创建复制集并负责卷展和回滚
ReplicaSet: creates the desired amount of Pod instances
ReplicaSet:创建所需数量的Pod实例
CronJob: creates Jobs based on a time schedule
CronJob:根据时间表创建作业
Job: creates short living Pods for one time executions
工作:为一次性执行创建短期生存Pods
DaemonSet: creates exactly one Pod per Node
守护程序集:每个节点只创建一个Pod
ReplicaSet
ReplicaSet 的工作原理
RepicaSet 是通过一组字段来定义的,包括一个用来识别可获得的 Pod 的集合的选择算符、一个用来标明应该维护的副本个数的数值、一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板等等。 每个 ReplicaSet 都通过根据需要创建和 删除 Pod 以使得副本个数达到期望值, 进而实现其存在价值。当 ReplicaSet 需要创建新的 Pod 时,会使用所提供的 Pod 模板。
ReplicaSet 通过 Pod 上的 metadata.ownerReferences 字段连接到附属 Pod,该字段给出当前对象的属主资源。 ReplicaSet 所获得的 Pod 都在其 ownerReferences 字段中包含了属主 ReplicaSet 的标识信息。正是通过这一连接,ReplicaSet 知道它所维护的 Pod 集合的状态, 并据此计划其操作行为。
ReplicaSet 使用其选择算符来辨识要获得的 Pod 集合。如果某个 Pod 没有 OwnerReference 或者其 OwnerReference 不是一个 控制器,且其匹配到 某 ReplicaSet 的选择算符,则该 Pod 立即被此 ReplicaSet 获得。
何时使用 ReplicaSet
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。 然而,Deployment 是一个更高级的概念,它管理 ReplicaSet,并向 Pod 提供声明式的更新以及许多其他有用的功能。 因此,我们建议使用 Deployment 而不是直接使用 ReplicaSet,除非 你需要自定义更新业务流程或根本不需要更新。
这实际上意味着,你可能永远不需要操作 ReplicaSet 对象:而是使用 Deployment,并在 spec 部分定义你的应用
RC/RS控制器
控制 Pod,使 Pod 拥有自愈,多副本,扩缩容的能力
RC 的定义包括如下几个部分:
(1) Pod 期待的副本数(replicas)
(2)用于筛选目标 Pod 的 Label Selector
(3)当 Pod 的副本数量小于预期数量时,用于创建新 Pod 的 Pod 模板(template)
示例
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: frontendlabels:app: guestbooktier: nginx-rs
spec:# modify replicas according to your casereplicas: 3selector:matchLabels:tier: nginx-tttemplate:metadata:labels:tier: nginx-ttspec:containers:- name: nginx-rsimage: nginx:1.9
metadata.labels:表示得是RS中得label,定义了rs中得label,就是rs特有得label;
spec.selector.matchLabels:这个是RS选择pod容器得label,对应到下面得pod定义得label,要一样,否则是找不到对应得pod得,当然不同得pod最好不要将label设置为一样得。
spec.template.metadata.lables:这个是定义模板得容器标签,这个标签要和spec.selector.matchLabels对应上
spec.replicas:表示这个容器要启动多少个pod副本,这里设置的3个
我们把上面得yaml应用过后,查看结果:
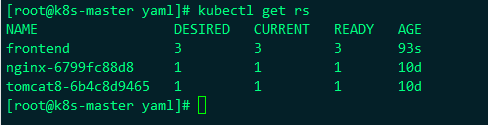
列表中frontend就是刚刚应用的yaml,我们设置了3个副本,所以
DESIRED:表示期望的副本是3个
CURRENT:表示当前为3个
READY:表示准备好的有3个
我们查看容器的详细信息如下:
 上面的selector中的tier=nginx-tt就是yaml中定义的label选择器对应到下面的Containers中的pod 模板template中的label 是tier=nginx-tt,而labels中定义的两个label
上面的selector中的tier=nginx-tt就是yaml中定义的label选择器对应到下面的Containers中的pod 模板template中的label 是tier=nginx-tt,而labels中定义的两个label
tier=nginx-rs
app=guestbook
是rs中定义的两个label
我们通过刚刚定义的rs的label来筛选出rs
kubectl get rs -l tier=nginx-rs

我们刚刚还定义了pod的三个副本label都是nginx-tt,我们筛选一下:
kubectl get pod -l tier=nginx-tt

删除rs
kubectl delete rs frontend
自愈能力
我们这里删除rs中的pod
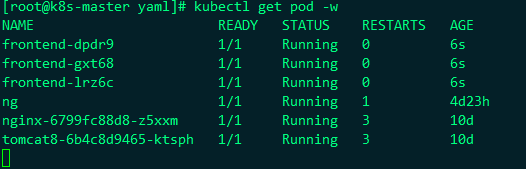
我们这里删除第一个frontend-dpdr9 pod容器观察下变化
kubectl delete pod frontend-dpdr9
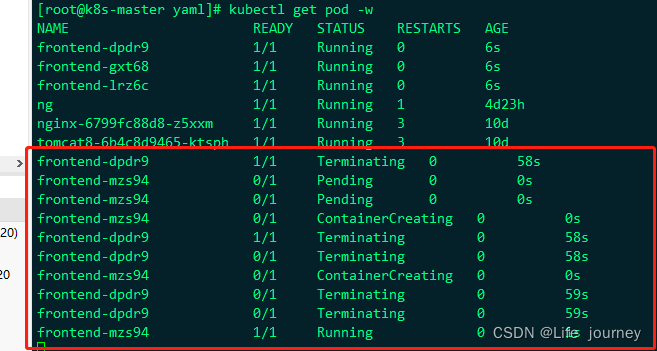
可以看到我们删除了rs中的pod以后,rs有自愈功能,会自动再重启一个pod来完成自愈功能,在实际的场景中,经常会有pod挂掉,而rs会自动自愈,在另外的地方或者本节点自动启动一个pod来完成自愈
扩容能力
kubectl scale --replicas=5 rs frontend
自动扩容到5个了
还可以进行缩容,缩容到3个
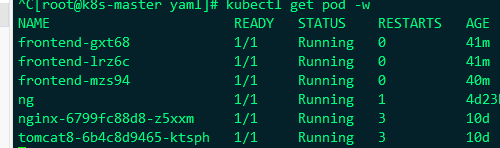
变成了3个了,还可以进行自动伸缩,通过命令:
kubectl autoscale rs frontend --max=10 --min=3 --cpu-percent=50
最大10个,最小3个,cpu的百分比是50
这篇关于3、k8s工作负载-replicaset详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






