本文主要是介绍通过关键词爬取人民网新闻入库并实现url去重,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
今天的任务是通过关键词爬取人民网的新闻,并存入数据库,同时实现url去重效果。
所需模块
requests
selenium
lxml
re
pymysql
redis
数据库创建
由于数据要存入数据库,同时还要实现去重效果,我们需要用到mysql和redis数据库
- 明确所需要提取的信息
我们首先创建一个mysql数据库
create database news_db;
然后创建一个存新闻简介的表
表包含以下属性:
id:主键
title:标题
url:新闻详情url
update_time:发布时间
create table brief_news(id int primary key auto_increment,title varchar(70),url varchar(100),update_time datetime);
再创建一个存放新闻详细内容的表
表包含以下属性:
news_id:外键
content:新闻内容
create table detail_news(news_id int not null,content text,foreign key (news_id) references brief_news(id));
网页分析
通过selenium我们可以拿到网页渲染的html,通过xpath提取每条新闻的url,标题,通过正则提取新闻时间
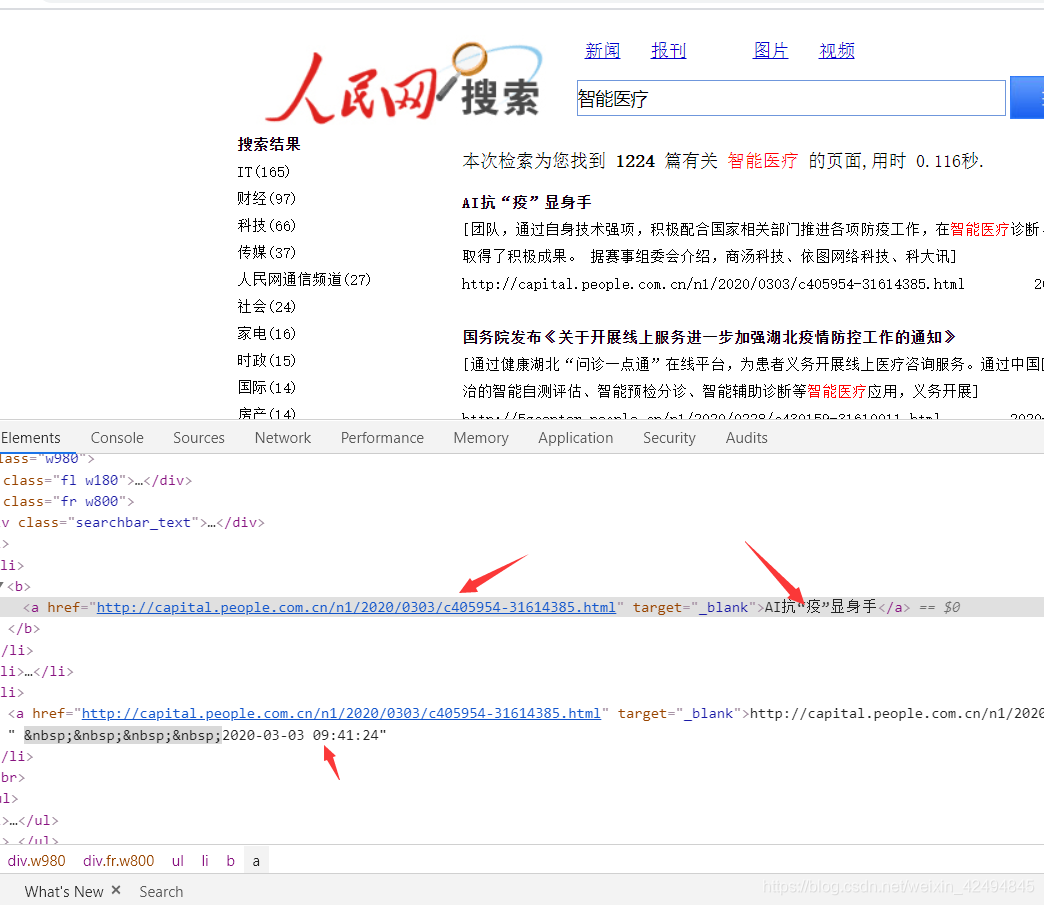
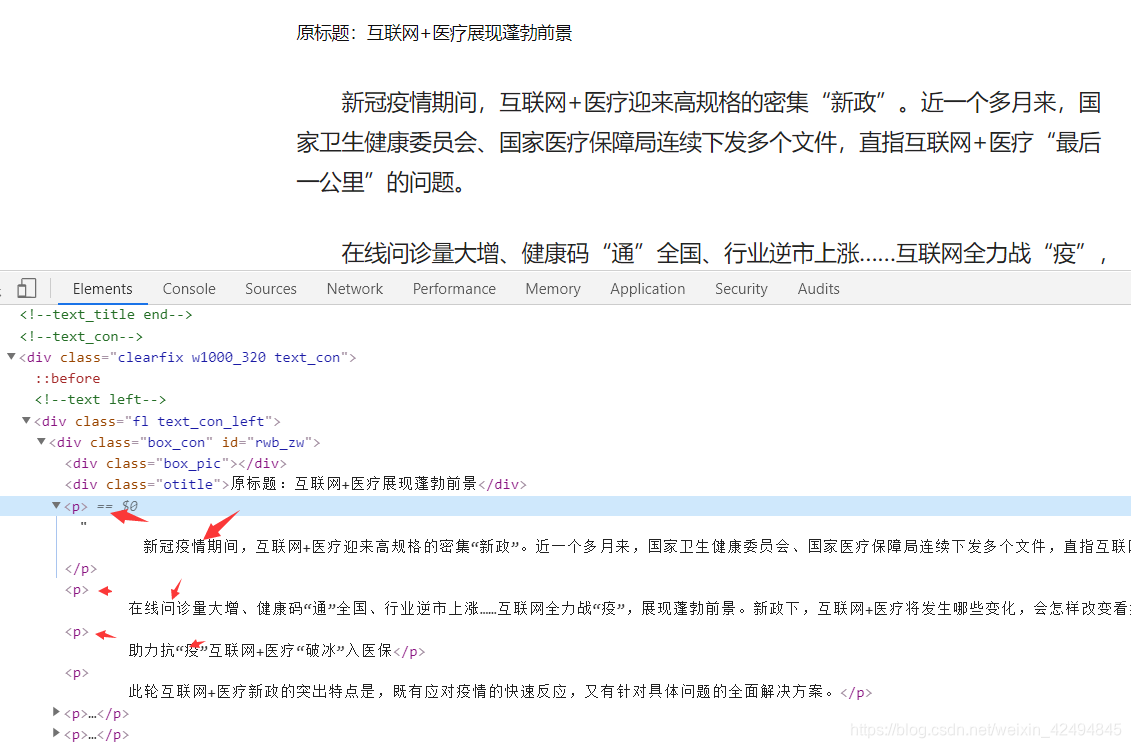
分析几个新闻详情页,发现新闻的主体内容都在p标签下。
程序分模块讲解
导入所需要的库
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ChromeOptions
import requests
from lxml.html import etree
import re
import pymysql
import redis
import hashlib
#以下两行用于忽略requests证书警告
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
Redis类和Hashencode类
用于对url进行hash编码和去重,这里就不详细讲了,之前已经写过一篇利用Redis去重的博客,这里也就是照着搬过来用。
class Redis():def __init__(self,host):self.con = redis.Redis(host=host, #ip地址port=6379, #端口号,默认为6379db=1,decode_responses=True #设置为True返回的数据格式就是时str类型)def add(self,key,data):self.con.sadd(key,data) #添加def query(self,key):return self.con.smembers(key) #拿出key对应所有值def delete(self,key):self.con.delete(key) #删除key键def exits(self,key,data):return self.con.sismember(key, data) # 判断key里是否有data,有则返回trueclass Hashencode():def __init__(self):self.encode_machine = hashlib.md5() # 创建一个md5对象def encode(self,url):self.encode_machine.update(url.encode()) #更新url_encode = self.encode_machine.hexdigest() #拿到编码后的十六进制数据return url_encode请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ""(KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36",'accept-language': 'zh-CN,zh;q=0.9','cache-control': 'max-age=0','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8'
}
MySpider类
用于配置mysql服务和实现将去重后的内容存入mysql两张表中
class MySpider():def __init__(self,host,user,password,db):# 配置信息db_config = {'host': host, # 需要连接ip'port': 3306, # 默认端口3306'user': user, # 用户名.'password': password, # 用户密码'db': db, # 进入的数据库名.'charset': 'utf8' # 编码方式.}self.options = ChromeOptions()# 添加无界面参数self.options.add_argument('--headless')self.driver = Chrome(options=self.options)self.conn = pymysql.connect(**db_config)# 得到一个可执行SQL语句的光标对象self.cur = self.conn.cursor() # create cursor.#实例化Hashencode和Redis对象self.en = Hashencode()self.red = Redis(host)#获取新闻详情页内容def get_content(self,news_url,title):"""获取新闻详情页内容并入库:param news_url: 新闻详情页url:param title: 新闻标题:return: """text = requests.get(news_url, headers=headers, verify=False)text.encoding = 'gb2312'html = etree.HTML(text.text)content = html.xpath("//p")news_detail = ''"""这里的这些if判断是为了过滤掉一些无用的信息因为每个新闻的网页结构不同,所有没有办法完全精确地匹配这里的过滤方法是经过测试后效果最好的。"""for i in content:sentence = i.xpath("string()")if len(sentence) == 0:continueif sentence == '\n':continueif sentence.count('\t') + sentence.count('\n') + sentence.count(' ') > 7:continueif '\u4e00' <= sentence[0] <= '\u9fff' or sentence[0].isdigit() or sentence[0].isalpha():continuenews_detail += sentence#获取主键IDself.cur.execute('SELECT id FROM brief_news WHERE title="{}";'.format(title))resp = self.cur.fetchall()news_id = resp[0][0]#入库self.cur.execute('INSERT INTO detail_news VALUES ("{}","{}");'.format(news_id,news_detail))self.conn.commit()#通过关键词,获取新闻标题,url,发布时间def get_urls(self,keyword):"""通过关键词搜索新闻并提取新闻标题,url,发布时间:param keyword: 关键词:return: """self.driver.get("http://search.people.com.cn/cnpeople/news/")self.driver.find_element_by_id("keyword").send_keys(keyword)self.driver.find_element_by_id("keyword").send_keys(Keys.ENTER)search_result = self.driver.page_sourcehtml = etree.HTML(search_result)news_urls = html.xpath('//div[@class="fr w800"]/ul/li/b/a/@href')news_titles = html.xpath('//div[@class="fr w800"]/ul/li/b/a/text()')update_times = re.findall("\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}",search_result)for i,j,k in zip(news_urls,news_titles,update_times):str_i = i.encode('utf-8').decode()str_j = j.encode('utf-8').decode()encode_i = self.en.encode(str_i)if self.red.exits("urls",encode_i):continueself.red.add("urls",encode_i)self.cur.execute('INSERT INTO brief_news VALUES(null,"{}","{}","{}");'.format(str_j,str_i,k))self.conn.commit()self.get_content(i,j)# next_page = self.driver.find_element_by_link_text("下一页").click()def __del__(self):self.cur.close()self.conn.close()self.driver.close()
这个类实现了通过关键词搜索新闻,并把第一页新闻的标题,url,发布时间存入第一张表,将新闻内容存入第二张表中,同时实现了url去重,不会存入同样的数据。
关于提取第二页的内容,读者只需要加一个循环即可实现。
这个类在实例化时需要传入mysql主机地址,用户名,密码和需要连接的数据库名,运行时需要插入的两个表存在,上文已经给出了创建的命令。
今天的分享就到这儿了,希望大家能够有所收获。
这篇关于通过关键词爬取人民网新闻入库并实现url去重的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





