本文主要是介绍PostgreSQL 进阶 - 模式匹配,过滤敏感数据,数据清理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 模式匹配
SELECT phone_number FROM customers;
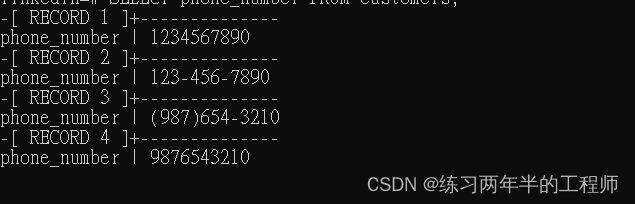
使用正则表达式替换所有非数字字符
这样可以清理和标准化电话号码数据,去除任何非数字字符,只保留数字
UPDATE customers
SET phone_number =
REGEXP_REPLACE(phone_number, '[^0-9]', '', 'g')
WHERE phone_number ~ '[^0-9]';
- 使用正则表达式 [^0-9] 匹配任何非数字字符,并将其替换为空字符串 ‘’。‘g’ 表示全局替换,即所有匹配的地方都会被替换。
- phone_number ~ ‘[^0-9]’:这是一个正则表达式匹配条件,它匹配 phone_number 列中包含任何非数字字符的值。
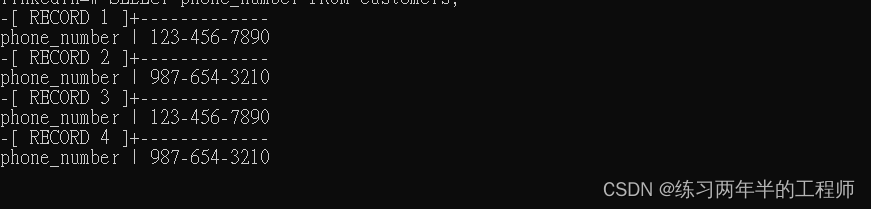
SELECT phone_number FROM customers;
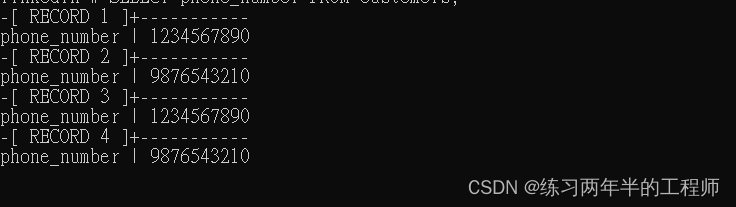
使用正则表达式匹配包含 10 个数字字符的电话号码,并将其格式化为 xxx-xxx-xxxx 的形式
UPDATE customers
SET phone_number =
REGEXP_REPLACE(phone_number, '([0-9]{3})([0-9]{3})([0-9]{4})',
'\1-\2-\3')
WHERE phone_number ~'^[0-9]{10}$';
- 使用正则表达式 ([0-9]{3})([0-9]{3})([0-9]{4}) 匹配电话号码的特定模式
- 使用 \1-\2-\3 替换该模式,其中 \1、\2 和 \3 是正则表达式中捕获的三组数字
- phone_number ~ ‘^[0-9]{10}$’:这是一个正则表达式匹配条件,它匹配 phone_number 列中包含且只包含 10 个数字字符的值。
2. 过滤敏感数据
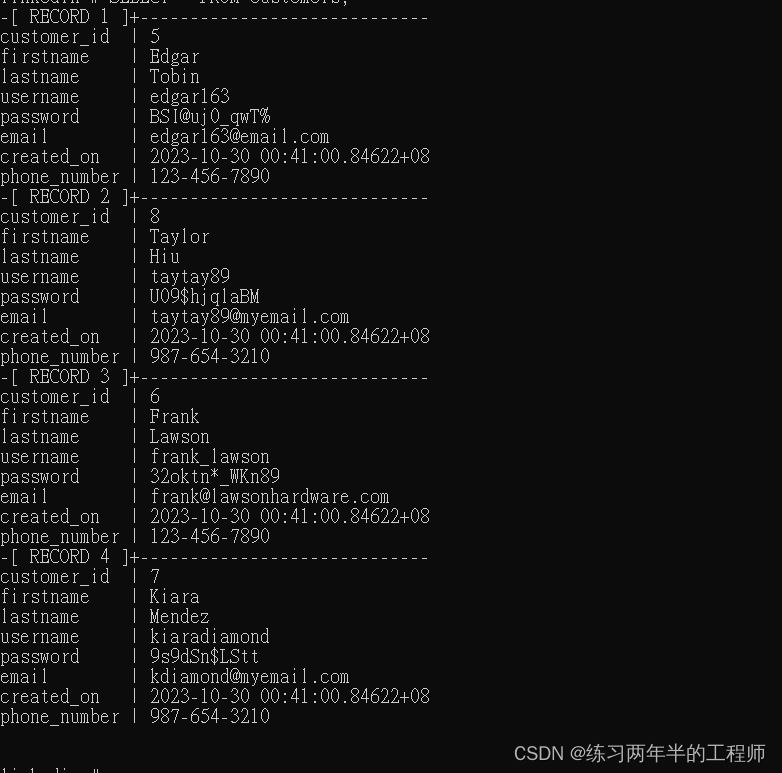
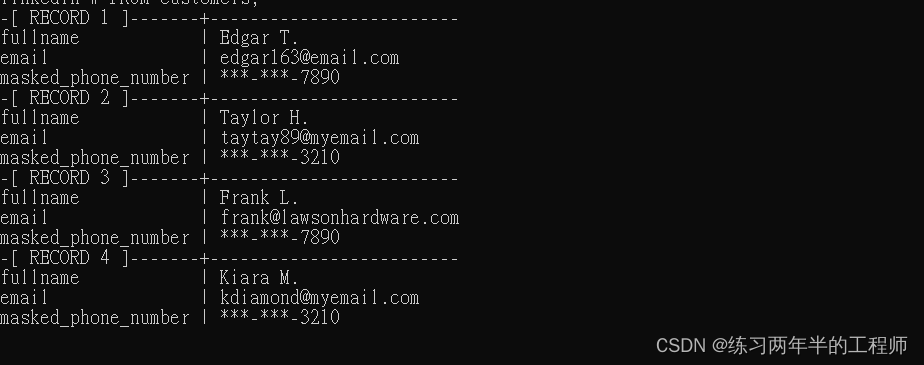
SELECT
CONCAT(firstname, ' ', UPPER(SUBSTRING(lastname, 1, 1)), '.')
AS fullname,
email,
(SELECT CONCAT('***-***-',
RIGHT(phone_number, 4)) AS masked_phone_number)
FROM customers;
- SUBSTRING() 函数用于提取 lastname 的第一个字符。第一个1 是起始位置参数,指定要提取的子字符串的起始位置。在这里,它是 lastname 字符串中的第一个字符。
第二个1 是长度参数,指定要提取的子字符串的长度。在这里,它表示只提取一个字符。 - 查询结果将以 ***-***- 开头,后跟原始 phone_number 值的最后四位数字。
3. 数据清理
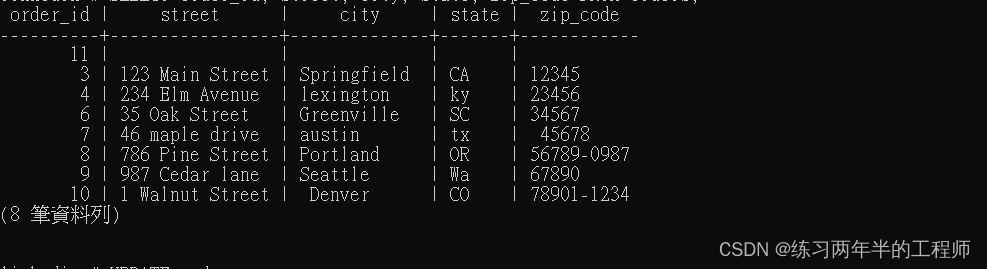
SELECT order_id, street, city, state, zip_code FROM orders;
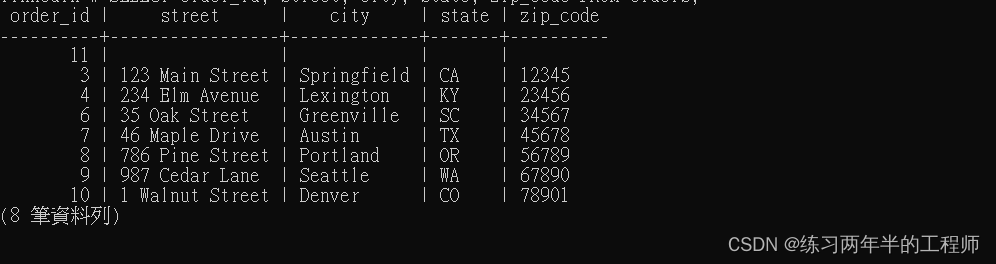
UPDATE orders
SET
street = INITCAP(TRIM(street)),
city = INITCAP(TRIM(city)),
state = UPPER(TRIM(state)),
zip_code = SUBSTRING(REGEXP_REPLACE(TRIM(zip_code), '[^0-9]', '', 'g'), 1, 5)
WHERE (
street != INITCAP(TRIM(street)) OR
city != INITCAP(TRIM(state)) OR
state != UPPER(TRIM(state)) OR
SUBSTRING(REGEXP_REPLACE(TRIM(zip_code), '[^0-9]', '', 'g'), 1, 5) != zip_code OR
LENGTH(zip_code) != 5);
- street = INITCAP(TRIM(street)),将街道名字的首字母大写,并去除首尾空格。
- 去除邮政编码中的非数字字符,并截取前5位数字作为新的邮政编码
4. 产生虚拟数据
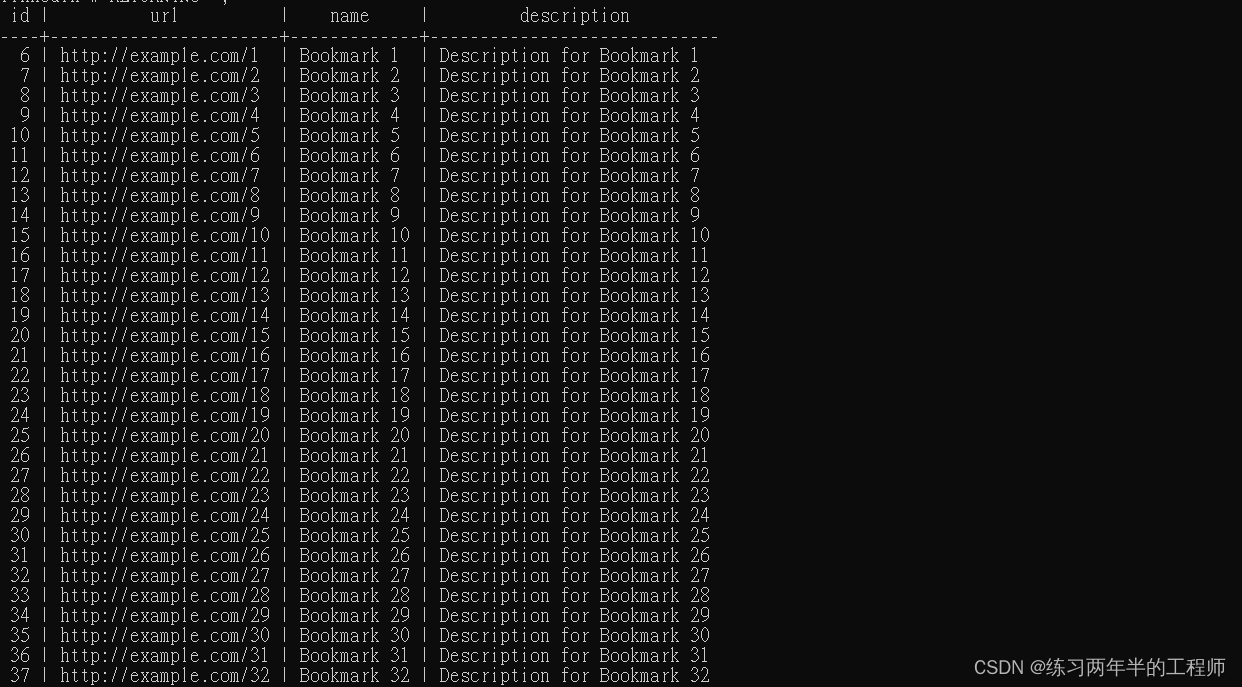
SELECT * FROM bookmarks;

INSERT INTO bookmarks (url, name, description)
SELECT 'http://example.com/' || generate_series AS url,
'Bookmark ' || generate_series AS name,
'Description for Bookmark ' || generate_series AS description FROM generate_series(1,50) AS generate_series
RETURNING *;
通过从1到50生成一系列数字,将生成的数字与预定义的字符串连接起来,并将结果分别插入“url”、“name” 和 “description” 字段。
5. 密码加密
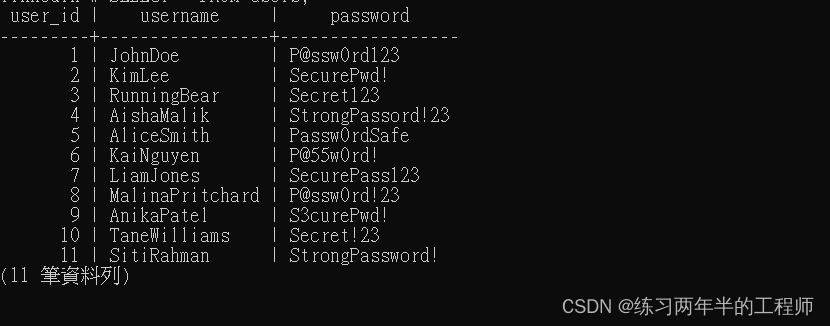
SELECT * FROM users;
ALTER TABLE users
ADD COLUMN password_hash VARCHAR(255),
ADD COLUMN password_salt VARCHAR(255);
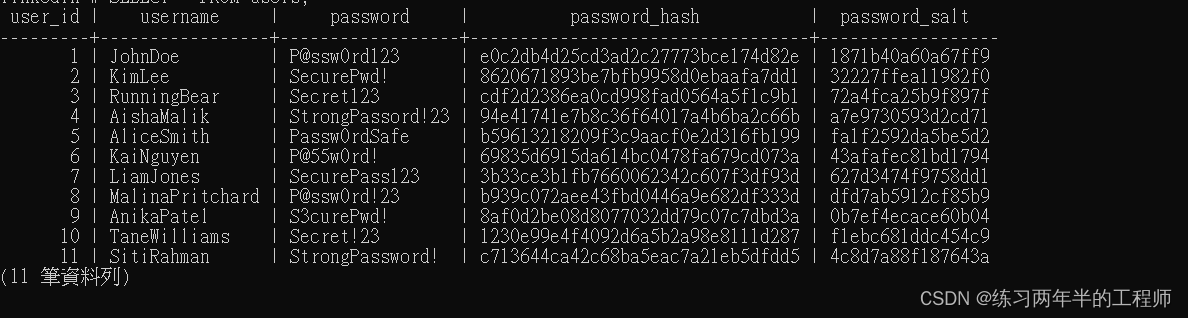
UPDATE users
SET password_salt = substr(md5(random()::text), 1, 16);
- 将“password_salt”字段设置为一个随机生成的字符串,该字符串是通过将一个随机数转换为文本格式后进行MD5加密,并截取前16位字符得到的。
UPDATE users
SET password_hash = md5(concat(password_salt, password))
WHERE password_hash IS NULL;
- 将“password_hash”字段设置为“password_salt”和“password”字段拼接后进行MD5加密得到的结果。
6. 取消正在运行的queries
SELECT pid, query, xact_start, wait_event, wait_event_type
FROM pg_stat_activity
WHERE backend_type = 'client backend'
AND wait_event IS NOT NULL;
- 从“pg_stat_activity”视图中选择特定列的数据。它选择了“pid”(进程ID)、“query”(查询语句)、“xact_start”(事务开始时间)、“wait_event”(等待事件)和“wait_event_type”(等待事件类型)列。

SELECT pg_cancel_backend(3236);
- 执行这条 SQL 语句后,具有进程 ID 为 3236 的进程将会被取消。

SELECT pid, query, xact_start, wait_event, wait_event_type
FROM pg_stat_activity
WHERE backend_type = 'client backend'
AND wait_event IS NOT NULL;

这篇关于PostgreSQL 进阶 - 模式匹配,过滤敏感数据,数据清理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








