本文主要是介绍Gale和Church的句对齐算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Gale和Church的句对齐算法
******如有问题请留言******
论文的链接地址
A Program for Aligning Sentences in Bilingual Corpora。
第一步是段落对其
第二步是在段落内部进行句对齐。
Gale和Church的句对齐算法只解析的是已知段落对齐,怎样在段落内进行句对齐。首先定义几个概念和定义的符号。
-
句子 一个短的字符串。
-
段落 语文里的自然段。分为源语言L1的段落和目标语言L2的段落,或称原文段落和译文段落。段落由一个序列的连续句子组成。
-
片段 一个序列的连续的句子,是段落的子集。对应论文中的portion of text。
-
片段对 原文片段和译文片段组成的对。
-
l1,l2分别对应片段对中原文部分和译文部分的字符总数。
-
c,s²假设源语言中的一个字符在目标语言中对应的字符数是一个随机变量,且该随机变量服从正态分布
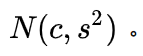
-
每个片段都有自己的
![[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imbg.csdnimg.cn/2MUo3G02012092038525494)(htps://img-log.csdnimg.cn/208120420925254.png)](https://img-blog.csdnimg.cn/20201209204937626.png)
-
对齐模式 或称匹配模式,描述一个句块对由几个原文句子和几个译文句子组成。
-
片段对序列 一个序列的片段对,这些片段对的原文部分的集合是原文段落的一个划分,译文部分的集合是译文段落的一个划分。
-
距离和 距离和是片段对序列中所有片段对的距离的和。 对齐序列 距离和最小的片段对序列。
-
match 对齐模式的概率分布。
-
距离(distance measure) 衡量片段对两个片段之间的距离。距离度量是以下公式的估计
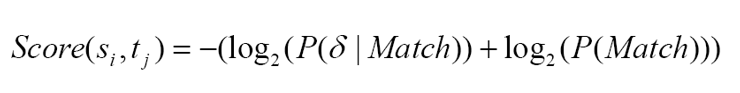
当一个片段对确定后,我们就知道它的mathc和 死哥maδ 。距离越大,此片段对对齐的概率越小。
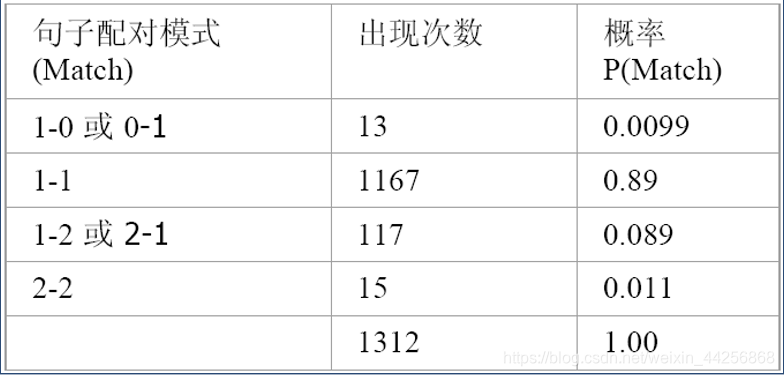
定义了六种配对模式,在实际UBS语料库的分布频度为:

D(i,j) = Score(si,tj)

本片文档的参考链接
这篇关于Gale和Church的句对齐算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








