本文主要是介绍小白爬虫学习之电影票房排名,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
学习目标:
使用正则表达式、requests等知识爬虫某网站的电影票房榜单,并用pandas、matplotlib进行绘图
1. 首先导入使用的库
import requests
import csv
import pandas as pd
import matplotlib.pyplot as plt
import warnings2. 解决符号问题
因为在爬虫的过程中,会遇到中文或特殊符号无法显示的情况,使用rcParams
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决符号无法显示3. 爬虫准备
将爬取的数据存入到cvs中,并设置cvs表格的标题
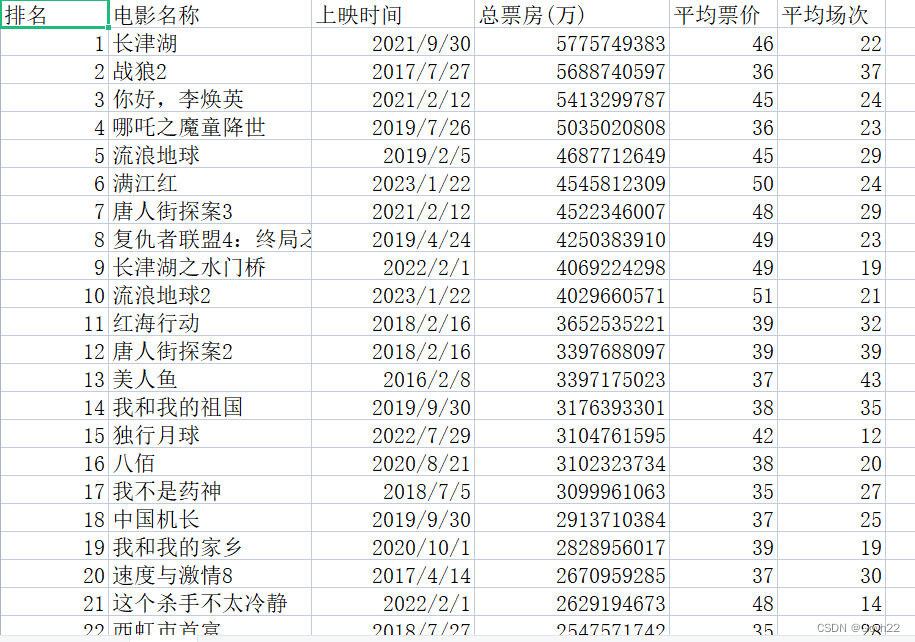
def main():headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36', }data = {'r': '0.9936776079863086','top': '50','type': '0',}resp = requests.post('https://ys.endata.cn/enlib-api/api/home/getrank_mainland.do', headers=headers, data=data)data_list = resp.json()['data']['table0']for item in data_list:rank = item['Irank'] # 排名MovieName = item['MovieName'] # 电影名称ReleaseTime = item['ReleaseTime'] # 上映时间TotalPrice = item['BoxOffice'] # 总票房(万)AvgPrice = item['AvgBoxOffice'] # 平均票价AvgAudienceCount = item['AvgAudienceCount'] # 平均场次# 写入csv文件csvwriter.writerow((rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount))print(rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount)
4. 进行爬虫
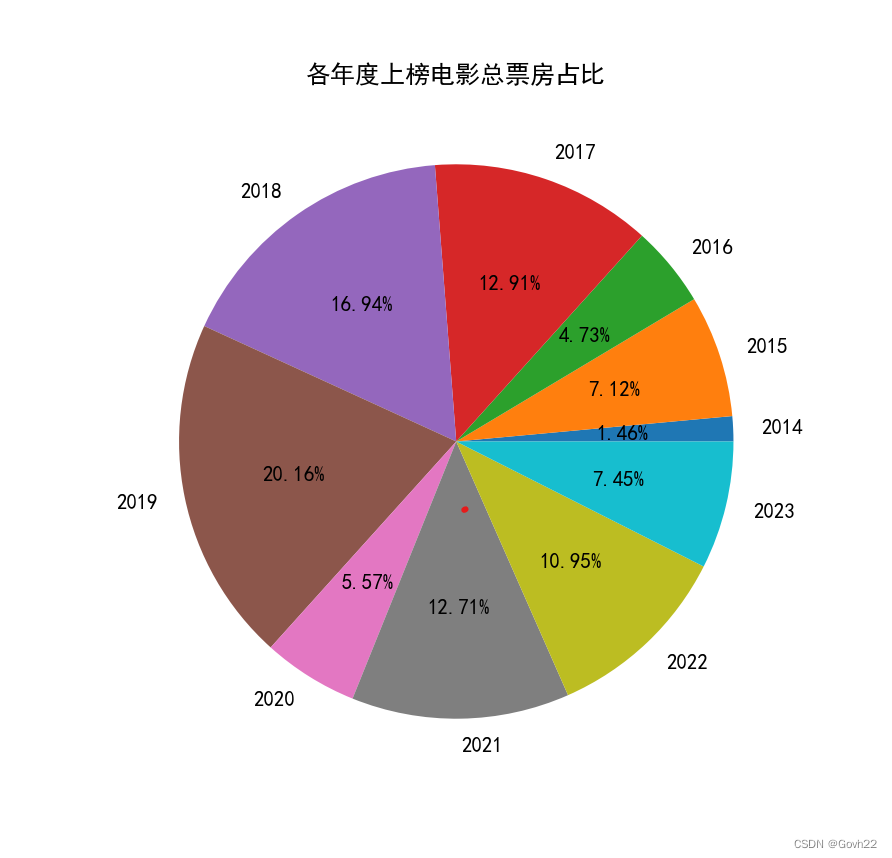
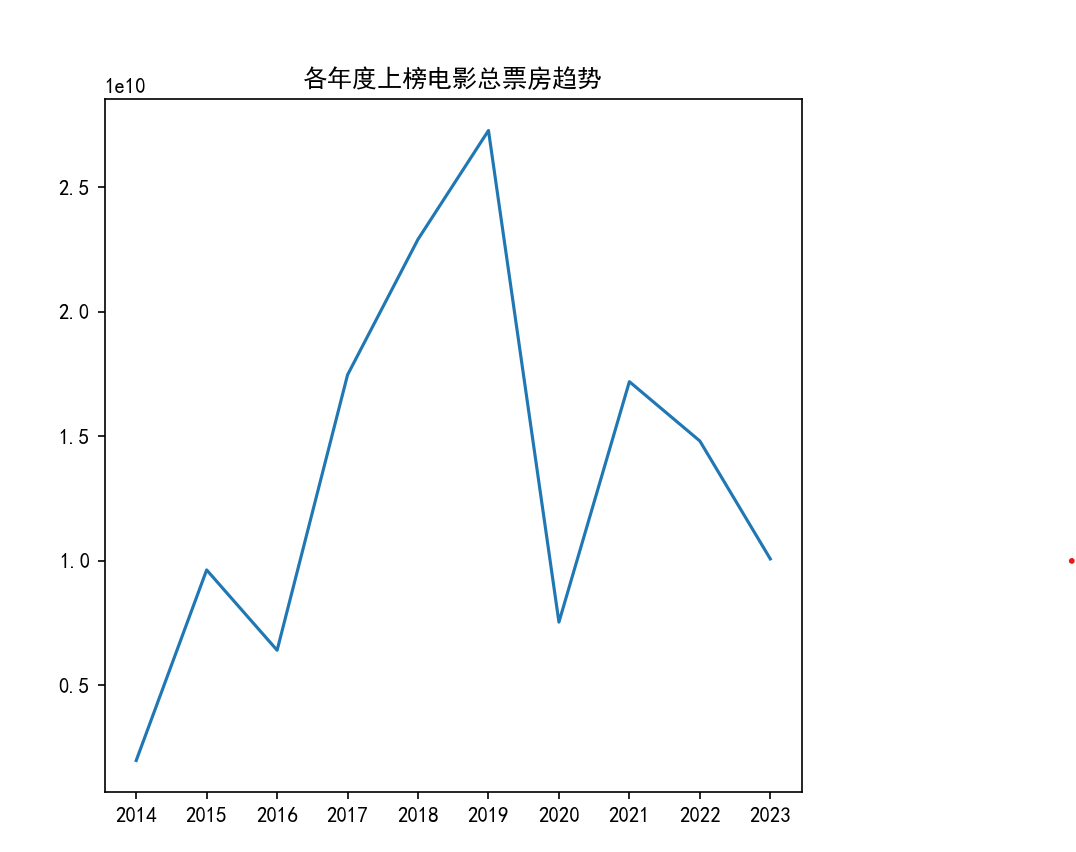
# 读取数据data = pd.read_csv('07.csv')# 从上映时间中提取出年份data['年份'] = data['上映时间'].apply(lambda x: x.split('-')[0])# 各年度上榜电影总票房占比df1 = data.groupby('年份')['总票房(万)'].sum()plt.figure(figsize=(6, 6))plt.pie(df1, labels=df1.index.to_list(), autopct='%1.2f%%')plt.title('各年度上榜电影总票房占比')plt.show()# 各个年份总票房趋势df1 = data.groupby('年份')['总票房(万)'].sum()plt.figure(figsize=(6, 6))plt.plot(df1.index.to_list(), df1.values.tolist())plt.title('各年度上榜电影总票房趋势')plt.show()# 平均票价最贵的前十名电影print(data.sort_values(by='平均票价', ascending=False)[['年份', '电影名称', '平均票价']].head(10))# 平均场次最高的前十名电影print(data.sort_values(by='平均场次', ascending=False)[['年份', '电影名称', '平均场次']].head(10))5. 运行结果
cvs中的文件内容
总票房占比
折线图
6. 完整代码
import requests
import csv
import pandas as pd
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决符号无法显示def main():headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36', }data = {'r': '0.9936776079863086','top': '50','type': '0',}resp = requests.post('https://ys.endata.cn/enlib-api/api/home/getrank_mainland.do', headers=headers, data=data)data_list = resp.json()['data']['table0']for item in data_list:rank = item['Irank'] # 排名MovieName = item['MovieName'] # 电影名称ReleaseTime = item['ReleaseTime'] # 上映时间TotalPrice = item['BoxOffice'] # 总票房(万)AvgPrice = item['AvgBoxOffice'] # 平均票价AvgAudienceCount = item['AvgAudienceCount'] # 平均场次# 写入csv文件csvwriter.writerow((rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount))print(rank, MovieName, ReleaseTime, TotalPrice, AvgPrice, AvgAudienceCount)def data_analyze():# 读取数据data = pd.read_csv('07.csv')# 从上映时间中提取出年份data['年份'] = data['上映时间'].apply(lambda x: x.split('-')[0])# 各年度上榜电影总票房占比df1 = data.groupby('年份')['总票房(万)'].sum()plt.figure(figsize=(6, 6))plt.pie(df1, labels=df1.index.to_list(), autopct='%1.2f%%')plt.title('各年度上榜电影总票房占比')plt.show()# 各个年份总票房趋势df1 = data.groupby('年份')['总票房(万)'].sum()plt.figure(figsize=(6, 6))plt.plot(df1.index.to_list(), df1.values.tolist())plt.title('各年度上榜电影总票房趋势')plt.show()# 平均票价最贵的前十名电影print(data.sort_values(by='平均票价', ascending=False)[['年份', '电影名称', '平均票价']].head(10))# 平均场次最高的前十名电影print(data.sort_values(by='平均场次', ascending=False)[['年份', '电影名称', '平均场次']].head(10))if __name__ == '__main__':# 创建保存数据的csv文件with open('07.csv', 'w', encoding='utf-8', newline='') as f:csvwriter = csv.writer(f)# 添加文件表头csvwriter.writerow(('排名', '电影名称', '上映时间', '总票房(万)', '平均票价', '平均场次'))main()# 数据分析data_analyze()7. 本次学习总结
在本次的学习中,使用了requests进行网络爬虫,并使用画图工具绘制了饼状图和折线图,对之前学过的知识也有了进一步的巩固。
这篇关于小白爬虫学习之电影票房排名的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








