本文主要是介绍Redis深度历险-Redis字典源码内部结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文大部分内容引自《Redis深度历险:核心原理和应用实践》,感谢作者!!!
Redis字典的用途
Redis中 hash结构的数据会使用到字典,整个Redis数据库中所有的key和value也组成了一个全局字典,带过期时间的key集合也是一个字典。zset集合中存储value和score值的映射关系也是通过dict结构实现的
struct RedisDb {dict* dict; // all keys key=>valuedict* expires; // all expired keys key=>long(timestamp)...
}struct zset {dict *dict; //all values value => scorezskiplist *zsl;
}dict内部结构
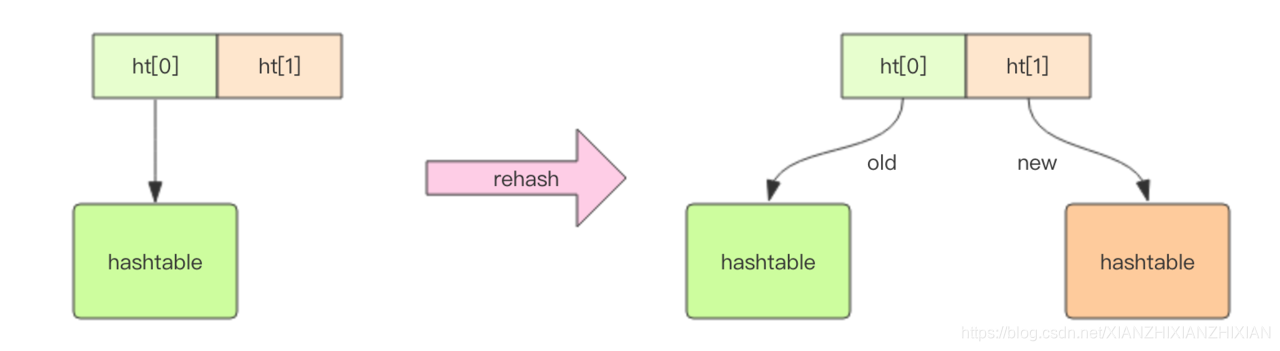
dict内部有两个hashtable,通常情况下只有一个hashtable是有值的;在dict扩容或者缩容时需要分配新的hashtable,然后进行渐进式rehash,两个hashtable种存储的分别是新值和旧值;在rehash完成之后,旧的hashtable被删除,新的hashtable会取代旧的hashtable
struct dict {dictType *type; //类型特定函数void *privdata; //私有数据dictht ht[2]; //2个哈希表,哈希表负载过高进行rehash的时候才会用到第2个哈希表int rehashidx; //rehash目前进度,当哈希表进行rehash的时候用到,其他情况下为-1
}
struct dictEntry {void *key;union {void *val;uint64_t u64; //uint64_t整数int64_t s64; //int64_t整数}v;struct dictEntry *next; //指向下个哈希表节点
}
struct dictht {dictEntry **table; //哈希表数组unsigned long size; //哈希表大小,即哈希表数组大小unsigned long sizemask; //哈希表大小掩码,总是等于size-1,主要用于计算索引unsigned long used; //已使用节点数,即已使用键值对数
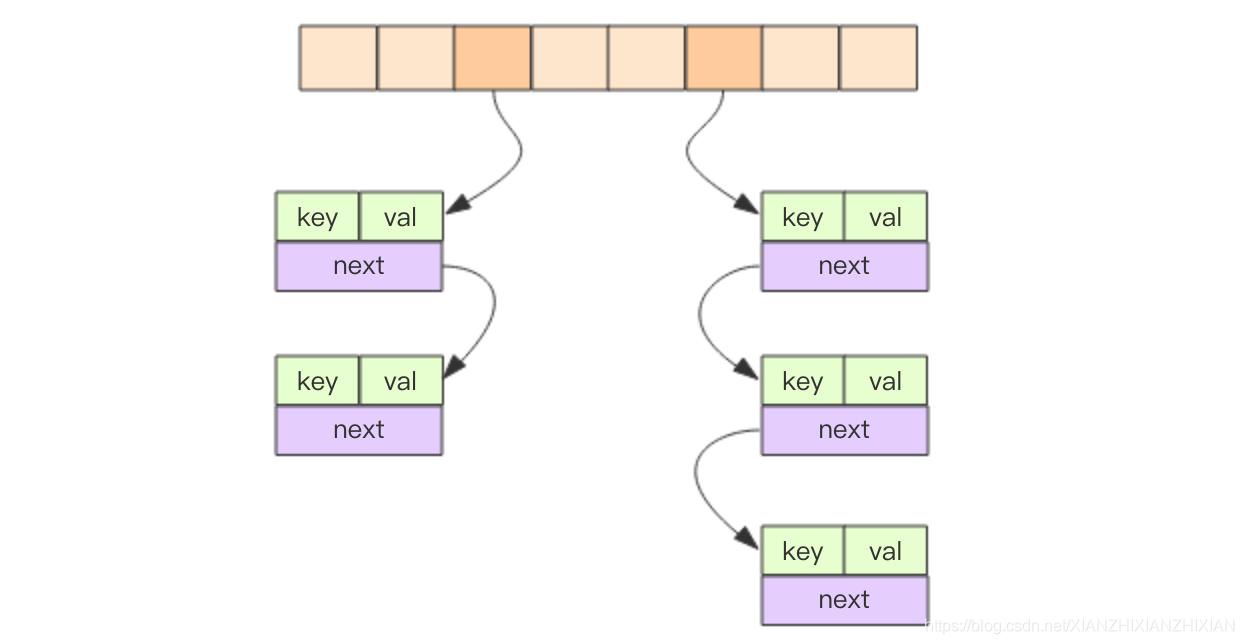
}Redis中的hashtable结构和Java的HashMap几乎是一样的,都是通过分桶的方式解决hash冲突。第一维是数组,第二维是链表;数组中存储的是链表的第一个元素的指针
渐进式rehash
大字典扩容是比较耗时的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个O(n)级别的操作,作为单线程的Redis无法接受这样的阻塞;Redis采用渐进式rehash
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{long index;dictEntry *entry;dictht *ht;// 这里进行小步搬迁if (dictIsRehashing(d)) {_dictRehashStep(d);}/* Get the index of the new element, or -1 if* the element already exists.*/if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) {return NULL;}/* Allocate the memory and store the new entry.* Insert the element in top, with the assumption that in a database* system it is more likely that recently added entries are accessed* more frequently.*///如果字典处于搬迁过程中,要将新的元素挂接到新的数组下面ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];entry = zmalloc(sizeof(*entry));entry->next = ht->table[index];ht->table[index] = entry;ht->used++;/* Set the hash entry fields.*/dictSetKey(d, entry, key);return entry;
}在客户端对dict进行(hset/hdel等指令时)会触发rehash,除了指令触发rehash,Redis还会在定时任务中对字典进行主动搬迁
// 服务器定时任务
void databaseCron() {
...if (server.activerehashing) {for (j = 0; j < dbs_per_call; j++) {int work_done = incrementallyRehash(rehash_db);if (work_done) {/* If the function did some work, stop here, we'll do* more at the next cron loop.*/break;} else {/* If this db didn't need rehash, we'll try the next one.*/rehash_db++;rehash_db %= server.dbnum;}}}
}dict查找过程
插入和删除元素都依赖于查找,hashtable的元素是存储在链表中的,所以得先计算出key对应的数组下标;hash_func会将keyhash得出一个整数,不同的key会被映射成分布比较均匀散乱的整数。只有hash均匀之后整个hashtable才是平衡的,二维链表的长度就不会差距很远,查找算法的性能也会比较稳定
func get(key) {let index = hash_func(key) % size;let entry = table[index];while(entry != NULL) {if entry.key == target {return entry.value;}entry = entry.next;}
}hash函数
Redis字典默认的hash函数是siphash,siphash算法即使在输入key很小的情况下,也可以产生随机性特别好的输出,而且它的性能也非常突出。对于Redis这样的单线程来说,字典数据结构如此普遍,字典操作也会非常频繁,hash函数自然也是越快越好
hash攻击
如果 hash 函数存在偏向性,黑客就可能利用这种偏向性对服务器进行攻击。存在偏向性的 hash 函数在特定模式下的输入会导致 hash 第二维链表长度极为不均匀,甚至所有的元素都集中到个别链表中,直接导致查找效率急剧下降,从O(1)退化到O(n)。有限的服务器计算能力将会被 hashtable 的查找效率彻底拖垮。这就是所谓 hash 攻击。
扩容条件
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d) {/* Incremental rehashing already in progress. Return. */if (dictIsRehashing(d)) {return DICT_OK;}/* If the hash table is empty expand it to the initial size. */if (d->ht[0].size == 0) {return dictExpand(d, DICT_HT_INITIAL_SIZE);}/* If we reached the 1:1 ratio, and we are allowed to resize the hash* table (global setting) or we should avoid it but the ratio between* elements/buckets is over the "safe" threshold, we resize doubling* the number of buckets. */if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) {return dictExpand(d, d->ht[0].used*2);}return DICT_OK;
}正常情况下,当hash表中元素的个数等于一维数组的长度时会开始扩容,扩容的新数组大小是原数组的2倍;若Redis正在做bgsave,为了减少内存页的过多分离(Copy On Write),Redis尽量不去扩容(dict_can_resize);如果hash表已经非常满了,元素个数已经达到了一维数组长度的5倍(dict_force_resize_ratio),说明hash表已经过于拥挤了,这个时候就会强制扩容
缩容条件
int htNeedsResize(dict *dict) {long long size, used;size = dictSlots(dict);used = dictSize(dict);return (size > DICT_HT_INITIAL_SIZE && (used*100/size < HASHTABLE_MIN_FILL));
}当hash表因为元素的逐渐删减变得越来越稀疏时,Redis会对hash表进行缩容来减少hash表的一维数组空间占用;缩容的条件是元素个数低于数组长度的10%,缩绒不会考虑Redis是否正在做bgsave
set的结构
Redis中的set底层结构也是字典,只不过所有的value都是NULL,其它特性和字典一模一样
为什么缩容不用考虑bgsave
扩容时考虑bgsave是因为,扩容需要申请额外的很多内存,且会重新链接链表(如果会冲突的话), 这样会造成很多内存碎片,也会占用更多的内存,造成系统的压力;而缩容过程中,由于申请的内存比较小,同时会释放掉一些已经使用的内存,不会增大系统的压力,因此不用考虑是否在进行bgsave操作
这篇关于Redis深度历险-Redis字典源码内部结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






