本文主要是介绍HBase协处理器及实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么引入协处理器?
HBase作为列数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。
比如,在旧版本(<0.92)的Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。
虽然HBase在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少通讯开销,从而获得很好的性能提升。于是, HBase在0.92之后引入了协处理器(coprocessors)。
协处理器实现了一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
灵感来源
HBase协处理器的灵感来自于Jeff Dean 09年的演讲。它根据该演讲实现了类似于bigtable的协处理器,包括以下特性:
1、每个表服务器的任意子表都可以运行代码。
2、客户端的高层调用接口 (客户端能够直接访问数据表的行地址,多行读写会自动分片成多个并行的RPC调用)。
3、提供一个非常灵活的、可用于建立分布式服务的数据模型。
4。能够自动化扩展、负载均衡、应用请求路由。
HBase的协处理器灵感来自 bigtable,但是实现细节不尽相同。 HBase建立了一个框架,它为用户提供类库和运行时环境,使得他们的代码能够在HBase region server和master上处理。
协处理器类型
协处理器分两种类型:
系统协处理器:可以全局导入region server上的所有数据表。
表协处理器:用户可以指定一张表使用协处理器。
协处理器插件
协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件。
一个是观察者(observer),类似于关系数据库的触发器。
另一个是终端(endpoint),动态的终端有点像存储过程。
Observer
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。
协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例,它提供了三种观察者接口:
RegionObserver:提供客户端的数据操纵事件钩子: Get、 Put、 Delete、Scan等。
WALObserver:提供WAL相关操作钩子。
MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等。
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行。用户可以任意基于协处理器实现复杂的HBase功能层。 HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大。
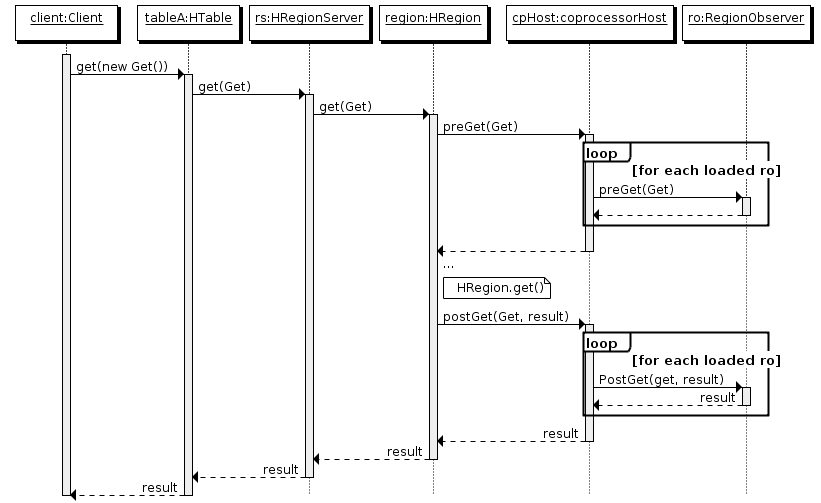
RegionObserver工作原理,如图1所示。
EndPoint
终端是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。
终端的使用如下面流程所示:
定义一个新的protocol接口,必须继承CoprocessorProtocol。
实现终端接口,该实现会被导入region环境执行。
继承抽象类BaseEndpointCoprocessor。
在客户端,终端可以被两个新的HBase Client API调用。
单个region:
HTableInterface.coprocessorProxy(Class<T> protocol, byte[] row) regions区域:
HTableInterface.coprocessorExec(Class<T> protocol, byte[] startKey, byte[] endKey, Batch.Call<T,R> callable)整体的EndPoint调用过程范例,如图所示:
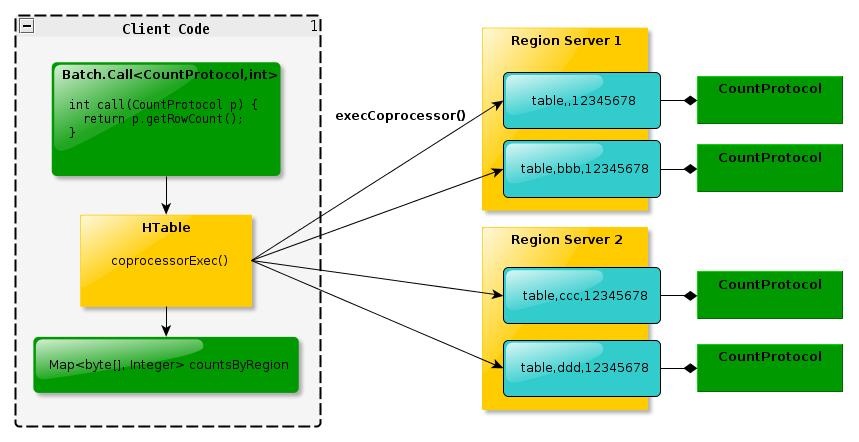
官方给的示例程序大体流程:


对Endpoint进行设置的三个方法:
A. 启动全局aggregation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现,只需要添加如下代码:
<property><name>hbase.coprocessor.user.region.classes</name><value>org.apache.hadoop.hbase.coprocessor.RowCountEndpoint</value>
</property>B. 启用表aggregation,只对特定的表生效。通过HBase Shell 来实现。
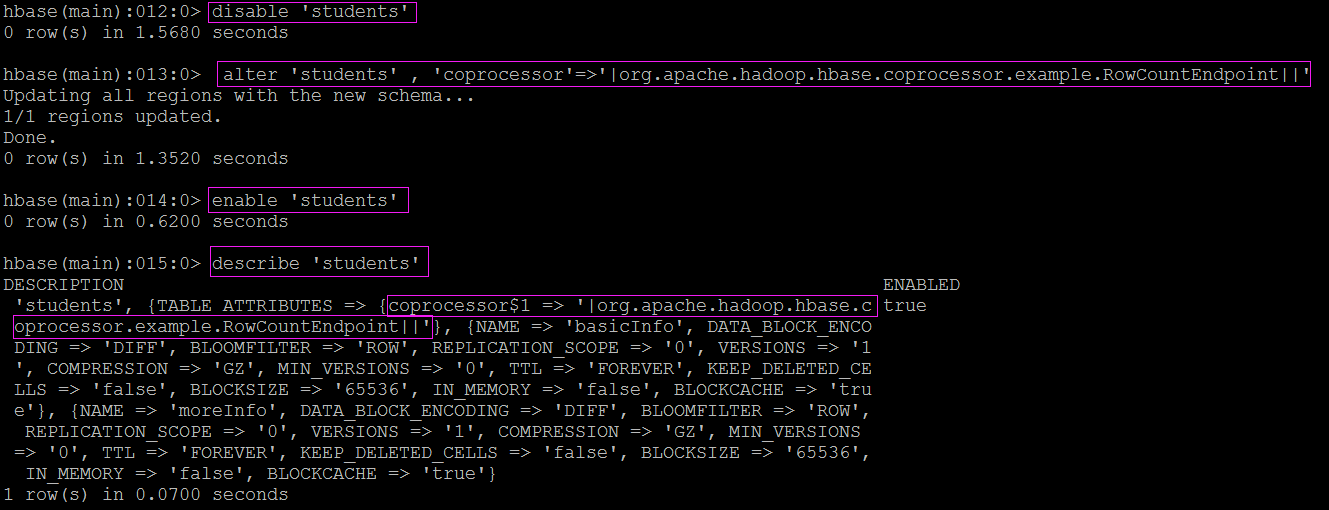
(1)disable指定表。
hbase> disable 'mytable' (2)添加aggregation 。
hbase> alter 'mytable','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.example.RowCountEndpoint ||'(3)重启指定表 。
hbase> enable 'mytable'C. API调用
HTableDescriptor htd=new HTableDescriptor("testTable");
htd.setValue("CORPROCESSOR$1" ,
path.toString+"|"+RowCountEndpoint.class.getCanonicalName()+"|"+Coprocessor.Priority.USER);其中path为jar在HDFS中的路径。
Demo1:
package Coprocessor;import java.io.IOException;
import java.util.Iterator;
import java.util.Map;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.coprocessor.Batch;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos;
import org.apache.hadoop.hbase.ipc.BlockingRpcCallback;
import org.apache.hadoop.hbase.ipc.ServerRpcController;import com.google.protobuf.ServiceException;public class CoprocessorRowCounter
{private String rootDir;private String zkServer;private String port;private Configuration conf; private HConnection hConn = null;private CoprocessorRowCounter(String rootDir,String zkServer,String port) throws IOException{this.rootDir = rootDir;this.zkServer = zkServer;this.port = port;conf = HBaseConfiguration.create();conf.set("hbase.rootdir", rootDir);conf.set("hbase.zookeeper.quorum", zkServer);conf.set("hbase.zookeeper.property.clientPort", port);hConn = HConnectionManager.createConnection(conf); }public static void main(String[] args) throws ServiceException, Throwable {String rootDir = "hdfs://hadoop1:8020/hbase";String zkServer = "hadoop1";String port = "2181";CoprocessorRowCounter conn = new CoprocessorRowCounter(rootDir,zkServer,port);//Configuration conf = HBaseConfiguration.create();HTable table = new HTable(conn.conf, "students"); //发送请求final ExampleProtos.CountRequest request = ExampleProtos.CountRequest.getDefaultInstance();//回调函数 call方法Map<byte[],Long> results = table.coprocessorService(ExampleProtos.RowCountService.class,null, null,new Batch.Call<ExampleProtos.RowCountService,Long>() {public Long call(ExampleProtos.RowCountService counter) throws IOException {ServerRpcController controller = new ServerRpcController();BlockingRpcCallback<ExampleProtos.CountResponse> rpcCallback =new BlockingRpcCallback<ExampleProtos.CountResponse>();//实现在server端counter.getRowCount(controller, request, rpcCallback);ExampleProtos.CountResponse response = rpcCallback.get();if (controller.failedOnException()) {throw controller.getFailedOn();}//返回return (response != null && response.hasCount()) ? response.getCount() : 0;}});int sum = 0;int count = 0;/* Iterator<Long> iter = results.values().iterator();Long val = iter.next();*/for (Long l : results.values()) {sum += l;count++;}System.out.println("row count = " + sum);System.out.println("region count = " + count);}
}
运行结果:
row count = 4
region count = 1注意:
- 协处理器配置的加载顺序:先加载配置文件中定义的协处理器,后加载表描述符中的协处理器。
COPROCESSOR$<number>中的number定义了加载的顺序。- 协处理器配置格式


移除协处理器

Demo2:

package Coprocessor;import java.io.IOException;
import java.util.List;import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.util.Bytes;public class RegionObserver extends BaseRegionObserver{private static byte[] fixed_rowkey = Bytes.toBytes("Ivy");//preGetOp代替preGet/*public void preGetOp(ObserverContext<RegionCoprocessorEnvironment> e,Get get, List<Cell> results) throws IOException {if (Bytes.equals(get.getRow(), fixed_rowkey)) {//行键 列族 列Cell cell = new KeyValue(get.getRow(), Bytes.toBytes("time"), Bytes.toBytes("time"));results.add(cell);}}*/@Overridepublic void preGet(ObserverContext<RegionCoprocessorEnvironment> c,Get get, List<KeyValue> result) throws IOException {if (Bytes.equals(get.getRow(), fixed_rowkey)) {//行键 列族 列KeyValue kv = new KeyValue(get.getRow(), Bytes.toBytes("time"), Bytes.toBytes("time"),Bytes.toBytes(System.currentTimeMillis()));result.add(kv);}}
}
打成jar包,上传到hdfs上面。

增加协处理器
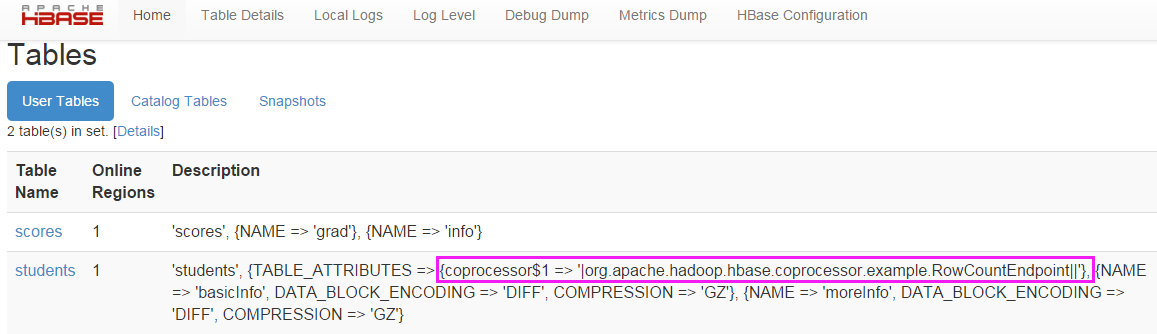
disable 'students'
alter 'students','coprocessor'=>'hdfs://nameservice1/liguodong/coprocessor.jar|Coprocessor.RegionObserver||'
enable 'students'
package HbaseAPI;import java.io.IOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.compress.Compression.Algorithm;
import org.apache.hadoop.hbase.io.encoding.DataBlockEncoding;
import org.apache.hadoop.hbase.util.Bytes;public class HBaseConnection {private String rootDir;private String zkServer;private String port;private Configuration conf; private HConnection hConn = null;private HBaseConnection(String rootDir,String zkServer,String port) throws IOException{this.rootDir = rootDir;this.zkServer = zkServer;this.port = port;conf = HBaseConfiguration.create();conf.set("hbase.rootdir", rootDir);conf.set("hbase.zookeeper.quorum", zkServer);conf.set("hbase.zookeeper.property.clientPort", port);hConn = HConnectionManager.createConnection(conf); }//获取数据public Result getData(String tableName,String rowkey) throws IOException{HTableInterface table = hConn.getTable(tableName);//用来获取单个行的相关信息Get get = new Get(Bytes.toBytes(rowkey));return table.get(get);}public void format(Result result){//行键String rowkey = Bytes.toString(result.getRow());//Return an cells of a Result as an array of KeyValuesKeyValue[] kvs = result.raw();for (KeyValue kv : kvs) {//列族名String family = Bytes.toString(kv.getFamily());//列名String qualifier = Bytes.toString(kv.getQualifier());//String value = Bytes.toString(result.getValue(Bytes.toBytes(family), Bytes.toBytes(qualifier)));String value = Bytes.toString(kv.getValue());System.out.println("rowkey->"+rowkey+", family->"+family+", qualifier->"+qualifier);System.out.println("value->"+value); }}public static void main(String[] args) throws IOException {String rootDir = "hdfs://hadoop1:8020/hbase";String zkServer = "hadoop1";String port = "2181";//初始化HBaseConnection conn = new HBaseConnection(rootDir,zkServer,port);//输出结果Result result = conn.getData("students", "Ivy");conn.format(result);result = conn.getData("students", "Tom");conn.format(result);}
}这篇关于HBase协处理器及实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






