本文主要是介绍全球的MLOps和ML工具概览,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
对于人工智能领域的任何人来说,MLOps一词是解决所有问题的一个神奇词汇。 它结合了所有与机器学习相关的任务,从管理、处理和可视化数据、运行和跟踪实验到将创建的模型投入生产,理想情况下是大规模、合规和安全的。它定义了实施ML工作以创建基于AI的应用程序和服务的过程。
我们在MLOps这个市场开展业务,但我们对还有哪些其他工具、平台和服务只有一个粗略的概念。 为了找到答案,我们对相关供应商进行了全面的搜索,一共找到了300多家! 我们决定整理我们发现的活跃项目,只列出那些专门针对机器学习任务和目标的项目。
下面是我们找到的全球的MLOps平台和ML工具总览的第一个版本。
关键统计数据
- 一共分析了300多个平台和工具,其中大约220个是活跃项目。
- 在整个欧洲,只能辨认出4个MLOps平台(MLReef、Hopsworks、Valohai(芬兰)和Polyaxon(德国柏林))。
- 大多数平台和工具涵盖2-3个ML任务。
MLOps的生命周期
下图展示了哪些工具和平台为ML生命周期中的各个任务和流程提供服务。 为了更好地概览,我们将生命周期分为4个主要的ML领域:
数据管理: 这主要是所有以机器学习为重点的任务,用于探索、管理和创建数据(集)。
建模: 这主要是从数据处理、训练模型、验证模型等所有流水线(Pipeline)相关的任务。
持续部署: 这是与MLOps的“Ops”部分相关的所有任务,包括启动、监控和保护生产模型。
计算和资源管理: 这是与计算和资源管理相关的所有功能。
注意:
一个提供的工具可以在多个ML任务中发现。 我们通过查看他们的网站、演示视频和动手测试来尽可能地确定他们的产品。

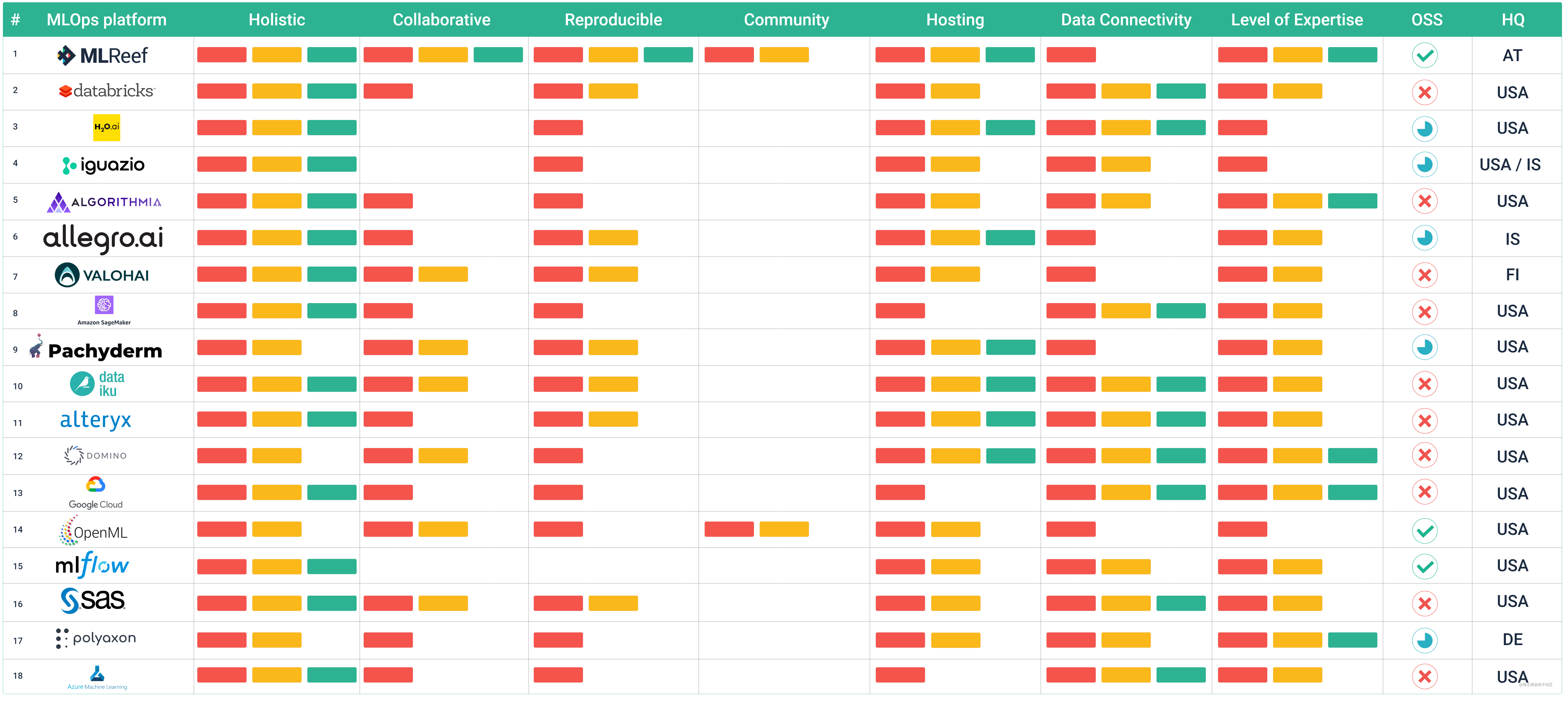
MLOps平台对比
我们想要更深入地分析工具,将他们定位为涵盖更广泛 ML 任务的全面的平台。 这种区分需要基于可识别和具体的指标进行,以避免随意选择。 我们认为,MLOps平台需要满足如下几点:
- 至少涵盖 ML 生命周期中的 5 个任务,
- 至少存在于 2 个主要领域(例如数据管理 + 建模),
- 将自己定位为 MLOps 平台。
根据这一标准,在220多个确定的平台和工具中,只有 18 个是 MLOps 平台。
审查特征
下一个有趣的问题是:这些平台之间的区别是什么?
我们决定最好的方法不是列出特定的特性和功能,而是列出关于它们的产品的更通用的能力。我们提出以下“软”标准,在我们看来,这些标准定义了一个出色的 MLOps 平台:
整体性: MLOps 平台需要涵盖广泛的 ML 任务可供选择。图中长条的规则为:一个表示覆盖一个主要领域,两个表示覆盖两个主要领域,三个表示覆盖三个主要领域。
协作: MLOps 中的一项关键任务是协作,并且随着 ML 解决方案越来越多地嵌入到组织中,协作变得越来越重要。我们根据在数据处理、建模和管理运行时环境的流水线(Pipeline)上共享和并行工作的可能性来定义协作。规则:一个长条表示覆盖三个部分中的其中一个。
可重现性: 在 ML 中重现整个增值链非常重要,因为它能够让我们理解预测并增加对已部署模型的信心。我们将可重现性定义为数据、源代码和超参数以及环境配置的跟踪和版本控制。规则:每个可变主题(例如数据、代码和超参数、运行时环境)表示一个长条。
社区: 随着越来越多的数据集、基于代码的函数和库可用,我们认为访问社区内容越来越重要。GitHub 一直是一个很好的代码来源,Kaggle 和其他代码/项目托管平台也是如此。尽管如此,我们希望看到在MLOps平台中直接利用社区协同增效作用。规则:MLOps平台内的每个可共享 ML 元素对应一个条(对于团队外部来说)。
托管: 在哪里可以使用该平台?仅限云、自托管或仅限本地。规则:主要的三种可能的使用方式中的每一种都对应一个长条。
数据连通性: 本节描述了平台内数据获取的可能性。我们确定了四种:在平台上、通过数据源(数据连接器)、第三方应用程序的直接 API 以及通过直接访问数据库。 规则:前面提到的每种数据连接类型都有一个长条(限制为 3 个长条)。
专业水平: 随着越来越多的新手进入 ML 市场,我们认为在平台的一般可操作性方面易于使用变得越来越重要。 最后一个特征更难评估,因为它涉及许多不同的方面(UI/UX、工作流机制、帮助文档、一般概念等)。 这部分的讨论更加开放,但我们尽量做到客观。 规则:一个长条表示仅限于专家,两个长条表示适用于专家和高级用户,三个长条表示适用于专家、高级和初学者。
深入审查MLOps平台
以下部分将仔细研究上面列出的 MLOps 平台。 在接下来的概览分析中,我们还将包括我们找到的每个工具和平台的部分(但现在这有点太多了!)。
MLReef(开源)
描述:MLReef 是一个开源 MLOps 平台,为机器学习项目提供托管。 它建立在您的团队或社区制作的可重用 ML 模块之上,以提高快速迭代和易于采用的能力。 它基于 git 来促进并发工作流、更高效、协作和可重复的 ML 开发,包含四个主要部分:
- 数据管理:完全版本化的数据托管和处理基础设施
- 发布代码存储库:容器化和版本化的脚本存储库,保证数据流水线中的使用不可变
- 实验管理:实验跟踪、环境和结果管理
- MLOps:ML/DL作业的流水线(pipeline)和编排解决方案(k8s/云/裸机)
开源仓库:https://gitlab.com/mlreef/mlreef 或 https://github.com/MLReef/mlreef


Databricks
描述:一个开放、简单的平台,用于存储和管理您的所有数据并支持您的所有分析和 AI 用例。
开源仓库:https://github.com/databricks


H2O(开源)
描述:H2O.ai 是 H2O 的创建者,H2O 是领先的开源机器学习和人工智能平台,受到全球 14,000 家企业的数据科学家的信赖。 我们的愿景是通过我们屡获殊荣的数据科学平台Driverless AI,让每个人的智能大众化。
开源仓库:https://github.com/h2oai


Iguazio
描述:Iguazio数据科学平台将人工智能项目转化为现实世界的业务成果。 使用 MLOps 和端到端自动化机器学习流水线(Pileline)来加速和扩展你的AI应用程序的开发、部署和管理。
开源仓库:https://github.com/iguazio/


Hopsworks(新增,开源)
描述:Hopsworks 2.0 是一个用于 ML 模型开发和运行的开源平台,可用作本地平台(开源或企业版)以及 AWS 和 Azure 上的托管平台。
开源仓库:https://github.com/logicalclocks/hopsworks


Algorithmia
描述:Algorithmia 是机器学习运维 (MLOps) 软件,用于管理现有操作流程中 ML 生命周期的所有阶段。 快速、安全且经济高效地将模型投入生产。
开源仓库:https://github.com/algorithmiaio


Allegro AI(开源,ClearML)
描述:端到端企业级平台,供数据科学家、数据工程师、DevOps 和管理人员管理整个机器学习和深度学习产品生命周期。
开源仓库:https://github.com/allegroai


Valohai⭐️(商业化,来自芬兰)
描述:训练、评估、部署、重复。 Valohai 是唯一一个从数据提取到模型部署自动化的 MLOps 平台。
开源仓库:https://github.com/valohai


Amazon SageMaker
描述:Amazon SageMaker 通过汇集专为 ML 构建的广泛功能集,帮助数据科学家和开发人员快速准备、构建、训练和部署高质量的机器学习 (ML) 模型。
开源仓库:https://github.com/aws/amazon-sagemaker-examples


Pachyderm(开源)
用于托管和管理的Pachydrm适用于希望获得Pachydrm所能提供的一切的用户,无需亲自管理基础设施。借助 Hub,您可以对数据进行版本控制、部署端到端流水线(Pipeline)等。 几乎不需要任何设置,而且是免费的!
开源仓库:https://github.com/pachyderm/pachyderm



Dataiku(商业化)
描述:Dataiku 是一个使数据访问大众化并使企业能够以以人为中心的方式构建自己的 AI 之路的平台。 注意:它们仅限于表格数据。
开源仓库:https://github.com/dataiku


Alteryx
描述:从数据到发现再到决策——只需几分钟。并且自动化和优化业务效果的分析。
开源仓库:https://github.com/alteryx


Domino Data Lab
描述:让您的数据科学团队使用他们喜欢的工具,并将它们整合到一个企业级平台中,使他们能够花更多时间解决关键业务问题。
开源仓库:https://github.com/dominodatalab


Google Cloud Platform
描述:利用 Google Cloud 对开源、多云和混合云的承诺,避免供应商锁定(lock-in)并加快开发速度。 在整个组织中实现更明智的决策。
开源仓库:https://github.com/GoogleCloudPlatform/


OpenML
描述:由于机器学习正在增强我们理解自然和建设更美好未来的能力,因此让研究、教育和行业中的每个人都透明且易于访问是至关重要的。 OpenML(Open Machine Learning)项目是一项范围广泛的动作,旨在为机器学习构建一个开放、有组织的在线生态系统。
开源仓库:https://github.com/openml


MLflow⭐️(开源)
描述:MLflow 是一个简化机器学习开发的平台,包括跟踪实验、将代码打包为能够可复现的运行以及共享和部署模型。 MLflow 提供了一组轻量级 API,可与任何现有的机器学习应用程序或库(TensorFlow、PyTorch、XGBoost 等)一起使用,无论您当前在何处运行 ML 代码(例如在notebooks、独立应用程序或云中)。
开源仓库:https://github.com/mlflow


SAS
描述:通过一个单一的、集成的、协作的解决方案解决最复杂的分析问题——现在它有了自动化建模 API。
开源仓库:https://github.com/sassoftware


Polyaxon⭐️(来自德国柏林,开源,针对k8s的机器学习平台)
描述:使用生产级 MLOps 工具重现、自动化和扩展您的数据科学工作流。
开源仓库:https://github.com/polyaxon


Microsoft Azure
描述:无限的数据和分析能力。 是的,无限。 在专为数据和分析构建的云上获得无与伦比的洞察、大规模和性价比。
开源仓库:https://github.com/Azure


DagsHub(git+dvc+mlflow)
DagsHub 是一个供数据科学家和机器学习工程师对其数据、模型、实验和代码进行版本控制的平台。 它允许您和您的团队轻松共享、审查和重复使用您的工作,为机器学习提供 GitHub 体验。
DagsHub 基于流行的开源工具和格式构建,可以轻松与您已经使用的工具集成。
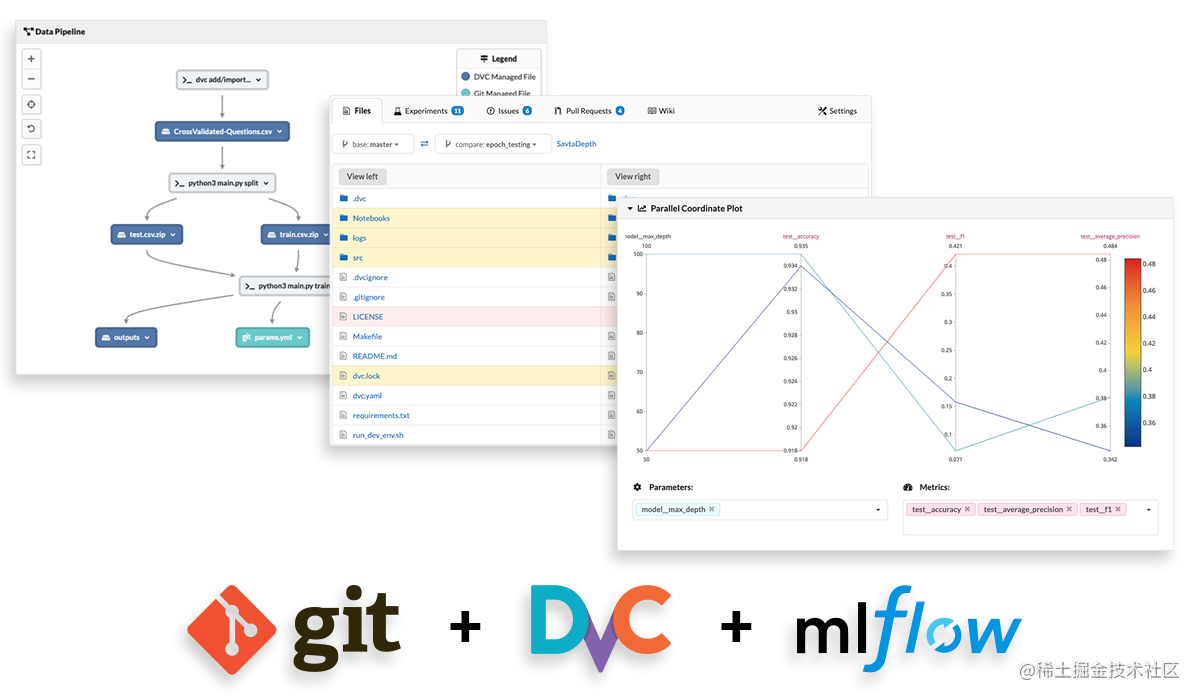
官方网站:https://dagshub.com/
Neu.ro⭐️
Neuro MLOps 平台,用于在公有云、混合云和私有云上进行全周期 ML/DL 应用程序开发和部署。
在多年为一系列企业客户开发创新 AI 解决方案的工作中,Neuro 获得了第一手了解构建和维护构建、部署和扩展 AI 解决方案所需的基础设施和工具所涉及的挑战。 这个 AI 基础设施现在被称为:MLOps。
我们相信构建和部署 ML 模型应该像使用 DevOps 的软件工程一样简单、快速和安全。 —MLOps.community
Neuro 平台使用户能够自动执行从数据收集到准备、训练、测试和部署的 ML 管道。 使用 Neuro,打包、扩展、微调、检测和持续交付的步骤都可以完全自动化,解决每个组织的两个主要挑战:上市时间和资源管理。
开箱即用的 Neu.ro 启动了一个成熟的机器学习开发环境,您需要的所有工具都触手可及。它将开源和专有工具集成到面向客户端的系统中。具体组件如下:
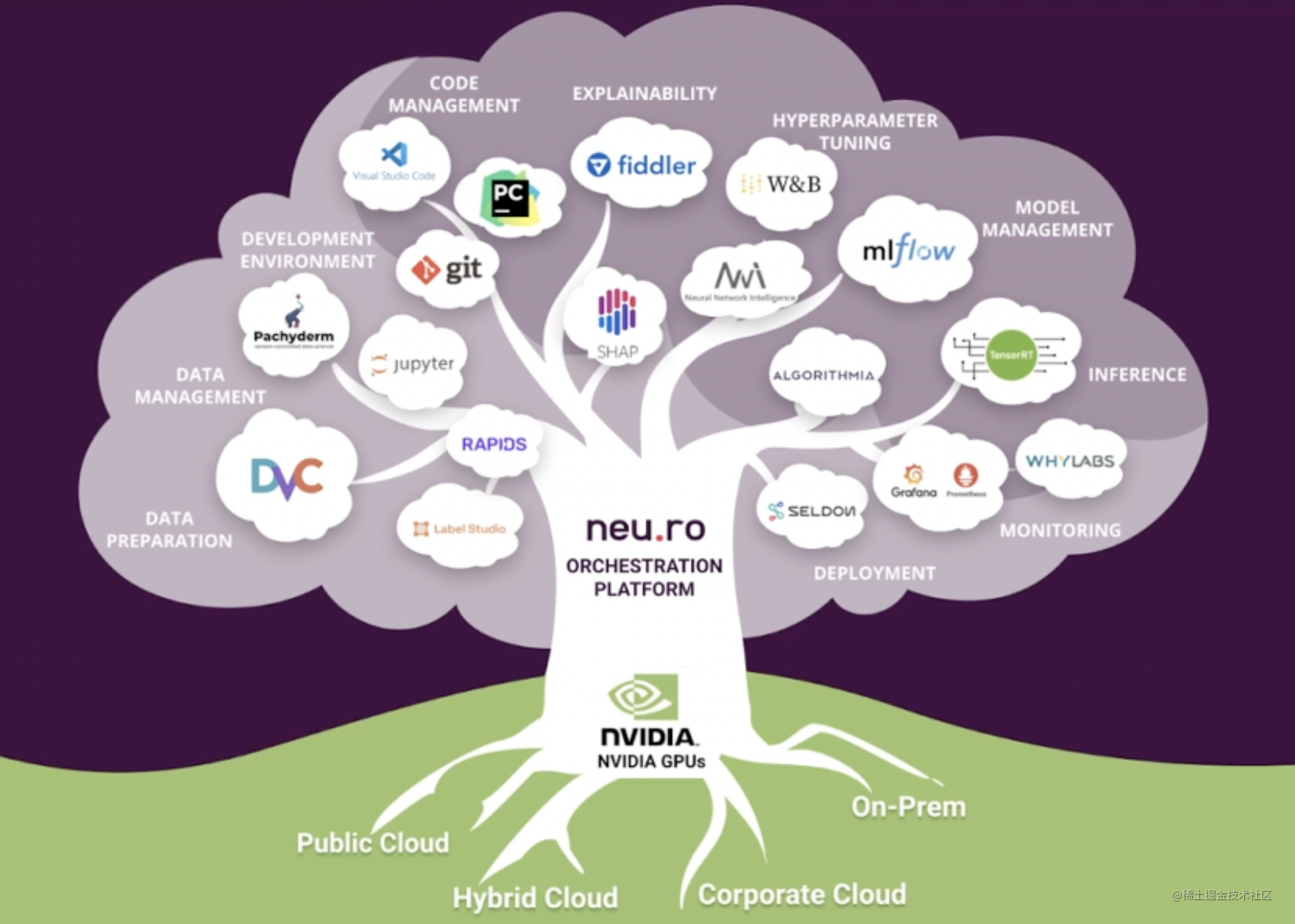
| ML项目生命周期组件 | 工具 |
|---|---|
| 1. Data labeling | Label Studio |
| 2. Data management | DVC |
| 3. Development environment | VSCode and Jupyter |
| 4. Remote debugging | VSCode remote debugger |
| 5. Code management | Git |
| 6. Experiment tracking | MLflow |
| 7. Hyperparameter tuning | NNI |
| 8. Distributed training | Neu.ro |
| 9. Metadata management | MLflow |
| 10. Model management | MLflow |
| 11. Deployment | Seldon Core |
| 12. Testing | Locust |
| 13. Monitoring | Prometheus + Grafana |
| 14. Interpretation | Seldon Alibi |
| 15. Pipelines orchestration | Neu.ro |
| 16. Resource orchestration | Neu.ro |
| 17. Access control orchestration | Neu.ro |
官方网站:https://neu.ro/mlops/
所有的MLOps和ML工具与平台
下面我们列出了我们在研究过程中发现的所有研究工具和平台。
数据管理
ML 生命周期中的这个主要领域侧重于管理数据。 我们决定将它作为一个单独的部分,因为它有许多方面位于“建模”部分之外。
数据探索和管理
帮助您管理、探索、存储和组织数据的工具和平台。
- Algorithmia
- Alluxio
- Amazon Redshift
- Amundsen
- Cohesity
- Aparavi
- AtScale
- Cazena
- Cloudera
- Clearsky
- Databricks
- Datagrok
- Dataiku
- Delta Lake
- Datera
- Dremio
- Druid
- Elastifile
- Erwin
- Excelero
- Fluree
- Gemini
- Hammerspace
- Hudi
- HYCU
- Imply
- Komprise
- Kyvos
- MLReef
- Microsoft Azure
- Milvus
- Octopai
- Openml
- Parquet
- Pilosa
- Presto
- Qri
- Rubrik
- Spark
- Tamr
- Waterline Data
- Whylabs
- Vearch
- Vexata
- Yellowbrick
数据标注
支持您标记数据以创建训练数据集的工具。
- 4SmartMachines
- Amazon Sage Maker - Data Labeling
- Appen
- Dataturks
- Defined Workflows
- Doccano
- Figure Eight
- iMerit
- Labelbox
- Prodigy
- Playment
- Scale
- Segments
- Snorkel
- Supervisely
数据流
用于将大量数据直接加载到数据流水线(pipelines)中的数据流服务和工具。
- Amazon Kinesis
- Alluxio
- Ares DB
- Confluent
- Flink
- Google Cloud Dataflow
- Hudi
- Kafka
- Microsoft Azure Stream Analytics
- Storm
- Striim
- Valohai
数据版本控制
下面提供了一些数据版本控制的工具和平台。这是特别有价值的,因为数据对模型的表现是不可分割的一部分。检视数据变更和数据治理对于模型完全再现性至关重要。
- Dagshub
- Databricks
- Dataiku
- Dolt
- DVC
- Floydhub
- MLReef
- Pachyderm
- Qri
- Waterline Data
数据隐私
数据隐私包含匿名化、加密、高度安全的数据存储和其他保护数据隐私的方法。
- Amnesia
- AirCloak
- Data Anon
- Celantur
- Mostly AI
- PySyft
- Tumult
数据质量检查
确保数据健康的方法。
- Arize
- Great Expectations
- Naveego
- Whylabs
建模
ML 生命周期中的这个主要领域侧重于创建 ML 模型。 这包括与创建模型直接相关的所有步骤,例如准备数据、特征工程、实验跟踪直至模型管理。 可以说,这个阶段是所有魔法发生的地方。
Notebook / ML 代码管理
帮助您管理、探索、存储和组织Notebook或机器学习操作的工具和平台。 我们明确没有包括 SCM 平台,例如 GitHub 或 Gitlab,因为它们并不是专门针对 ML(尽管他们完全能够托管这些功能)。
- Amazon Sagemaker
- Dagshub
- Databricks
- Dataiku
- Deepnote
- Domino Data Labs
- Floydhub
- Google Colab
- H2O
- Kaggle
- MLReef
- Openml
- Polyaxon
- Pachyderm
- Valohai
- Weights and Biases
数据处理和可视化
专门的数据处理(例如数据清理、格式化、预处理等)和可视化流水线(pipelines),旨在分析大量数据。 我们明确排除了简单的数据表示,例如在表格数据中显示数据分布(有很多工具可以做到这一点)。
- Alteryx
- Ascend IO
- Google Colab
- Dask
- Dataiku
- Databricks
- Dotdata
- Flyte
- Gluent
- Koalas
- Iguazio
- Imply
- Incorta
- Mlflow
- Kyvos
- MLReef
- Modin
- Naveego
- Openml
- Pachyderm
- Pilosa
- Presto
- SAS
- Snorkel
- SQLflow
- Starburst
- Turi Create
- Vaex
- Valohai
- Weights and Biases
特征工程
专门的特征工程和特征存储平台和工具。
- Amazon Sagemaker
- Dotdata
- Feast
- Featuretools
- Pachyderm
- ScribbleData
- Tecton
- TSfresh
- MLReef
- Iguazio
模型训练
这些工具和平台具有专门的流水线(pipeline)和功能来训练机器学习模型。
- Alteryx
- Amazon Sagemaker
- Iguazio
- Microsoft Azure
- Google Cloud Platform
- Google Colab
- Databricks
- Dataiku
- Domino Data Labs
- Dotscience
- Floydhub
- Flyte
- Horovod
- IBM Watson
- Ludwig
- Kaggle
- MLReef
- H2O
- Metaflow
- Mlflow
- Paperspace
- PerceptiLabs
- Snorkel
- Turi Create
- Valohai
- SAS
- Anyscale
- Pachyderm
实验跟踪
提供跟踪、比较和记录模型训练指标的工具和平台。
- Allegro AI
- Amazon Sagemaker
- Comet ML
- Dagshub
- Dataiku
- Datarobot
- Datmo
- Domino Data Labs
- Floydhub
- Google Cloud Platform
- H2O
- Ludwig
- Iguazio
- Mlflow
- MLReef
- Neptune AI
- Openml
- Polyaxon
- Spell
- Valohai
- Weights and Biases
模型/超参数优化
允许您为模型搜索理想超参数的工具和平台(例如,包括贝叶斯或网格搜索、性能优化等)
- Alteryx
- Amazon Sagemaker
- Angel
- Comet ML
- Datarobot
- Hyperopt
- Polyaxon
- Sigopt
- Spell
- Tune
- Optuna
- Talos
自动机器学习
自动机器学习,也称为AutoML,是基于架构、数据和超参数自动化找到理想模型配置的过程。 AutoML 是一种更高级的模型优化方法,但并不总是适用。
- Datarobot
- DeterminedAI
- Dotdata
- Google Cloud Platform
- H2O
- Iguazio
- Tazi
- Transmogrify
模型管理
模型管理包括模型存储、工件制品管理和模型版本控制。
- Algorithmia
- Allegro AI
- Amazon Sagemaker
- Databricks
- Dataiku
- DeterminedAI
- Dockship
- Domino Data Labs
- Dotdata
- Floydhub
- Gluon
- Google Cloud Platform
- H2O
- Huggingface
- IBM Watson
- Iguazio
- Mlflow
- Modzy
- Perceptilabs
- SAS
- Turi Create
- Valohai
- Verta
模型评估
此任务涉及测量模型的预测性能。它还包括测量所需的计算资源、延迟检查和漏洞。
- Arize
- Dawnbench
- MLperf
- Streamlit
- Tensorboard
- Whylabs
模型可解释性
通过分析深度学习模型的架构、权重分布与测试数据、热力图等来消除(尤其是)深度学习模型的黑盒综合症。这些工具为模型可解释性提供了专用功能。
- Amazon Sagemaker Clarify
- Fiddler
- InterpretML
- Lucid
- Perceptilabs
- Shap
- Tensorboard
持续部署
ML 生命周期中的这个主要领域侧重于将经过训练的模型投入生产。
数据流管理
这些工具让您可以在推理过程中管理和自动化数据流过程(新数据进入后会发生什么?),衡量性能和安全问题。
- Alluxio
- Spark
- Ascend IO
- Kafka
- Dataiku
- Dotdata
- HYCU
- Prefect
特征转换
类似于模型训练期间的过程,但现在在推理任务期间。 随着新数据的进入,需要对其进行转换以适应模型训练过的输入数据。 这些工具允许您创建应用于生产模型的特征转换。
- Feast
- Featuretools
- ScribbleData
- Tecton
- Iguazio
监控
模型性能监控非常重要,因为数据分布或计算性能的偏差可能会对业务逻辑和流程产生直接影响。
- Algorithmia
- Amazon Sagemaker
- Arize
- Dataiku
- Datadog
- Datatron
- Datarobot
- Domino Data Labs
- Dotscience
- Fiddler
- H2O
- Iguazio
- Losswise
- Snorkel
- Unravel
- Valohai
- Verta
- Whylabs
模型合规性和审计
此任务涉及提供模型来源的透明度。
- Algorithmia
- SAS
- H2O
模型部署和服务
集成模型部署功能的工具和平台。
- Amazon Sagemaker
- Aible
- Algorithmia
- Allegro AI
- Clipper
- Core ML
- Cortex
- Dataiku
- Datatron
- Datmo
- Domino Data Labs
- Dotdata
- Dotscience
- Floydhub
- Fritz AI
- Google Cloud Platform
- IBM Watson
- Iguazio
- Kubeflow
- Mlflow
- Modzy
- OctoML
- Paperspace
- Prediction IO
- SAS
- Seldon
- Spell
- Streamlit
- H2O
- Valohai
- Verta
模型验证(Model validation)
模型验证是一组旨在验证模型是否按预期执行的过程和活动。模型有效性应在操作上(即通过确定模型输出是否与观察到的数据一致)和概念上(即通过确定模型背后的理论和假设是否合理)进行评估。
- Arize
- Datatron
- Fiddler
- Lucid
- MLperf
- SAS
- Streamlit
模型序列化格式
调整模型以与其他框架、库或语言兼容。
- MMdnn
- ONNX
- Plaidml
计算管理
ML 生命周期中的这个主要领域包括管理计算基础设施。 这一点尤其重要,因为机器学习有时需要大量的存储和计算资源。
计算和数据基础设施(服务器)
这些组织为您的 ML 项目提供所需的能力(在硬件方面)。
- Google Cloud Platform
- IBM Watson
- Amazon AWS
- Microsoft Azure
- Cloudera
- Paperspace
- Kamatera
- Linode
- Cloudways
- Liquidweb
- Digitalocean
- Vultr
环境管理
自定义脚本管理基础环境需要包、库和运行时环境。 以下工具和平台将帮助您管理基础环境。
- Conda
- Databricks
- Datmo
- Mahout
- MLReef
资源分配
以下工具和平台支持管理不同的资源(如计算实例、存储卷等)。 此外,还管理一些包括预算和团队优先权等,以控制支出。
- Amazon Sagemaker
- Algorithmia
- Google Cloud Platform
- MLReef
- Databricks
- Microsoft Azure
- Dataiku
- DeterminedAI
- Floydhub
- IBM Watson
- Polyaxon
- Spell
- Amazon Sagemaker
- Valohai
- Allegro AI
模型服务和计算任务扩展
这些工具提供对已部署模型和计算任务的弹性扩展。
- Amazon Sagemaker
- Argo
- Microsoft Azure
- Datadog
- Datatron
- Datmo
- Google Cloud Platform
- TensorRT
- Seldon
- TVM
安全与隐私
这些工具可让您在将模型部署到生产环境时管理隐私话题(例如,GDPR合规性)并提高安全水平。
- Algorithmia
- Clever Hans
- Datadog
- Modzy
- PySyft
- Tumult
原文链接:Global MLOps and ML tools landscape
这篇关于全球的MLOps和ML工具概览的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







