本文主要是介绍招商资本对贝恩资本横刀夺爱:拟34亿美元私有化秦淮数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

雷递网 雷建平 7月10日
在贝恩资本筹备私有化秦淮数据之际,半路杀出了一个“程咬金”。
招商局资本控股(国际)有限公司(代表其自身及关联方,简称“招商资本”)今日宣布,于2023年6月向秦淮数据集团控股有限公司 (简称“秦淮数据”)(纳斯达克代码:CD)董事会特别委员会提出非约束性初步要约。
招商资本拟以每股A类或B类普通股4.60美元现金,或每股美国存托股份(ADS)9.20美元现金收购公司所有已发行的普通股,包括以美国存托股份(ADS)代表的 A类普通股(简称“ADSs”,每股代表两股 A类普通股)(简称“拟议交易”)。
招商资本拟议交易现金价值约为34亿美元。
受这一消息的影响,秦淮数据股价大涨超过12%,截至今日收盘,公司市值近30亿美元。
招商资本称私有化方案优于贝恩资本的方案
这之前,贝恩资本提议,以每股A类或B类普通股4美元的现金,或每股美国存托股票8美元的现金,收购贝恩股东尚未拥有的秦淮数据所有流通普通股,包括由美国存托股票(ADS,每股代表两股A类普通股)代表的A类普通股。根据上述要约,秦淮数据估值为约29.3亿美元。
招商资本称,此次提出的私有化价格较贝恩股东提出之收购价格高出15%的溢价(基于其2023年6月6日初步要约函),为秦淮数据集团股东提供更高价值;
为秦淮数据集团股东提供了比不受干扰的交易价格(公司ADSs于2023年6月5日的收盘价)高出52.6%的溢价;
提供较公司美国存托股份(ADS)于2023年6月5日前最后30个交易日的成交量加权平均收盘价高出61.1%的溢价。
招商资本还表示,拟议交易完成后,将与秦淮数据集团管理团队紧密合作,以助力公司加速下一阶段的发展战略部署,进一步提升公司作为亚洲领先数据中心平台的核心实力。
贝恩资本是秦淮数据大股东
据介绍,秦淮数据是一家亚太地区超大规模算力基础设施解决方案运营商,2020年10月在美国纳斯达克上市。

当时秦淮数据发行价为13.5美元,融资额度(包含超额配售权)为6.21亿美元。秦淮数据当时上市基石投资者包括红杉资本SCEP Master Fund、碧桂园旗下公司Joyful Phoenix Limite和世茂集团旗下的Shiying Finance Limited,分别投资4000万美元、6500万美元和3500万美元。
秦淮数据首日收盘价为16.23美元,较发行价上涨20.22%。以收盘价计算,秦淮数据市值为58.43亿美元。
秦淮数据的发展过程中,贝恩资本扮演了很重要的角色。IPO前,公司创始人Jing Ju(居静)持股6.19%,Bain Capital Entities(贝恩资本)持股为57.17%。
2022年2月,秦淮数据进行了上市后的换帅——创始人居静出局,原中国区总裁吴华鹏出任集团CEO,全面负责集团的战略规划、组织管理以及业务发展等工作。
吴华鹏于2019年加入秦淮数据集团,任中国区总裁。加入秦淮数据前,吴华鹏曾担任过凤凰新媒体副总裁及凤凰网CTO。
当时贝恩资本董事总经理竺稼还表示:“我们有充足的信心,在吴华鹏的带领下,秦淮的业务将更加多元,文化将更加开放,底子也将更加扎实,实现从10到100的持续进步”。
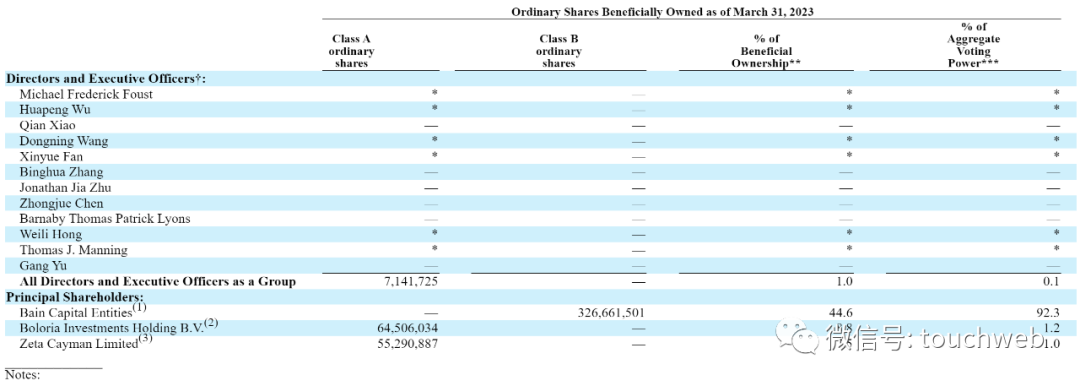
截至2023年3月31日,秦淮数据股权结构
截至2023年3月31日,贝恩资本仍持有秦淮数据44.6%的股权,投票权达到92.3%。Boloria Investments Holding持股为8.8%,有1.2%的投票权;Zeta Cayman Limited持股为7.5%,有1%的投票权。
预计年调整后EBITDA超30亿
据财报披露,秦淮数据2022年营收45.5亿元,同比增长60%;净利润6.52亿元,增长106%;调整后EBITDA为23.7亿元,增长67%。
秦淮数据2023年第一季度营收14.44亿元,同比增长56.8%;净利润2.53亿元,同比增长167.5%,净利润率达17.5%;调整后EBITDA 8.14 亿元,同比增长64.6%,调整后EBITDA利润率56.4%。
同时,秦淮数据将调整后EBITDA全年指引上调为31亿元到32.2亿元。
截至2023年3月,秦淮数据全球已运营及在建数据中心共33座,运营容量639MW;IT总容量898MW,预计未来一年内总容量突破1000MW。
据财报透露,秦淮数据在“东数西算”关键节点和亚太新兴市场长期经营,海内外两个“增长极”并驾齐驱的良好态势已经形成。
秦淮数据2023年第一季度新增的78MW签约容量中,69MW来自海外。截至一季度末,海外投运容量75MW,比上年同期增长275%;上架容量49MW,同比提升562%,位于马来西亚的柔佛超大规模数据中心一期满架运行。
在国内,位于山西灵丘的220kV输变电工程正式投产,为亚太最大单体园区数据中心提供稳定电力;与甘肃省人民政府签署零碳算力基础设施项目战略合作协议,未来3-5年将打造150MW数据中心基地。
———————————————
雷递由媒体人雷建平创办,若转载请写明来源。


这篇关于招商资本对贝恩资本横刀夺爱:拟34亿美元私有化秦淮数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





