本文主要是介绍袋鼠云产品功能更新报告05期|应有尽“优”,数栈一大波功能优化升级!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这段时间,我们对产品本身以及客户反馈的一些问题进行了持续的更新和优化,包括对离线平台数据同步功能的更新,数据资产平台血缘问题的优化等,力求满足不同行业用户的更多需求,为用户带来极致的产品使用体验。
以下为袋鼠云产品功能更新报告第五期内容,更多探索,请继续阅读。
离线开发平台
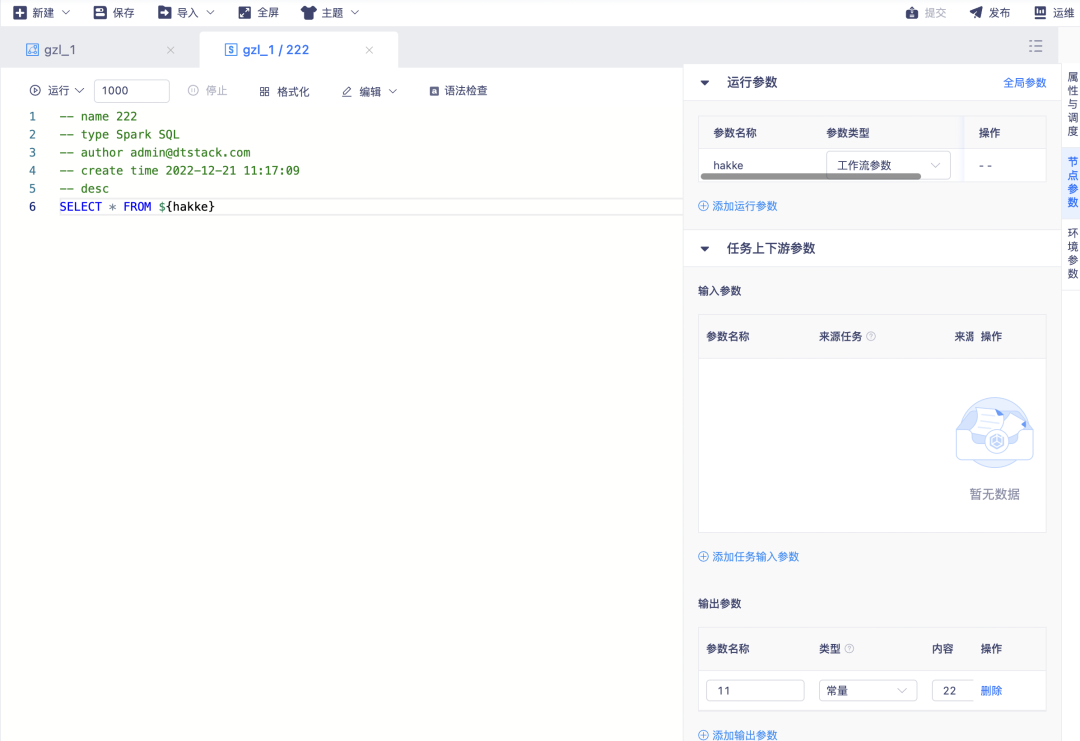
1.支持工作流参数
背景:很多业务场景下一个工作流中需要有一些能生效于整个工作流的参数,统一配置其下所有子节点通用。
新增功能说明:工作流父任务中支持创建工作流层级参数,工作流参数在工作流范围内生效。工作流下子节点支持通过${参数名称}的方式来引用该工作流参数。

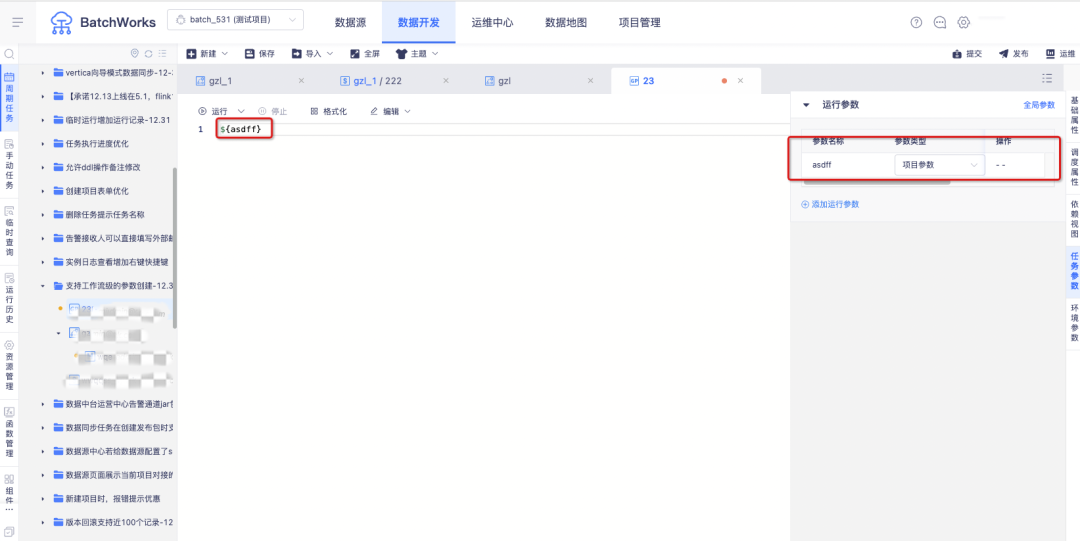
2.支持项目级参数
背景:
目前离线已支持的参数类型有以下几种:
• 全局参数-作用于整个数栈平台
• 自定义参数-作用于单个离线任务/工作流子节点
• 任务上下游参数-作用于引入此参数的下游任务
• 工作流参数-作用于单个工作流任务
增加的项目级参数,作用于当前项目之内的所有任务,既不影响别的项目的任务,也可实现项目内某些业务配置批量修改的效果。
新增功能说明:支持在项目的「项目管理->项目参数」中配置项目参数,配置完成后,该项目下的任务都可以进行引用。在任务中可以通过${参数名称}的方式引用项目参数。

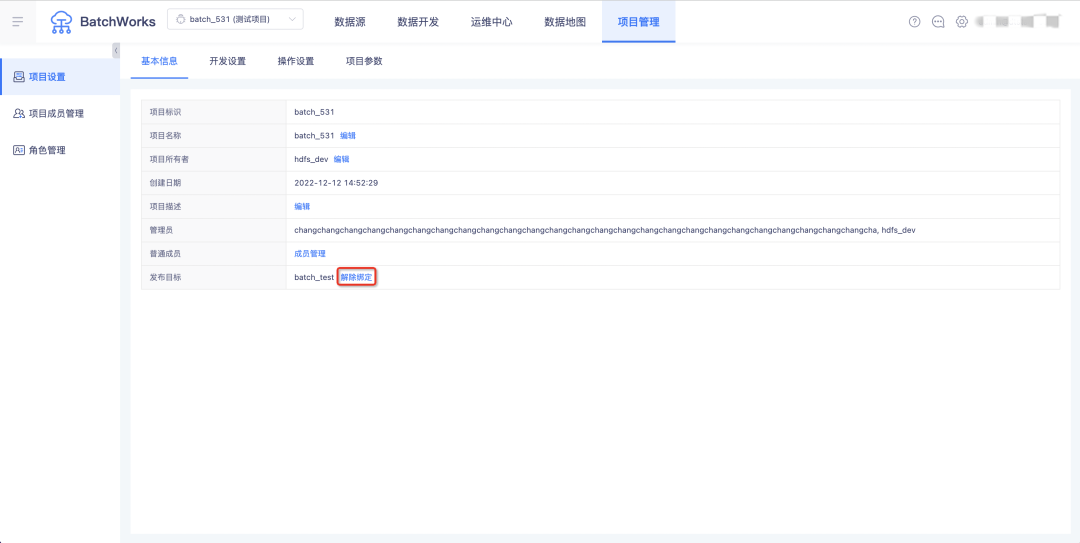
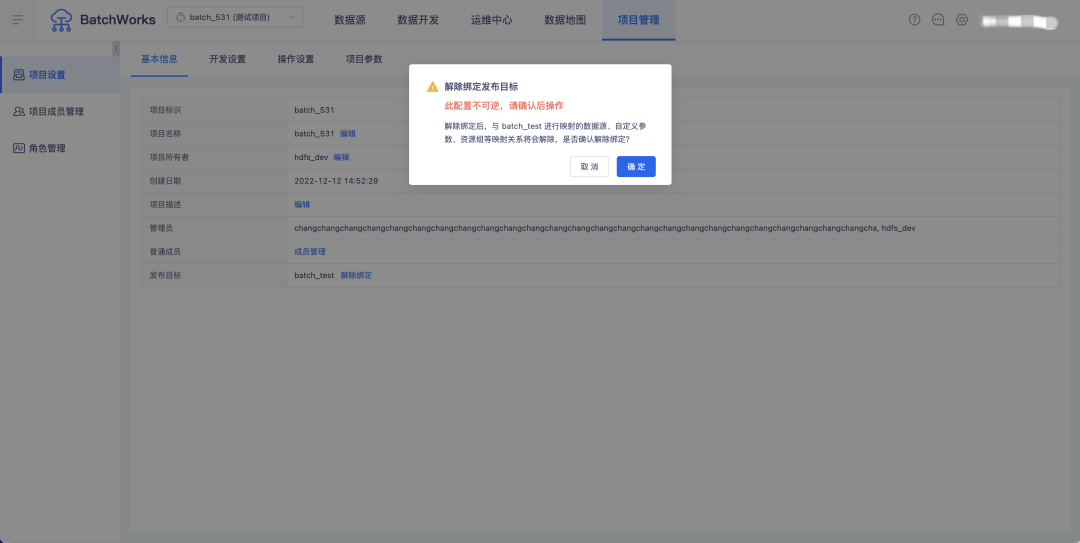
3.绑定的项目支持解绑
背景:当前项目绑定为非可逆操作,一个项目一旦和另一个项目产生绑定后无法解绑也不支持删除,但部分已经绑定的项目因业务原因可能需要换目标项目绑定,或者不再使用需要删除。
新增功能说明:可在测试项目的「项目设置-基本信息」中操作解绑生产项目,此操作不可逆。解除生产测试项目绑定后,数据源映射、资源组映射、发布至目标项目功能会受到影响,回退至绑定前状态,可按正常逻辑删除。
4.补数据支持对各类型参数进行一次性赋值
背景:补数据时可能会存在需要对参数值进行临时替换的情况,例如跑历史日期的数据时,补数据的时间参数范围需要变更。
新增功能说明:在「运维中心-周期任务管理-任务补数据」中进行补数据参数重新赋值操作,补数据实际跑任务的参数值会被补数据时重新赋值的参数值替换。
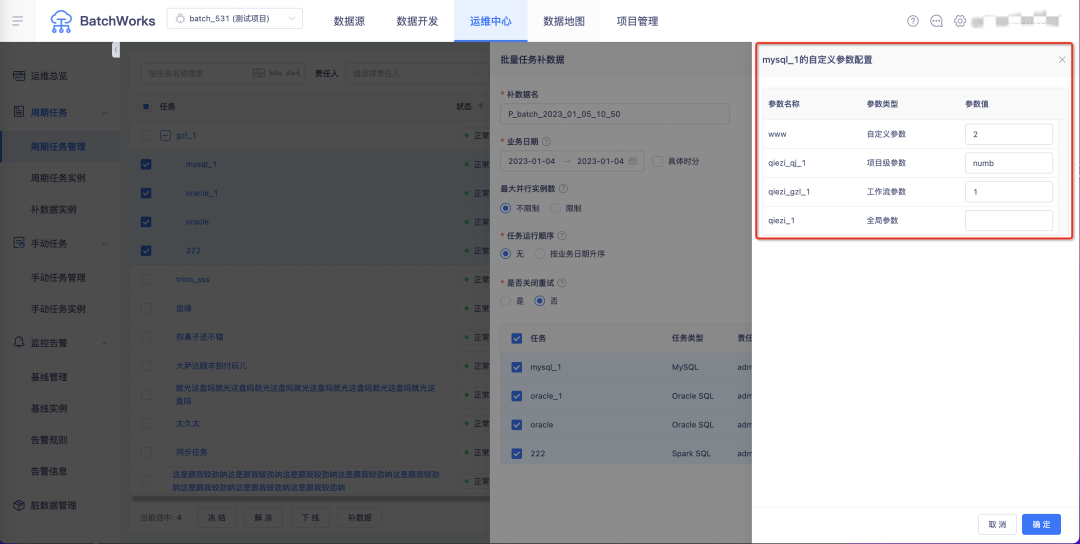
5.临时运行可查看运行历史
背景:周期任务、手动任务提交到调度运行时,都会产生实例,记录运行状态和运行日志等信息。但是周期任务、临时查询和手动任务在临时运行时不存在运行记录,用户无法查看历史临时运行的运行状态和运行日志等信息,导致一些重要的操作无法追踪。
新增功能说明:在数据开发页面最左侧功能模块列表中,新增了「运行历史」功能。在「运行历史」中,可查看历史近30天(可自定义)临时运行的 SQL、日志等信息。
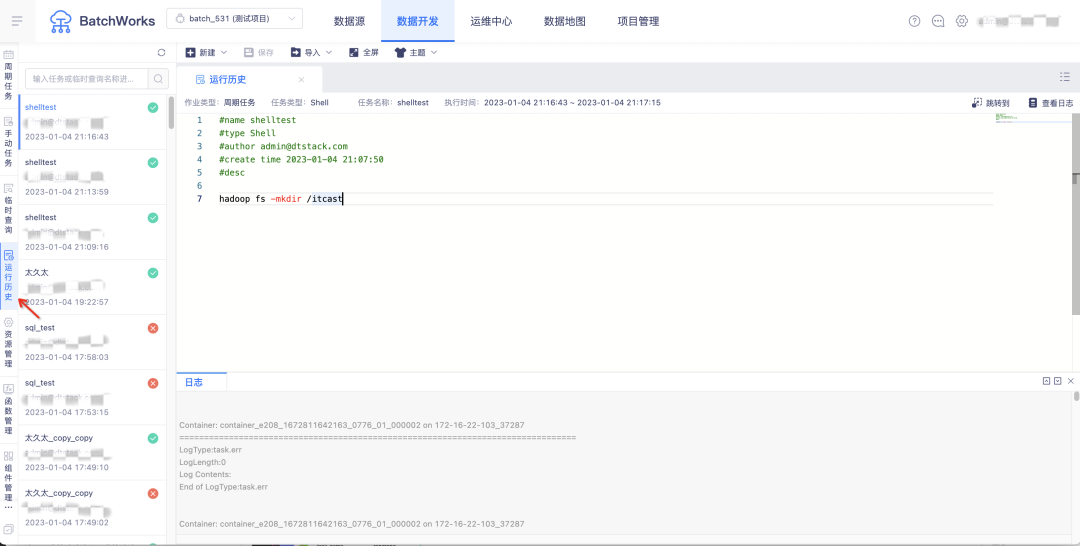
6.告警接受人支持填写其他参数
背景:部分客户希望一些非数栈用户(比如合作方)也能收到任务的告警信息,而目前平台支持选的告警接收人范围为当前项目下的用户。期望离线侧告警配置时能灵活添加一些自定义值:可以是手机号、邮箱、用户名等信息,客户通过自定义告警通道中上传的 jar 包自定义解析获取值的内容,再通过自己的系统给解析出的联系人发送告警。
新增功能说明:在创建告警规则时,支持填写外部联系人信息,通过英文逗号分割。(自定义告警通道中上传的 jar 需要支持解析)
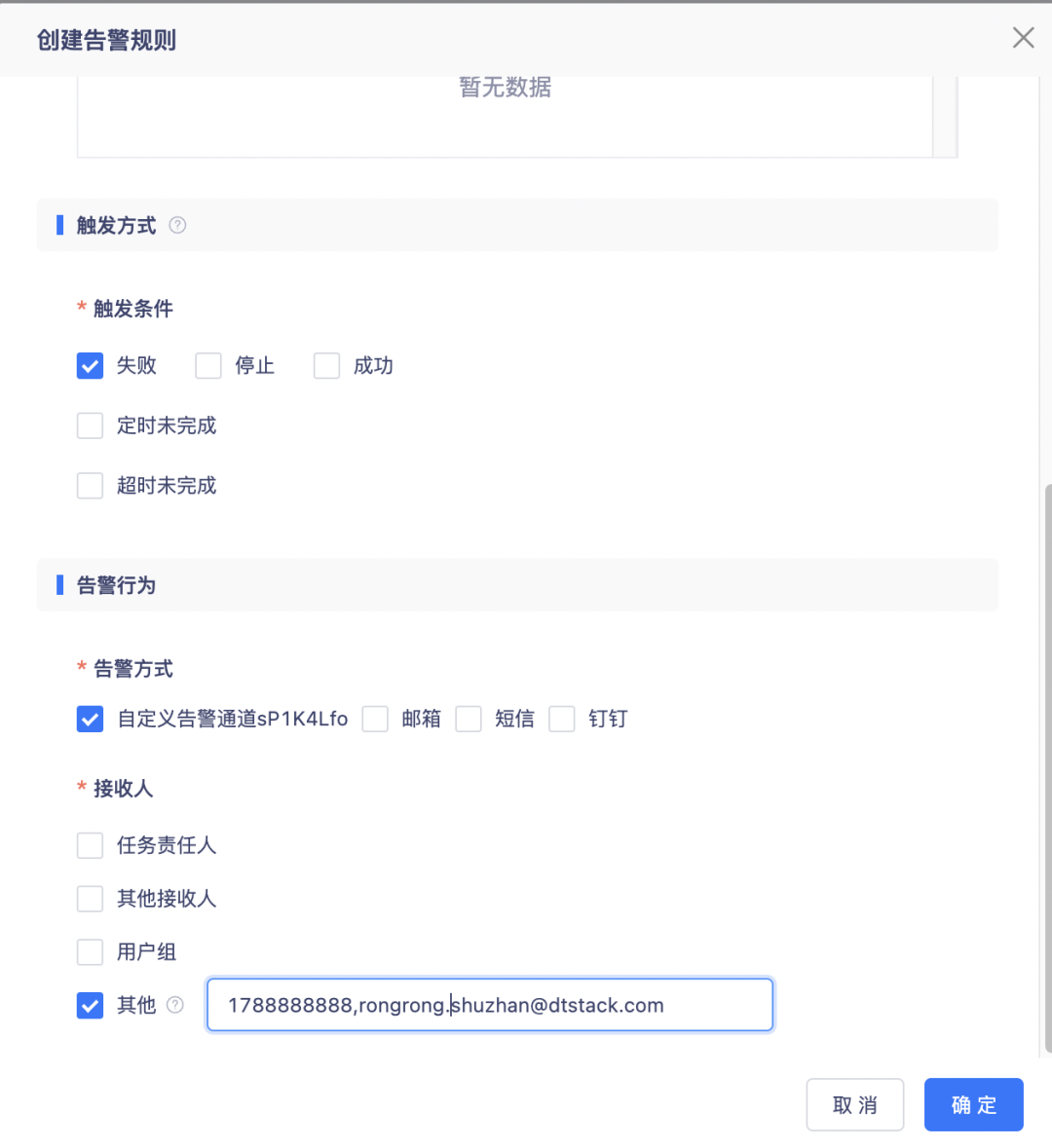
7.数据同步的读写并行度支持分开设置
背景:由于数据同步源端与目标端的数据库存在数据库本身性能等因素的影响,读和写的速率往往是不一致的,例如读的速率是5M/s,写的速率只有2M/s,读和写统一用一个并行度控制实际不能达到同步速率的最大优化,反而可能带来问题。
新增功能说明:在数据同步的通道控制中原“作业并发数”改为“读取并发数”和“写入并发数”,两个参数单独配置互不影响,用户可灵活调整让同步效率最大化,并发数调整范围上限改为100。
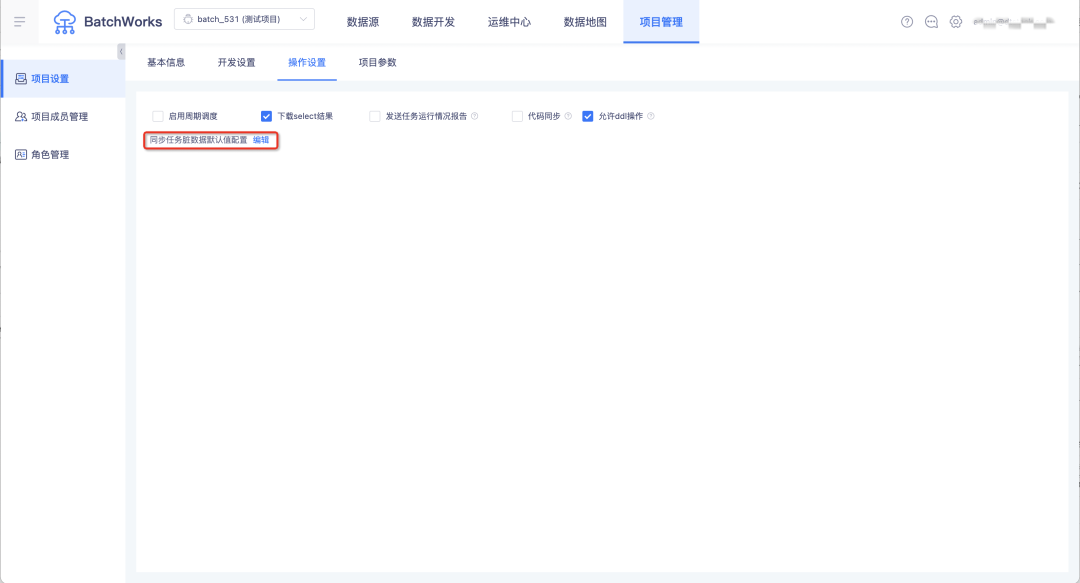
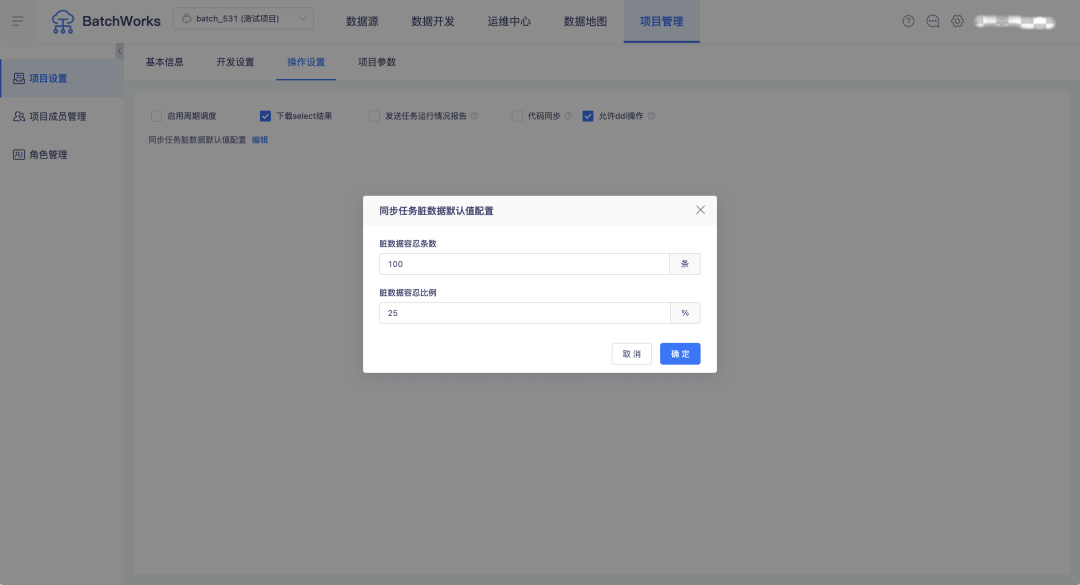
8.脏数据容忍条数支持按项目设置默认值
新增功能说明
背景:同步任务中的脏数据默认容忍条数原本固定是100,部分客户实际接受的容忍度是0,导致每配置一个同步任务就需要改一下脏数据容忍条数的设置值,使用不便。
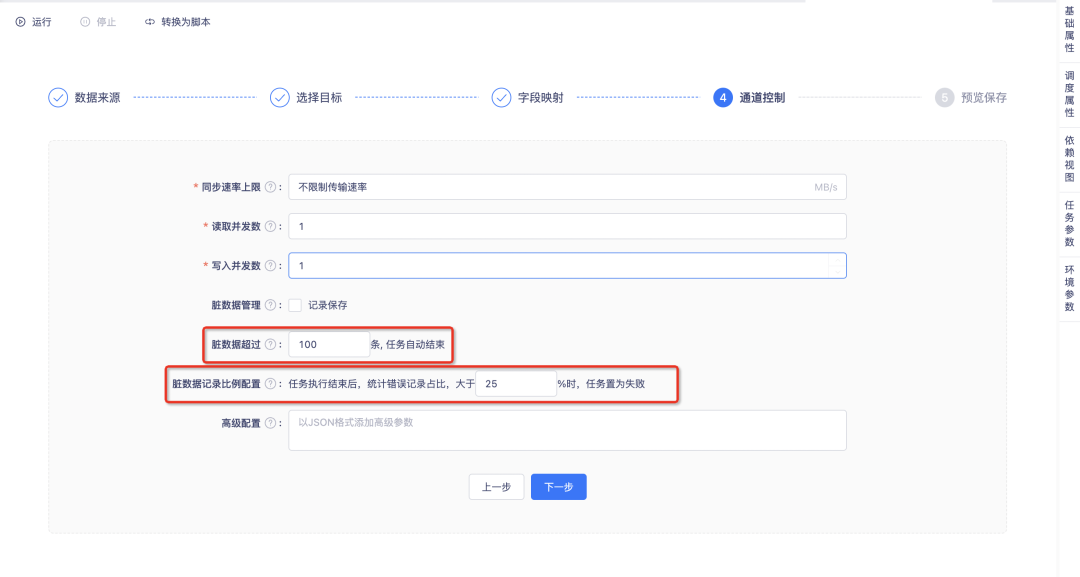
新增功能说明:在离线「项目管理->项目设置->操作设置」中,支持设置数据同步任务脏数据默认容忍条数和脏数据默认容忍比例。配置完成后,新建数据同步任务在通道控制模块会展示默认值。
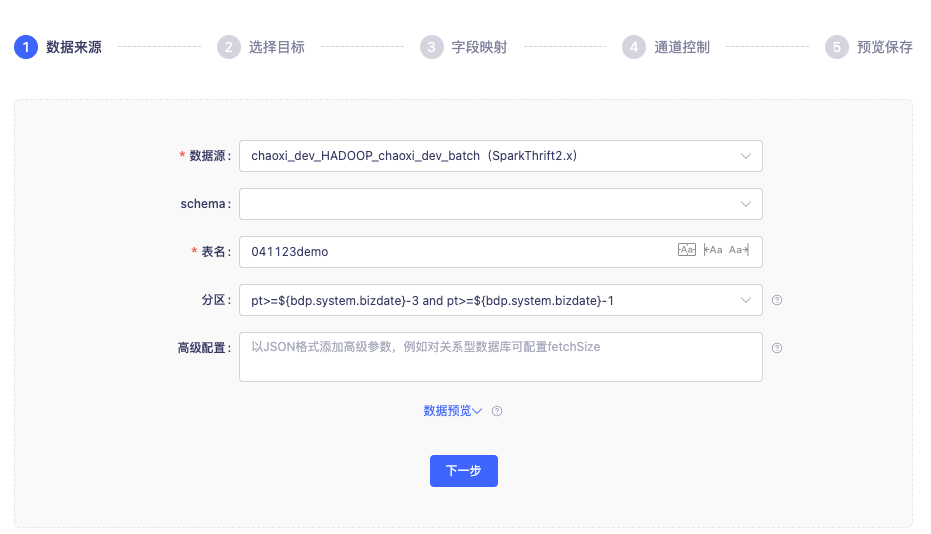
9.数据同步读取 hive 表时可选择读取多个分区的数据
背景:数据同步读取 hive 表时目前仅支持选择一个分区读取,部分客户场景下需要把多个分区的数据读取出来写入目标表。
新增功能说明:读 hive 表时分区可以用 and 作为连接符筛选多个分区进行数据读取。
10.任务运行超时中断
背景:目前所有任务一旦开始运行,无论运行多久平台都不会自动杀死,导致部分异常任务运行时间长,占用大量资源。
新增功能说明:所有任务在调度属性处增加了超时时间的配置项,默认不限制,可选择定义超时时间,运行超时后平台会自动将其杀死。
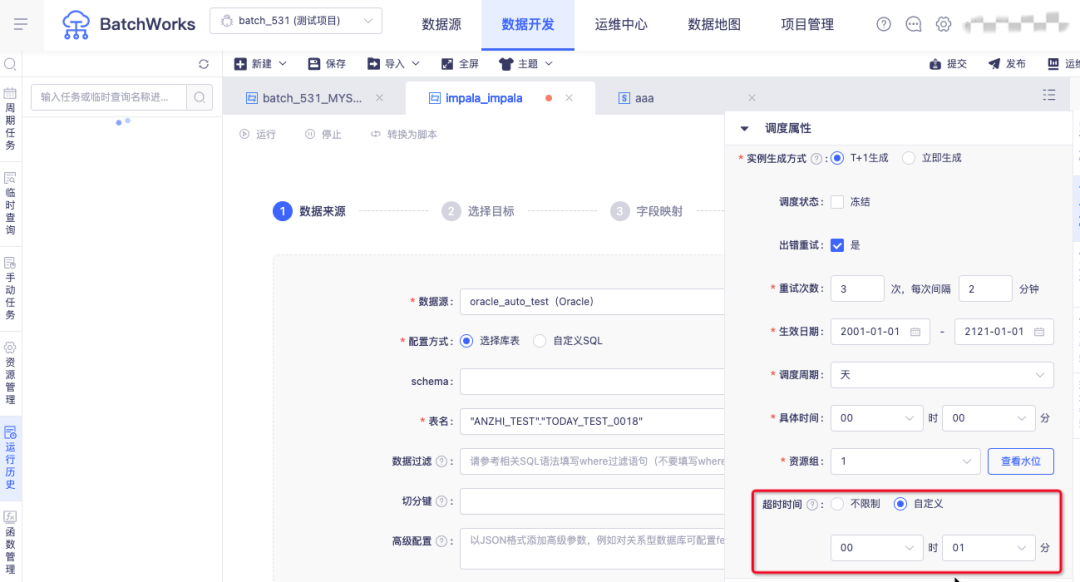
11.表管理的表查看交互优化
背景:点击表管理中某张表的字段、分区等详细信息的区域较小,不方便查看。
新增功能说明:对该区域可手动进行拉高。
12.hive 数据同步的分区支持选择范围
当 hive 类数据源作为数据同步的来源时,分区支持识别逻辑运算符“>”“=”“<”“and”,例如“pt>=202211150016 and pt<=202211200016 ”,即代表读取范围在此之间的所有分区。
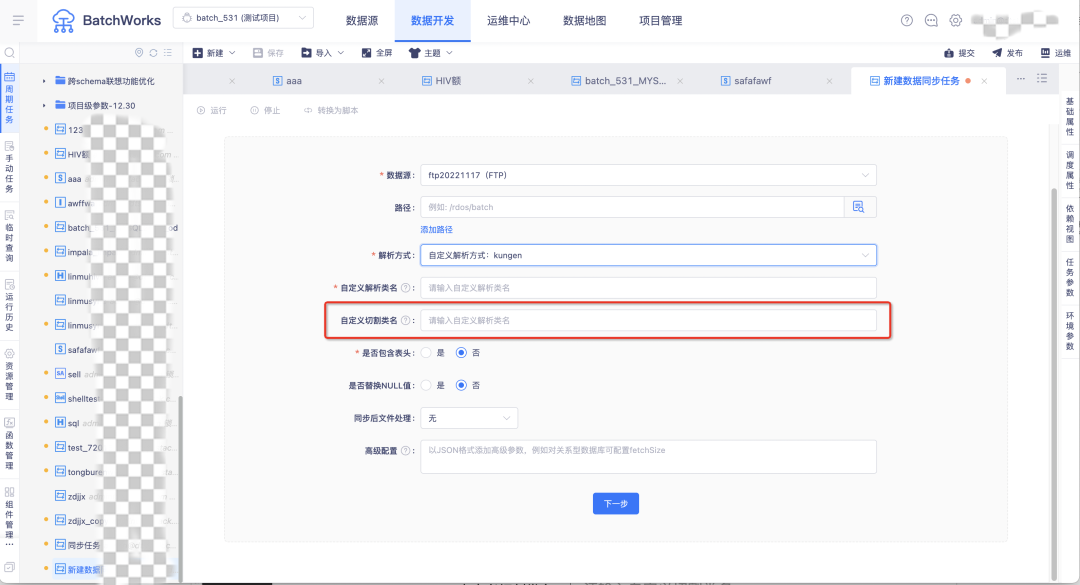
13.FTP 大文件拆分支持自定义解析文件的拆分
在用户解析方式选择自定义解析方式时,支持用户上传自定义 jar 包对 FTP 中的文件进行切割拆分同步。
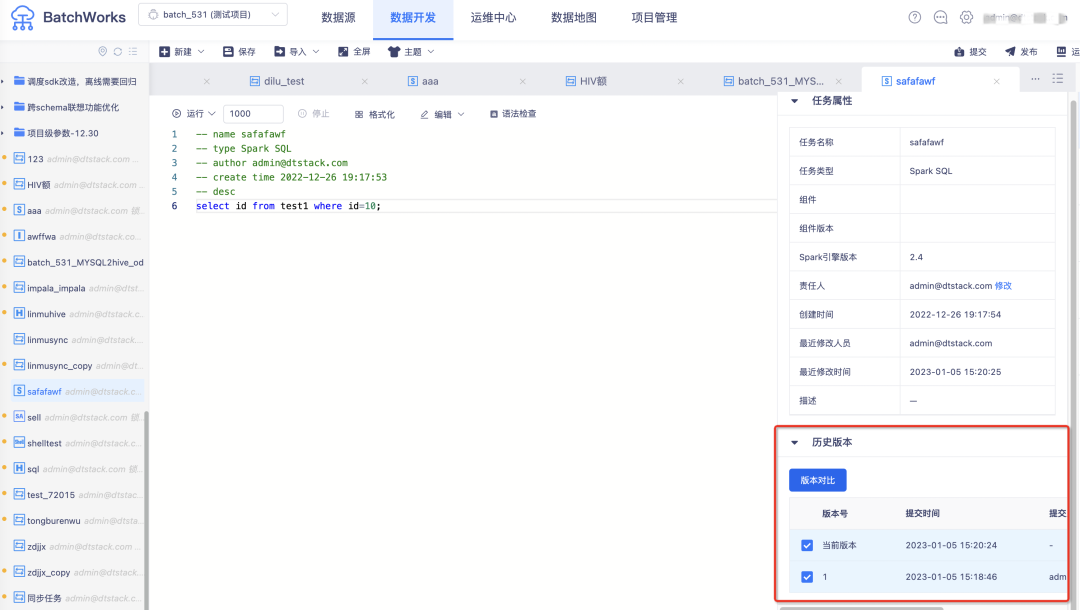
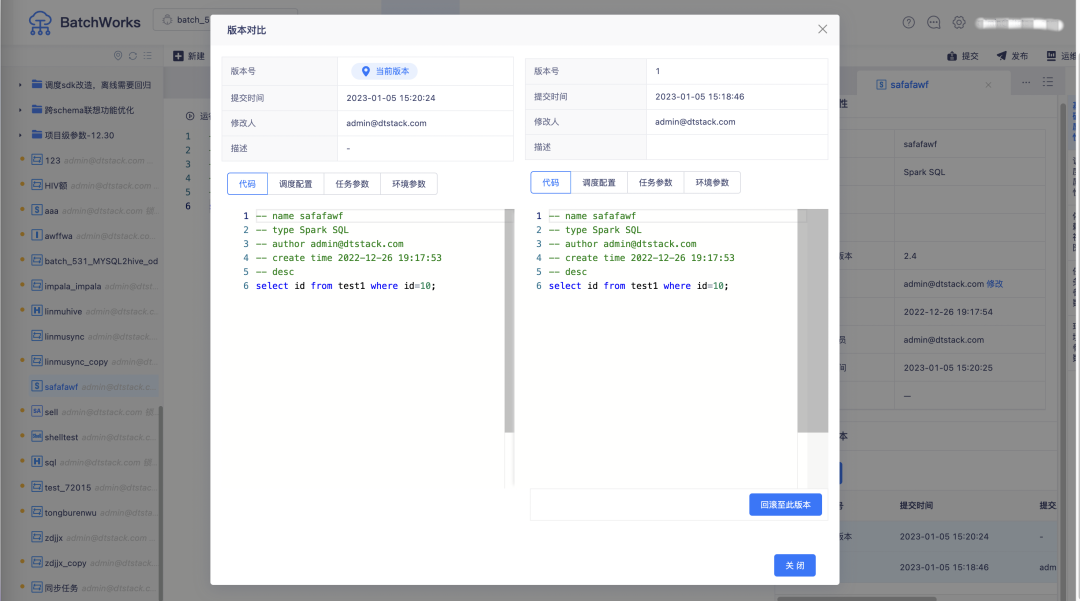
14.版本对比功能优化
· 历史版本支持查看近50条版本记录
· 版本对比功能交互调整
• 支持历史版本间对比
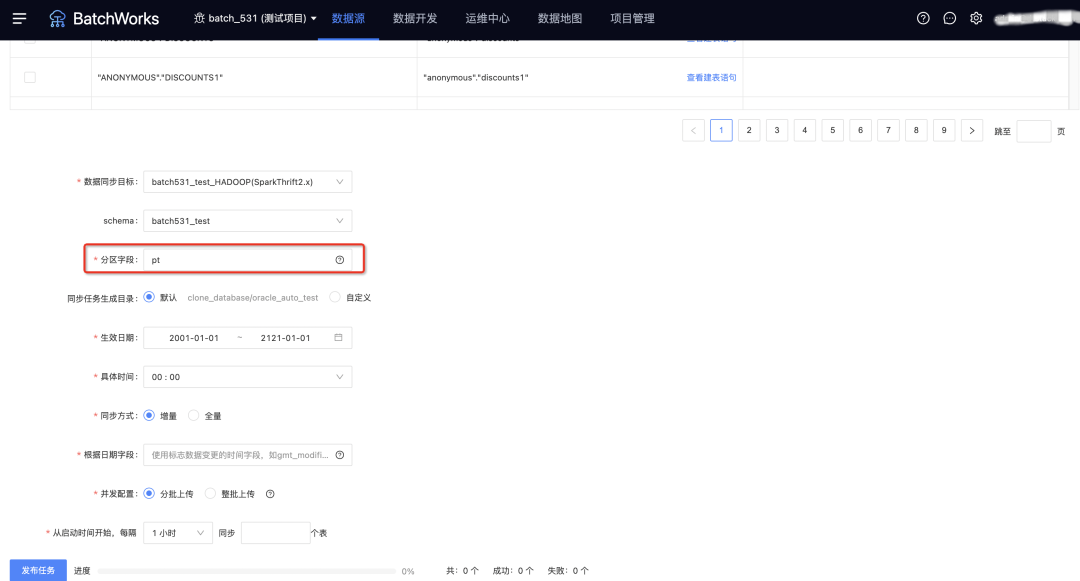
15.整库同步写 hive 时支持对分区表指定分区名称
当整库同步选中 hive 类的数据同步目标时,可以指定分区字段的名称。
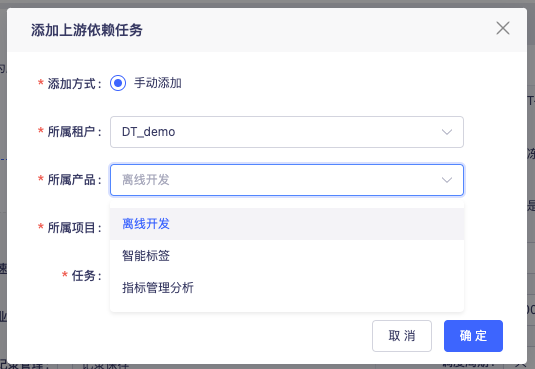
16.离线支持配置指标任务作为上游依赖
目前离线已经支持的跨产品任务依赖包括:质量任务(关联)、标签任务,加上指标任务后整个数栈的所有离线任务就可实现相互的依赖了。
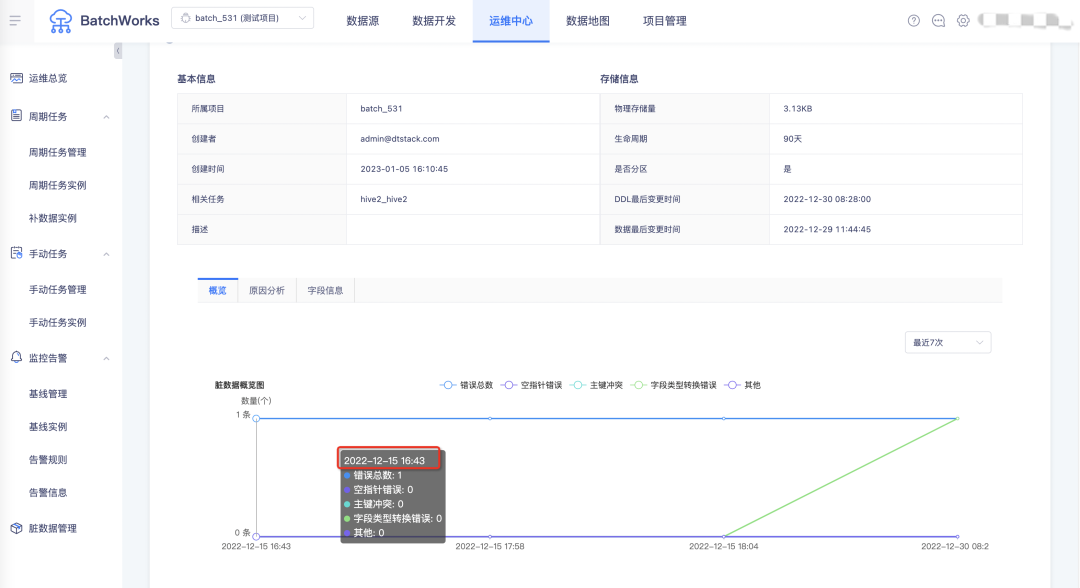
17.脏数据管理概览图显示具体时间
18.通过右键快捷键可查看任务日志
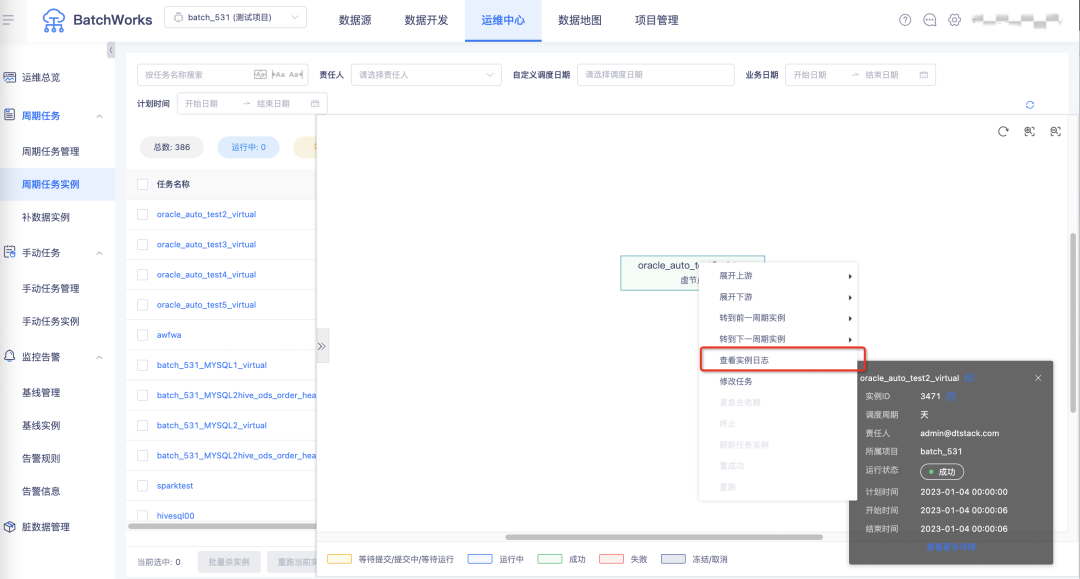
19.任务执行进度优化
执行进度前展示等待时长。 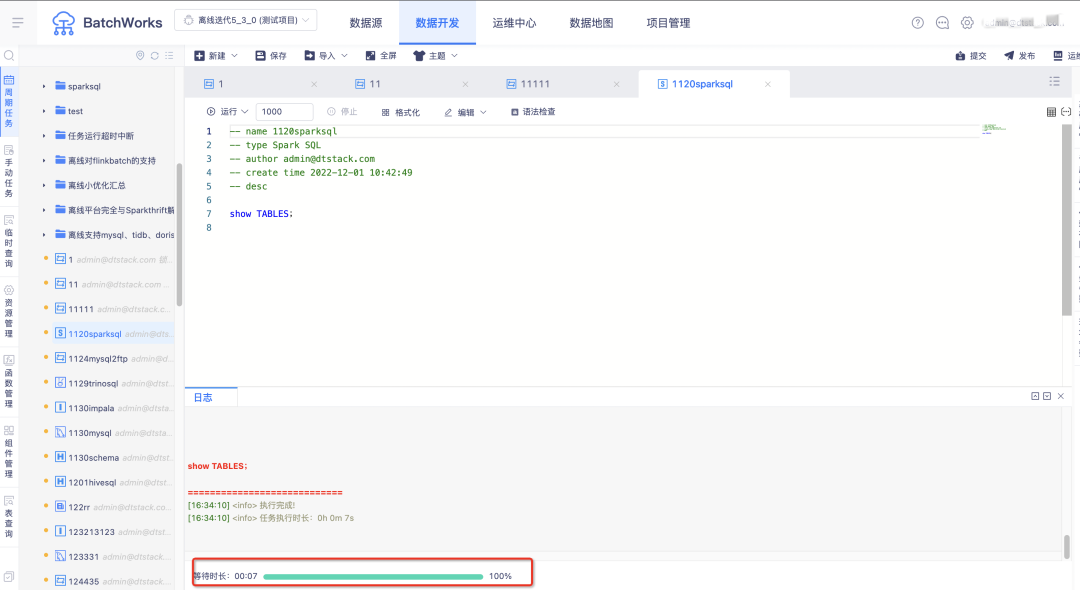
20.其他优化项
· vertica 支持向导模式数据同步
· 任务下线后,支持查看任务实例
· RDB 任务支持在任务间及工作流里的参数传递
· 数据同步任务在创建发布包时被选中时支持关联到表:数据同步任务目标端一键生成的目标表,支持关联至发布包中
· SQL 语句支持:Desc database、Show database、Create database、Drop database、Show tables、Create table、Desc table、Alter table、Drop table、Creat function
· 表联想功能优化:spark sql、hive sql、gp sql 编写 SQL 代码时,支持表联想功能,联想范围:离线对接和创建 schema 下的表
· 删除任务、资源等内容时,提示内容名称
实时开发平台
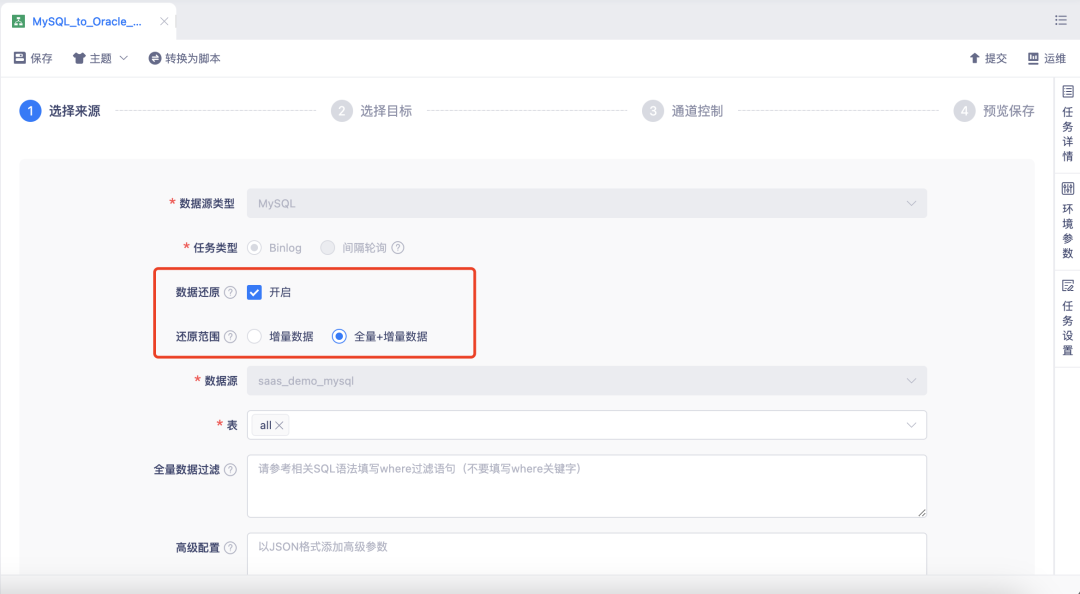
1.【数据还原】支持一体化任务
背景:一个任务即可完成存量数据的同步,并无缝衔接增量日志的采集还原,在数据同步领域实现批流一体,常用于需要做实时备份的数据迁移场景。
比如在金融领域,业务库出于稳定性考虑,无法直接面向各种上层应用提供数据查询服务。这时候就可以将业务数据实时迁移至外部数据库,由外部数据库再统一对外提供数据支撑。
新增功能说明:支持存量数据同步+增量日志还原的一体化任务,支持 MySQL—>MySQL/Oracle,在创建实时采集任务时,开启【数据还原】,还原范围选择【全量+增量数据】。
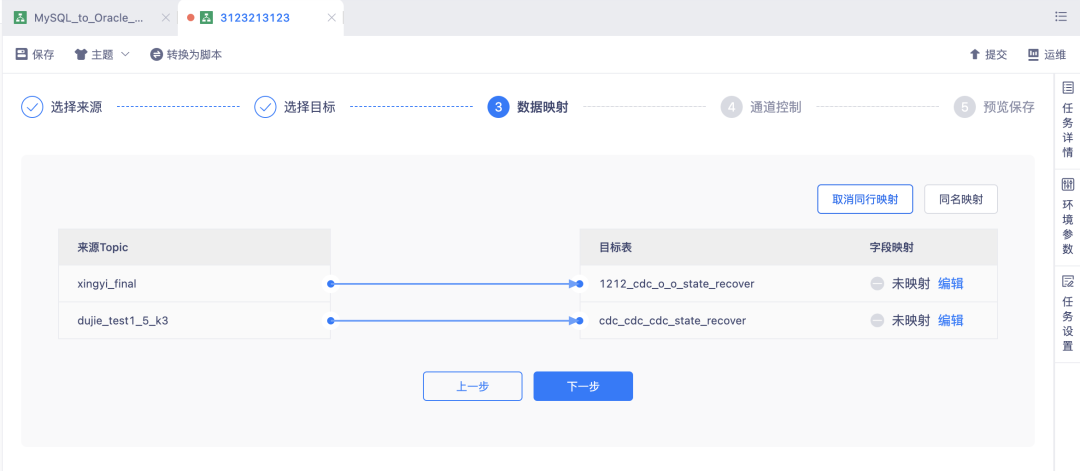
2.【数据还原】支持采集 Kafka 数据还原至下游
背景:当用户对 Kafka 数据没有实时加工的需求,只希望能将 kafka 消息还原至下游数据库对外提供数据服务时,可以通过实时采集配置化的方式,批量完整此类采集还原任务,不需要一个个的维护 FlinkSQL 任务。
新增功能说明:支持将 Kafka(OGG格式)数据,采集还原至下游 MySQL/Hyperbase/Kafka 表,在创建实时采集任务时,源表批量选择 Kafka Topic,目标表批量选择 MySQL 表,再完成表映射、字段映射。
3.任务热更新
背景:目前对于编辑修改实时任务的场景,操作比较繁琐。需要在【数据开发】页面完成编辑后,先到【任务运维】处停止任务,然后回到【数据开发】页面提交修改后的任务,最后再回到【任务运维】页面向 YARN 提交任务。
新增功能说明:当前更新后,支持修改「环境参数」、「任务设置」后,在数据开发页面提交任务后,任务运维处自动执行「停止-提交-续跑」操作。
4.数据源
新增 ArgoDB、Vastbase、HUAWEI ES作为 FlinkSQL 的维表/结果表,均支持向导模式。
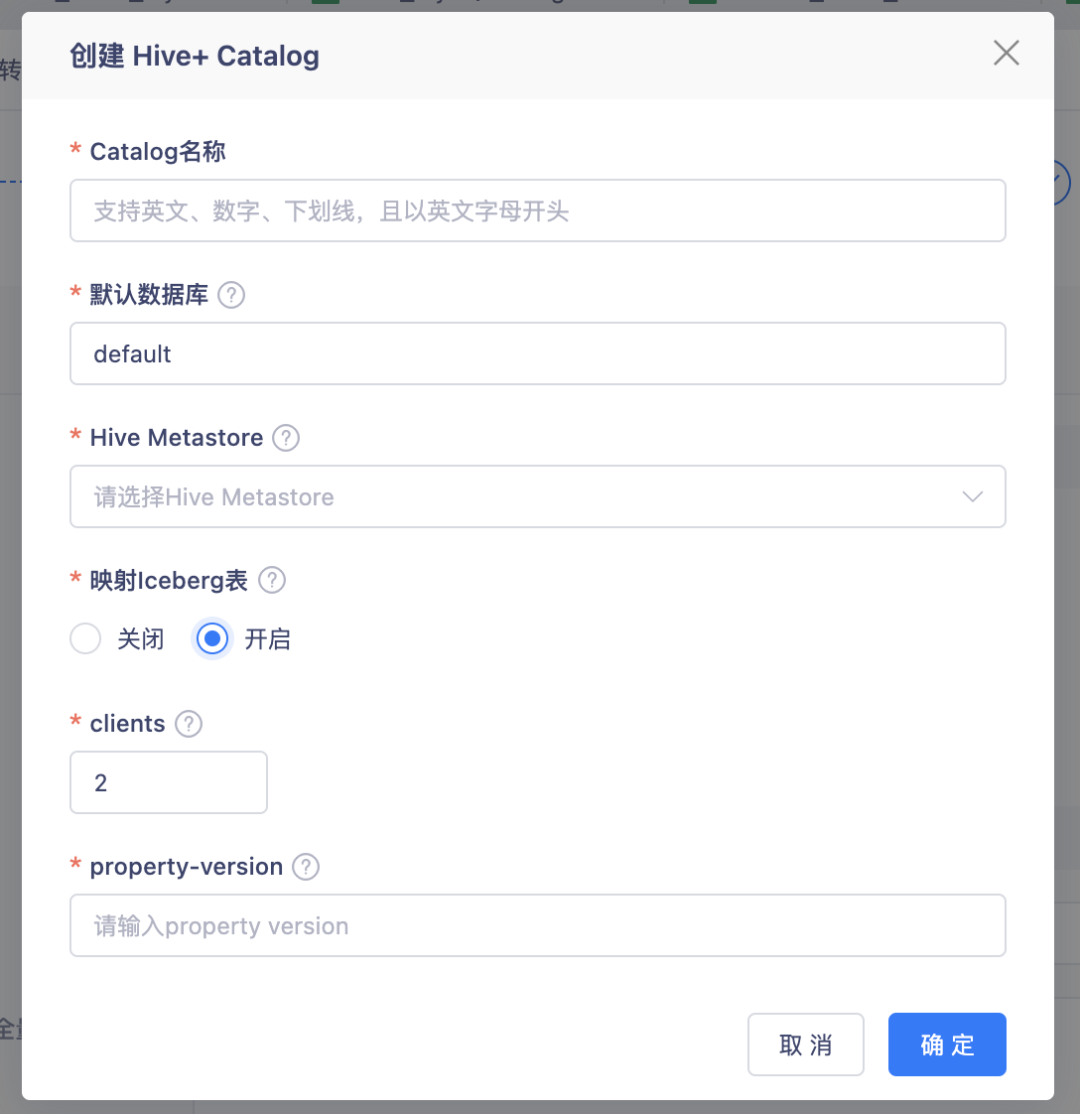
5.【表管理】合并原有的 Hive Catalog 和 Iceberg Catalog
背景:这两类 Catalog,实际都是依赖 Hive Metastore 做元数据存储,Iceberg Catalog 只需要在 Hive Catalog 基础上,开启额外的一些配置项即可,所以将这两类 Catalog 做了合并。
体验优化说明:创建 Hive Catalog,可以选择是否开启 Iceberg 表映射,如果开启了,在这个 Catalog 下创建 Flink Table 时,只支持映射 Iceberg 表。
6.【任务运维】优化任务停止时的状态说明
背景:在保存 Savepoint 并停止任务时,因为 Savepoint 文件可能会比较大,保存时间需要比较久,但是状态一直显示「停止中」,用户无法感知停止流程。并且如果保存失败了,任务依然会一直显示「停止中」,任务状态不符合实际情况。
体验优化说明:在保存 Savepoint 并停止任务时,「停止中」状态会显示当前持续时间,以及保存失败的重试次数。当最终保存失败时(代表任务停止失败),此时任务会自动恢复至「运行中」状态。

7.【启停策略】创建启停策略时,支持强制停止配置项
背景:目前创建的启停策略,默认都是执行保存 savepoint 的逻辑。但是当保存失败时,任务不允许自动做出选择帮用户丢弃 savepoint 进行强制停止,所以我们将这个的选择权,放给了用户。
体验优化说明:创建启停策略,有个强制停止的开关。

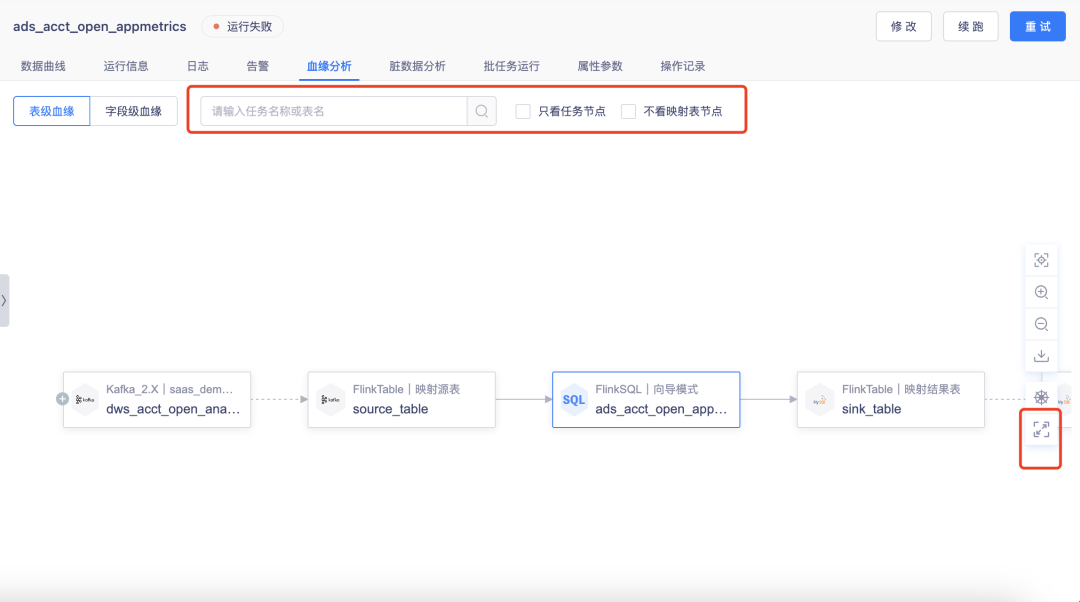
8.血缘解析
支持过滤链路节点类型,支持全屏查看,支持搜索,任务节点支持查看状态。
9.系统函数
更新内置的系统函数,同步 Flink 官方内容。 
10.其他优化项
· 数据还原:开启数据还原的实时采集任务,支持生成 Checkpoint 并续跑
· UI5.0:更新 UI5.0 前端样式
数据资产平台
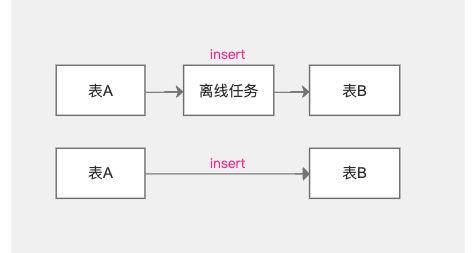
1.【血缘问题】冗余血缘移除
背景:当前现状当存在血缘关系时,会生成两条血缘关系,此问题需要解决,否则全链路会产生非常多的冗余血缘。
体验优化说明:只展示一条血缘。
2.【血缘问题】关键字支持
· 当表发生 delete、drop、trancate 数据清空时,表与表之间、表与任务之间的血缘关系删除
· 当任务下线、删除时,表与表之间血缘依旧存在,表与任务之间的血缘关系删除
3.【血缘问题】重合数据源
背景:标签指标对接的是 trino 引擎,离线对接的是 sparkthrift,如果不解决唯一性问题,无法串联全链路血缘。
体验优化说明:不同链路间的血缘不相互影响,但是汇总成同一链路展示。
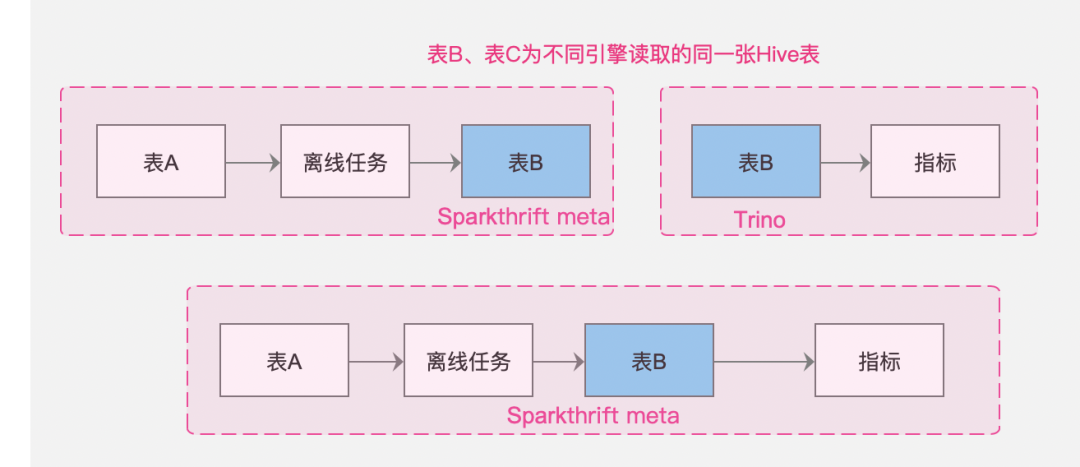
4.【血缘问题】数据源唯一性区分
· 不同的引擎读取同一张控制台的 hive 表(如sparkthrift、trino)
· 数据源中心建立的不同的数据源,其实是同一个数据库
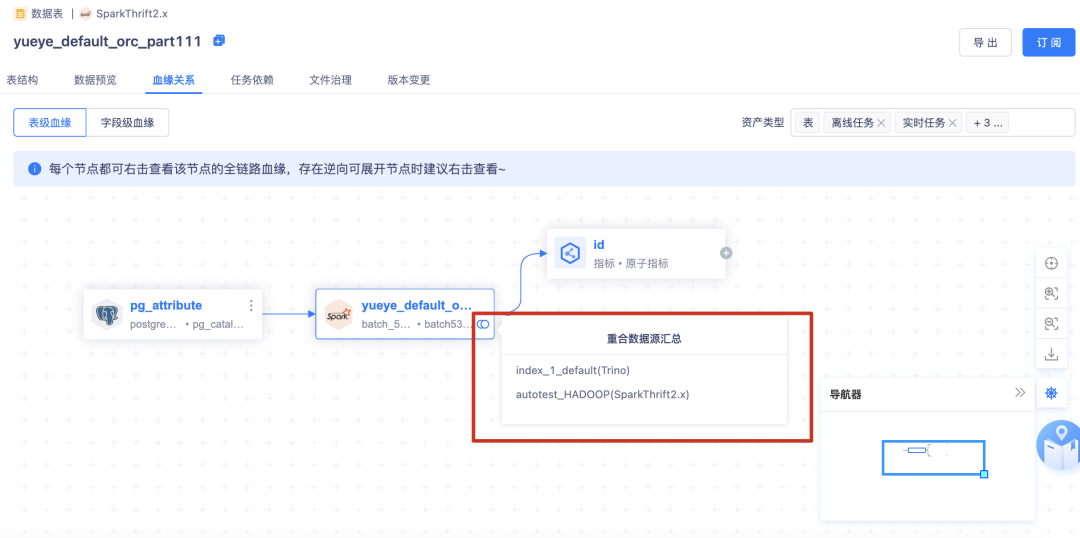
5.【全链路血缘】表→指标
数据资产平台已初步实现数栈内部全链路血缘关系的打通,包括表、实时任务、离线任务、API、指标、标签。
表→指标:
• 根据指标平台的【指标的生成】记录【表→指标】之间的血缘关系
• 指标的生成包括【向导模式】、【脚本模式】
• 指标平台如果有变动,比如删除、下线了某个指标,资产平台需要更新血缘视图
• 支持指标的字段血缘解析
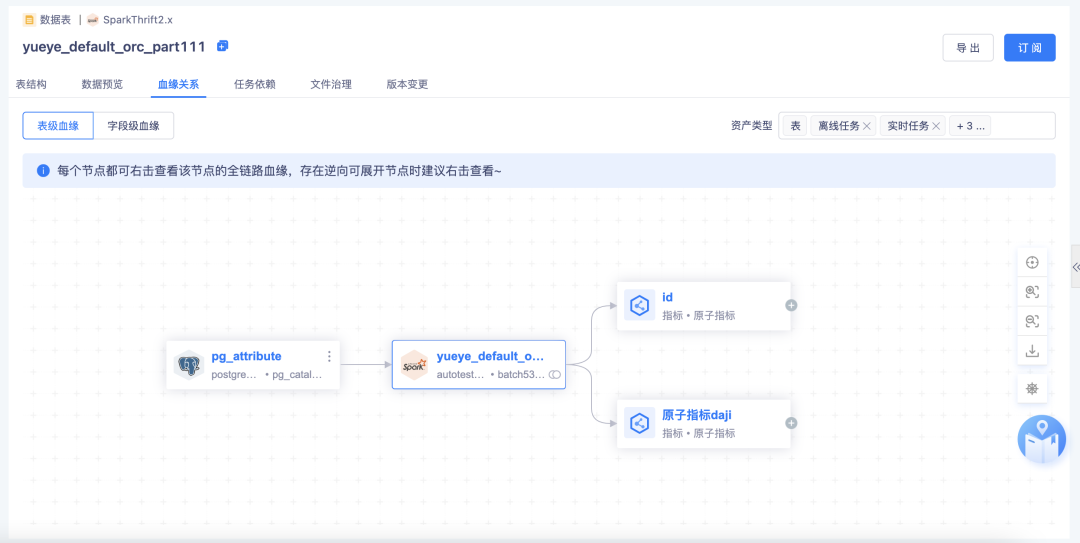
6.【全链路血缘】表→标签
· 根据标签平台的【标签的生成】记录【表→标签】之间的血缘关系
· 标签通过实体和关系模型创建,实体中需要关联主表和辅表,关系模型中有事实表和维表,并且关系模型可存储为实际的物理表,因此血缘链路包括数据表、标签
· 标签平台如果有变动,比如删除、下线了某个标签,资产平台需要更新血缘视图
· 支持标签的字段血缘解析 
7.【全链路血缘】实时任务
· 任务类型有两种:实时采集任务和 FlinkSQL 任务,FlinkSQL 任务存在字段血缘关系
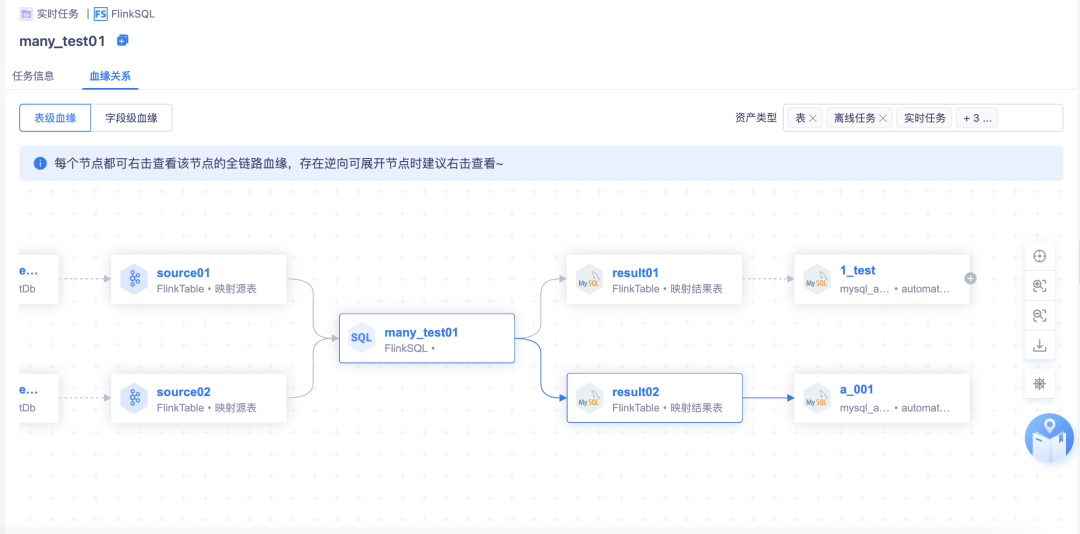
· 支持 kafka 侧的血缘关系展示

8.血缘展示优化
· 右上角筛选项:优化为多选菜单,表、离线任务、实时任务、API、标签、指标(默认选中全部维度,当前进入的维度选中且不可取消)
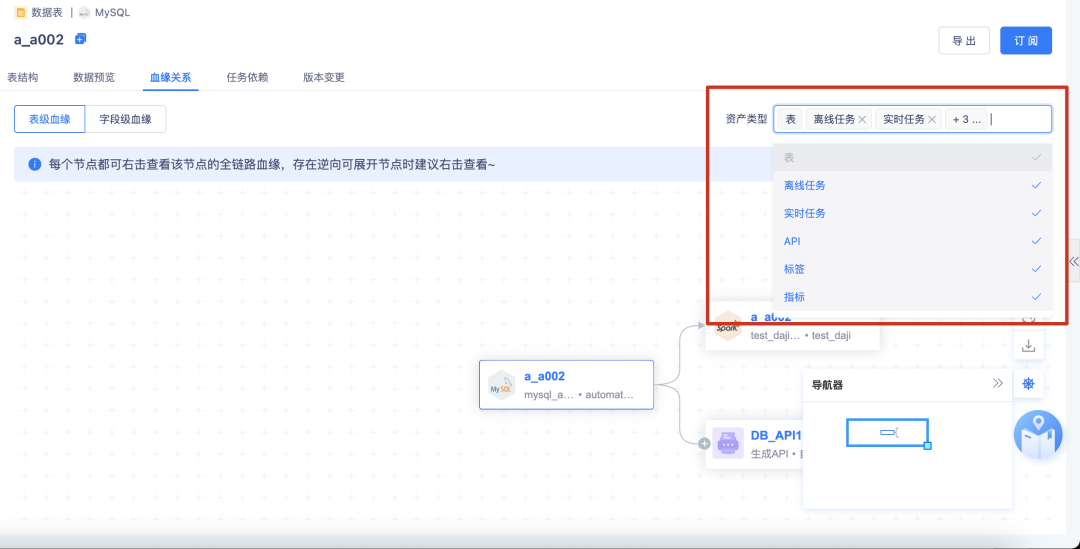
• 字段血缘:不展示右上角的筛选项
• 逆向血缘全局提示:
a.进入血缘关系页面,进行全局提示:“进入血缘每个节点都可右击查看该节点的全链路血缘,存在逆向可展开节点时建议右击查看~”
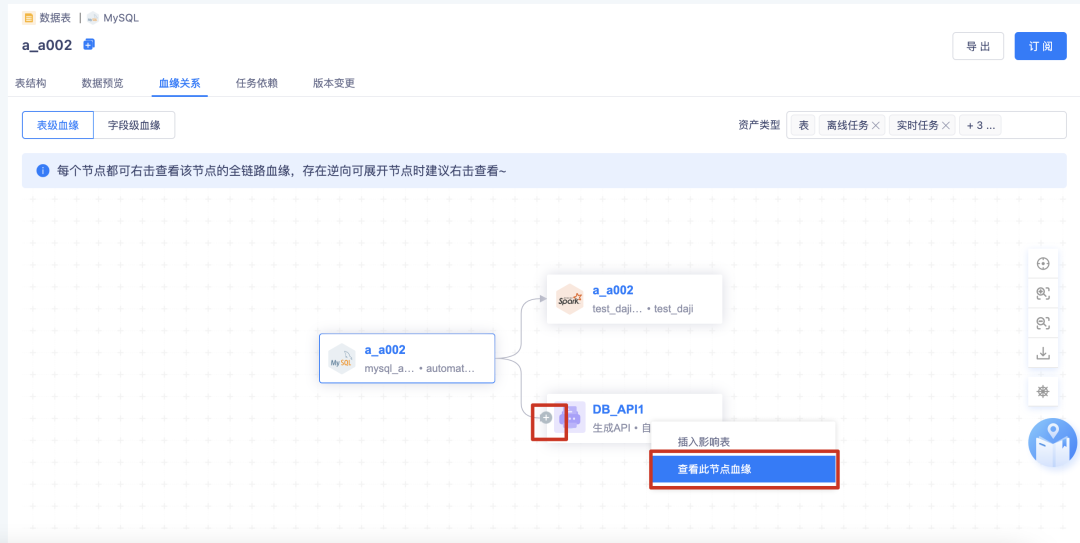
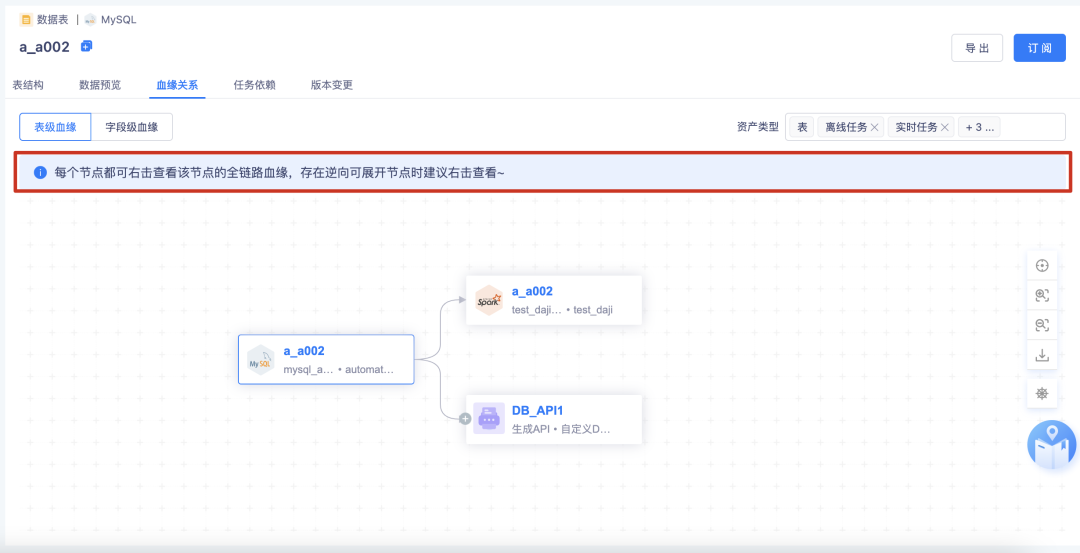 b.右击查看当前节点的血缘会更完整
b.右击查看当前节点的血缘会更完整
9.DatasourceX:【存储】、【表行数】逻辑优化
背景:直接从 metastore 读取是不准确的,之前 flinkx 是支持通过脚本更新存储和表行数,flinkx 升成 datasourcex 之后,相关 analyze 逻辑没有带过来。
体验优化说明:datasourcex 优化了对部分数据源的【存储】、【表行数】的脚本统计,包括 hive1.x、2.x、3.x(cdp/apache)、sparkthrift、impala、inceptor。
10.DatasourceX:【存储大小】【文件数量】更新逻辑优化
背景:数据治理新增了 meta 数据源的文件数量,又因为文件数量这个属性是 datasourcex 支持,普通的数据源也需要新增这个属性。
体验优化说明:datasourcex 对部分数据源的【存储大小】【文件数量】的脚本统计,数据治理结束后,更新【存储大小】【文件数量】逻辑。
11.前端页面升级
体验优化说明
• 资产盘点

• 元数据标签页面
• 元模型管理

• 分区优化

指标管理平台
1.【demo封装】demo功能优化
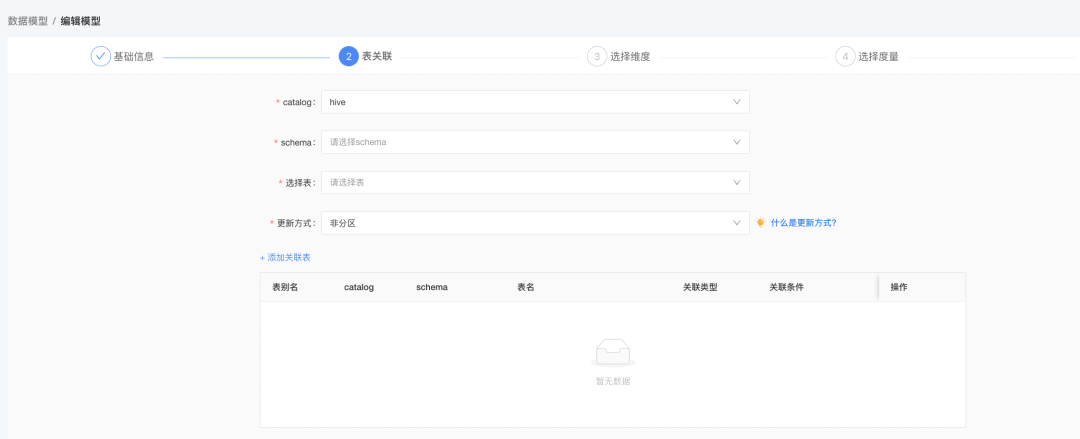
· 数据模型支持 catalog 选择,catalog 默认采用 DT_demo 租户下指标绑定的 trino 数据源对应的 catalog,schema 信息默认为 dt_demo。
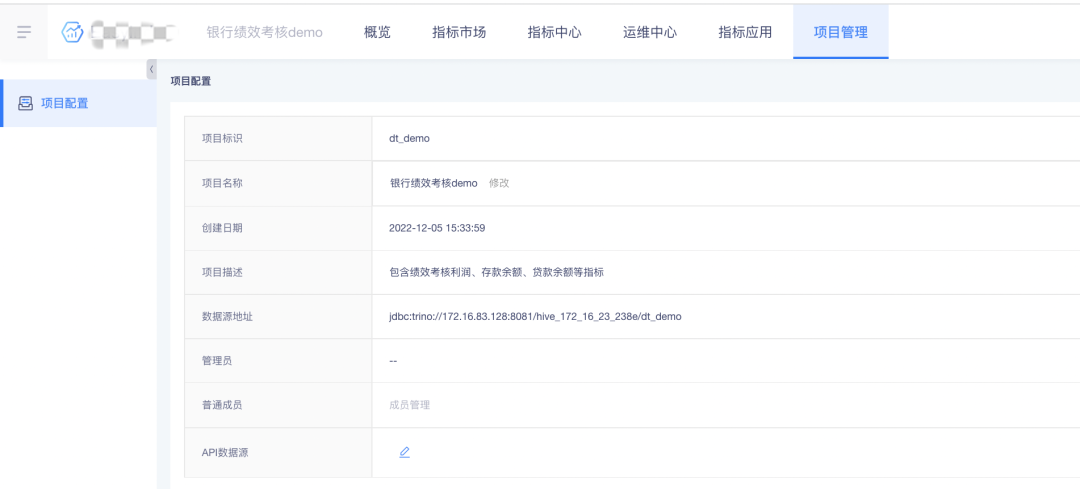
· 「项目管理」模块展示,支持查看项目配置信息,支持设置 API 数据源,但不支持正常项目中可编辑的其他功能的修改,以保障 demo 项目的正常使用。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn
同时,欢迎对大数据开源项目有兴趣的同学加入我们,一起交流最新开源技术信息,号码:30537511,项目地址:https://github.com/DTStack
这篇关于袋鼠云产品功能更新报告05期|应有尽“优”,数栈一大波功能优化升级!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





