本文主要是介绍前端数据可视化diango rest-framwork + vue,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HouseAnalysisWeb
项目地址GitHub
基于joint-spider爬虫数据的Web端数据可视化平台,在线访问
数据源来自项目 Joint-spider
后端: django-restframework
前端: Vue
应用技术
- Python 后端
- django-restframework
- redis
- mysql
- Web 前端
- Vue 全家桶
- echarts
- element-ui
- 百度地图
- Web服务API
- vue-baidu-map
环境配置及项目启动
# 环境配置需要 python3.7 redis mysql vue vue-cli3.x
#
# 项目启动
# 1. 后端服务启动,进入项目\HouseAnalysis\python manage.py runserver
# 2. 前端项目启动,进入项目目录\HouseAnalysisWeb\npm run dev
# 3. 前端项目打包npm run build-prod
# 4. 访问地址:http://localhost:9527/
# 5. 后端接口地址: http://localhost:8000/
项目持续改进中…
注意事项
- mysql及redis服务配置均在\HouseAnalysis\HouseAnalysis\settings.py文件中进行配置
- utils文件夹下文件功能:
- 插入数据分析结果信息至MySQL:Insert.py
- 插入基本总信息至Redis:insertRedis.py
- 插入区划及小区信息至MySQL:com_pro.py
前端页面展示
- 房源信息页面

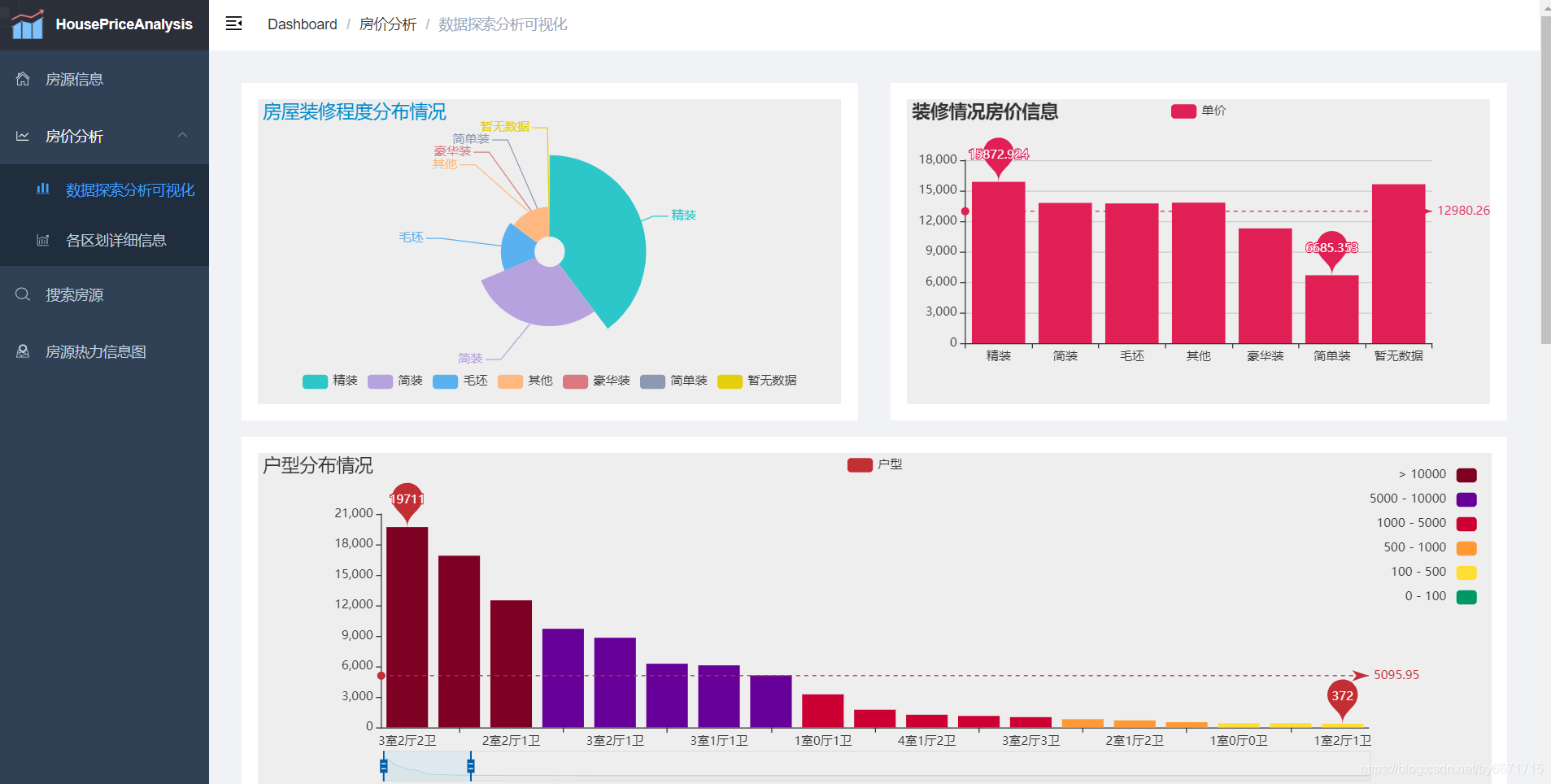
- 房价分析-数据探索分析可视化页面
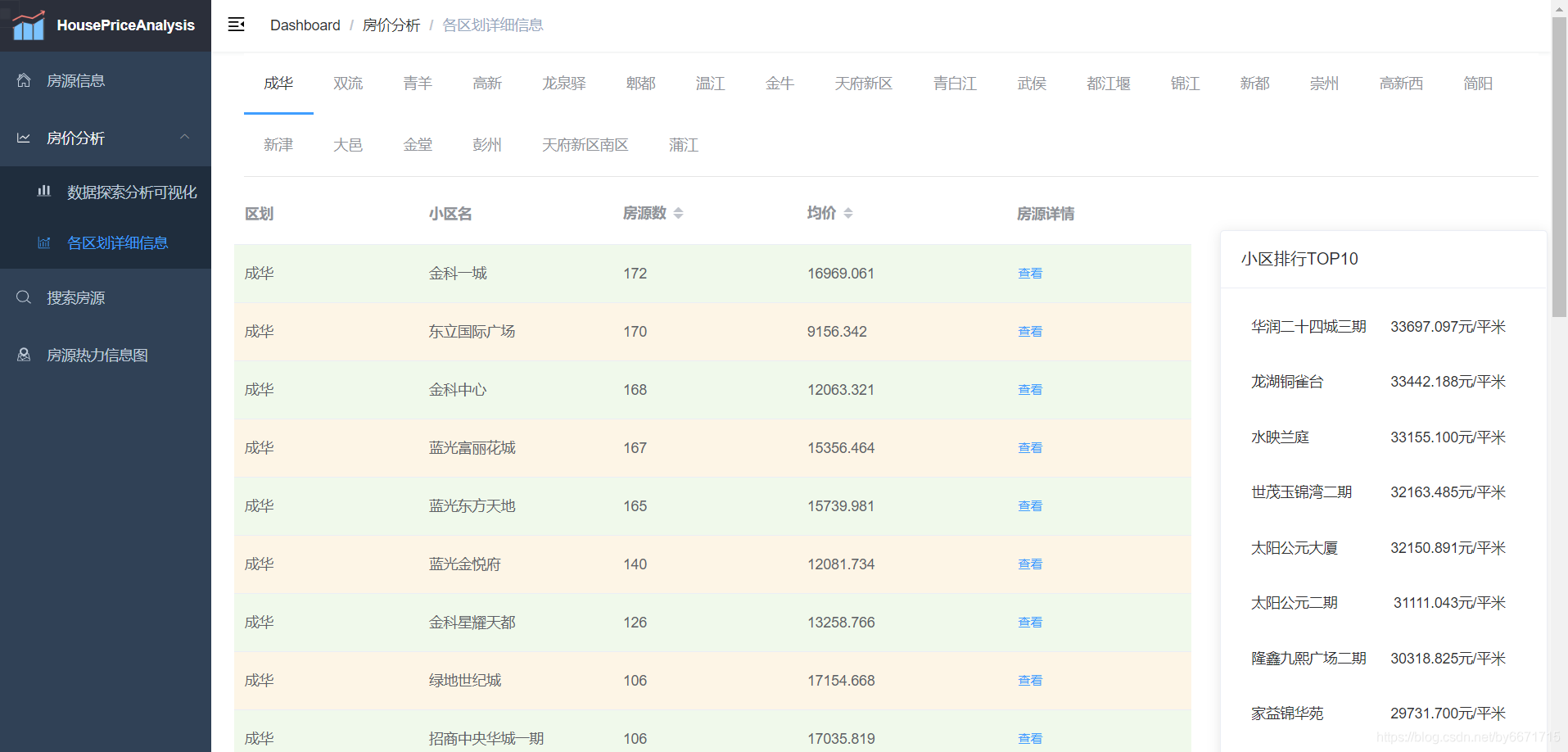
- 房价分析-各区划详细信息页面
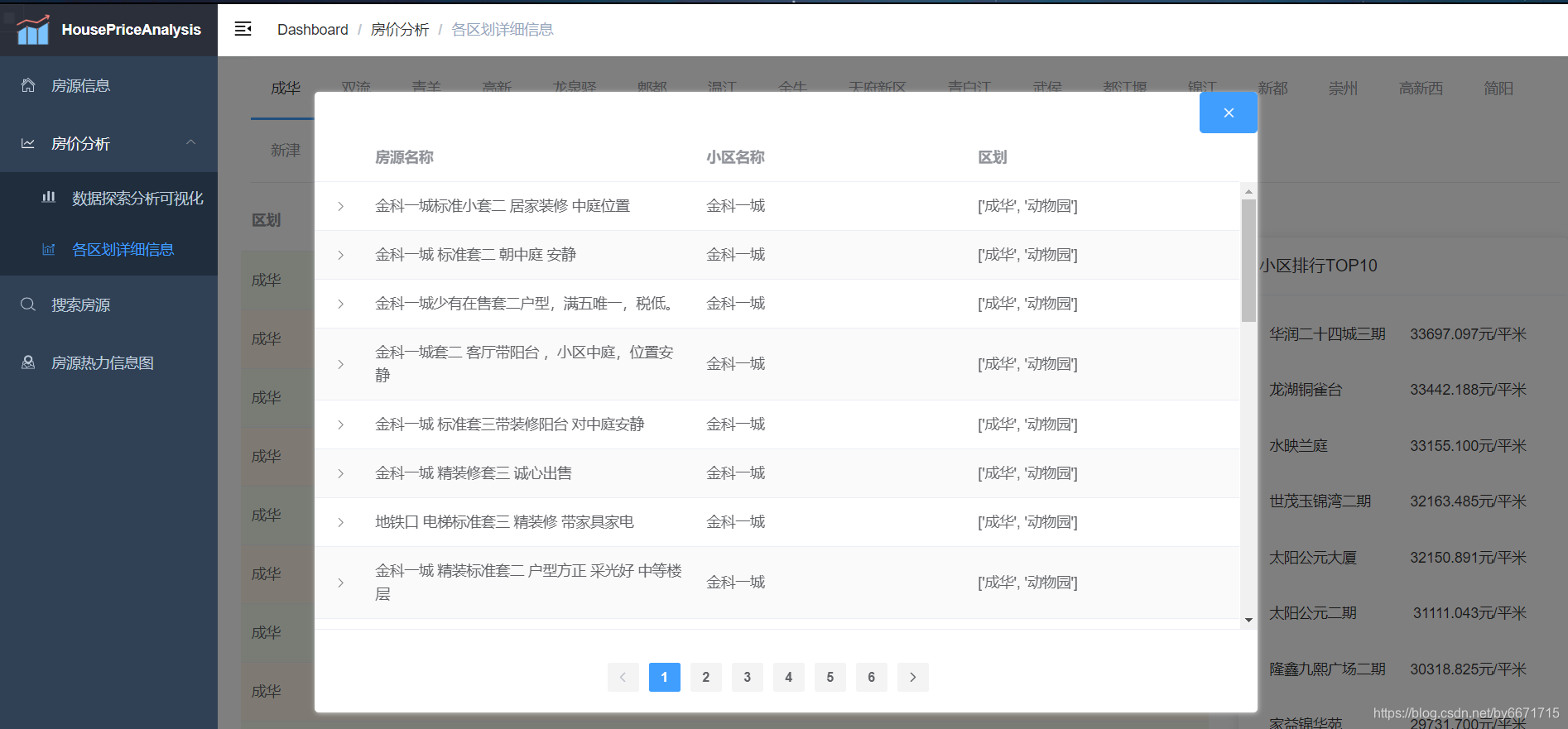
- 区划小区详情
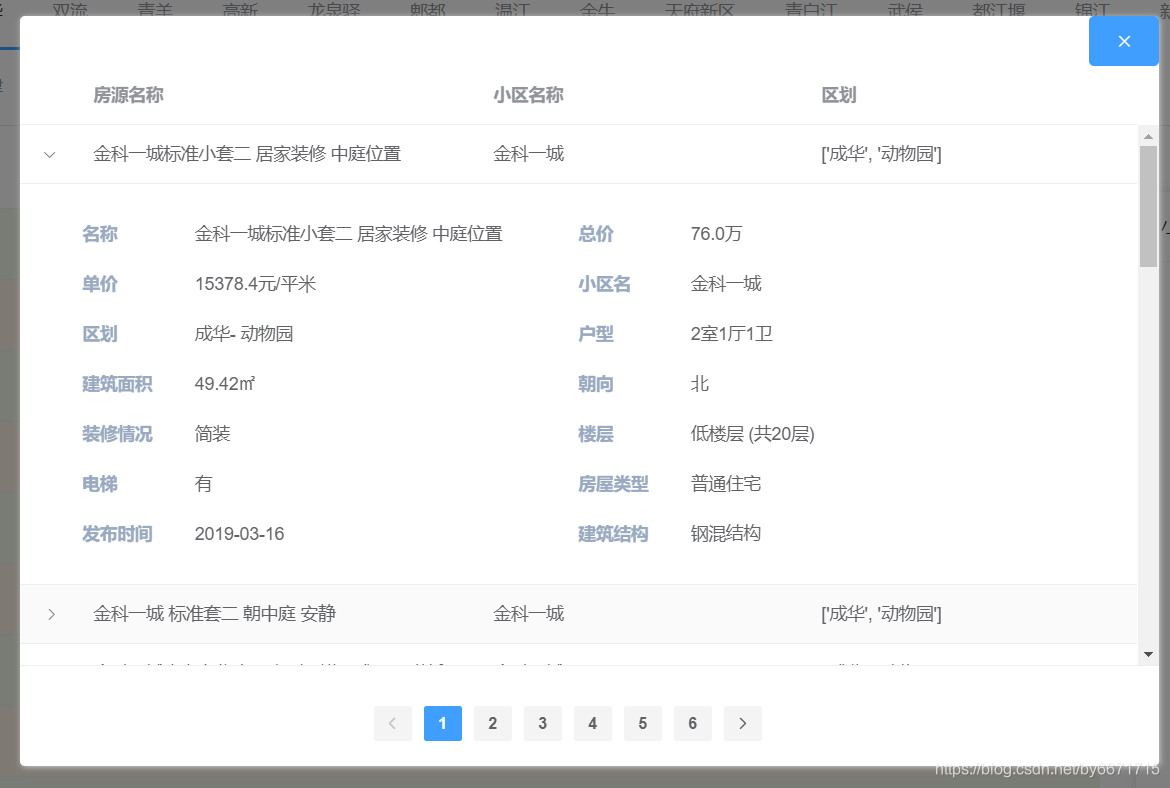
-
小区房源列表详情
-
搜索房源页面
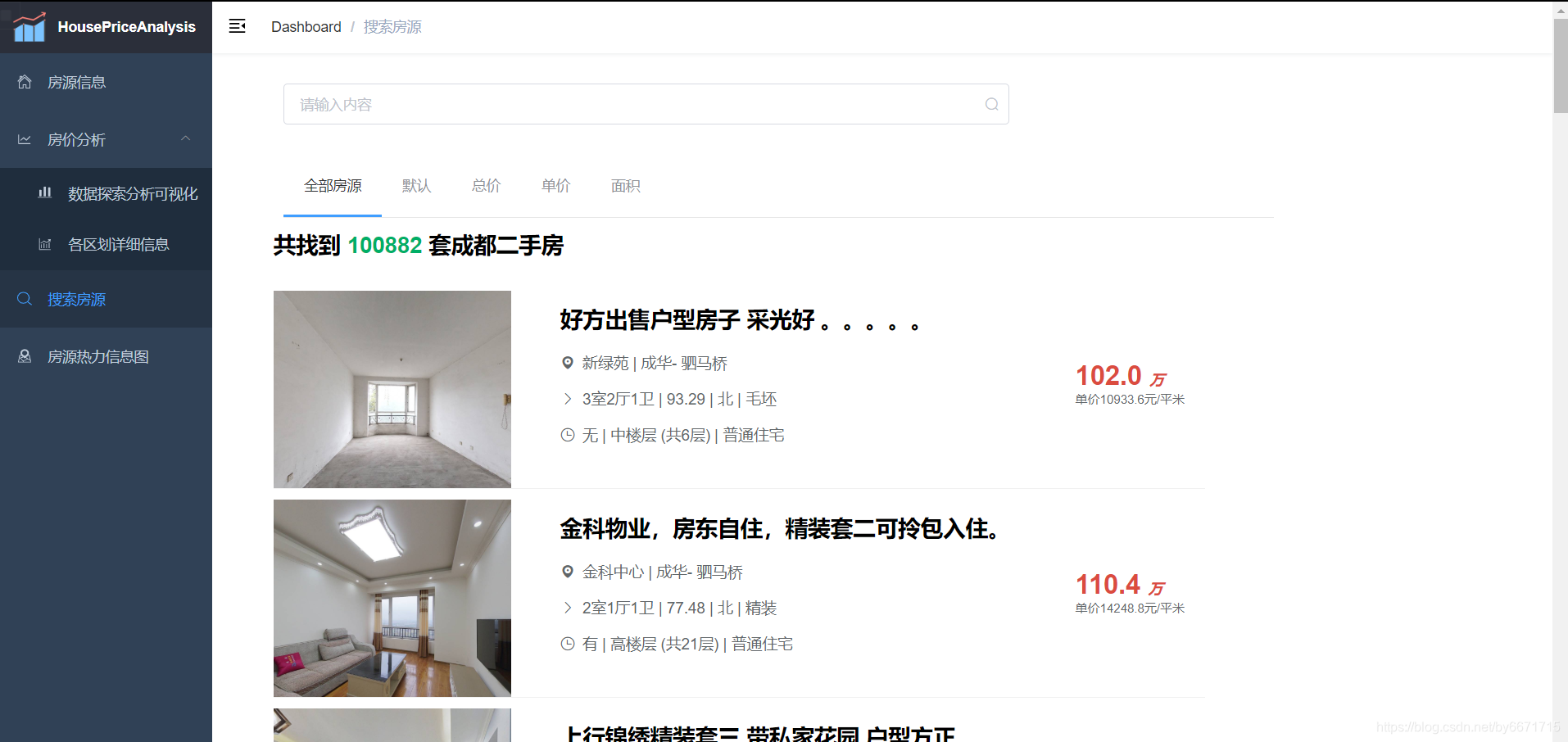
-
具体房源详情页面
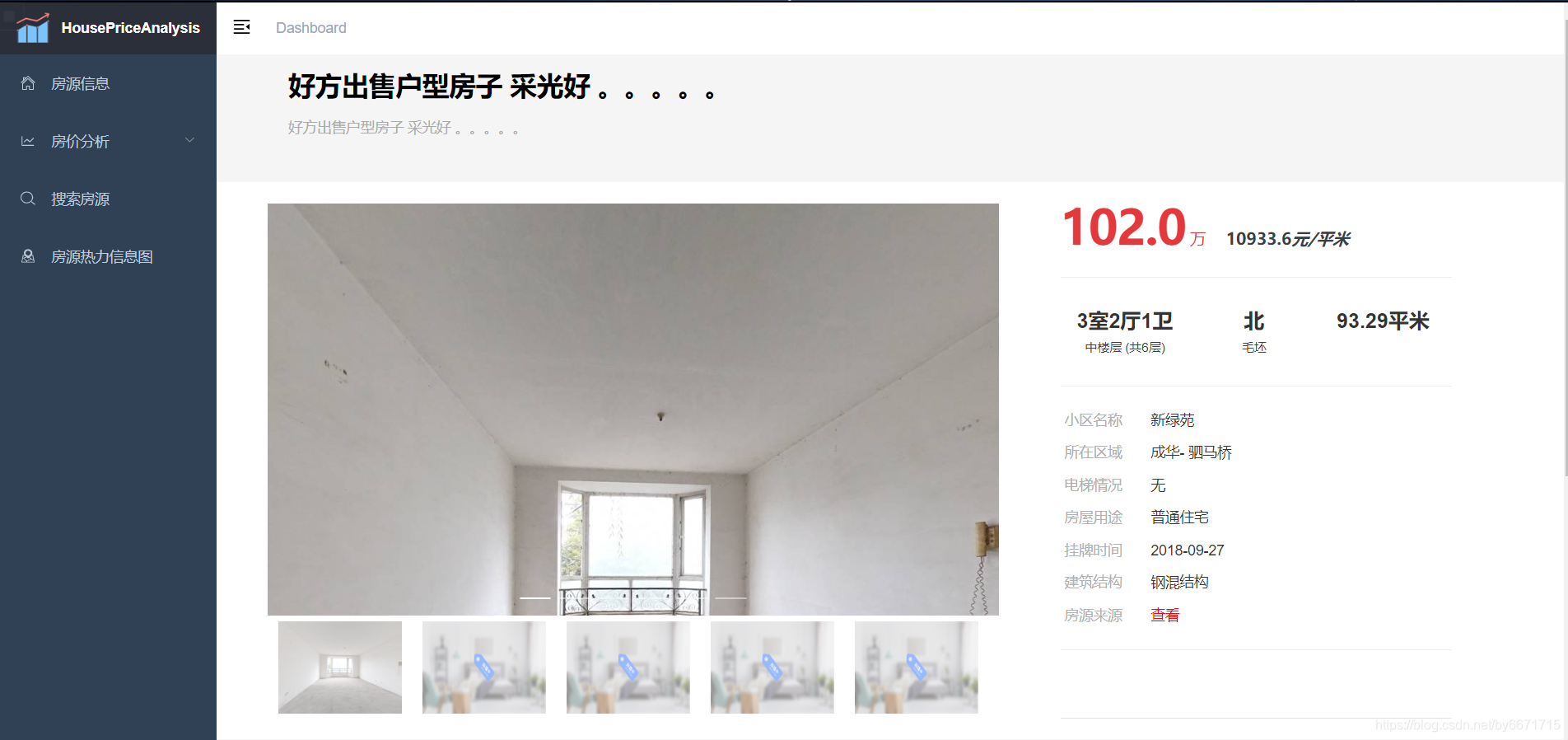
-
房屋周边
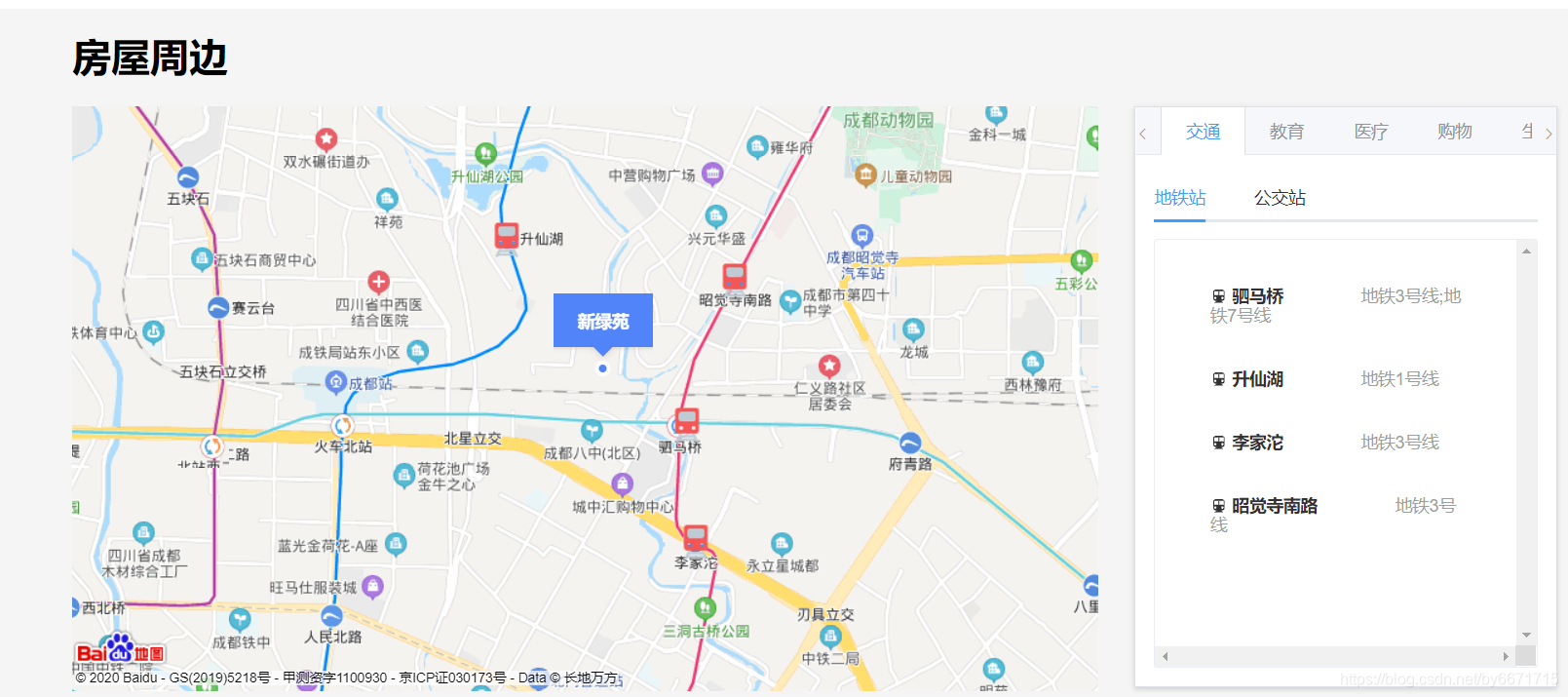
- 房源热力信息图页面
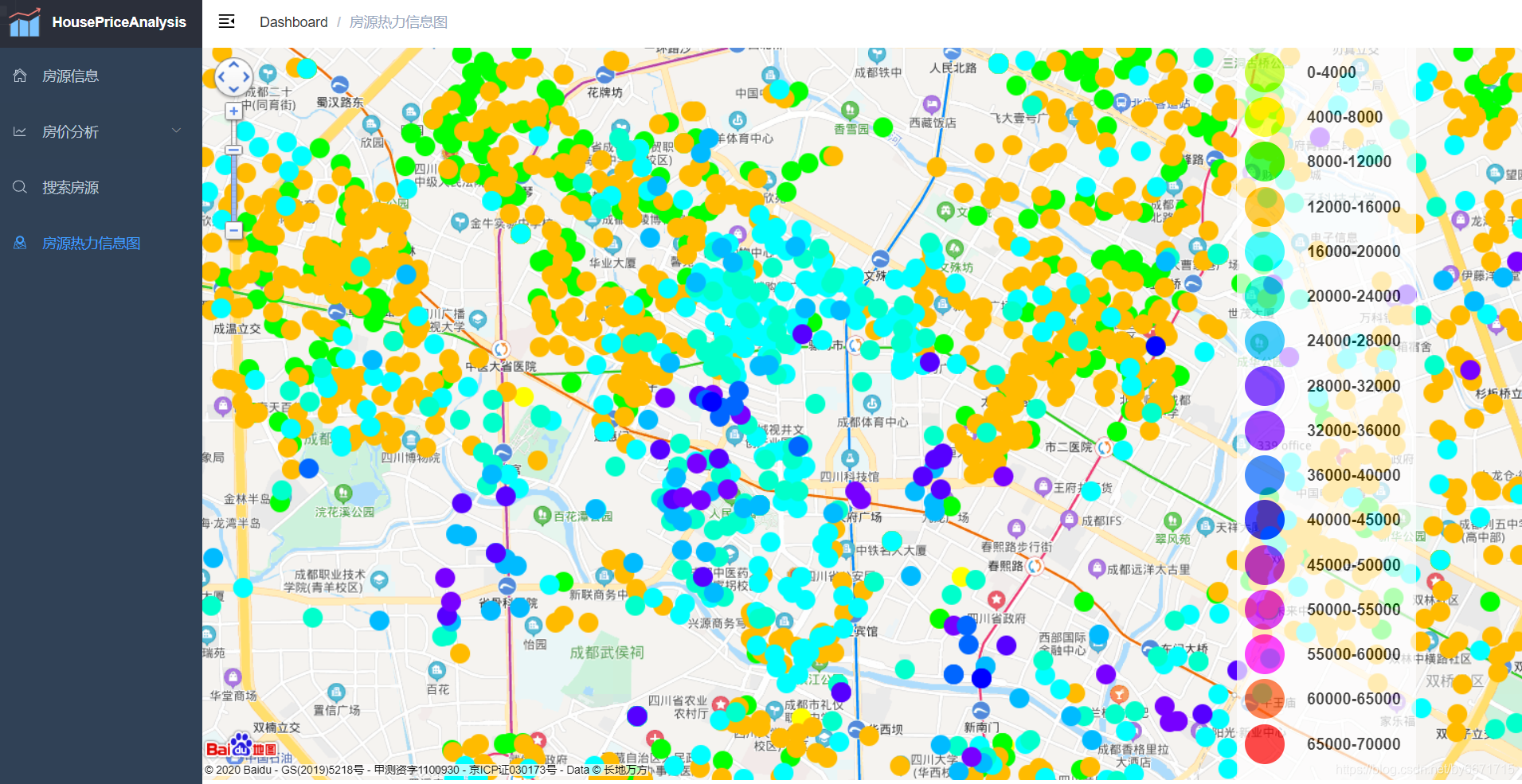
项目介绍:
一. 系统功能架构
- 后端
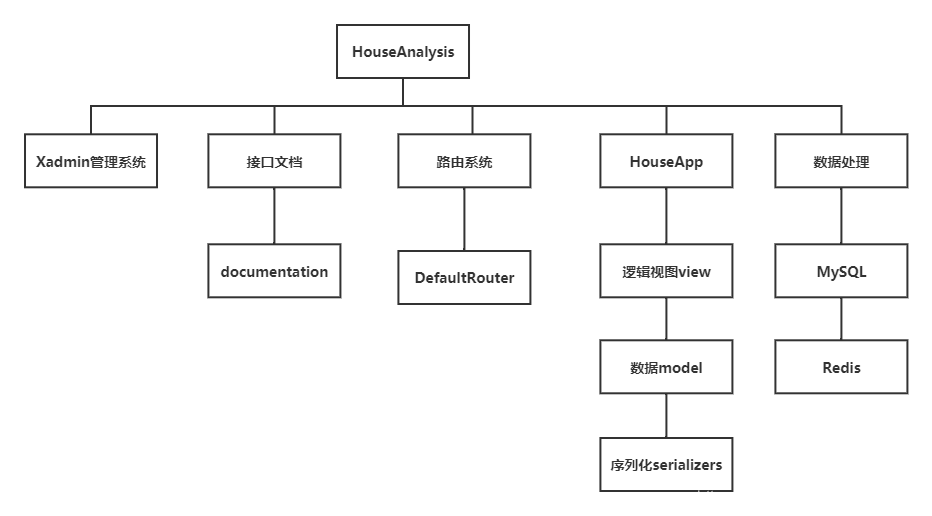
- 前端、
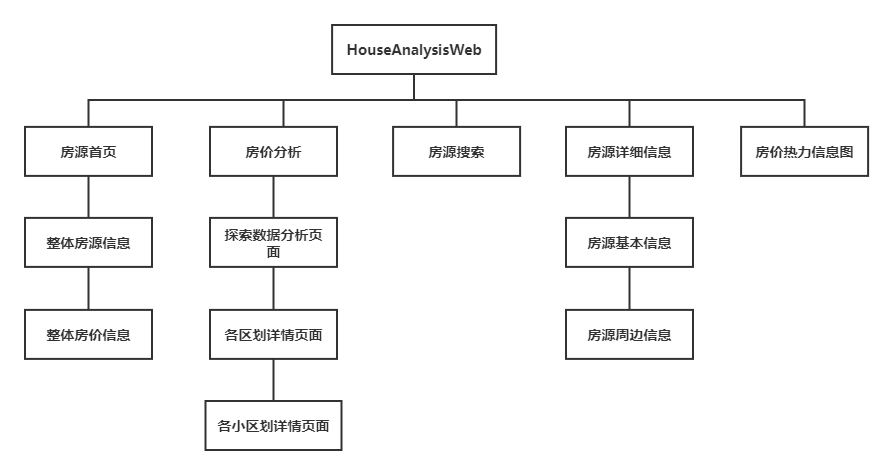
二. 系统实现
1) 后端部分
# 项目依赖
Django==2.1.5
django-cors-headers==2.4.0
django-crispy-forms==1.7.2
django-filter==2.0.0
django-formtools==2.1
django-guardian==1.4.9
django-import-export==1.1.0
django-redis==4.10.0
django-reversion==3.0.2
djangorestframework==3.9.0
djangorestframework-jwt==1.11.0
drf-extensions==0.4.0
PyMySQL==0.9.3
redis==3.0.1
SQLAlchemy==1.3.2
基本流程
-
Django生命周期:
前端发送请求–>Django的wsgi–>中间件–>路由系统–>视图–>ORM数据库操作–>模板–>返回数据给用户
-
rest framework生命周期:
前端发送请求–>Django的wsgi–>中间件–>路由系统_执行CBV的as_view(),就是执行内部的dispath方法–>在执行dispath之前,有版本分析 和 渲染器–>在dispath内,对request封装–>版本–>认证–>权限–>限流–>视图–>如果视图用到缓存( request.data or request.query_params )就用到了 解析器–>视图处理数据,用到了序列化(对数据进行序列化或验证) -->视图返回数据可以用到分页
项目文件树:
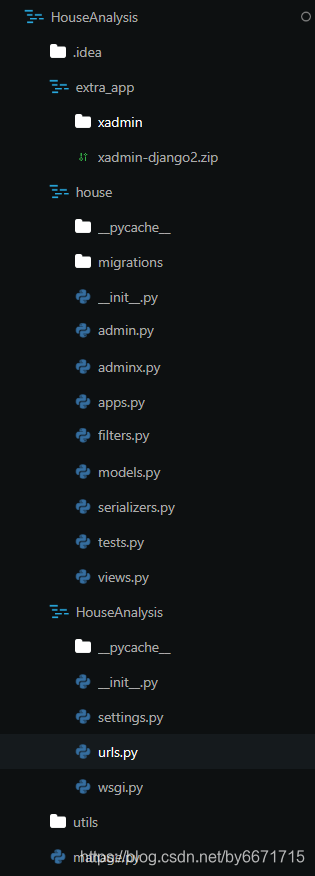
- 基本接口框架搭建
# 1. 初始化项目
django-admin startproject HouseAnalysis
# 2. 创建相关应用
cd HouseAnalysis
django-admin startapp house
- 配置xadmin后台可视化管理系统
# 项目根目录下创建extra_app 文件夹,存放xadmin压缩文件,运行
pip3 install xadmin
- 配置基本项目信息
# 1. 配置settings.py 文件 位于\\HouseAnalysis\HouseAnalysis\settings.py
# 找到INSTALLED_APPS,加入配置项'corsheaders','xadmin','crispy_forms','rest_framework','django_filters','house'
# 上述配置向是用于将app注册到项目中
# 2. 增加跨域支持
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_ALLOW_ALL = True
CORS_ORIGIN_WHITELIST = ('*'
)
CORS_ALLOW_METHODS = ('DELETE','GET','OPTIONS','PATCH','POST','PUT','VIEW',
)
CORS_ALLOW_HEADERS = ('XMLHttpRequest','X_FILENAME','accept-encoding','authorization','content-type','dnt','origin','user-agent','x-csrftoken','x-requested-with','Pragma',
)
# 3. 在DATABASES中配置MySQL数据库信息
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'house','USER': 'root','PASSWORD': '123456','HOST': '127.0.0.1','PORT': '3306','OPTIONS':{'init_command':"SET sql_mode='STRICT_TRANS_TABLES'"},}
}
# 4. 配置drf缓存
REST_FRAMEWORK_EXTENSIONS = {#10s后失效'DEFAULT_CACHE_RESPONSE_TIMEOUT': 10
}
# 5. 配置redis缓存
CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379/3","OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient",}}
}
注:本项目为接口开发不涉及template模板及static静态资源,所以不用对这两项进行配置
- 配置接口文档
进入\HouseAnalysis\HouseAnalysis\urls.py,配置路由信息:
添加path('xadmin/', xadmin.site.urls),
re_path(r'docs/', include_docs_urls(title="HA")),到urlpatterns列表,xadmin为管理页面路由,
docs为接口文档路由,通过http://localhost:8000/docs/可进行访问,如下图:
- 数据model设计
Django Model设计是Django五项基础核心设计之一(Model设计,URL配置,View编写,Template设计,From使用),也是MVC(MVT)模式中重要的环节。
Model是数据模型,并不是数据库,它描述了数据的构成和他们之间的逻辑关系,在Django中,Model设计实质上就是一个类。每一个模型都映射一张数据库表。
- 每个模型都是一个 Python 的类,这些类继承 django.db.models.Model;
- 模型类的每个属性都相当于一个数据库的字段;
- 利用这些,Django 提供了一个自动生成访问数据库的 API;
进入\HouseAnalysis\house\models.py ,添加Api,Elevator,Floor,Layout,Region,Decortion,Purposes,Orientation,Constructure,Community,CommunityRange模型,用以提供数据进行序列化。
model创建完成后进行数据迁移:
# 进入项目根目录
python manage.py makemigrations
# 同步至数据库
python manage.py migrate
- 序列化器设计
在house文件夹下新建文件serializer.py 文件,用来进行数据序列化。
定义序列化器(本质就是一个类),一般包括模型类的字段,有自己的字段类型规则。实现了序列化器后,就可以创建序列化对象以及查询集进行序列化操作,通过序列化对象.data来获取数据(不用自己构造字典,再返回Json数据)
-
用于序列化时,将模型类对象传入instance参数
-
用于反序列化时,将要被反序列化的数据传入data参数
-
除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据
这里我们使用模型序列化器(ModelSerializer),ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 基于模型类自动为Serializer生成validators,比如unique_together
- 包含默认的create()和update()的实现
例如:利用简单代码就可序列化house内容
class HouseSerializer(serializers.ModelSerializer):class Meta:# 需要序列化的modelmodel = Api# 需要序列化的字段fields = "__all__"
同理,将剩余的model序列化,包括ElevatorSerializer,FloorSerializer,LayoutSerializer,RegionSerializer,RegionS,CommunitySerializer,CommunityRangeSerializer,DecortionSerializer,PurposesSerializer,ConstructureSerializer,OrientationSerializer,其中,RegionS序列化器作为CommunitySerializer和CommunityRangeSerializer的上级序列化器。
- 视图View:
视图的功能:说白了就是接收前端请求,进行数据处理
(这里的处理包括:如果前端是GET请求,则构造查询集,将结果返回,这个过程为序列化;如果前端是POST请求,假如要对数据库进行改动,则需要拿到前端发来的数据,进行校验,将数据写入数据库,这个过程称为反序列化)
最原始的视图可以实现这样的逻辑处理,但是针对不同的请求,需要在类视图中定义多个方法实现各自的处理,这样是可以解决问题,但是存在一个缺陷,那就是每个函数中一般的逻辑都差不多:读请求,从数据库拿数据,写东西到数据库,返回结果给前端。这样就会产生大量的重复代码。
在开发REST API的视图中,虽然每个视图具体操作的数据不同,但增、删、改、查的实现流程基本套路化,所以这部分代码也是可以复用简化编写的:
增:校验请求数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
删:判断要删除的数据是否存在 -> 执行数据库删除
改:判断要修改的数据是否存在 -> 校验请求的数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
查:查询数据库 -> 将数据序列化并返回
视图编写在views.py 文件中,这里我们使用类识图的方式进行开发。
- 对于GET请求,我们需要返回一个列表,例如对于请求为:
http://127.0.0.1/api/v1/allhouse,我们需要将所有房源信息的序列化结果返回暴露出去。 - 对于GET/:ID请求,我们需要返回一个对用结果,例如对于请求为:
http://127.0.0.1/api/v1/allhouse/1,我们需要将房源id(此时的id可配置为指定需求参数)为1的序列化结果返回暴露出去。 - 对于POST请求,我们需要新建一条信息,例如对于post请求参数为:
{id:xxx,values:xxx...},我们需要当前信息做检验,合法后将当前数据添加到数据库中。 - 对于PATCH请求:更新某个指定房源的信息。
- 对于DELETE请求:删除某个房源信息。
例:
# CacheResponseMixin: 缓存,内存级别
# ListModelMixin处理GET(all)请求
# RetrieveModelMixin处理(id)请求
# 基础类GenericViewSet,提供分页,过滤,排序等功能
class HouseListViewSet(CacheResponseMixin, mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):queryset = Api.objects.all()# 房源序列化serializer_class = HouseSerializer# 房源分页pagination_class = HousePagination# 自定义排序,过滤类filter_backends = (DjangoFilterBackend, filters.SearchFilter, filters.OrderingFilter)# 过滤信息字段filter_fields = ('price',)# 搜搜字段search_fields = ('title', 'region', 'community_name')# 排序字段ordering_fields = ('price', 'unit_price','construction_area')# 重写retrieve方法,实现获取单个序列化对象信息def retrieve(self, request, *args, **kwargs):instance = self.get_object()serializer = self.get_serializer(instance)return Response(serializer.data)# 分页配置项
class HousePagination(PageNumberPagination):page_size = 30page_size_query_param = 'page_size'page_query_param = "page"max_page_size = 100
其他视图类似,包括:ElevaorViewSet,FloorViewSet,LayoutViewSet,RegionViewSet,CommunityViewSet,CommunityPagination,AllCommunityViewSet,CommunityRangeViewSet,DecortionViewSet,PurposesViewSet,ConstructureViewSet,OrientationViewSet
其中对于CommunityViewSet类,我们需要根据具体的community_id来返回其所有信息,这时就不能用RetrieveModelMixin类的retrieve方法了,需要重写get_queryset方法,返回特定的model。
def get_queryset(self):if self.request.GET['rid'] == '0' :# 获取所有return Community.objects.all()else:return Community.objects.filter(region=self.request.GET['rid'])
其他参数
- ?limit=10:指定返回记录的数量
- ?offset=10:指定返回记录的开始位置。
- ?page=2&per_page=100:指定第几页,以及每页的记录数。
- ?sort=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
- ?animal_type_id=1:指定筛选条件
- 路由配置
使用rest_framework的DefaultRouter进行路由注册:
from rest_framework.routers import DefaultRouter
router = DefaultRouter()
router.register(r'v1/api/all_house', HouseListViewSet, base_name="house")
......
将router加入到urlpatterns中:
path('', include(router.urls)),
这时当有请求访问到存在的路由后,路由会将请求转发到视图类,在视图类中将请求处理后,返回序列化结果,即后端暴露的接口数据。
- 关于接口数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JmH9EULX-1588257851195)(imgs/接口数据.png)]
数据描述
- count : 总数据量
- next: 下一页url
- previous: 上一页url
- results: 结果集
HTTP状态码:
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
- 关于具体数据处理-为了更方便序列化
- 将总体信息数据存放到Redis数据库中,减少后端处理请求是进行大量数据操作是运算量
# 将所有房源数,小区数,总体单价价均价,总体总价均价,存入redis
def insertIndexInfo():all_number = house.count()com_number = Api.objects.values('community_name').distinct().count()mean_price = format(house.aggregate(Avg('price'))['price__avg'],'.3f')mean_unit_price = format(house.aggregate(Avg('unit_price'))['unit_price__avg'],'.3f')data = {"all_number": all_number,"com_number": com_number,"mean_price": mean_price,"mean_unit_price": mean_unit_price}redis_conn.mset(data)
- 将处理好的数据存入MySQL,包括(电梯,装修情况等信息)
# 1. 定义专门数据库操作类InsertIntoMysql
class InsertIntoMysql():# 属性中定义sql语句获取数据def __init__(self):self.elevator_sql = 'select unit_price, price, elevator from house_api'# ......# 定义数据插入方法def insertElevator(self):index, values, price_mean, unit_price_mean = multiple(self.elevator_sql, engine, 'elevator')for i in range(len(index)):elevator = Elevator()elevator.version = 'v1'elevator.title = '电梯分布情况'elevator.has_ele = index[i]elevator.el_num = values[i]elevator.mean_price = price_mean[i]elevator.mean_unit_price = unit_price_mean[i]elevator.save()# 其他剩余数据插入方法# ......
# 2. 数据处理模块,包括单因子和对因子处理
# 利用数据处理模块pandas
def single(sql,engine,feature):""":param sql: sql语句:param engine: mysql引擎:param feature: 数据特征:return: 特征,数量"""df_sql = sqldf = pd.read_sql(df_sql, engine)df[feature] = df[feature].astype(str)if feature=='floor':df[df[feature]=='暂无数据'] = '18'df[feature] = df[feature].apply(lambda x: re.findall('\d+',x)[0])feature_res = df[feature].value_counts()index = feature_res.indexvalues = feature_res.valuesreturn index,valuesdef multiple(sql,engine,feature):""":param sql: sql语句:param engine: mysql引擎:param feature: 数据特征:return: 特征,数量,总价均价,单价均价"""df_sql = sqldf = pd.read_sql(df_sql, engine)df[feature] = df[feature].astype(str)if feature == 'region':df[feature] = df[feature].apply(lambda x:re.sub(r"\[|\]|'",'',x).split(',')[0])feature_res = df[feature].value_counts()index = feature_res.indexvalues = feature_res.valuesprice_mean = []unit_price_mean = []max_unit_price = []min_unit_price = []for inx,val in zip(index,values):price_mean.append(format(df[df[feature]==inx]['price'].astype(float).mean(),'.3f'))unit_price_mean.append(format(df[df[feature]==inx]['unit_price'].astype(float).mean(),'.3f'))max_unit_price.append(format(df[df[feature]==inx]['unit_price'].astype(float).max(),'.3f'))min_unit_price.append(format(df[df[feature]==inx]['unit_price'].astype(float).min(),'.3f'))return index, values, price_mean, unit_price_mean, max_unit_price, min_unit_price
2) 前端部分
前端使用基本框架Vue搭建,基于vue-admin-template开发。前端主要业务用于图表展示,地图信息,主要用于做成都二手房房价数据及相关信息可视化,包括总体信息展示,各项特征-如房屋装修情况等的图表信息可视化,房源搜索,基本房源信息可视化,地图展示等功能。
项目说明
- 关于地图模块,这里我们采用的是百度地图,使用之前,需要申请百度地图ak,用于我们的WebAPI服务
- 地图库使用开源vue-baidu-map库,并采取按需加载的方式,即在需要用到的页面才进行模块导入。
- 项目UI使用element-ui组件库,采用全局加载模式。
- 图表库使用echarts.js,采用按需加载的方式使用模块。
前端项目文件树:

- src目录为项目核心代码文件,所欲自定义工具,接口文件,页面文件都在这里面编写。
- test目录是项目测试文件,使用jest进行项目测试。
- public目录为公共资源文件。
- dist目录为项目开发完成后进行打包后自动生成的文件。
具体流程
- UI组件的使用
# 安装到项目
npm install -S element-ui# 全局加载: 在main.js中
import ElementUI from 'element-ui'
import 'element-ui/lib/theme-chalk/index.css'
import locale from 'element-ui/lib/locale/lang/en' // i18n
Vue.use(ElementUI, { locale })# 这样我们据可以在vue文件中使用UI组件,如: 按钮组件<Button />
- 地图组件使用
# 安装到项目
npm install -S vue-baidu-map# 局部加载: 在任意vue文件中
import BaiduMap from 'vue-baidu-map/components/map/Map.vue'
# 地图标注组件
import { BmMarker } from 'vue-baidu-map'# 使用,例如:<baidu-map ref="baidumap"class="bm-view"style="width:100%;height:93vh"ak="YOUR AK":center="{lng: 104.07, lat: 30.67}":scroll-wheel-zoom="true":zoom="16"><bm-navigation anchor="BMAP_ANCHOR_TOP_LEFT"></bm-navigation><bm-marker v-for="spoi in searchResults"--><!--:position="{lng: spoi.lng, lat: spoi.lat}"--><!--:title="spoi.community_name">--></bm-marker></baidu-map>
- 定义请求拦截-用于截获错误请求及超时请求等。
在src目录下新建文件夹utils,用于存放我们自定义的工具文件,新建requests.js,重新封装axios方法,满足我们请求接口时的操作。此文件将暴露一个用作异步请求的对象,做为更高级的接口访问方法,在接口文件设计中将使用此方法。
- 初始化
# 新建一个servie对象
const service = axios.create({// 项目基本配置文件中定义的VUE_APP_BASE_API,开发和发布环境各部相同,在.env.devolopment和.env.product文件中进行配置baseURL: process.env.VUE_APP_BASE_API,// 直接写死的url,无论环境如何都不会改变// baseURL: 'http://127.0.0.1:8000/v1/api',timeout: 8000 // 最大请求时间
})
- 请求拦截-发送请求时
service.interceptors.request.use(config => {// 请求方法为POST时,配置请求头config.method === 'post'? config.data = qs.stringify({ ...config.data }): config.params = { ...config.params }config.headers['Content-Type'] = 'application/x-www-form-urlencoded'return config
}, error => {// 错误时提示信息Message({message: error,type: 'error',duration: 3 * 1000})Promise.reject(error)
})
- 响应拦截-接收数据时
service.interceptors.response.use(response => {if (response.statusText === 'OK') {// 正确响应时,直接返回数据return response.data} else {Notification({title: '错误',message: '访问api错误', // TODO 后端拦截错误请求type: 'error',duration: 3 * 1000})}},// 错误处理error => {let dtext = JSON.parse(JSON.stringify(error))try {if(dtext.response.status === 404) {Notification({type: 'error',title: '出问题404',message: '访问api错误或服务器忙',duration: 3 * 1000})}} catch (err) {Notification({title: '错误',message: '请求超时,请稍后再试或刷新页面',type: 'error',duration: 3 * 1000})}return Promise.reject(error)}
)
- 最后一定要暴露service对象
export default service
- 前端路由配置
使用vue-router实现路由功能,在新建router.js,进行路由项配置。
// 定义路由列表
export const constantRoutes = [{path: '/404',component: () => import('@/views/404'),hidden: true},{path: '/',component: Layout,redirect: '/dashboard',children: [{path: 'dashboard',name: 'Dashboard',// 采用路由懒加载的方式component: () => import('@/views/dashboard/index'),meta: { title: '房源信息', icon: 'house' }}]},// ......]
// 构造路由对象
const createRouter = () => new Router({// mode: 'history', // require service supportscrollBehavior: () => ({ y: 0 }),routes: constantRoutes
})// 在main.js 中引入并挂载
import router from './router'
new Vue({el: '#app',router,render: h => h(App)
})- 接口函数编写
接口api.js文件中定义了所有与项目有关的接口访问请求,并封装成函数暴露出去,供组件使用。
// 例如获取区划信息接口
export function getRegionInfo(id,params) {return request({url: '/region/'+id,method: 'get',params})
}
其中request为上面封装好的接口访问对象,使用前需引入,组件中使用接口的时候,按需导入,例如:
// charts.js是接口函数文件
import { getRegionInfo } from '@/api/charts'// 使用
// 第一种方式,由于它本来就是一个promise对象,所以直接在then中获取响应
getRegionInfo(1).then((res,err)=>{// 相关操作
})
// 第二种方式,使用async await方式,包含await的方法中需要加上async 作为方法前缀
let res = await getRegionInfo(1)
- 项目页面编写

- dashbord为总体信息展示面班,也是页面入口
heatmap为热力图页面- house为房源搜索和基本信息展示页面
- map为房源地图分布图
- multiple为区划信息页面
- single为房源一系列数据可视化图表页
word为词云页
这篇关于前端数据可视化diango rest-framwork + vue的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





