本文主要是介绍HD.047 | 水文数据——全球植被数据集[V: VCI],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
植被作为影响联系土壤、大气、水分等地气要素的重要因素,其准确估算不仅对研究植被动态变化、植被物候过程具有重要意义,而且对于流域生态水文等方面具有十分重要的应用价值。目前已有大量全球植被数据产品,本期选取植被条件指数Vegetation Condition Index(VCI)数据集进行介绍。具体下载或处理步骤可参考Hydro90知乎相关技术帖(知乎平台将进行同步),往期数据集介绍可以通过当期推文最后目录进行跳转。
#1
VCI
植被条件指数
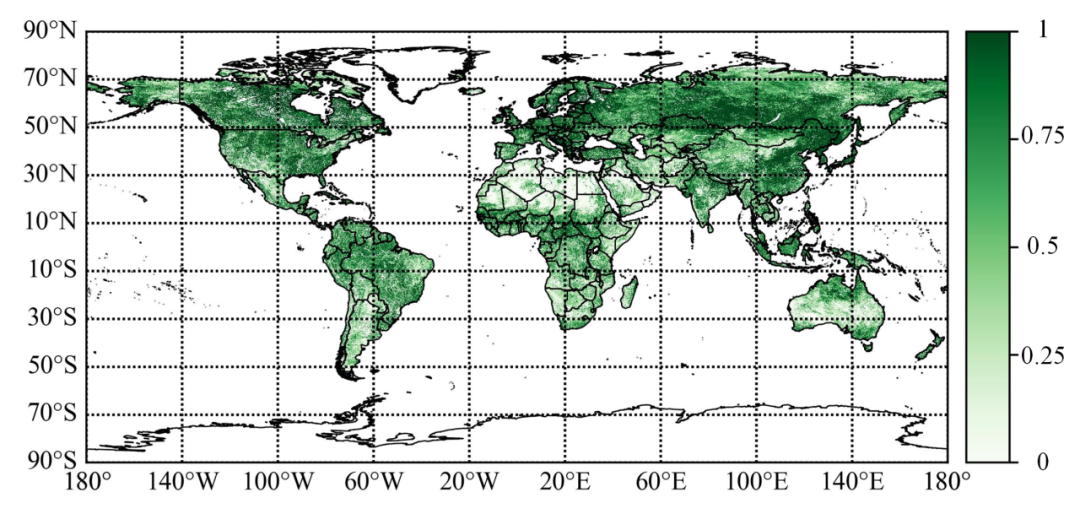
图1 2023年10月22日全球植被条件指数
数据简介
VCI指数来源于美国国家海洋和大气管理局(NOAA)卫星应用与研究中心(STAR)提供的全球和区域植被健康产品(VHP)数据集,该指数可以很好地反映植被生长状况与历史同期的比较,同时对干旱十分敏感,可减少或消除地理位置、生态系统和土壤条件对NDVI的影响,是大尺度干旱监测的理想指标,该指数越大代表植被生长越好。NOAA STAR提供的VCI指数空间分辨率分别有1km,4km和16km,本期推送将主要介绍空间分辨率为4km对应数据集的下载。
这篇关于HD.047 | 水文数据——全球植被数据集[V: VCI]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







