本文主要是介绍(详细步骤)使用scrapy爬取新浪热点新闻,进入链接获取新闻内容。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.在Pycharm的Terminal中输入“scrapy startproject news”创建爬虫项目,“news”为项目名。
2.自动生成的工程目录
3.编写item.py,也就是定义要爬取信息的字段

4.进入news/news/spiders目录下,使用命令“ scrapy genspider -t crawl newscrawl ‘news.sina.com.cn’ ”创建爬虫名为“newscrawl”的爬虫文件,爬虫域是“news.sina.com.cn”。

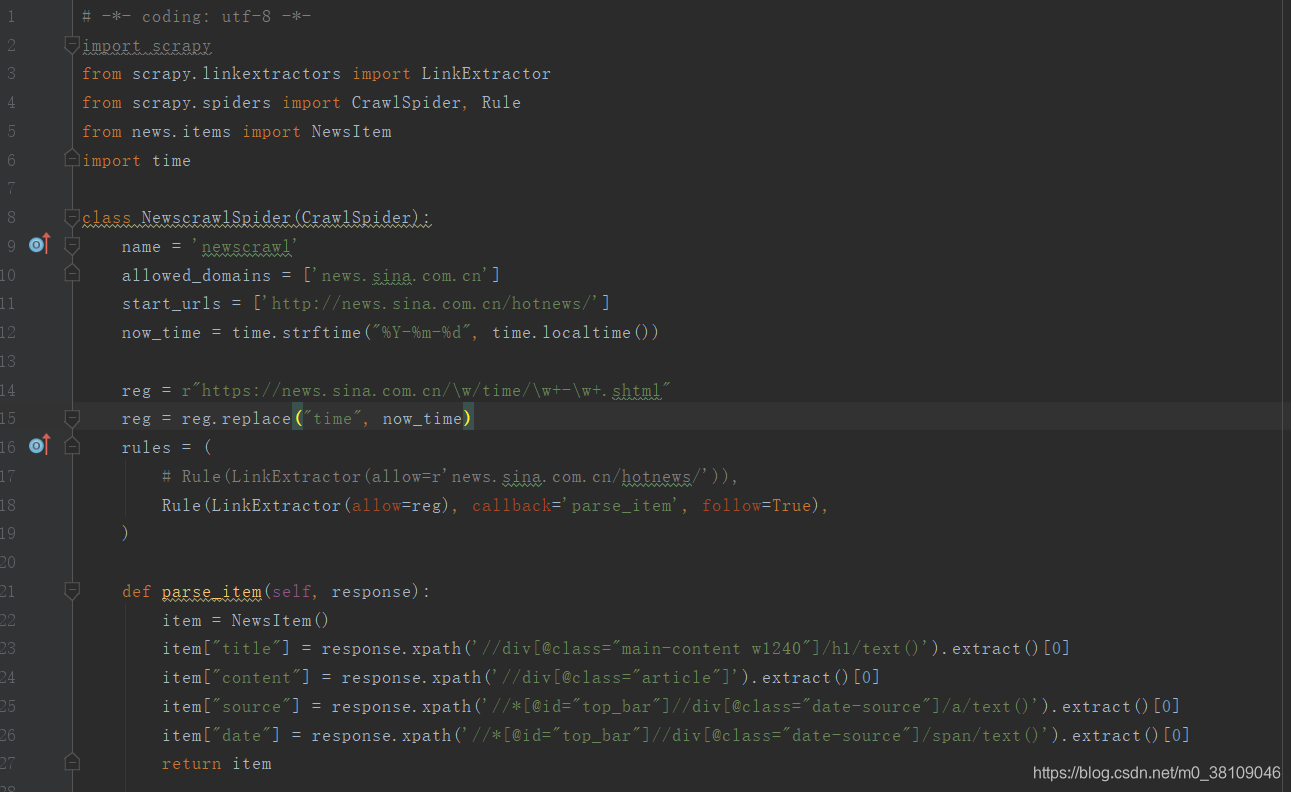
5.编写newscrawl.py文件。其中“https://news.sina.com.cn/\w/time/\w+-\w+.shtml”正则是用来匹配“http://news.sina.com.cn/hotnews/”页面上的链接的。注:可以查看链接的规律个性化定制。
xpath的匹配可以通过“xpath helper”插件来快速定位,或者通过chrome浏览器按F12检查网页代码,选中匹配的代码右击选择“copy xpath”获取匹配规则。
6.编写pipelines.py文件,处理爬取的数据。(此处是存入数据库)

7.在settings.py中将下图中的代码注释取消。

8.启动爬虫,在spiders目录下启动爬虫“scrapy crawl newscrawl”
9.任务结束后查看数据库。(因为数据库中newsContent字段在自己的项目中是用富文本编辑器展示的,所以将标签和内容一起爬取出来,便于展示。可以根据自己的需求在步骤5中修改content的xpath匹配规则)

10.将项目部署到阿里云,设置定时任务。
链接:跳转至“定时爬虫”
代码附录:
1.newscrawl.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from news.items import NewsItem import timeclass NewscrawlSpider(CrawlSpider):name = 'newscrawl'allowed_domains = ['news.sina.com.cn']start_urls = ['http://news.sina.com.cn/hotnews/']now_time = time.strftime("%Y-%m-%d", time.localtime())reg = r"https://news.sina.com.cn/\w/time/\w+-\w+.shtml"reg = reg.replace("time", now_time)rules = (# Rule(LinkExtractor(allow=r'news.sina.com.cn/hotnews/')),Rule(LinkExtractor(allow=reg), callback='parse_item', follow=True),)def parse_item(self, response):item = NewsItem()item["title"] = response.xpath('//div[@class="main-content w1240"]/h1/text()').extract()[0]item["content"] = response.xpath('//div[@class="article"]').extract()[0]item["source"] = response.xpath('//*[@id="top_bar"]//div[@class="date-source"]/a/text()').extract()[0]item["date"] = response.xpath('//*[@id="top_bar"]//div[@class="date-source"]/span/text()').extract()[0]return item2. items.py
# -*- coding: utf-8 -*-# Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass NewsItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()content = scrapy.Field()source = scrapy.Field()date = scrapy.Field()3. pipelines.py
# -*- coding: utf-8 -*-# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html# 本地测试 # import json # # class NewsPipeline(object): # def __init__(self): # # 创建一个文件,将文件的保存类型设置为utf-8 # self.filename = open("news1.json", "w", encoding="utf-8") # def process_item(self, item, spider): # # 将数据由列表格式先变换为字典格式,再变换为json格式的数据 # text = json.dumps(dict(item), ensure_ascii=False)+"\n" # # 保存数据为utf-8的格式 # self.filename.write(text) # return itemimport pymysqlclass NewsPipeline(object):def __init__(self):# 连接MySQL数据库self.connect = pymysql.connect(host='服务器ip地址', user='root', password='******', db='news', port=3306)self.cursor = self.connect.cursor()def process_item(self, item, spider):# 往数据库里面写入数据sql = "insert into t_news(newsTitle, newsContent, newsSource, newsDate) values (%s, %s, %s, %s)"self.cursor.execute(sql, (item['title'], item['content'], item['source'], item['date']))self.connect.commit()return item# 关闭数据库def close_spider(self, spider):self.cursor.close()self.connect.close()
这篇关于(详细步骤)使用scrapy爬取新浪热点新闻,进入链接获取新闻内容。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



