本文主要是介绍西瓜/南瓜_学习_3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第3章-二分类线性判别分析_哔哩哔哩_bilibili
3.1 基本形式
给定X=(x1;x2;...;xd),括号里的内容称为属性,xi称为X在第i个属性上的取值,线性模型(linear model)则是通过这一系列的属性,对某个量进行预测的函数,即:
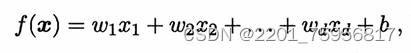
可以转换成向量,或是说矩阵的形式,即[x1,...,xd]*[w1,...,wd].T,得到:
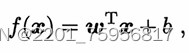
在这个过程中,我们实际上要确定的就是w和b,其中w是指一组w,但b是每一个线性方程常数项的数量之和,确定了w和b就相当于确定了模型。
若以西瓜问题举例,我们可以确定一系列w1、w2、w3,比如:
![]()
X=(x色泽;x根蒂;x敲声),w=(0,2;0.5;0.3),b=1。根据w的大小,我们可以看出,在这种情况下,最看重根蒂,其次敲声,最后色泽。
线性模型算是基础样例,由于w直观地表现了各属性在预测中的重要性,具有很好的可解释性(comprehensibility)。之后的许多非线性模型(non_linearRegression model)也在此基础上,通过引入层级结构或高维映射得来。
注:Comprehensibility:在ML模型中,Comprehensibility指的是学习算法以人类可理解的方式表示其所学习到的知识的能力[19-21]。模型Comprehensibility的概念源于米卡尔斯基[22]的假设,即“计算机归纳的结果应该是对给定实体的符号描述,在语义和结构上与人类专家观察相同实体可能产生的那些实体相似。”这些描述的组成部分应该作为单一的信息“块”来理解,可以直接用自然语言解释,并应该以一种综合的方式将定量和定性的概念联系起来。”由于其难以量化,可理解性通常与模型复杂度[17]的评估有关
可解释性机器学习( Explainable Artificial Intelligence (XAI) )文献阅读记录(1.1)_Lucy@IshtarXu的博客-CSDN博客
层级结构:卷积神经网络的层次结构_卷积层结构_辰的博客-CSDN博客
层级结构——组合模式_Inevitability的博客-CSDN博客 ( 这个对于现在的我确实超纲了,回头再补吧(哭
问AI的回答是酱紫的:
层级结构是一种将不同级别的组织或信息在不同层次上进行划分和管理的方式。层级结构可以帮助我们理清关系,简化复杂度,提高效率和应对能力。层级结构有多种形式和应用,例如:
- 树形结构是一种层级结构,它将数据或对象按照根节点、子节点和叶节点的关系进行组织和展示。树形结构可以用来表示导航、组织、选择、定位等功能1。
- 分层架构是一种层级结构,它将软件系统按照不同的抽象层次和关注点进行划分和隔离。分层架构可以用来降低耦合,提高可维护性,应对变化2。
- 层次结构还可以用来描述社会组织、管理机构、决策过程等方面的结构和规则。层次结构可以用来明确职责,分配权力,协调行动3。
高维映射:同理,回头再说吧()机器学习笔记——支持向量机(2)——处理非线性问题_支持向量机求解非线性_Eugene丶SHAO的博客-CSDN博客
3.2 线性回归

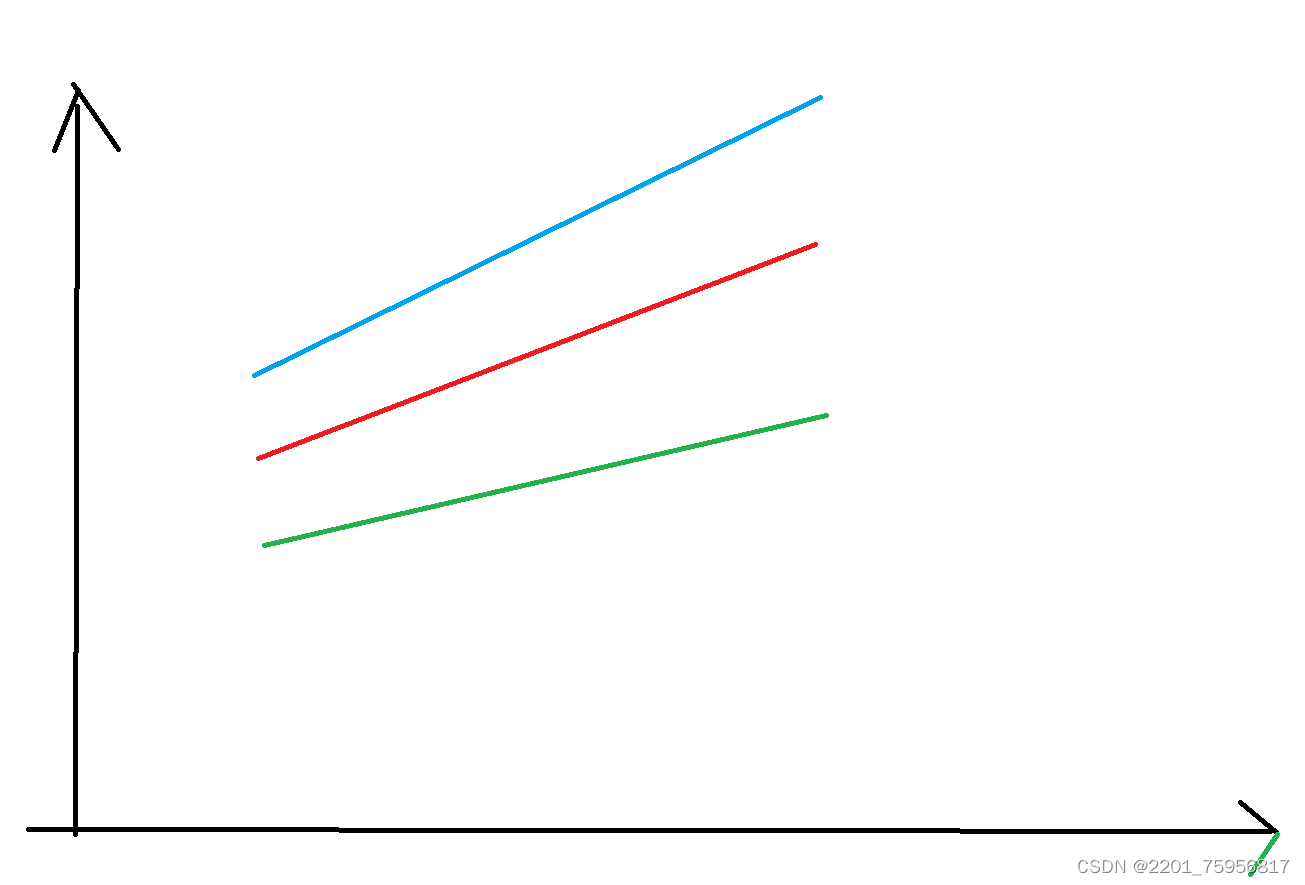
这是书上的定义,我自己的理解的话,可以想一下吴恩达老师课里的例子,也就是买房。横坐标是选定的一个自变量x,代表面积,纵坐标是相应的房价:(不要在意我这里的横纵坐标,主要看点的分布和线)
我们实际要干的是预测嘛,就是根据现有的点,作一条线,使之尽量符合点的分布趋势,这样我们就能直观的大概看出来之后点的分布了,这就是线性回归的意思。
个人感觉这样比书上的例子好理解一些,不过还是把原文贴一下吧:


从上面的定义也能看出我们的目标主要就是确定w和b,想想我们初高中怎么处理一次函数的,得到两个点,然后画一条线对吧?我们现在就是有预测出来的f(x),而它一般是不准的,也就是蓝线或是绿线,我们的目标是得到红线,也就是需要得到我们现在的直线端点的f(x)和实际的y的差距
我们沿用2.3见过的性能度量——均方误差(平方损失),也就是说,我们现在的目标是让这个误差最小化,设w*和b*为w和b的解,即:

均方误差在几何上对应欧几里得距离。基于均方差最小化来进行模型求解的方法称为最小二乘法(least square method).。在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小。
注:机器学习中的数学——距离定义(一):欧几里得距离(Euclidean Distance)_von Neumann的博客-CSDN博客

有点儿看不清,都是➖,其实就是两点间距离公式或者点到线的距离公式。
最小二乘法:一文让你彻底搞懂最小二乘法(超详细推导)_最小二乘解_胤风的博客-CSDN博客

我们现在求w和b使每一点的损失加和起来最小的值(![]() ),就是线性回归 模型的最小二乘"参数估计"(parameter estimation)。
),就是线性回归 模型的最小二乘"参数估计"(parameter estimation)。
这里贴一段书上对E的解释:

注:这里的凸函数概念是最优化数学中的凸函数,也就是传统意义上的凹函数,正好相反。
所以我们现在需要找函数关于w和b的导数均为0的点,因此对w和b分别求偏导:
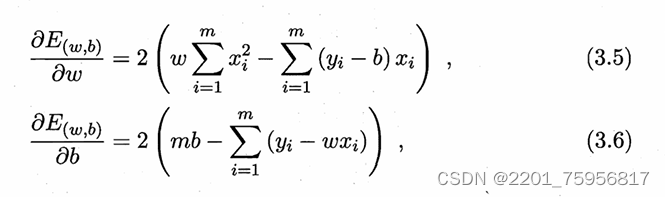
令两式分别为0,求解w和b:
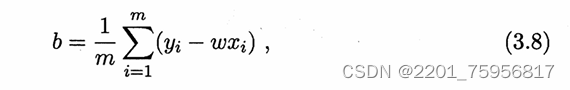
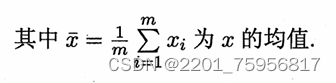
这里先给出多元线性回归的式子:
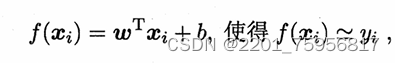 ,可以看出这其实是更一般的情况,有根据问题得到的更多变量和参数。
,可以看出这其实是更一般的情况,有根据问题得到的更多变量和参数。
依然还是用最小二乘法,对这一堆w和b进行估计。为方便计算和讨论,我们把这些w和b都写成向量形式(w;b),相应的,把数据集D表示成一个m×(d+1)大小的矩阵X,每行对应一个示例

把Y也写成向量形式,我们就可以得到下式:

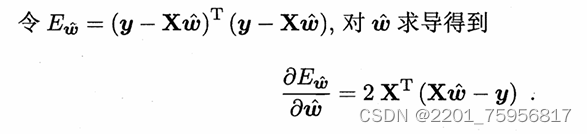 (3.10)
(3.10)
令上式为零可得w帽最优解的闭式解。这里的式子就是上面求方均差的式子,只不过平方项换成了矩阵的转置×自己。不过因为涉及了矩阵逆运算,比单变量情形复杂一些,我们需要做一些讨论,因为不是所有的矩阵都可以做逆运算的。
当XTX为满秩矩阵(full-rankmatrix)或正定矩阵(positive definite matrix)时,令式(3.10)为零可得
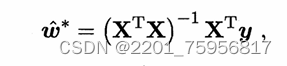
令xi帽=(xi,1),则多元回归模型为:

好的,现在我们来解释一下。时刻记得,这个w帽是(w,b),而我们上面把x都写成了(x,1),那么第二个式子里的![]() 就是x的转置乘w,就是单纯的矩阵乘法。
就是x的转置乘w,就是单纯的矩阵乘法。
那么当上面的XTX不是满秩矩阵怎么办呢,也就是有时我们得到的变量数量超过样例的数量,拿西瓜举例就是,你只有10个西瓜,但是可以拿来判断的标准可能有15种,也就是这些瓜在15个方面都不同。这种情况下,不满秩就会有很多个w,之后我们会引入正则化(regularizartion)来解决这个问题,这里先按下不表。
让我们先回到模型:
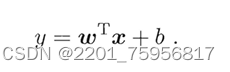
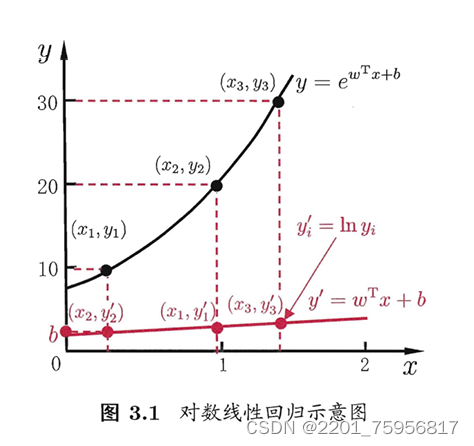
回想一下曾经的知识,我们知道等号左边不一定是个y,可能也是个含y的式子。比如我们可以对y取个对数:

这种情况下,y这个标记可认为是在指数尺度上变化,所以我们可以叫它对数线性回归(log_linear regression)相当于此时我们是在让![]() 不断逼近y,这个式子实质上已是在求取输入空间到输出空间的非线性函数映射,
不断逼近y,这个式子实质上已是在求取输入空间到输出空间的非线性函数映射,
如果我们要给这些个非线性函数映射一个泛化的式子,我们可以把wx+b当作一个变量,赋给一个单调可微函数g(·),单调可微是为了从y=g()得到r(y)=wx+b:
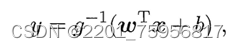
这种模型就是广义线性模型(generalized linear regression model),其中的g()是联系函数(link function)。
3.3 对数几率回归(逻辑回归)
三要素:
模型:线性模型,输出值的范围为[0,1],近似阶跃的单调可微函数
策略:极大似然估计,信息论
算法:梯度下降,牛顿法
如何处理分类任务呢?上面我们似乎都是在进行预测任务。事实上,上面的广义线性回归模型就可以做到,只需要找一个g(),将分类任务的真实标记y与线性回归模型的预测值联系起来。
以二分类任务为例,y从1和0中取值,而我们之前的![]() 是实值,所以我们要做的就是把z转换成0/1值,我们需要使用单位跃升函数(unit_step function)
是实值,所以我们要做的就是把z转换成0/1值,我们需要使用单位跃升函数(unit_step function)
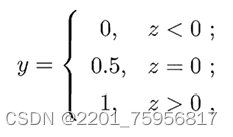
其实就是设定一个阈值,超过就是1,不到就是0
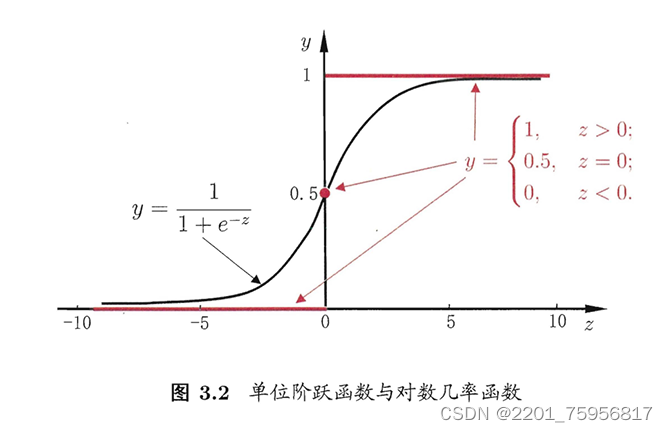
但是单位跃升函数不连续,而我们需要的g()是个单调可微函数,所以还需要做一步转换,我们需要找到一个近似于这个跃升函数,且连续的替代函数(surrogate function),对数几率函数(logistic function)正是这样的函数。
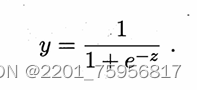
接下来一段直接贴原文吧,然后解释一下:

对数几率函数是Sigmoid函数,是S型的函数,通过这个式子,y与z建立了联系,y是关于z的函数,而且符合我们的需要,而z与x有关系,这样就得到了y和x的关系,这里的把y视作x作为正例的可能性,可以理解为单纯的形式合适;也可以理解为,wTx是一堆的加和,每组是一个很小的数,类似于之前的∑xi求损失的期望,这里加和起来相当于得到每个数概率的加和。
这种方法有很多优点,例如它是直接对分类可能性(也就是上面算的概率)进行建模,无需事先假设数据分布。这样就避免了假设分布不准确所带来的问题;它不是仅预测出"类别",而是可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用;此外,对率函数是任意阶可导的凸函数,有很好的数学性质,现有的许多数值优化算法都可直接用于求取最优解。
接下来我们需要先认识一下一个概念——先验概率和后验概率。
【概率论】极大似然估计和最大后验估计_极大似然估计经典例题_Mr_health的博客-CSDN博客
抛一枚硬币10次,有10次正面朝上,0次反面朝上。问正面朝上的概率p。在频率学派来看,利用极大似然估计可以得到 p= 1.0。但是很显然,一般情况下硬币都是均匀的。可以看到,当缺乏数据时极大似然估计可能会产生严重的偏差。最大后验估计就可以在一定程度上解决这样的问题。
最大后验估计依然是根据已知样本X,通过调整模型参数θ使得模型能够产生该数据样本的概率最大,只不过对于参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例(万一数据量少或者数据不靠谱呢)。

个人感觉和条件概率有一些相似,都是先考虑一个条件,或者说先考虑前者的分布情况,然后再考虑后者。注意:这里给定的是X!是给定样本的情况下,y=0或1的概率!
用到我们的这里可以帮助确定w和b。
若将(3.18)的y视作类后验概率p(y=1|x),则式(3.19)可重写为
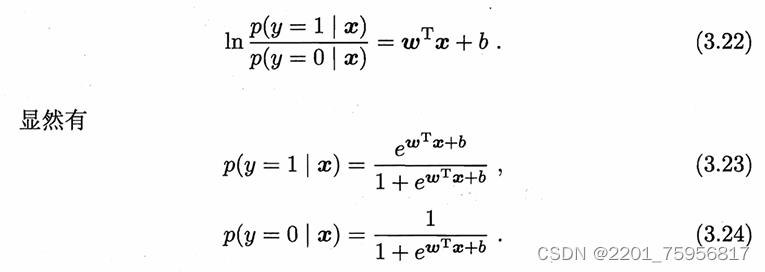
p(y=1|x)就是正确的概率,p(y=0|x)就是错误的概率,分别对应y和1-y。


上下对应一下,已知的数据分布X就是![]() ,需要反推的参数
,需要反推的参数就是
![]() ,我们可以把这里的
,我们可以把这里的ln p(·) 看作上面的p(xi;
),这样就好理解了。
即令每个样本属于其真实标记的概率越大越好,也就是让l()越大越好。令β=(w,b),=(x;1),则
x+b可简写为
,再令
![]() (1),
(1),![]() (2),则(3.25)中的似然项可重写为:
(2),则(3.25)中的似然项可重写为: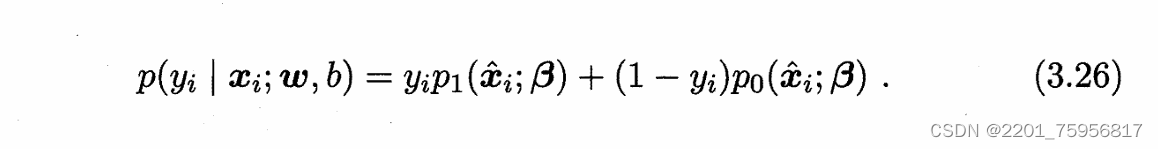
我们来分析一下这几个式子。因为用β和代替了原来的wx+b,所以我们要确定的就是β,使用的样本就是
,所以p()里的
![]() 就换成了
就换成了![]() ,道理是一样的。所以(1)的目的就是表示y=1条件下,求概率和参数,(2)同理。
,道理是一样的。所以(1)的目的就是表示y=1条件下,求概率和参数,(2)同理。
(3.26)的话,参考:【概率论】极大似然估计和最大后验估计_极大似然估计经典例题_Mr_health的博客-CSDN博客
这块儿我想了挺久的,先复习一下两种估计的概念:

但是我们可以看到我们这里的似然和后验都是P(y|x),那按照定义说不通啊?
错是肯定不会错的,这种说法是从样本预测的角度来说明的,我们上面的公式也一样。在预测阶段,输入样本X,经过逻辑回归后得到样本的特征,此时样本的特征是结果,根据特征来判断样本属于哪个类别,是由果索因,因此可以看成是后验概率。

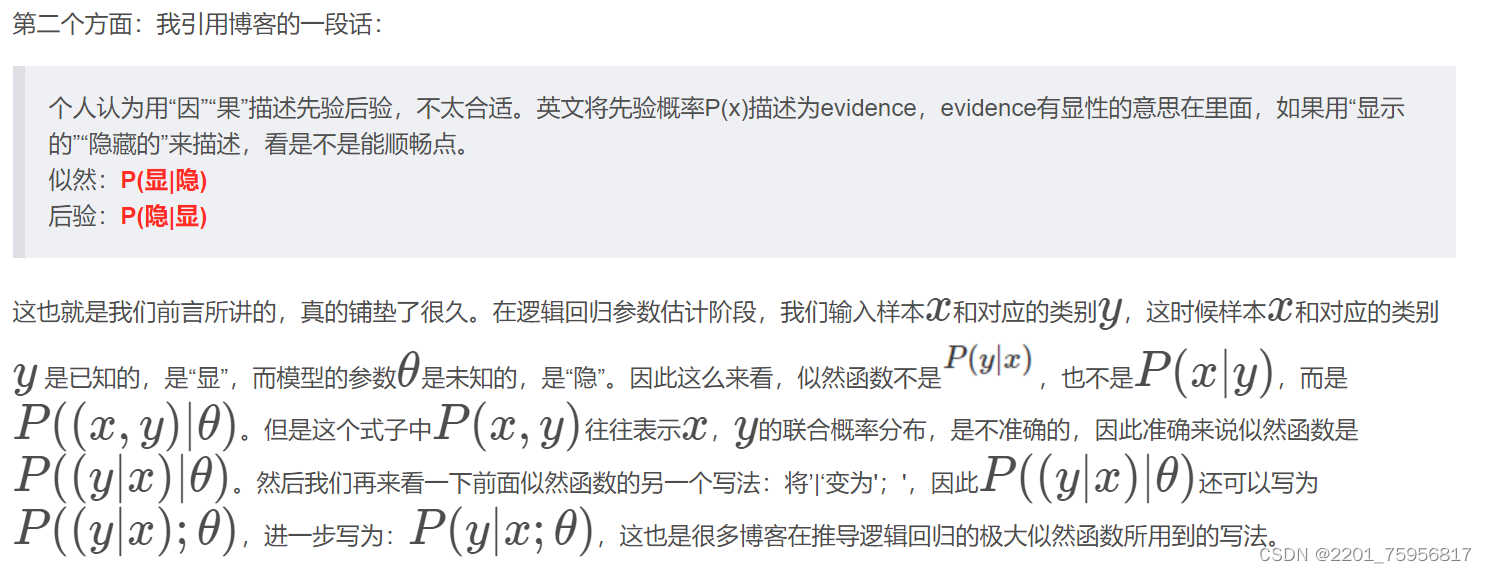
(3.26)里的p1和p0是分类为正例或负例的概率,但是我们上面还干了一件事,就是把离散的xy换成了连续的,也就是 使得y有很多取值,这里就是某个取值分类为正例或负例的概率,然后就和正常求概率一样,相乘再相加。(这段真的查了好多博客,我也不知道对不对,但是感觉这样理解是说的通的)
使得y有很多取值,这里就是某个取值分类为正例或负例的概率,然后就和正常求概率一样,相乘再相加。(这段真的查了好多博客,我也不知道对不对,但是感觉这样理解是说的通的)
或者还有个队友的理解,3.23和3.24这2个对应的是给定x,得到y为1或者0的概率,那么这个对应到这个事例的似然函数就是p1(如果是1)或者是1-p1(如果为0)
凸优化学习笔记_chapter9_牛顿法收敛性分析_xiaofei473的博客-CSDN博客 
这部分对我来说也有些超纲了QAQ,之后再看看能不能解决吧(捂脸
目前看起来像是梯度下降那种感觉,多次求导,来找凸函数的极值点。
(信息论角度推导逻辑回归)第3章-对数几率回归_哔哩哔哩_bilibili
自信息:
p(x)是概率质量函数,当等于2时,单位为bit,当b=e时单位为nat。可以理解为信息的一个小单位。
信息熵(自信息的期望):度量随机变量X的不确定性,信息熵越大越不稳定
比如a和b两种情况,当一个为1,一个为0时,最稳定,因为我猜一个是必然永远正确的;而都为1/2时是最不稳定的,因为a和b都有一半的可能性正确。
(此处为离散型)
计算信息熵的时候约定,若p(x)=0,则![]() 等于0。
等于0。
相对熵(KL散度):度量两个分布的差异,其典型应用场景是用来度量理想分布p(x)和模拟分布q(x)的区别。
其中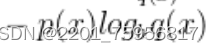 称为交叉熵,
称为交叉熵,就是遍历x的所有可能取值。可以看出,当p(x)和q(x)完全相同时,D=0,也就是说没有差异。
从机器学习三要素中策略角度来说,与理想分布最接近的模拟分布即为最有分布,因此可以通过最小化相对熵这个策略来求出最优分布,就是让D最小。由于理想分布p(x)是未知但固定的分布(频率学派的角度),所以为常量那么最小化相对熵就等价于最小化交叉熵


(每一步之间有=)

(有m个样本,把全体交叉熵都加起来,作为一个损失,然后最小化这个损失)
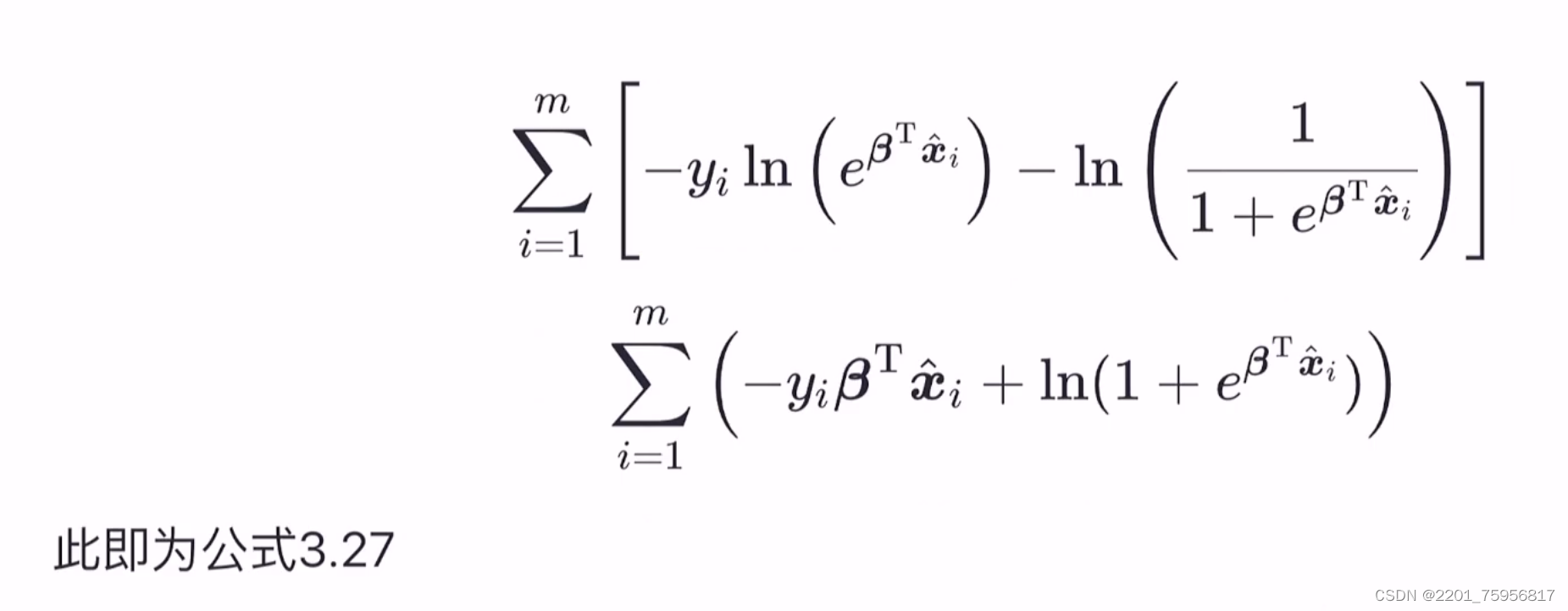
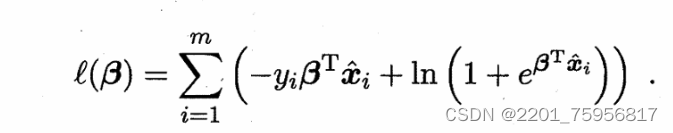
3.4 线性判别分析
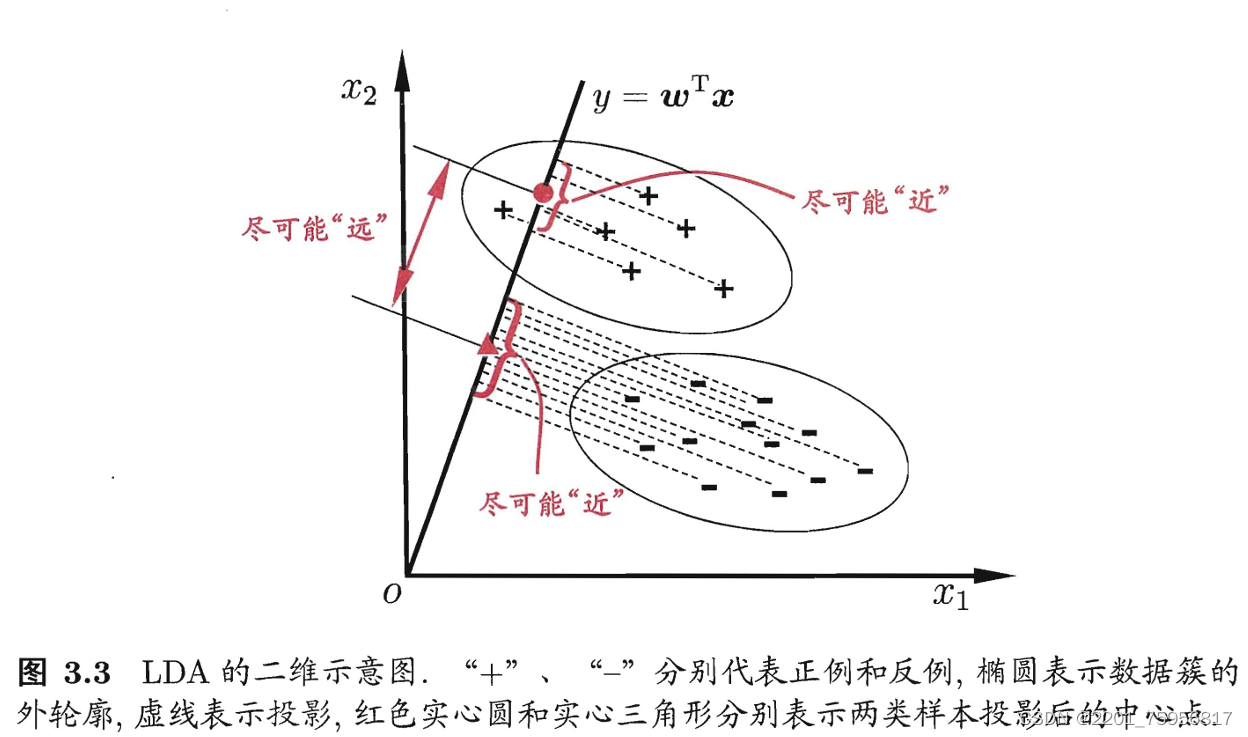
线性判别分析(linear Discriminant Analysis,简称LDA)是一种线性学习方法
给定训练样例集,设法将样例投影到一条直线上, 使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。图3.3给出了一个二维示意图:
给定数据集D,令、
、
分别表示i
{0,1}类示例的集合、均值向量、协方差矩阵。注意,这里的i和xi,yi的i不一样,前者只有0或1两种可能,表示正例或负例情况下这个量的取值;后者的i表示数量,第几个的意思。比如我们有正例集合{(x1,y1),(x2,y2)},还有负例集合{(x3,y3),(x4,y4)},那么
=((x1+x2)/2,(y1+y2)/2)
=((x3+x4)/2,(y3+y4)/2)
,其中m0和m1表示X0和X1中的样本数,比如此时就等于2,不过其实可以没有这两个数,不影响建模分析的结果。
不是直线的斜率,
是一个向量,有模长和方向,我们需要的是它的方向。再考虑上多个样本的同时表示,我们用上面定义的几个变量来表示一下两类样本的中心在直线上的投影:
![]() 相当于求内积,
相当于求内积,
(对应关系)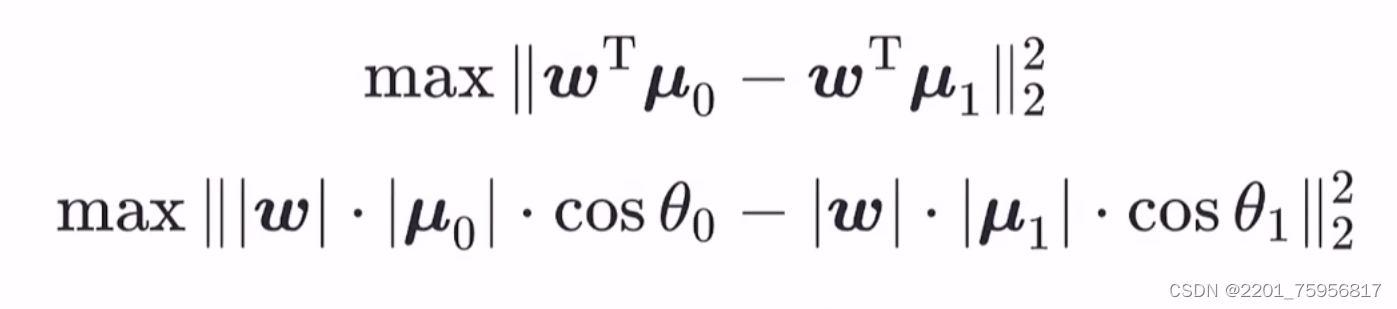
注意这里的投影事实上放大了,都乘了一个w,这是为了凑出内积形式,而且不影响最大值判断。
是指二范数,是用来求向量的模长,比如
=
,右上角再加个2就是取平方的意思。
二者的协方差(COV):![]()

解释一下:我们知道协方差就是用来描述相关程度的,所以我们需要让同一类(i相等的)的协方差尽可能相近,也就是两个都要尽可能地小,表示成表达式就是和最小;后面的好理解,就是让两类样本尽可能远离,也就是向量的差最大(注意,这里是正例样本的中心和负例样本的中心求出来的向量)
还需注意一点,这里的协方差其实更像方差: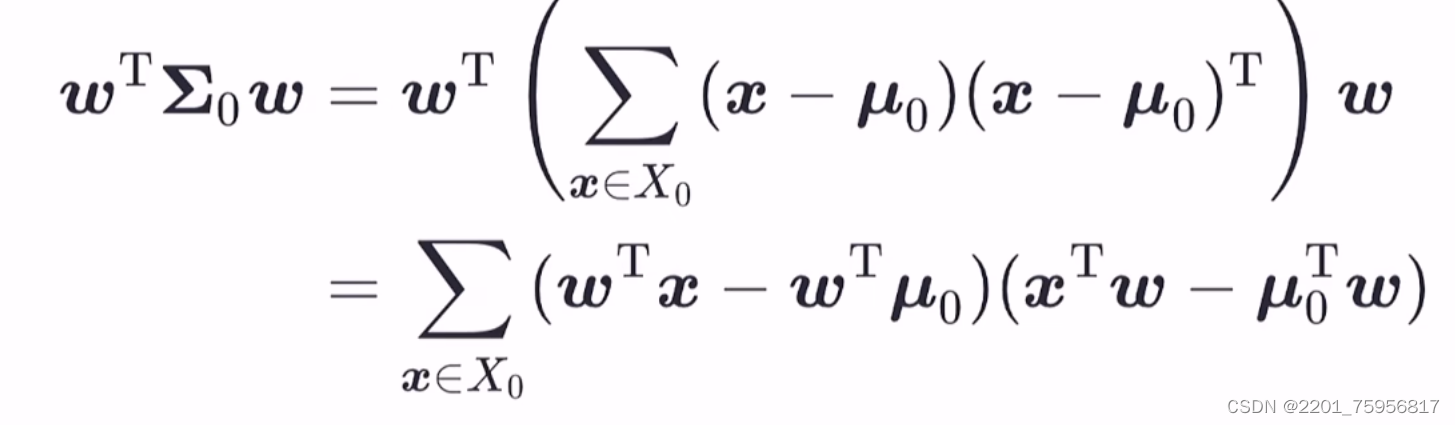
下面这个式子如果看作一个个整体的话,就是,只是缺了1/m0,但其实不论方差还是协方差,都缺了这一项,所以都不是严格的。
接下来推导一下: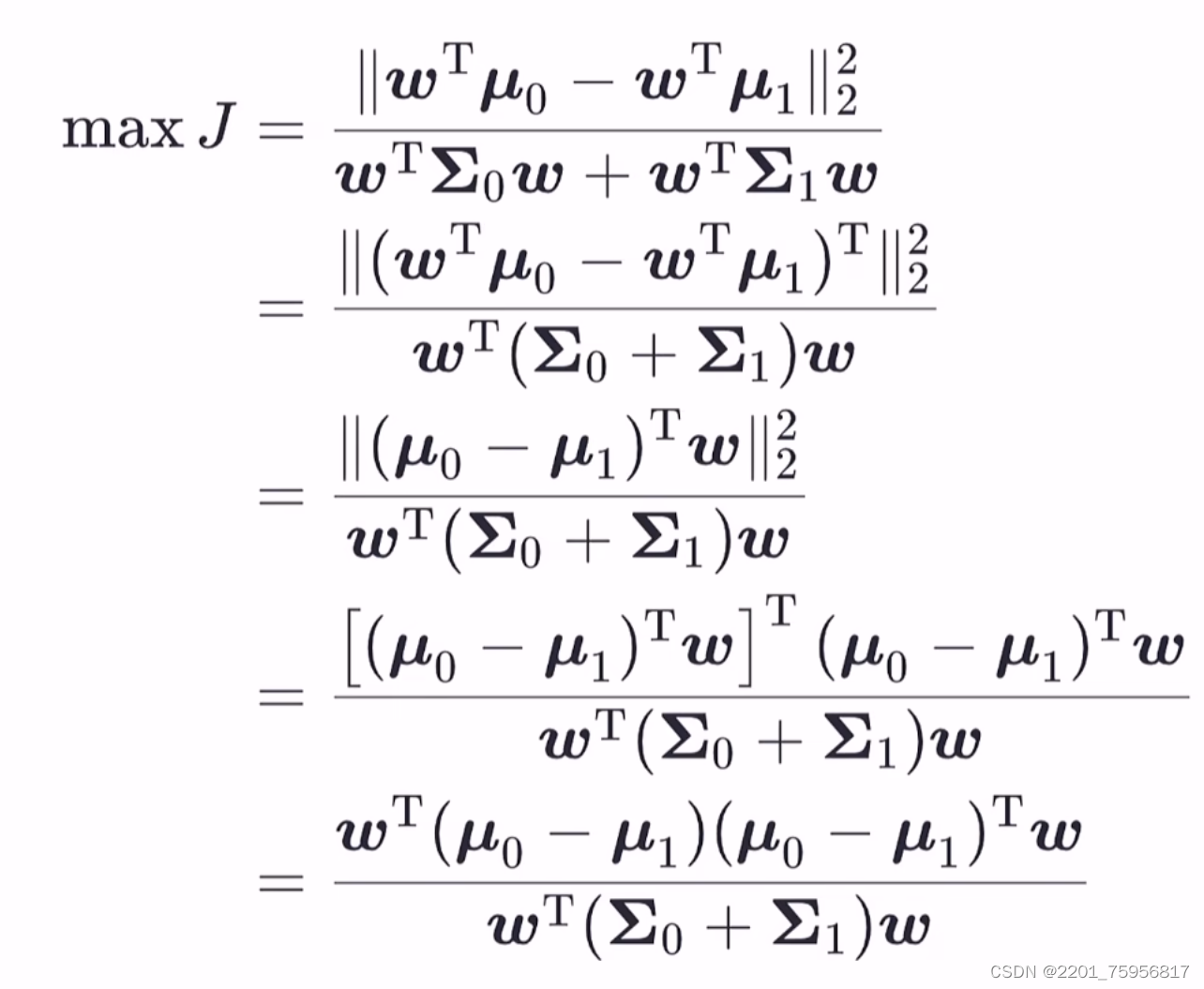
J可以理解为上限,就是我们要求这个数的最大值,然后让这个值越小越好,这样可以理解为分类很准确。
我们定义一些量方便后续的表示:
类内散度矩阵(within-class scatter matrix)表示误差的和
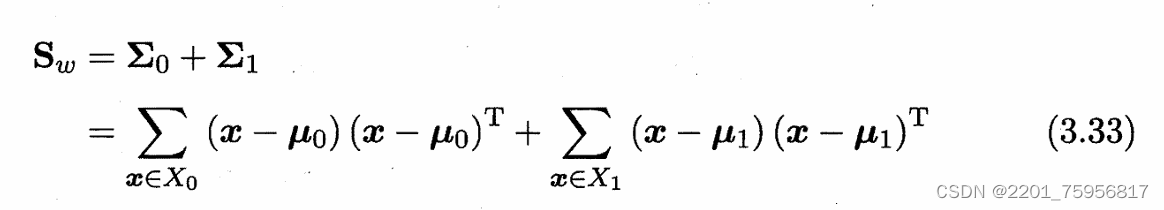
类间散度矩阵(between-class scatter matrix)表示两个分类的差别
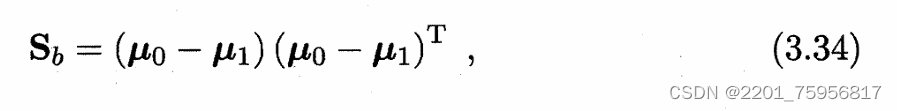
则:
J就是LDA欲最大化的目标,即和
的广义瑞利商(generalized Rayleigh quotient)
我们现在是要求这些个值。仔细看一下这个式子可以发现,w的大小不影响结果,那么我们就可以固定w的模长,因为Sw是个常量,所以固定了w就相当于固定了分母,我们可以固定分母为1,以便后续计算。这样一来,只有分子就可以求出固定的w了。
因此我们就得到了真正的损失函数:

其中min是因为加了个-
那么怎么解呢?我们需要使用拉格朗日乘子法,(拉格朗日乘子法详解-CSDN博客)


令偏导等于0:
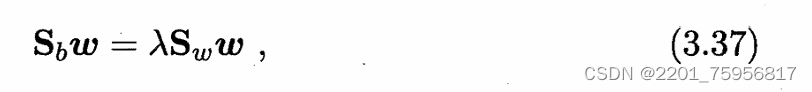
其实就是把固定分母等于1当作条件函数g(x),然后求解。但是对比博客的描述,好像缺了个变量啊,按照书上的方法,我们可以把Sbw展开,因为Sbw方向恒为![]() ,所以改写为:
,所以改写为:

(Sb是矩阵w是列向量,乘出来是一个行向量,所以等于右边)
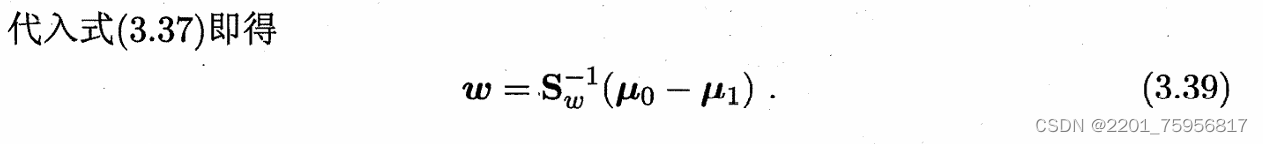
考虑到数值解的稳定性,就是让解是个数,我们需要对Sw进行奇异值分解。奇异值分解(SVD)(Singular Value Decomposition)_大豆木南的博客-CSDN博客
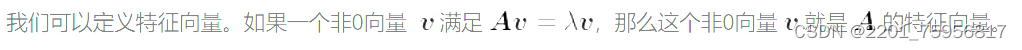


按照视频的方法,我们需要拆开Sb,得到: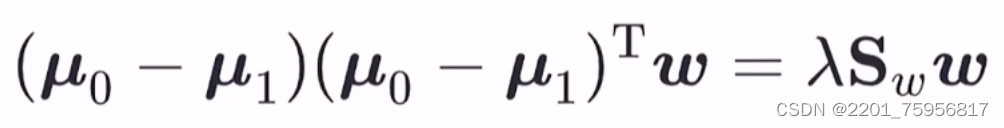
前面两项是行向量乘列向量等于一个数,这个数是个定值,所以整个左边的大小只与w有关,而w我们可以随便改变的。
可以令![]() ,这个γ只和w有关
,这个γ只和w有关
然后我们会得到这两个式子:
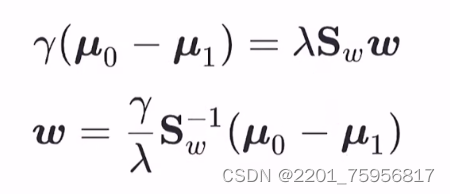
因为我们能控制w,所以γ我们也可以随便改变赋值,我们令γ=λ,就得到(3.39)
补充一些知识(广义特征值):
(广义瑞利商):

厄米矩阵可以暂且理解为实数对称矩阵

同样的LDA也可以被推广到多分类任务中,假设有N个类,且第i类示例数为mi,我们先定义“全局散度函数”(感觉可以理解为误差的和)
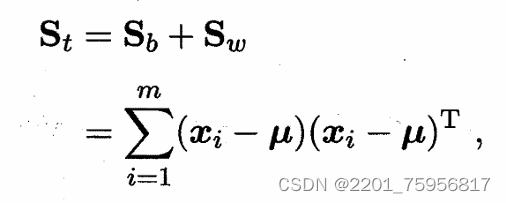 、
、
是所有示例的均值向量,Sw是每个单个类别的散度矩阵之和,即:

其中:
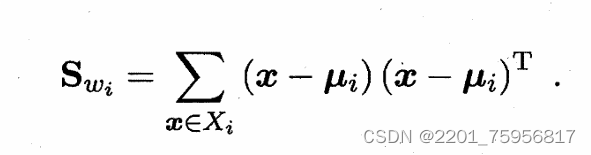
就是单个类的散度矩阵,求个和
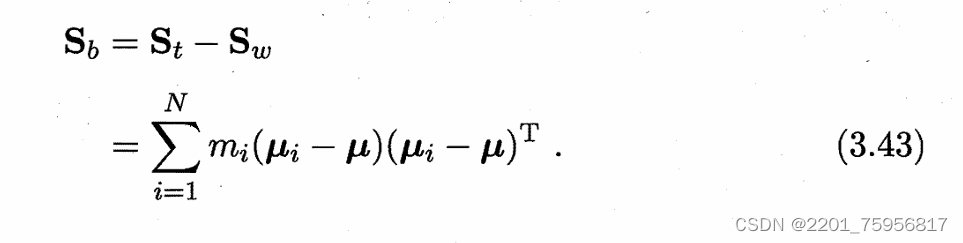
这个就是推广的的形式,tr迹是对角线上一堆数的累加,
tr()=
tr()=
所以就是每一个示例中的散度矩阵求和后,相加。用一个式子表示就是下图
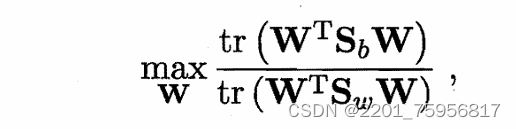 (3.44)
(3.44)
固定分母为1,则上式等价于
- tr(
)
s.t. tr()=1
还是用拉格朗日算子法:
L(W,λ)= - tr() + λ( tr(
) - 1)
L对w求偏导可得,令其等于0,得
和上面两类时的操作一样,把Sb拆开,除了W都是定值,设为γ,再令γ=λ,则
W=

3.5 多分类学习
除了上面推广的LDA,拆分策略也常被用于解决多分类问题。简单来说就是,如果你有三个类,就选一个出来,剩下两个作为一类,然后当作二分类问题解决,这样把所有类都进行一遍。这里的关键是如何对多分类任务进行拆分,以及如何对多个分类器进行集成。
一对一(One vs. One,简称OvO)
给定数据集D{(x1,y1), ... ,(xm,ym)},yi{C1,C2, ... ,
},OvO要做的就是把所有这些类别两两配对,形成N(N-1)/2个二分类任务,规定一部分为正例,一部分为反例。每个输入的样本将会在每一个分类器中被分类一次,所以最后也会有N(N-1)/2个结果,这之中被分类到最多次的类别为最终结果。
一对其余(One vs. Rest,简称OvR)
每次将一个类设为正例,剩下的都是反例,这样在所有类都当过一次正例后,我们将得到N个分类器。输入的新样本在哪个分类器中被分为正例,最终结果就是这个分类器中正例的类别。
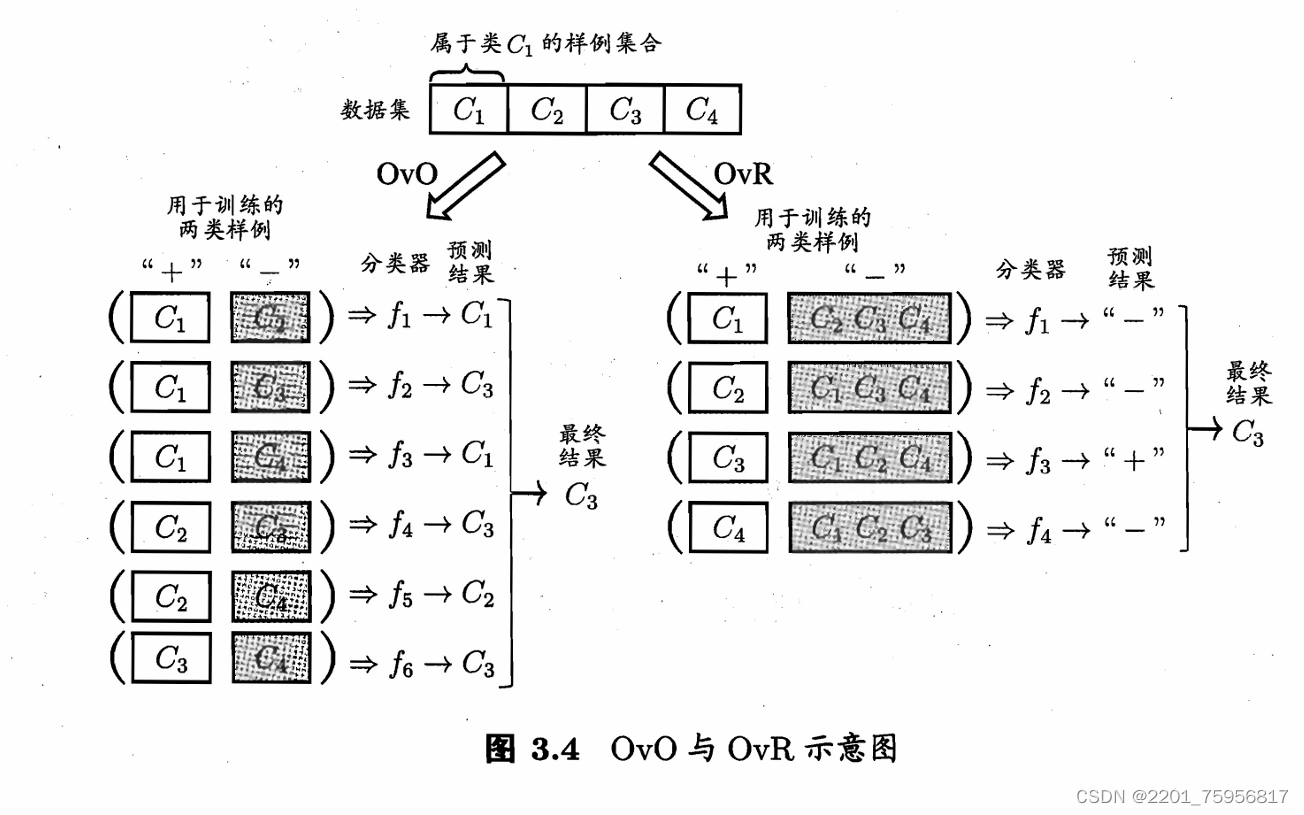
两者相比的话,前者需要训练的模型更多,所以存储和测试时间比后者需求大,但是后者每个模型都需要所有数据来训练,因此在类别很多的时候,前者会更快。实际上普遍而言,两者差不多。
多对多(Many vs. Many,简称MvM)
每次将若干类当作正例,若干类当作反例,当然正例和反例也是不能随便选取的。介绍一种常用的MvM技术:纠错输出码(Error Correcting Output Codes,简称ECOC)。主要分两步:
(1)编码:对N个类别做M次划分,每次划分将一部分化为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生M个训练集,可训练出M个分类器。
(2)解码:M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。
类别划分通过编码矩阵(coding matrix)指定,常见的有二元码和三元吗两种。前者只有正例和反例,后者还有一个停用类。
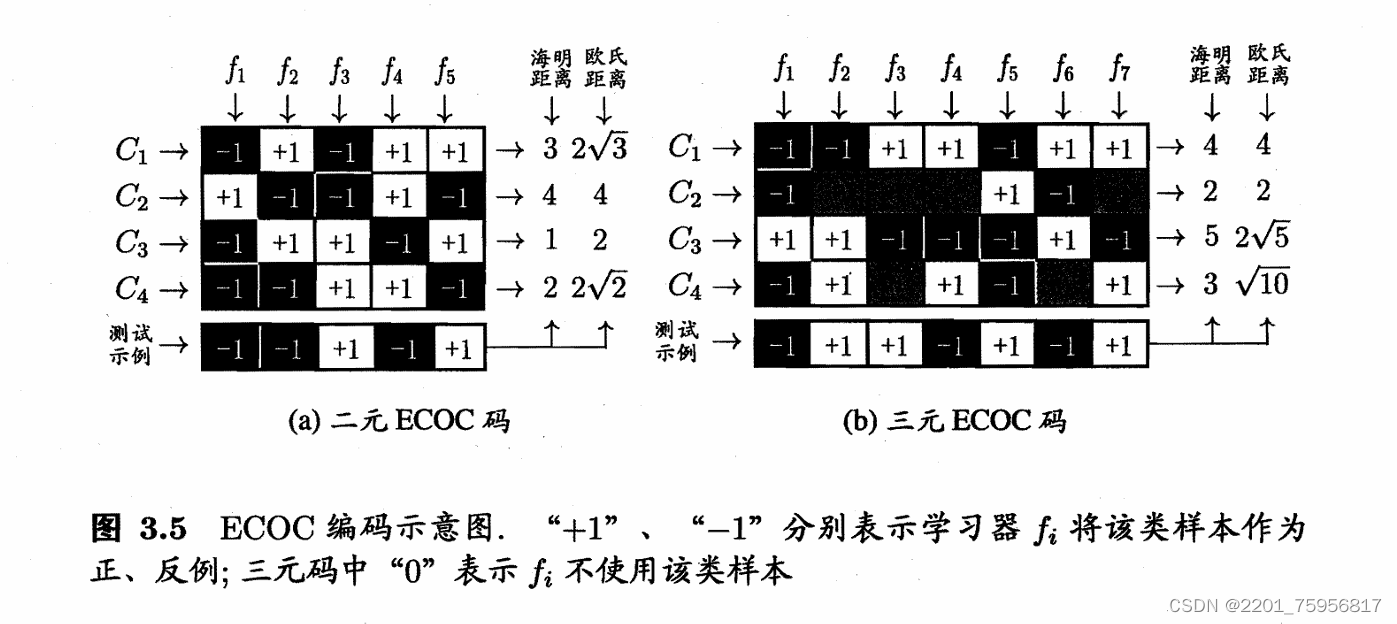
解释一下图,f代表得到的一些分类器,C代表样本。以f1为例,C1在f1下是反例,C2是正例,以此类推。测试数据是在五个测试器下得到的数值,海明距离是测试示例与上面的一行数据进行异或,然后相加。
(纠错输出码(Error Correcting Output Code, ECOC)_ecoc纠错输出码_地上悬河的博客-CSDN博客)
| 编码值 | -1 | +1 | -1 | +1 | +1 |
|---|---|---|---|---|---|
| 测试值 | -1 | -1 | +1 | -1 | +1 |
| 异或 | 0 | 1 | 1 | 1 | 0 |
海明距离=0+1+1+1+0=3
欧式距离就是对应位置相减,求平方,再相加,再开方。

所以对于C1,欧氏距离=sqrt(0+4+4+4+0 ) = 2根号3
三元的规则同理,只是海明距离不是异或,-1和+1距离1,+1/-1和0距离0.5.
之所以被称为纠错码就是因为对某一个分类器出错的情况下,还是能得到正确结果,某种意义上可以说是比较健壮。例如图3.5(a)中对测试示例的正确预测编码是(-1,+1,十1,一1,+1),假设在预测时某个分类器出错了,例如f2出错从而导致了错误编码(-1,-1,+1,一1,+1),但基于这个编码仍能产生正确的最终分类结果C3。
虽然说编码越长,也就是分类器越长,理论上纠错能力越强,但是所需训练器也会更多,而且如果C不变的话,分类可能性是一定的,在一定长度后,在增加分类器也没有用。
3.6 类别不平衡问题
类别不平衡问题(class imbalance)就是指分类问题中,正反例数量差别很大的问题,比如有98个反例,只有2个正例。
从线性分析器角度分析,正如我们之前分析的,对样本的分类事实上是拿得到的预测值,和我们一开始设置的阈值进行比较,y其实就相当于正例的可能性,1-y就是负例的可能性,
就是正例和负例的比例。设实际样本中的整理数量为
,负例数量为
,也就是说我们用的时候,如果阈值设置为0.5,
=
,就是看有没有
>
= 1,有就是正例。
是预测几率,是基于我们的分类器得到的数学结果;
是观测结果,是我们直接看样本比例得出的。
但是其实在训练分类器的时候,我们一般是假设训练集是真实样本总体的无偏采样,因此观测几率就代表了真实几率,也就是正负例相同来训练的。当不相等的时候,我们也不需要回去重新调整训练原则,我们可以直接调整预测值:
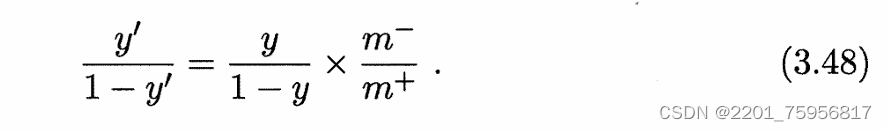 也就是使其在执行
也就是使其在执行>1的时候,实际上是在执行(3.48),这样的策略叫做再缩放(rescaling)。但事实上实现的时候没这么简单,因为我们假设训练集是真实样本总体的无偏采样通常就是不成立的,也就是说,我们很难直接得到
。技术上大致有三种做法来解决问题:
类别不平衡解决策略_林夕雨小月的博客-CSDN博客
欠采样(undersampling):去除一些样本,使得正负例数目相近。
代表算法:SMOTE
步骤如下:
对于少数类中每一个样本x,以欧氏距离(特征向量)为标准,计算它到少数类样本集Smin中所有样本的距离,得到其K近邻。
根据样本不平衡比例设置一个采样倍率N,对于每一个少数类样本x,从其K近邻中随机选择若干个样本,假设选择的近邻为xn。
对于每一个随机选出的近邻xn,分别于原样本按以下公式构建新样本。
Xnew = x + rand(0,1) × norm(x-xn)
过采样(oversampling):增加一些样本,使得正负例数目相近。
代表算法:EasyEnsemble(一种集成学习机制)EasyEnsemble的用法-CSDN博客
阈值移动(threshold-moving)就是上面的那种做法,使用(3.48).
接下来写一些代码实现:
"""Add polynomial features to the features set"""
import numpy as np
from .normalize import normalizedef generate_polynomials(dataset, polynomial_degree, normalize_data=False):"""变换方法:x1, x2, x1^2, x2^2, x1*x2, x1*x2^2, etc."""features_split = np.array_split(dataset, 2, axis=1)#把接收的数据切成两份dataset_1 = features_split[0]#前一段dataset_2 = features_split[1]#后一段# 获取两个子数据集的行数和列数,并检查是否相等(num_examples_1, num_features_1) = dataset_1.shape(num_examples_2, num_features_2) = dataset_2.shapeif num_examples_1 != num_examples_2:raise ValueError('无法用行数不同的两组数组生成多项式')if num_features_1 == 0 and num_features_2 == 0:raise ValueError('没有数据,无法生成多项式')if num_features_1 == 0:dataset_1 = dataset_2elif num_features_2 == 0:dataset_2 = dataset_1#取两个子数据集中较小的列数作为num_features,并截取每个子数据集的前num_features列。num_features = num_features_1 if num_features_1 < num_examples_2 else num_features_2dataset_1 = dataset_1[:, :num_features]dataset_2 = dataset_2[:, :num_features]polynomials = np.empty((num_examples_1, 0))#然后,用一个双重循环遍历从1到polynomial_degree的所有次数组合i和j,# 并计算dataset_1的i-j次方乘以dataset_2的j次方作为一个多项式特征,并将其拼接到polynomials中#计算dataset_1的i-j次方乘以dataset_2的j次方作为一个多项式特征的目的是为了生成两个数据集的交互特征,# 即两个特征相乘的结果。这样可以捕获特征之间的非线性关系,提高模型的拟合能力和表达能力。# 例如,如果dataset_1和dataset_2分别表示用户的年龄和地点,那么它们的交互特征就可以表示用户位于# 某个年龄段并且位于某个特定地点的情况。这种特征在基于决策树的模型中极其常见,在广义线性模型中也经常使用。for i in range(1, polynomial_degree + 1):for j in range(i + 1):polynomial_feature = (dataset_1 ** (i - j)) * (dataset_2 ** j)polynomials = np.concatenate((polynomials, polynomial_feature), axis=1)#标准化if normalize_data:polynomials = normalize(polynomials)[0]return polynomials
import numpy as np
'''
dataset: 一个二维的numpy数组,表示输入的数据集,每一行是一个样本,每一列是一个特征。
sinusoid_degree: 一个正整数,表示要生成的正弦函数的次数,从1到sinusoid_degree。
sinusoids: 一个二维的numpy数组,表示输出的正弦函数特征,每一行对应一个样本,每一列对应一个正弦函数特征。
sinusoids的列数等于sinusoid_degree。
'''def generate_sinusoids(dataset, sinusoid_degree):"""sin(x)."""#初始化一个空的numpy数组sinusoids,用于存储正弦函数特征。num_examples = dataset.shape[0]sinusoids = np.empty((num_examples, 0))#对于从1到sinusoid_degree的每一个次数degree,计算dataset中每个样本的正弦函数值,# 即sin(degree * dataset),并将其作为新的特征添加到sinusoids中。for degree in range(1, sinusoid_degree + 1):sinusoid_features = np.sin(degree * dataset)sinusoids = np.concatenate((sinusoids, sinusoid_features), axis=1)return sinusoids
"""Normalize features"""import numpy as npdef normalize(features):features_normalized = np.copy(features).astype(float)#astype是类型转换函数# 计算均值features_mean = np.mean(features, 0)# 计算标准差features_deviation = np.std(features, 0)# 标准化操作if features.shape[0] > 1:#列数是否 > 1features_normalized -= features_mean# 防止除以0features_deviation[features_deviation == 0] = 1features_normalized /= features_deviationreturn features_normalized, features_mean, features_deviation
# 标准化的值 平均值 是否等于 0"""Prepares the dataset for training"""import numpy as np
from .normalize import normalize
from .generate_sinusoids import generate_sinusoids
from .generate_polynomials import generate_polynomials
#polynomial_degree: 一个整数,表示要生成的多项式特征的最高次数。默认为0,表示不生成多项式特征。
#sinusoid_degree: 一个整数,表示要生成的正弦波特征的最高次数。默认为0,表示不生成正弦波特征。
#normalize_data: 一个布尔值,表示是否对原始数据进行归一化处理。默认为True,表示进行归一化处理。
#data_processed: 一个二维的numpy数组,包含预处理和特征变换后的数据,每一行对应一个样本,
# 每一列对应一个特征。第一列为全1列,用于方便计算截距项。
#features_mean: 一个一维的numpy数组,包含原始数据每一列的均值。如果不进行归一化处理,则为0。
#features_deviation: 一个一维的numpy数组,包含原始数据每一列的标准差。如果不进行归一化处理,则为0。def prepare_for_training(data, polynomial_degree=0, sinusoid_degree=0, normalize_data=True):# 计算样本总数num_examples = data.shape[0]# 浅拷贝数据,避免对原数据造成影响data_processed = np.copy(data)# 根据normalize_data参数决定是否对数据进行归一化处理。如果是,则调用normalize函数,将数据转换为均值为0,# 标准差为1的分布,并返回归一化后的数据、原始数据的均值和标准差。如果否,则将归一化后的数据、均值和标准差都设为原始数据features_mean = 0features_deviation = 0data_normalized = data_processedif normalize_data:(data_normalized,features_mean,features_deviation) = normalize(data_processed)data_processed = data_normalized# 根据sinusoid_degree参数决定是否生成正弦波特征。如果是,则调用generate_sinusoids函数,# 根据归一化后的数据和正弦波次数生成相应的特征,并将其拼接到data_processed中。如果否,则不做任何操作。if sinusoid_degree > 0:sinusoids = generate_sinusoids(data_normalized, sinusoid_degree)data_processed = np.concatenate((data_processed, sinusoids), axis=1)# 根据polynomial_degree参数决定是否生成多项式特征。如果是,则调用generate_polynomials函数,# 根据归一化后的数据、多项式次数和normalize_data参数生成相应的特征,并将其拼接到data_processed中。# 如果否,则不做任何操作。if polynomial_degree > 0:polynomials = generate_polynomials(data_normalized, polynomial_degree, normalize_data)data_processed = np.concatenate((data_processed, polynomials), axis=1)# 加一列1data_processed = np.hstack((np.ones((num_examples, 1)), data_processed))return data_processed, features_mean, features_deviation
"""Sigmoid function"""import numpy as npdef sigmoid(matrix):"""Applies sigmoid function to NumPy matrix"""return 1 / (1 + np.exp(-matrix))"""Sigmoid gradient function"""from .sigmoid import sigmoiddef sigmoid_gradient(matrix):"""Computes the gradient of the sigmoid function evaluated at z."""return sigmoid(matrix) * (1 - sigmoid(matrix))import numpy as np
from utils.features import prepare_for_training'''
data 一个二维的numpy数组,表示输入的数据集,每一行是一个样本,每一列是一个特征。
theta 一个二维的numpy数组,表示模型的参数,每一行对应一个特征,每一列对应一个输出值。
初始化类的参数theta为一个零向量,其长度等于预处理后的数据集的特征数。
delta 预测值和标签之间的误差delta。
labels 一个二维的numpy数组,表示输入的标签,每一行对应一个样本,每一列对应一个输出值。
predictions 计算并获取模型对训练集的预测值
'''class LinReg:def __init__(self,data,labels,polynomial_degree = 0,sinusoid_degree = 0,normalize_data = True):(data_processed,features_mean,features_deviation) = prepare_for_training(data,polynomial_degree,sinusoid_degree,normalize_data=True)self.data = data_processedself.labels = labelsself.features_mean = features_meanself.features_deviation = features_deviationself.polynomial_degree = polynomial_degreeself.sinusoid_degree = sinusoid_degreeself.normalize_data = normalize_datanum_features=self.data.shape[1]self.theta=np.zeros((num_features,1))@staticmethoddef hypothesis(data,theta):predictions = np.dot(data,theta)#矩阵乘法return predictionsdef gradient_descent(self,alpha,num_iterations):'''实际迭代模块 会迭代num_iterations次'''cost_history=[]for i in range(num_iterations):self.gradient_steps(alpha)cost_history.append(self.cost_function(self.data,self.labels))return cost_historydef gradient_steps(self,alpha):"""梯度下降参数更新计算方法,注意矩阵运算"""num_examples = self.data.shape[0]#得到行数predictions=LinReg.hypothesis(self.data,self.theta)#矩阵乘法delta = predictions - self.labelstheta = self.thetatheta = theta - alpha * (1/num_examples) * (np.dot(delta.T,self.data)).Tself.theta = thetadef train(self,alpha,num_iterations=500):'''训练模块 执行梯度下降'''cost_history = self.gradient_descent(alpha,num_iterations)return self.theta,cost_historydef cost_function(self,data,labels):'''损失计算方法'''num_examples = data.shape[0]delta = LinReg.hypothesis(self.data,self.theta) - labelscost = (1/2)*np.dot(delta.T,delta)/num_examplesreturn cost[0][0]def get_cost(self,data,labels):data_prosessed = prepare_for_training(data,self.polynomial_degree,self.sinusoid_degree,self.normalize_data)[0]return self.cost_function(data_prosessed, labels)
#这里的data_prosessed是一个二维的numpy数组,表示经过预处理的数据集,每一行是一个样本,每一列是一个特征。预处理的步骤包括:#- 如果self.polynomial_degree大于1,那么对数据集中的每个特征进行多项式扩展,即添加其平方、立方等高次项作为新的特征。
#- 如果self.sinusoid_degree大于0,那么对数据集中的每个特征进行正弦函数扩展,即添加其正弦、余弦等周期函数作为新的特征。
#- 如果self.normalize_data为True,那么对数据集中的每个特征进行归一化处理,即减去其均值并除以其标准差,使其分布在0附近。#prepare_for_training函数返回一个元组,包含四个元素:预处理后的数据集、原始数据集的均值、
#原始数据集的标准差和预处理后的数据集的列数。这里只取了元组的第一个元素,即预处理后的数据集。def predict(self,data):'''用训练好的参数模型 预测得到回归值结果'''data_prosessed = prepare_for_training(data,self.polynomial_degree,self.sinusoid_degree,self.normalize_data)[0]predictions = LinReg.hypothesis(data_prosessed,self.theta)return predictionsimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
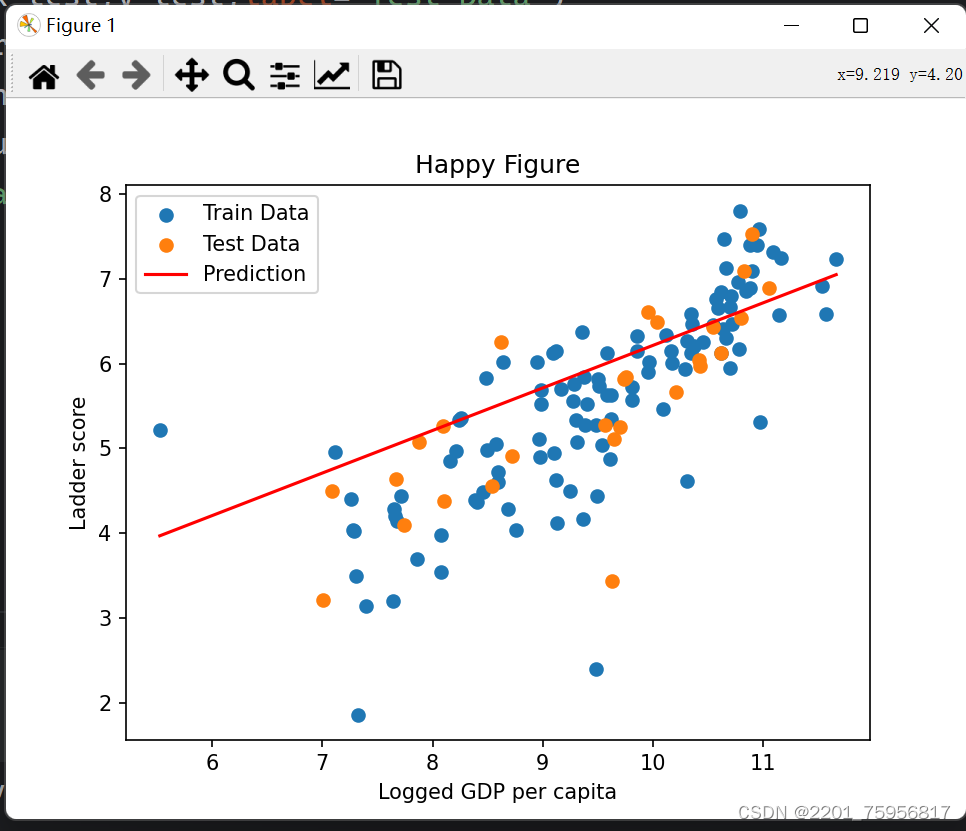
import xlrdfrom Linear_Regression import LinRegdata = pd.read_excel('../data/DataForFigure2.1WHR2023.xls')#得到训练和测试数据
train_data = data.sample(frac = 0.8)
test_data = data.drop(train_data.index)input_param_name = 'Logged GDP per capita'
output_param_name = 'Ladder score'x_train = train_data[[input_param_name]].values
y_train = train_data[[output_param_name]].valuesx_test = test_data[input_param_name].values
y_test = test_data[output_param_name].valuesnum_iterations = 500
learing_rate = 0.01lin_reg = LinReg(x_train,y_train)
(theta,cost_history) = lin_reg.train(learing_rate,num_iterations)print('开始时的损失:',cost_history[0])
print('训练后的损失:',cost_history[-1])plt.plot(range(num_iterations),cost_history)
plt.xlabel('Iter')
plt.ylabel('Cost')
plt.title('GD')
plt.show()predictions_num = 100
x_predictions = np.linspace(x_train.min(),x_train.max(),predictions_num).reshape(predictions_num,1)
y_predictions = lin_reg.predict(x_predictions)plt.scatter(x_train,y_train,label='Train Data')
plt.scatter(x_test,y_test,label='Test Data')
plt.plot(x_predictions,y_predictions,'r',label='Prediction')
plt.xlabel(input_param_name)
plt.ylabel(output_param_name)
plt.title('Happy Figure')
plt.legend()
plt.show()(以单变量线性回归为例)
这篇关于西瓜/南瓜_学习_3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







