本文主要是介绍推荐系统——MF及其python实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
目前推荐系统中用的最多的就是矩阵分解方法,在Netflix Prize推荐系统大赛中取得突出效果。以用户-项目评分矩阵为例,矩阵分解就是预测出评分矩阵中的缺失值,然后根据预测值以某种方式向用户推荐。今天以“用户-项目评分矩阵R(M×N)”说明矩阵分解方式的原理以及python实现。
一、矩阵分解
1.案例引入
有如下R(5,4)的打分矩阵:(“-”表示用户没有打分)
其中打分矩阵R(n,m)是n行和m列,n表示user个数,m行表示item个数
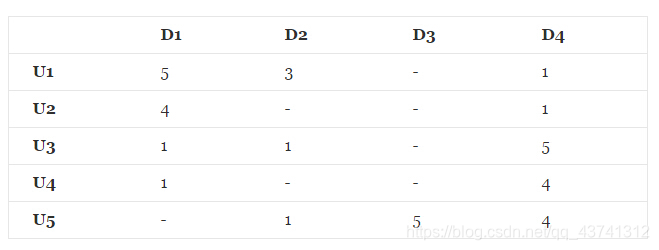
那么,如何根据目前的矩阵R(5,4)如何对未打分的商品进行评分的预测(如何得到分值为0的用户的打分值)?
——矩阵分解的思想可以解决这个问题,其实这种思想可以看作是有监督的机器学习问题(回归问题)。
矩阵分解的过程中,,矩阵R可以近似表示为矩阵P与矩阵Q的乘积:

矩阵P(n,k)表示n个user和k个特征之间的关系矩阵,这k个特征是一个中间变量,矩阵Q(k,m)的转置是矩阵Q(m,k),矩阵Q(m,k)表示m个item和K个特征之间的关系矩阵,这里的k值是自己控制的,可以使用交叉验证的方法获得最佳的k值。为了得到近似的R(n,m),必须求出矩阵P和Q,如何求它们呢?
2.推导步骤
- 首先令:

- 对于式子1的左边项,表示的是r^ 第i行,第j列的元素值,对于如何衡量,我们分解的好坏呢,式子2,给出了衡量标准,也就是损失函数,平方项损失,最后的目标,就是每一个元素(非缺失值)的e(i,j)的总和最小值

- 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:

- 根据负梯度的方向更新变量:

-
不停迭代直到算法最终收敛(直到sum(e^2) <=阈值,即梯度下降结束条件:f(x)的真实值和预测值小于自己设定的阈值)
-
为了防止过拟合,增加正则化项
3.加入正则项的损失函数求解
- 通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入正则L2范数的损失函数为:

对正则化不清楚的,公式可化为:

- 使用梯度下降法获得修正的p和q分量:
-求解损失函数的负梯度:

- 根据负梯度的方向更新变量:

4.预测
预测利用上述的过程,我们可以得到矩阵和,这样便可以为用户 i 对商品 j 进行打分:

二、python代码实现
以下是根据上文的评分例子做的一个矩阵分解算法,并且附有代码详解。
from math import *
import numpy
import matplotlib.pyplot as pltdef matrix_factorization(R,P,Q,K,steps=5000,alpha=0.0002,beta=0.02): #矩阵因子分解函数,steps:梯度下降次数;alpha:步长;beta:β。Q=Q.T # .T操作表示矩阵的转置result=[]for step in range(steps): #梯度下降for i in range(len(R)):for j in range(len(R[i])):eij=R[i][j]-numpy.dot(P[i,:],Q[:,j]) # .DOT表示矩阵相乘for k in range(K):if R[i][j]>0: #限制评分大于零P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k]) #增加正则化,并对损失函数求导,然后更新变量PQ[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j]) #增加正则化,并对损失函数求导,然后更新变量QeR=numpy.dot(P,Q) e=0for i in range(len(R)):for j in range(len(R[i])):if R[i][j]>0:e=e+pow(R[i][j]-numpy.dot(P[i,:],Q[:,j]),2) #损失函数求和for k in range(K):e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2)) #加入正则化后的损失函数求和result.append(e)if e<0.001: #判断是否收敛,0.001为阈值breakreturn P,Q.T,resultif __name__ == '__main__': #主函数R=[ #原始矩阵[5,3,0,1],[4,0,0,1],[1,1,0,5],[1,0,0,4],[0,1,5,4]]R=numpy.array(R)N=len(R) #原矩阵R的行数M=len(R[0]) #原矩阵R的列数K=3 #K值可根据需求改变P=numpy.random.rand(N,K) #随机生成一个 N行 K列的矩阵Q=numpy.random.rand(M,K) #随机生成一个 M行 K列的矩阵nP,nQ,result=matrix_factorization(R,P,Q,K)print(R) #输出原矩阵R_MF=numpy.dot(nP,nQ.T)print(R_MF) #输出新矩阵#画图plt.plot(range(len(result)),result)plt.xlabel("time")plt.ylabel("loss")plt.show()
这篇关于推荐系统——MF及其python实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





