本文主要是介绍python学习之利用format()或zfill()函数对数据进行编号排序的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
平时对数据整理的时候,添加每行的数据序号,方便以后查询使用。
一般会用到format函数或者zfill函数,下面做了简单的示例,有需要的小伙伴可以参考。
Python zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。
zfill()方法语法:
str.zfill(width)
参数:
width – 指定字符串的长度。原字符串右对齐,前面填充0。
返回值:
返回指定长度的字符串。
示例代码:
# *_* coding : UTF-8 *_*datasort = []
i = 0
data = '莱科宁 236,汉密尔顿 358,维泰尔 294,维斯塔潘 216,博塔斯 227' # 字符串数据
newlist = data.split(',') # 将字符串数据分割为列表
print(newlist)
# 将车手与积分数据添加到新的列表中
for item in newlist:opendata = item.split(' ')datasort.append([opendata[1], opendata[0]])
datasort.sort(reverse=True) # 数据降序排列
print("\033=" * 35)
print("输出F1大奖赛车手积分".center(25))
print('=' * 35 + '\033')
print('排名 车手 积分')
# 循环打印每个赛车手与对应积分
for item in datasort:i = i + 1print(str(i).zfill(2) + '\t', item[1].ljust(14) + '\t', item[0].ljust(6) + '\t')print()
输出结果:
['莱科宁 236', '汉密尔顿 358', '维泰尔 294', '维斯塔潘 216', '博塔斯 227']
===================================输出F1大奖赛车手积分
===================================
排名 车手 积分
01 汉密尔顿 358 02 维泰尔 294 03 莱科宁 236 04 博塔斯 227 05 维斯塔潘 216
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
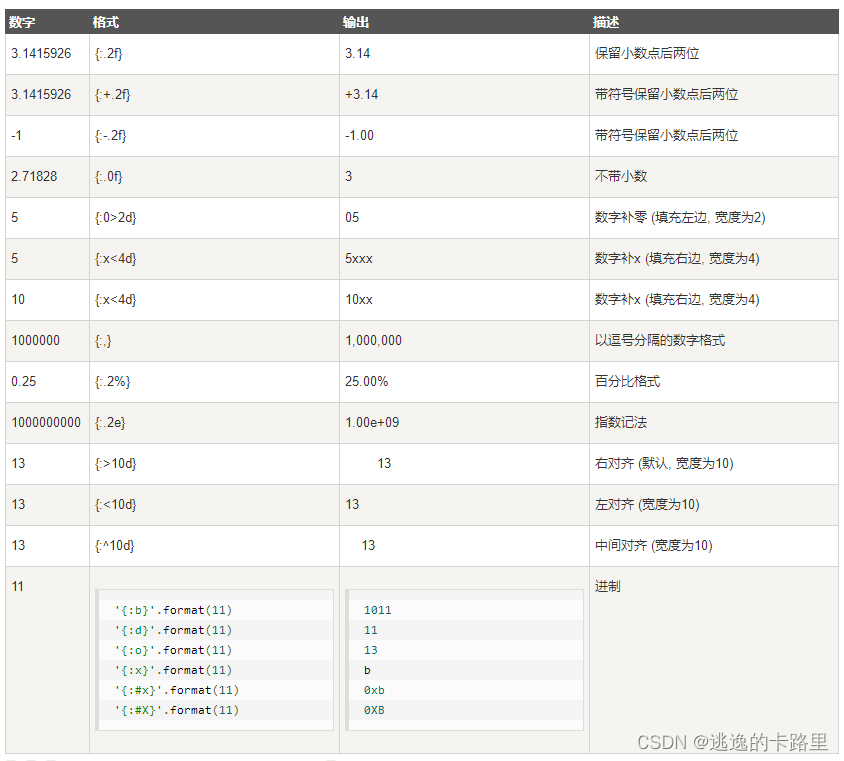
示例代码:
# *_* coding : UTF-8 *_*nba=['猛龙','勇士','雄鹿','开拓者','掘金','76人'] # 数据列表
i=0 # 默认编号
for item in nba:i=i+1 # 递增编号data='{:0>2}'.format(i)+ ' '+ item # 数字补0,填充左边宽度为2print(data) # 打印带编号的数据
输出结果:
01 猛龙
02 勇士
03 雄鹿
04 开拓者
05 掘金
06 76人
最近几年很多朋友对python的学习热情一直很高,希望对有需要参考的小伙伴有帮助,感谢支持。
这篇关于python学习之利用format()或zfill()函数对数据进行编号排序的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




