本文主要是介绍Attention mechanism总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Attention mechanism
总结:Attention机制简单来说就是一种信息过滤或者提取机制类似于记忆或者门控机制,用来筛选、更新信息。
类比于人脑,神经网络中可以存储的信息量称为网络容量。要存储的信息越多,神经元数量就越多或者网络越复杂,大量的信息增加了存储负担和计算开销。由于人脑每个时刻接收的外界信息非常多,在有限的资源下,并不能同时处理这些过载的输入信息。大脑神经系统通过注意力和记忆两个机制解决信息过载问题。注意力是指人可以在关注一些信息的同时忽略另一些信息的选择能力,选择性过滤掉大量无关信息。在计算能力有限的情况下,注意力机制将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段。
注意力一般分为两种:
- 自上而下的有意识的注意力,称为聚焦式注意力(Focus Attention)。聚焦式注意力也常称为选择性注意力(Selective Attention)。聚焦式注意力是指有预定目的、依赖任务的,主动有意识地聚焦于某一对象的注意力。
- 自下而上的无意识的注意力,称为基于显著性的注意力(Saliency Based Attention).基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关。如果一个对象的刺激信息不同于其周围信息,一种无意识的机制就可以把注意力转向这个对象。不管这些注意力是有意还是无意,大部分的人脑活动都需要依赖注意力,比如记忆信息、阅读或思考等。
Attention最早被应用于计算机视觉并取得显著成果。受到人类视觉的启发,当人们看到一张图片时,更倾向于关注图片的某一部分,而忽视其他不相干的信息,这样有助于提高感受能力。类似的在文本中,单词序列之间的关系也可以通过注意力机制处理。
Attention机制可以追溯到Seq2seq模型(Sutskever, et al. 2014)。该模型由编码器和解码器组成,编码器可将任意长度的输入句子转化为一个指定长度的上下文向量,解码器把该上下文向量转化为目标句子。Seq2seq模型主要应用于翻译任务,编码器和解码器通常是循环神经网络实现的。该模型的缺点就是在每次解码器解码时只能通过编码阶段最后生成的上下文向量c来解码,由于该向量长度固定,无法包含输入句子的所有信息,因此模型存在遗忘问题,翻译效果较差。而attention mechanism(Bahdanau et al., 2015)的引入较好的解决了该问题。
注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均。Attention在神经网路中的应用往往是作为权重向量引入的,通过为相关的元素赋予一定的权值,然后把相应元素的加权求和作为目标元素的估计。
注意力分布是指通过一个和任务相关的表示即查询向量q,从n个输入向量中选择出和某个特定任务相关的信息,并通过一个打分函数来计算每个输入向量和查询向量之间的相关性a。
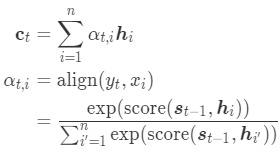
𝑠core(𝒙, 𝒒)为注意力打分函数,可以使用以下常见几种方式来计算:

理论上,加性模型和点积模型的复杂度差不多,但是点积模型在实现上可以更好地利用矩阵乘积,从而计算效率更高,当输入向量的维度𝐷 比较高时,点积模型的值通常有比较大的方差,从而导致Softmax函数的梯度会比较小。因此,缩放点积模型可以较好地解决这个问题。双线性模型是一种泛化的点积模型。假设公式(8.5)中𝑾 = 𝑼T𝑽,双线性模型可以写为𝑠(𝒙,𝒒) = 𝒙T𝑼T𝑽𝒒 = (𝑼𝒙)T(𝑽𝒒),即分别对𝒙和𝒒进行线性变换后计算点积。相比点积模型,双线性模型在计算相似度时引入了非对称性。
加权平均,注意力分布ai可以理解为对于给定向量q,第i个输入向量的受关注程度。可以通过加权求和汇总信息。

相较于只用编码阶段的最后一个隐藏状态h作为上下文向量c,Attention机制为输入句子的每个token生成一个权重向量。对于每一个输出元素,都会在编码输入句子时生成一组权重向量来衡量该元素与输入句子中各个单词之间的相关性并用这些向量的加权求和作为对应元素的上下文向量。由于每个上下文向量包含着整个输入句子的全部信息,因此并不会出现遗忘问题。生成权重向量的过程可以称作对齐或者软查找,因为每次都会用解码阶段的隐藏状态与编码阶段的所有隐藏状态进行比较,类似于查找过程。
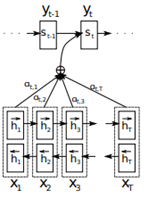
常见类别
基于Attention的帮助,输入与输出句子之间的关系不在受限于句子的长度。这点在机器翻译领域取得了巨大的提升,同时也在视觉等领域有了一定的进展(Xu et al. 2015)。人们也探索了不同形式的注意力机制如(Luong,et al., 2015; Britz et al., 2017; Vaswani, et al., 2017)。
通过对attention不断地更改优化,attention的性能得到不同程度的提高。目前主流的优化方式是通过更改打分函数和更改attention的设计结构,具体参照表格。
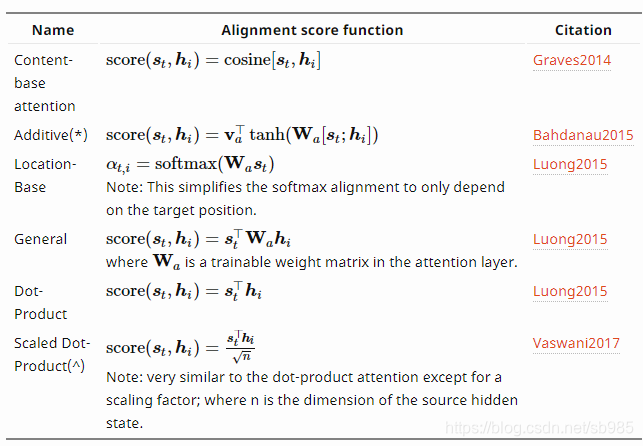
Graves2014,Bahdanau2015,Luong2015,Vaswani2017,Cheng2016

Additive attention
为了解决seq2seq网络中的不足,Bahdanau等人在论文Neural Machine Translation By Jointly Learning to Align and Translate中引入Attention 的方法,这是在NLP领域最早引入attention的文章。文中是在机器翻译任务上采用encoder-decoder结构并引入对齐机制。即输入和输出分别是一个句子,decoder每个输出都会在输入句子中寻找与解码部分当前隐藏状态最为相关的信息,并结合decoder上一阶段的输出生成当前阶段的输出。
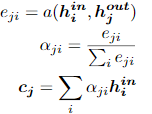
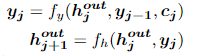
J为当前decoder解码的位置,Yj-1是decoder上一时刻的输出,hj是时刻j的隐藏状态。
Soft and hard attention
在文章show,attend and tell中,attention被用于看图配文。文中通过attention是获取了整个图片的全部信息还是部分信息来将attention分为soft和hard attention。
Soft attention也就是Bahdanau提出的attention方法,通过对输入句子的所有隐藏状态加权求和得到上下文向量。这种方法可以使神经网络通过反向传播高效的学习,但是同时也增加了计算的复杂度。
Hard attention的不同在于上下文向量c的计算不再是输入句子隐藏向量的加权求和而是根据使用attention权重参数化的multinoulli分布随机在输入句子的隐藏状态中选择一个作为上下文向量。Hard attention的好处在于降低的计算开销但是在输入句子的每个位置做决策使该方法不可微且难以优化。而该问题可用通过强化学习中的可变学习方法(variational learning methods)和策略梯度方法(policy gradient methods)解决。
Global and local attention
Global attention类似于soft attention而local attention是介于soft attention和hard attention之间的模型。在上下文向量C的计算中,判断是否Encoder的所有隐藏状态都参与了计算,若果全部参与计算就是Global Attention,只有部分参与,则是 Local Attention。
Local attention的核心思想是首先在输入句子中找到一个关注点,以该位置为中心选择一个指定大小的窗口,在该窗口内计算一个soft attention模型。该专注点可以事先设定也可以通过学习得到。Local attention的好处在于做了soft attention与hard attention的折中,既考虑了效率的同时也使该方法在窗口内可微。论文可参考Effective Approaches to Attention-based Neural Machine Translation。
Self-attention
Self-attention也叫做intra-attention,是一种用于在单个句子上计算不同位置之间相关性的注意力机制。最早在long short-term memory network一文中提出。通过在单个句子上使用注意力机制可以很好的处理句子中单词之间的依赖关系,较好理解句子结构信息。Transformer是完全基于attention的框架,使用self-attention处理输入句子,使用mutil-head attention获取不同空间的表征(这里是分开解释的,而原文中的mutil-head都是self-attention直接处理输入的句子),使用encoder-decoder attention连接encoder和decoder两个部分类似于引入了attention的seq2seq。Transformer相较于传统的RNN可以并行处理并且不会遗忘,与CNN相比还可以获取输入句子的全局特征。
Hierarchical Attention Network
分层的注意力机制是通过分析不同大小范围的信息逐级的处理输入信息的。对于一个输入句子可以分别从单词级别到句子级别到文档级别逐级使用attention分析信息。低级别的输出作为高级的query。这样既可以获取局部信息也可以获取全局的信息。具体看参考Hierarchical Attention Networks for Document Classification
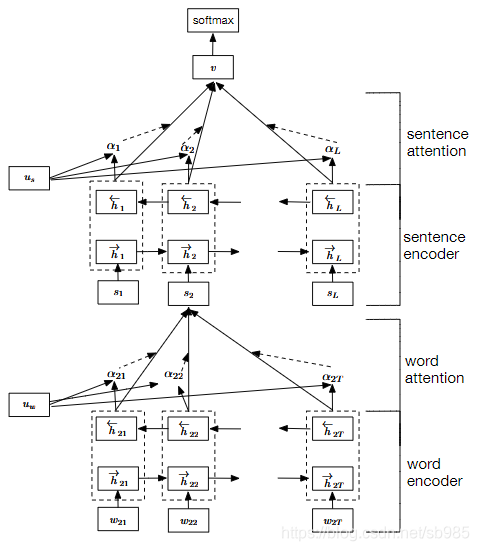
Multi-representation attentionr/ multi-dimensional Attention
在一般的任务中只考虑了输入的一个(种)特征,这些信息对一些下游任务并不充分,因此充分考虑输出信息不同方面的特征非常有必要。Multi-representation attention可以给不同的特征赋予权重,分析哪些方面较为重要。该方法可以减少噪音,降低冗余。该方法最终的特征是各个特征的加权和。该方法的好处是可以对于指定的下游任务可以直接判断哪个特征最为相关。类似的还有multi-dimensional Attention通过为输入特征向量的每个维度计算权重来选择对于指定任务较为相关的维度特征。
Memory network
对于像问答或者聊天这种任务,需要大量数据库中的信息,因为答案并非与query直接相关。End-to-End Memory Networks通过一组记忆块存储数据库中的信息,用attention计算记忆中能回答该query的信息的注意力权重。为了回答该问题可以通过多跳操作,通过若干次查询记忆,不断更新query来得到相应的回答。
Pointer network
指针网络与一般网络不同的是其输出是离散的值,这些值对应着输入句子中的位置并且输出过程中的每一步对应的目标类别数量依赖于输入句子的长度。传统的encoder-decoder结构无法实现此功能,因为该结构的输出是先验的。作者是通过attention权重估计在每个输出位置上选择输入的第i个位置作为输出的概率。该方法可以用于优化货郎问题和排序等问题。
Reference
- Sequence to Sequence Learning with Neural Networks
- Neural Machine Translation by Jointly Learning to Align and Translation
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- Attention is All You Need
- Hierarchical Attention Networks for Document Classification
- Effective Approaches to Attention-based Neural Machine Translation
- An Introductory Survey on Attention Mechanisms in NLP Problems
- An Attentive Survey of Attention Models
- Attention in Natural Language
这篇关于Attention mechanism总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





