本文主要是介绍pythonB站爬虫二(速度提升),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果只是想获取弹幕文件呢,用之前的代码就浪费太多时间了。
所以用B站官方的api做了一点改进。(没有查到除了b站官方api之外的其他方便的下载弹幕的方法)
效果如下:
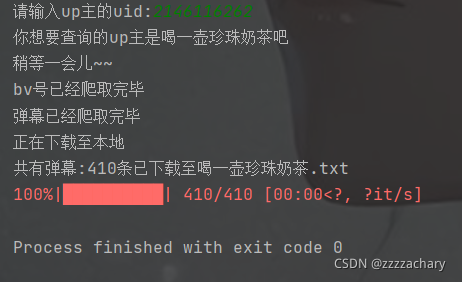

代码如下:
import requests
import json
from tqdm import tqdm
from bs4 import BeautifulSoup
from xml.dom.minidom import parseStringheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"}def get_resp_text(url):rsp = requests.get(url,headers=headers)rsp.encoding = 'utf-8'return rsp.text
def get_upname(mid):global upnamersp = requests.get('https://space.bilibili.com/'+mid)rsp.encoding = 'utf-8'html = rsp.textbss = BeautifulSoup(html, 'lxml')return (bss.find('title').text[:-len('的个人空间_哔哩哔哩_Bilibili')])
def get_bvid(mid):i = 1bvid = []while i != 0:url0 = 'https://api.bilibili.com/x/space/arc/search?mid=' + str(mid) + '&ps=30&tid=0&pn=&keyword=&order=pubdate&jsonp=jsonp'url0 = url0[:-len('&keyword=&order=pubdate&jsonp=jsonp')] + str(i) + '&keyword=&order=pubdate&jsonp=jsonp'i += 1rsp = requests.get(url0, headers=headers)rsp.encoding = 'utf-8'html = rsp.textdict = json.loads(html.replace('\n', ''))datadict = dict['data']listdict = datadict['list']vlist = listdict['vlist']if len(vlist) == 0:i = 0elif len(vlist) != 0:for _ in range(len(vlist)):bvid.insert(0, vlist[_]['bvid'])print("bv号已经爬取完毕")return bvid
def get_cid_url(bvid):cid_url = []for bid in bvid:cid_url.insert(0,'https://api.bilibili.com/x/player/pagelist?bvid=' + str(bid) + '&jsonp=jsonp')return cid_url
def get_cids(cid_urls):cids = []for cid_url in cid_urls:str = get_resp_text(cid_url)jsonstr = json.loads(str)jsrdata = jsonstr['data']jsrdict = jsrdata[0]cids.insert(0,jsrdict['cid'])return cids
def get_xml_url(cids):xml_urls = []for cid in cids:xml_urls.insert(0,'https://api.bilibili.com/x/v1/dm/list.so?oid='+str(cid))return xml_urls
def get_xmls(xml_urls):xmls = []for xml_url in xml_urls:xmls.insert(0,get_resp_text(xml_url))return xmls
def get_danmus(xmls):danmus = []for xml in xmls:tanmus = parseString(xml).documentElement.getElementsByTagName('d')for tanmu in tanmus:tanmu = tanmu.childNodes[0].datadanmus.insert(0, tanmu)print("弹幕已经爬取完毕"+'\n正在下载至本地')return danmus
def save_danmus(upname,danmus):with open(upname+".txt",'w',encoding='utf-8') as f:for danmu in tqdm(danmus):f.write(danmu+"\n")print("共有弹幕:" + str(len(danmus)) + "条已下载至"+upname+".txt")if __name__ =='__main__':uid = input("请输入up主的uid:")upname = get_upname(uid)print("你想要查询的up主是" + upname + "吧" + "\n稍等一会儿~~")bvid = get_bvid(uid)cid_urls = get_cid_url(bvid)cids = get_cids(cid_urls)xml_urls = get_xml_url(cids)xmls = get_xmls(xml_urls)danmus = get_danmus(xmls)save_danmus(upname, danmus)
这篇关于pythonB站爬虫二(速度提升)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




