本文主要是介绍使用Python轻松获取Binance历史交易,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
鉴于某些策略需要一定水平的技术数据,而其他数据可能只需要花费一个小时的时间,该过程并不总是那么简单,而基础架构,可用性和连接性等元素可能会因数据类型的不同而大相径庭。
但是为什么本文仅涉及获取“交易”数据,为什么我们使用Binance API?你可能对我的文章内容有些疑问。
数据频率和平衡
我想说,交易数据端点主要在99.99%的交易所中提供。它是细粒度的,提供了足够的详细信息(在某些非常特殊的情况下)用于回测高频交易(HFT)策略,并且可以用作 OHLC candles(1S至24H或更多,如果你想要的话)的基础。
交易数据是通用的,并且允许使用不同频率的策略进行大量实验。
为什么选择Binance?
那只是因为它是我由于数量庞大而倾向于回溯的交易所之一。
我们将要进行的编码
我们将创建一个Python脚本,该脚本接收对符号,开始日期和结束日期作为命令行参数。它将包含所有交易的CSV文件输出到磁盘。该过程可以通过以下步骤进行详细说明:
1、解析symbol,starting_date和ending_date论据。
2、获取开始日期发生的第一笔交易,以获取第一笔交易trade_id。
3、循环获取每个请求1000笔交易(Binance API限制),直到ending_date达到为止。
4、最后,将数据保存到磁盘。对于示例,我们将其保存为CSV,但是你还有其他选择,不一定保存为CSV。
5、我们将使用pandas,requests,time,sys,和datetime。在代码段中,将不会显示错误验证,因为它不会为说明添加任何值。
编码时间
该脚本将使用以下参数:
1、symbol:交易对的符号,由Binance定义。可以在此处查询,也可以从Binance Web应用程序的URL复制(不包括 _ 字符)。

-starting_date and ending_date:不言自明。期望的格式为mm/dd/yyyy,或者使用Python lang语为%m/%d/%Y。
为了获取参数,我们将使用内置函数sys(这里没有什么花哨的地方),并且为了解析日期,我们将使用datetime库。

我们将添加一天并减去一微秒,以使ending_date时间部分始终处于23:59:59.999,这使得获取当天间隔更加实用。
提取交易
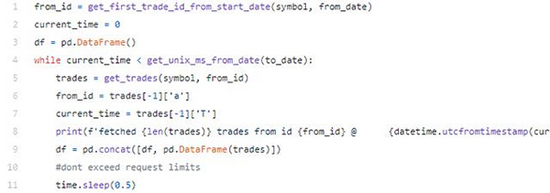
使用Binance的API并使用aggTrades端点,我们可以在一个请求中获得最多1000 笔交易,如果我们使用开始和结束参数,则它们之间的间隔最多为一小时。
在出现一些失败之后,通过使用时间间隔获取(在某个时间点或另一个时间点,流动性会变得疯狂,我会失去一些宝贵的交易),我决定尝试from_id策略。
将aggTrades选择的端点,因为它返回压缩行业。这样,我们将不会丢失任何宝贵的信息。
获得压缩的总交易。在同一时间从同一订单以相同价格执行的交易将汇总数量。
该from_id策略是这样的:
我们要得到的第一笔交易starting_date 通过发送日期的时间间隔向终点。之后,我们将从第一个获取的交易ID开始获取1000个交易。然后,我们将检查最后一笔交易是否发生在我们之后ending_date。
如果是这样,我们已经遍历了所有时间段,可以将结果保存到文件中。否则,我们将更新from_id变量以获取最后的交易ID,然后重新开始循环。
取得第一个交易编号
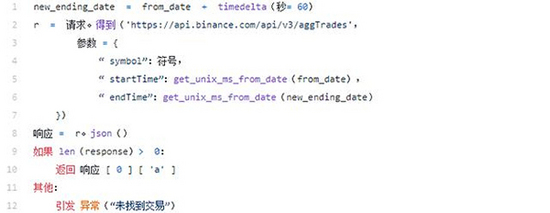
首先,我们创建一个new_end_date。那是因为我们aggTrades通过传递a startTime和endTime 参数来使用。
现在,我们只需要知道该期间的第一个交易编号,因此我们将增加60秒。在低流动性货币对中,可以更改此参数,因为不能保证在请求的第一天发生交易。
然后,使用我们的辅助函数解析日期,以使用该calendar.timegm函数将日期转换为Unix毫秒表示形式。该timegm函数是首选函数,因为它将日期保留为UTC。

请求的响应是按日期排序的贸易对象列表,格式如下:

因此,由于我们需要第一个交易ID ,因此我们将返回该response[0]["a"]值。
现在我们有了第一个交易ID,我们可以一次提取1000个交易,直到达到ending_date。以下代码将在我们的主循环中调用。它将使用from_id参数,放弃startDate和endDate参数,执行我们的请求。
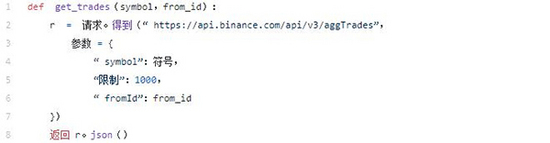
现在,这是我们的主循环,它将执行请求并创建我们的DataFrame。
我们检查是否current_time包含最近获取的交易日期大于to_date,如果是,则我们:
- 使用from_id参数获取交易
- 使用从最新交易中获取的信息来更新from_id和current_time参数
- 打印nice调试消息
- pd.concat 这些交易与我们之前的交易 DataFrame
- 使用sleep让Binance不会给我们一个429 HTTP响应
清洁和保存
组装完之后DataFrame,我们需要执行简单的数据清理。我们将删除重复trim的交易和之后发生的交易to_date(我们有这个问题,因为我们要获取1000笔交易中的大部分,因此,我们有望在目标结束日期之后执行一些交易)。
我们可以封装我们的trim功能:

并执行我们的数据清理:

现在,我们可以使用以下to_csv方法将其保存到文件中:

我们还可以使用其他数据存储机制,例如Arctic。
最后:验证你的数据
在使用交易策略时,我们必须信任我们的数据,这一点很重要。通过应用以下验证,我们可以轻松地利用获取的交易数据来做到这一点:
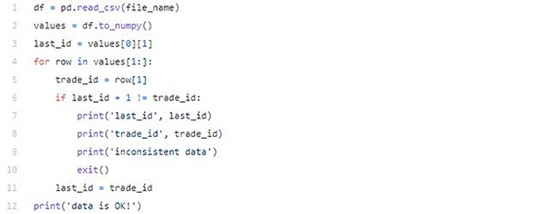
在代码段中,我们将其转换DataFrame为NumPy数组,并逐行迭代,检查交易ID是否每行递增1。
Binance交易ID是以递增方式编号的,并且是为每个交易品种创建的,因此,很容易验证数据是否正确。
PS:创建成功的交易策略的第一步是拥有正确的数据。
这篇关于使用Python轻松获取Binance历史交易的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







