本文主要是介绍UNIPOSE: DETECTING ANY KEYPOINTS(2023.10.12),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- Abstract
- Introduction
- 现有的方法存在哪些不足
- 基于此,我们提出了哒哒哒
- 取得惊人的成绩
- Related Work
- Method
- MULTI -MODALITY PROMPTS ENCODING(多模态提示编码)
- Textual Prompt Encoder(文本提示编码器)
- Visual Prompt Encoder
- CROSS-MODALITY INTERACTIVE ENCODER AND DECODER(跨模态交互编码器和解码器)
- 跨模态交互编码器
- 跨模态交互解码器
- Training and inference pipeline
- Instance-level Alignment
- Keypoint-level Alignment
- UniKPT用于关键点检测的统一数据集
- Statistical Analysis(统计分析)
- Experiment
- Conclusion
- Appendix(略)
原文链接
代码即将开源
Abstract
这项工作提出了一个称为UniPose的统一框架,通过视觉或文本提示来检测任何铰接(例如,人类和动物),刚性和柔软物体的关键点,以便进行细粒度的视觉理解和操作。关键点是任何对象,特别是铰接对象的结构感知、像素级和紧凑的表示,现有的细粒度提示任务主要集中在对象实例的检测和分割上,往往无法识别图像和实例的细粒度和结构化信息,如眼睛、腿、爪子等。同时,基于提示的关键点检测仍未得到充分的探索,为了弥补这一差距,我们首次尝试开发了一个名为UniPose的端到端基于提示的关键点检测框架,以检测任何对象的关键点。由于关键点检测任务在此框架中是统一的,我们可以利用13个关键点检测数据集,其中包含1,237个类别中的338个关键点,超过400K个实例来训练通用关键点检测模型,UniPose基于跨模态对比学习优化目标,通过文本和视觉提示的相互增强,可以有效地对齐文本和图像到关键点。实验结果表明,UniPose具有较强的跨图像样式、类别和姿态的细粒度定位和泛化能力,基于UniPose作为一个通用性的关键点检测器,我们希望它能够服务于细粒度的视觉感知、理解和生成
Introduction
关键点检测是一项基本的计算机视觉任务,用于估计图像中任何物体的二维关键点位置。它对机器人和自动化、VR/AR、神经科学、生物医学、人机交互等领域都有很大的影响
现有的方法存在哪些不足
现有的解决方案需要为不同的物种训练许多特定类别的模型。
对于未知或任意类别的多目标关键点检测问题,目前研究较少。这个问题很重要,因为它需要学习细粒度的视觉表示、与类别无关的关键点概念和语义结构信息。
Xu等人(2022a)首先提出了使用视觉提示(即新类的支持图像和相应的关键点注释)来估计查询图像中同类的姿态的类别不可知论姿态估计(CAPE)任务。它将其表述为关键点匹配问题
然而,CAPE方法有几个限制:
1)只支持视觉提示,用户交互不友好,效率低下
2)没有实例到实例匹配的关键点到关键点匹配方案往往学习低级的局部外观转换,往往导致不可避免的语义模糊,没有捕获全局关系,因此不具有有效性和鲁棒性
3)使用自上而下的两阶段检测方案(即对每个实例裁剪图像或使用ground-truth box),缺乏处理多目标场景的实例级泛化能力
4)用于训练的数据量通常是小规模的(例如,只有20K图像和100个实例类),这严重限制了基于视觉提示的关键点检测的泛化性和有效性
基于此,我们提出了哒哒哒
考虑到上述挑战和动机,我们提出在端到端基于提示的框架UniPose中统一关键点检测任务,该框架支持对未见对象和关键点进行多目标关键点检测,如图1所示
(所提出的UniPose既具有较高的关键点检测泛化能力,又具有较高的性能。UniPose利用视觉和文本提示进行训练,通过关键点-文本和关键点-图像对齐来学习细粒度的局部区域视觉表示。经过训练后,它可以泛化跨实例和跨关键点类别,其中它可以检测具有不同视觉风格,尺度和姿势的各种具有挑战性的场景中的多目标关键点)
首先,我们在类别不可知姿态估计任务中引入文本提示,引入语义引导,消除现有视觉提示的视觉歧义。通过UniPose中视觉提示和文本提示的联合训练,相互增强语义理解和定位能力,提高模型的鲁棒性和性能
其次,受类似DETR的端到端非提示人体姿态估计器(Yang et al., 2022a)的启发,我们在端到端框架中构建了一个用于多目标和关键点检测的粗到细信息流。我们首先解码实例信息,然后解码相应的细粒度关键点。这样(从图像到实例再到关键点),我们可以通过实例和关键点级别的两种对比损失来改进关键点到关键点匹配策略的相似学习过程
最后,由于数据的质量和数量对于有效的模型训练都很重要,我们通过重组来自不同数据集的不一致和未定义的关键点,合并相似的关键点和类别,将13个关键点检测数据集统一为1237个类别的338个关键点,超过400K个实例。我们通过考虑图像外观和风格多样性,具有不同姿势,视点,可见性和尺度的实例来平衡这些数据集。每个关键点都有其文本提示,每个类别都有其默认的结构化关键点集。我们称之为统一数据集UniKPT
取得惊人的成绩
通过综合实验,我们展示了UniPose对未见物体和关键点检测的显著泛化能力,与最先进的CAPE方法相比,PCK性能显著提高42.8%。此外,UniPose在12个不同的数据集上优于最先进的端到端模型(例如ED-Pose)。其性能也可与最先进的对象检测专家模型(例如GroundingDINO)和关键点检测(例如ViTPose++)相媲美。此外,UniPose在实例和关键点水平上都表现出令人印象深刻的文本-图像相似性,在区分不同动物类别时明显超过CLIP 204%,在识别各种图像风格时超过CLIP 166%。如图2所示,我们展示了UniPose在野外图像上的强大检测性能,并希望它能够为社区提供细粒度的视觉感知、理解和生成服务
(我们强调了跨类别(第一行)、多目标(第二行)和跨图像风格(第三行)在各种姿态场景下的强大检测性能)
Related Work
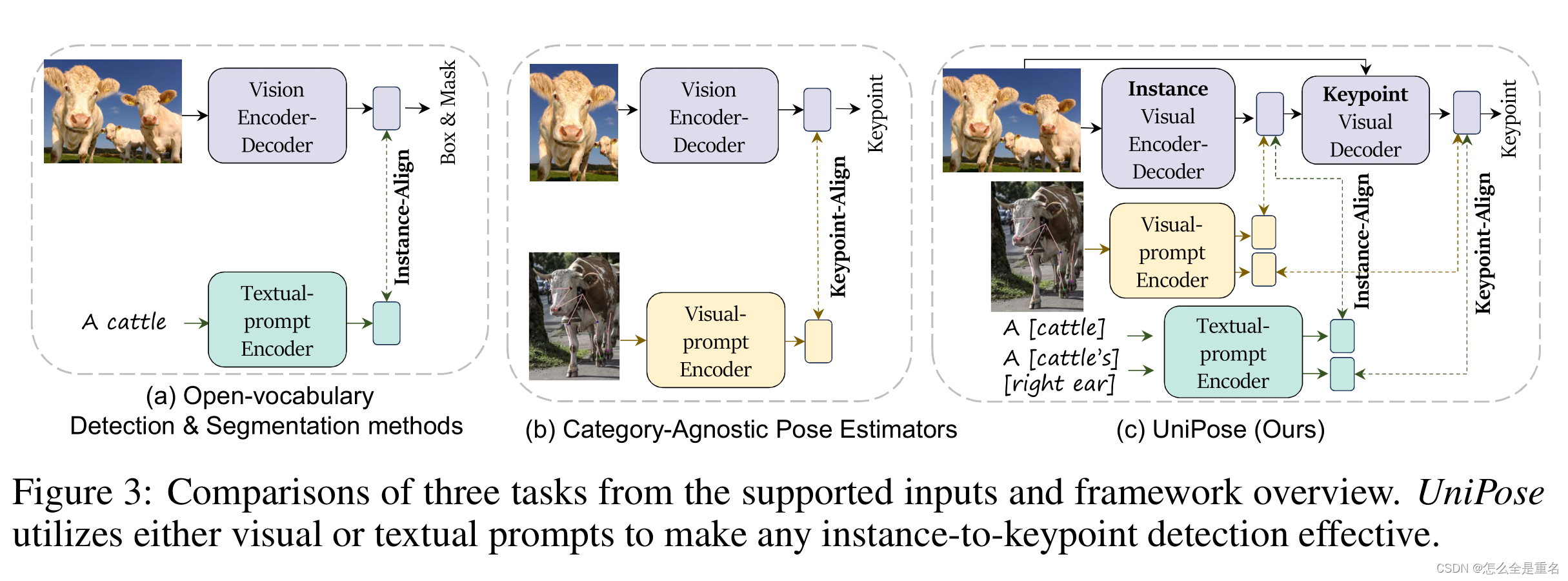
(从支持输入和框架概述的三个任务的比较,UniPose利用视觉或文本提示使任何实例到关键点的检测有效)
Method
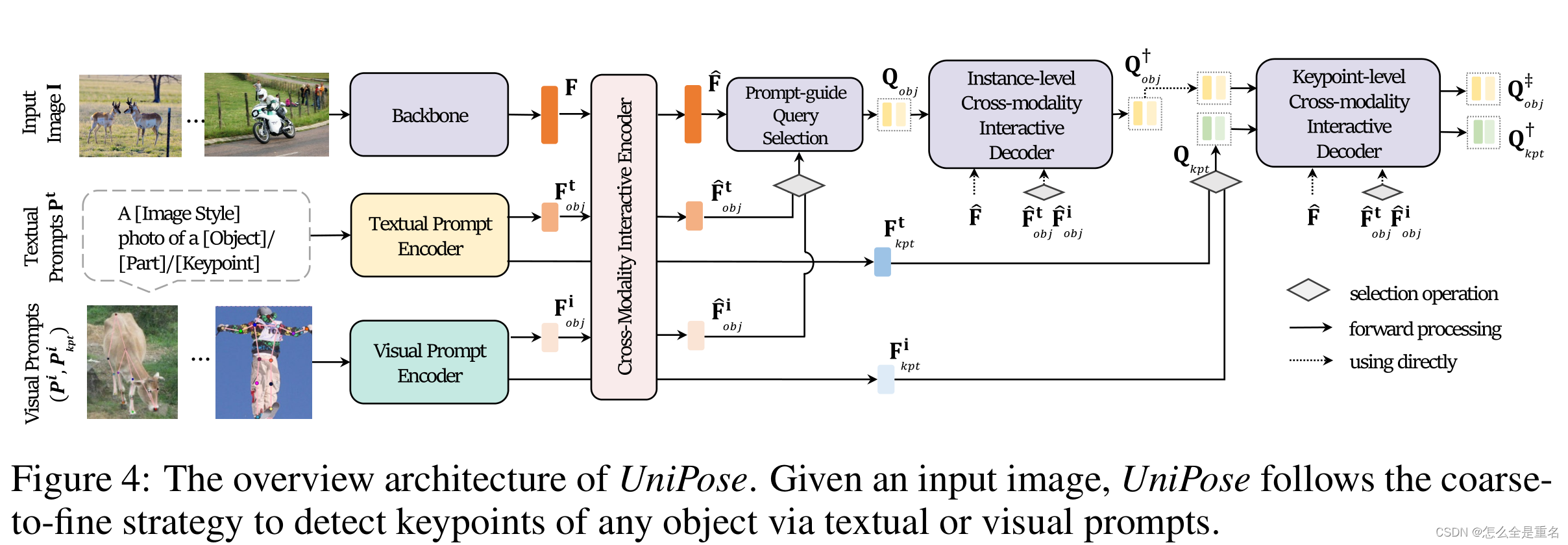
(UniPose的体系结构概述。给定输入图像,UniPose遵循从粗到精的策略,通过文本或视觉提示来检测任何对象的关键点)
UniPose是一个端到端的基于提示的关键点检测框架。它以图像I作为输入,首先解码实例级表示(即对象边界框),然后解码像素级表示(即对象关键点)。UniPose为视觉和文本提示引入了新颖的编码机制,并在输入图像和提示之间集成了一种新颖的交互方案,支持对具有任何关键点定义的任何对象进行基于提示的关键点检测
Encoding Multi-modality Inputs
我们使用三个不同的模块对相应的输入进行编码。首先,我们利用骨干网络提取 I 的多尺度特征,得到标记化表征F。然后,采用文本提示编码器(Textual Prompt Encoder)将Pt编码为文本语义表征Ft,其中Ft obj表示对象,Ft kpt表示关键点。最后,我们使用视觉提示编码器将Pi和Pi kpt编码为视觉语义表示Fi,其中Fi obj和Fi kpt分别对应对象和关键点
Coarse-to-Fine Keypoint Detection
给定表征F, Ft和Fi,我们引入了一个跨模态交互编码器,通过交叉注意操作来实现不同模态之间的交互,从而获得增强表征Fhat,Ft hat和Fi hat。此外,我们采用了一种从粗到细的方案,并集成了两个专注于不同粒度的解码器,包括实例级跨模态交互解码器和关键点级跨模态交互解码器。我们进一步采用关键点级跨模态解码器对Q kpt和Q†obj进行细化,得到Q†kpt和Q‡obj。最后,我们利用前馈网络用Q†kpt回归关键点位置,用Q‡obj回归目标边界框。此外,我们使用Q†kpt对关键点类别进行分类,使用Q‡obj对对象类别进行分类,使用提示引导分类器。
MULTI -MODALITY PROMPTS ENCODING(多模态提示编码)
CLIP在数以亿计的图像-文本对上进行训练,将图像与其相应的标题对齐(Radford et al., 2021)。在这种情况下,UniPose利用其预训练的图像和文本编码器,通过精心设计的编码机制对用户提示进行编码
Textual Prompt Encoder(文本提示编码器)
1)分层文本结构。为了实现文本到图像/区域/关键点的精确映射,我们提出了一种描述实例和关键点的分层文本结构,即图像→实例→部分→关键点
2)文本提示退出。利用层次文本结构为UniPose提供了专门的检索功能,此外,在训练过程中,我们引入随机dropout来描述,包括图像样式、对象或部分,以提高其一般检索能力
Visual Prompt Encoder
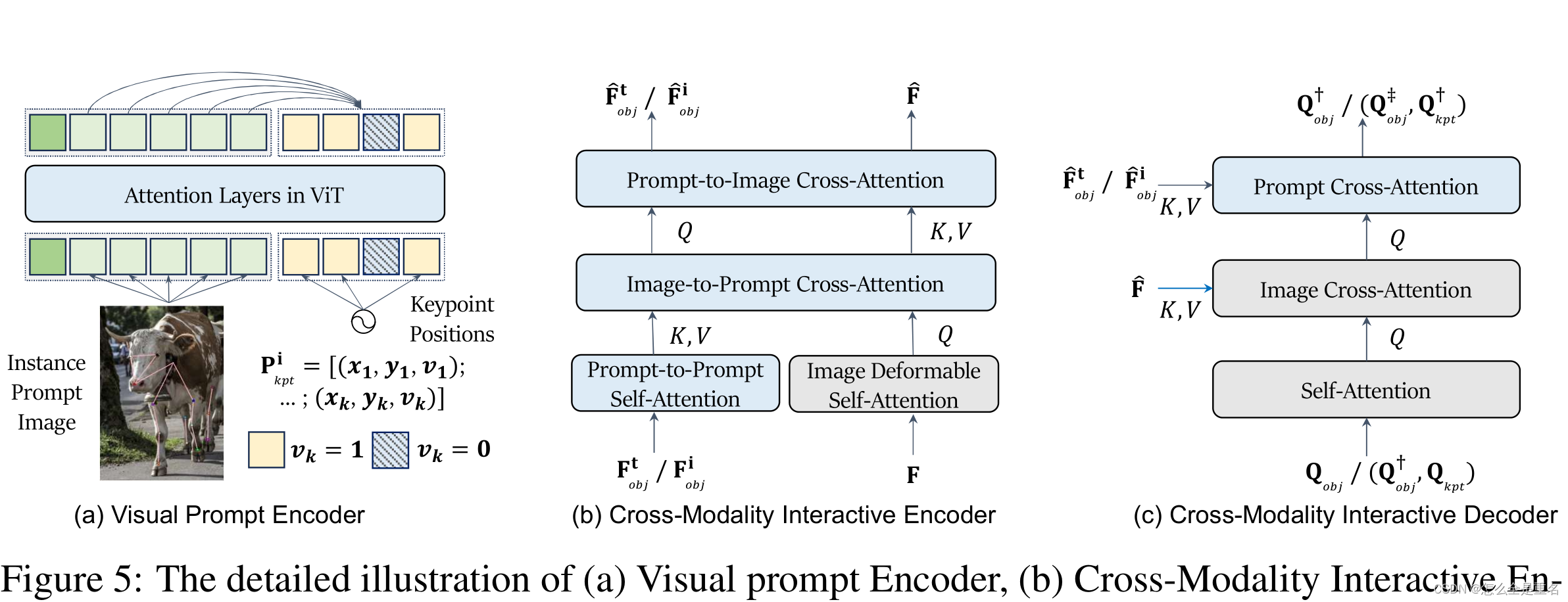
((a)视觉提示编码器,(b)跨模态交互编码器,©跨模态交互解码器。在(b)和©中,灰色的模块是在以前的工作中呈现的,而蓝色的模块是为了包含提示交互而引入的)
原始CLIP的图像编码器(例如:(ViT)通常通过可学习的[CLS]令牌和补丁令牌获得图像表示,它们是图5-(a)左侧的输入。UniPose通过进一步合并关键点位置编码(表示为的右侧的输入)扩展了这一点
CROSS-MODALITY INTERACTIVE ENCODER AND DECODER(跨模态交互编码器和解码器)
UniPose通过合并多模态提示,将以前的闭集关键点检测扩展到开集场景。为了实现这一点,我们引入了跨模态交互编码器和解码器,允许通过多模态提示对输入图像进行任何关键点检测,如图5-(b)和©所示
跨模态交互编码器
除了之前工作中使用的可变形图像自关注层,即图5-(b)的灰色模块,我们的跨模态交互编码器进一步引入了提示符的自注意层和连接图像和提示符的交叉注意层,如图5-(b)的蓝色模块所示
跨模态交互解码器
UniPose将解码器解耦为实例级解码器和关键点级解码器。这种分离允许以粗到细的方式进行关键点检测。在之前的工作中,使用对象查询和关键点查询,通过查询之间的自关注和图像与查询之间的交叉关注,独立查询相应的边界框和关键点,即图5-©的灰色模块。为了增强提示引导的关键点检测,我们更进一步,通过提示到查询的交叉注意将提示表示集成到查询中,如图5-©中的蓝色模块所示
Training and inference pipeline
我们采用与之前的端到端人体姿态估计器相同的边界盒和关键点回归损失,对象的边界盒回归的L1损失和GIOU损失,关键点回归的L1损失和OKS损失(Shi et al., 2022)。此外,UniPose用提示到实例的对比损失替换了对象分类损失,并引入了用于细粒度对齐的提示到关键点的对比损失
Instance-level Alignment
以往的关键点检测框架主要关注近集目标,通常使用简单的线性层作为目标分类器,UniPose将多模态提示(即文本或图像)编码为统一公式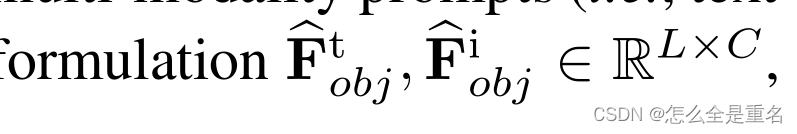
其中L为提示符中实例类的数量,C为特征维度,我们使用预测对象Q‡obj和提示标记之间的对比损失进行分类
Keypoint-level Alignment
在以往的关键点检测框架中,与关键点相关的分类问题往往被忽略,学习过程主要集中在建立预测关键点与标记关键点之间的一对一映射,相反,UniPose使用一组统一的关键点定义向提示到关键点对齐迈出了第一步
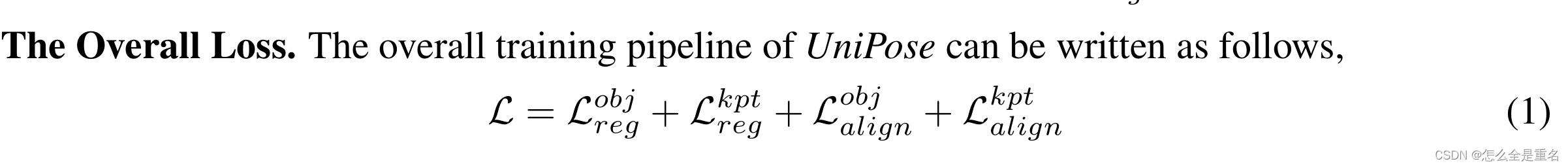
UniKPT用于关键点检测的统一数据集
我们提出基于三个原则统一现有关键点检测数据集:
1)收集和包含所有铰接的,刚性的和柔软的对象
2)尽可能包括更广泛的对象和关键点类别
3)跨越各种图像风格
如表1所示,我们统一了13个关键点检测数据集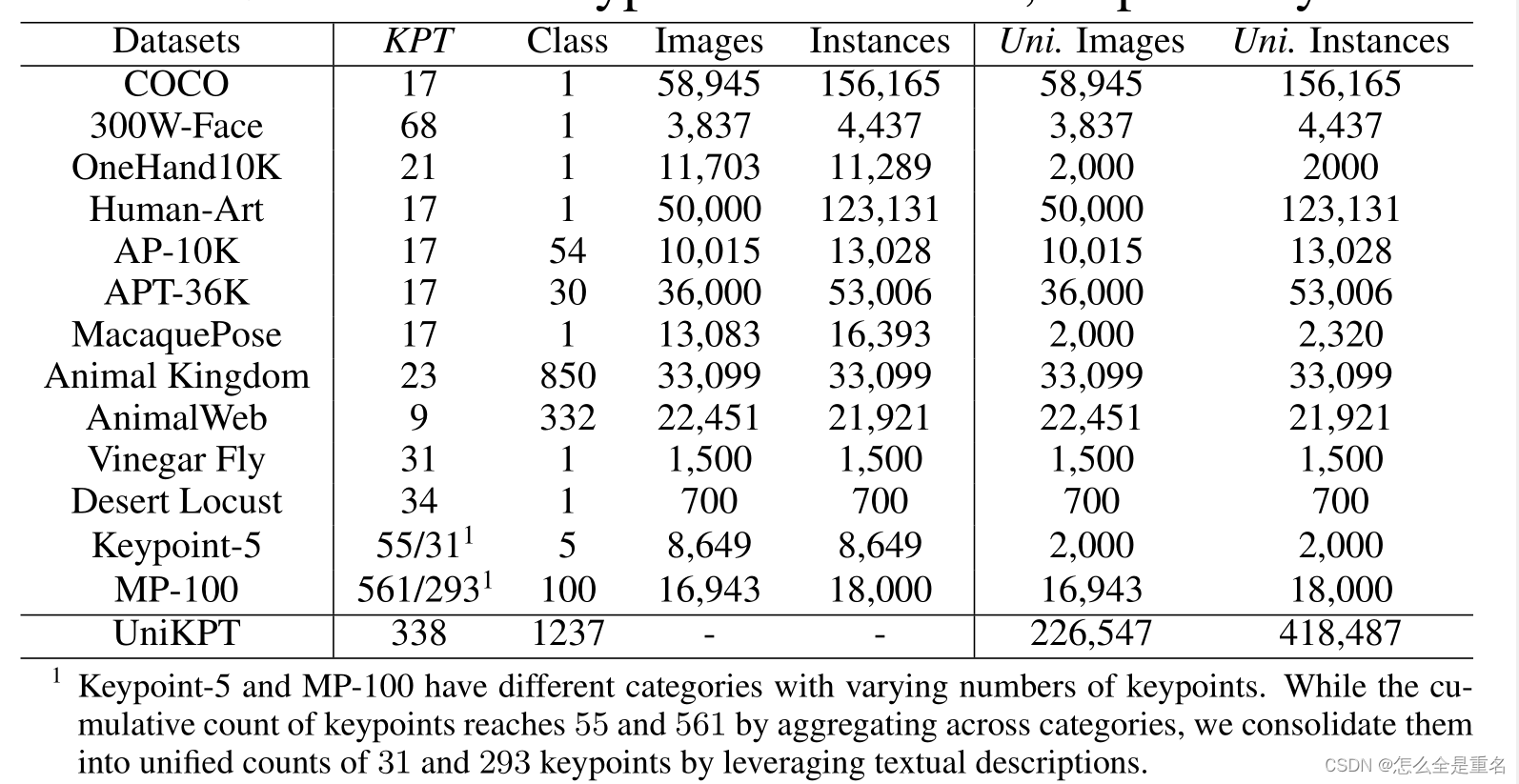
Statistical Analysis(统计分析)
统一的数据集包含226,547张图像和418,487个实例,包含338个关键点和1,237个实例类别。特别是对于像人类和动物这样的铰接对象,我们进一步根据生物分类学对其进行了分类,得到了66科23目7纲1216种
Experiment
验证了该算法对未见目标和关键点检测的泛化能力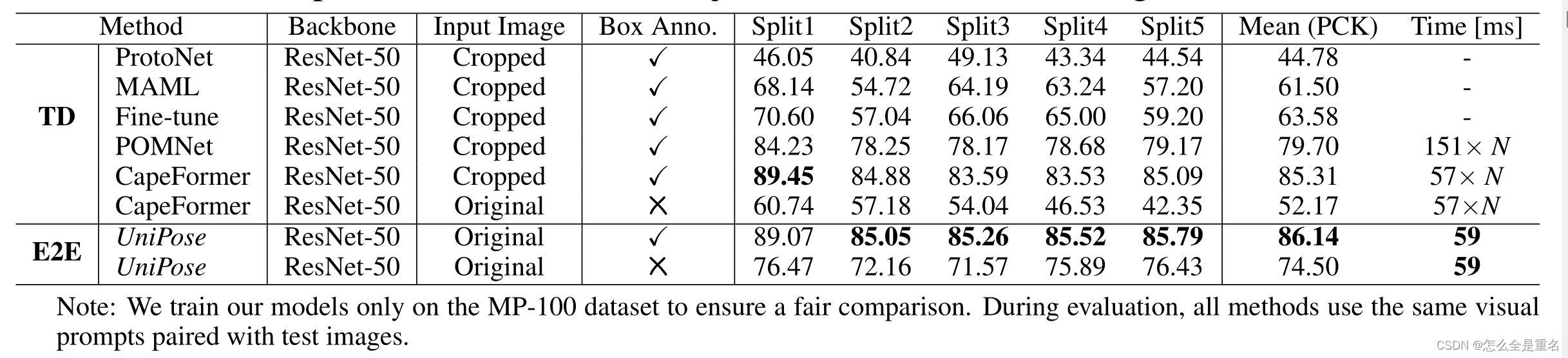

UniPose是建立在ED-Pose的基础上,采用从粗到精的关键点检测方法
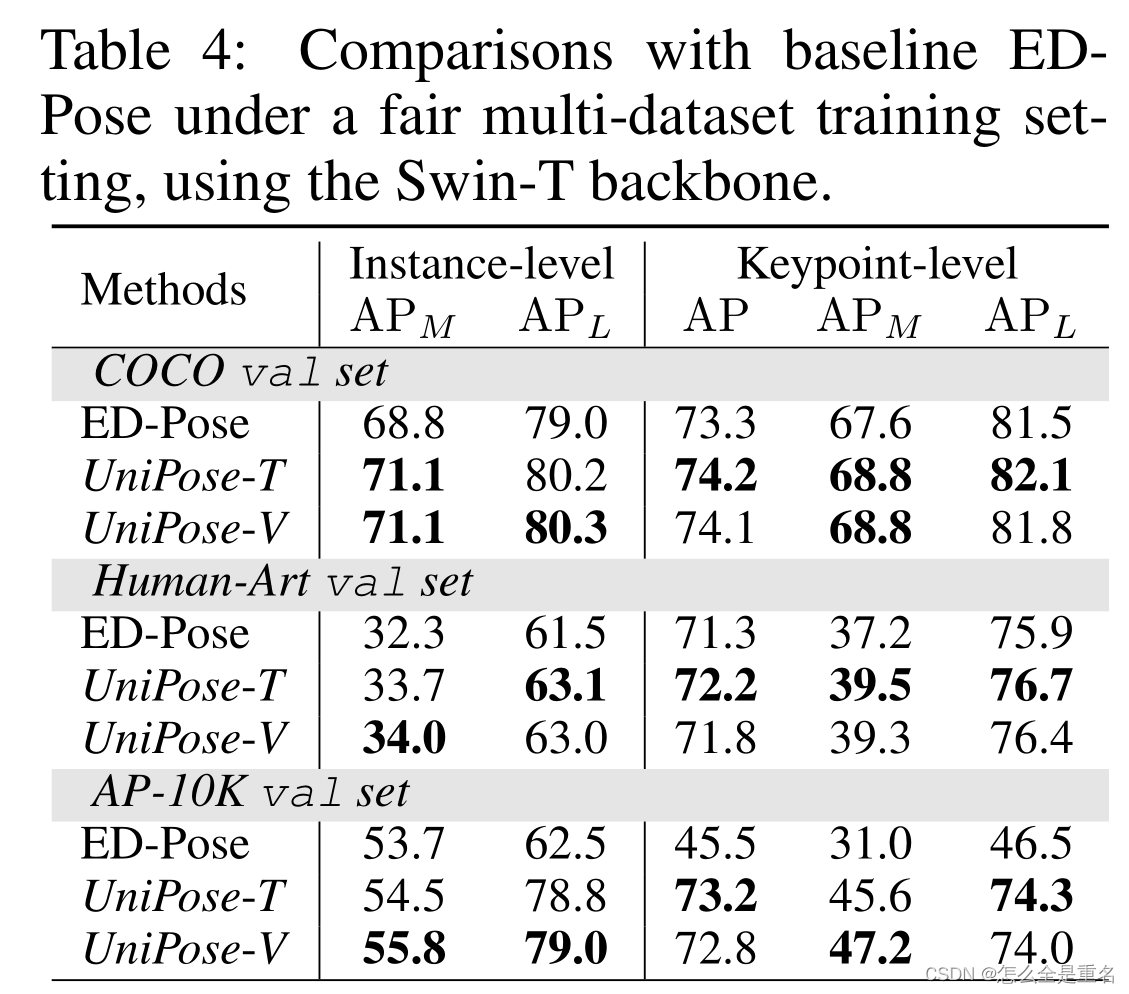
UniPose的优势在于以端到端的方式检测更多的对象和关键点

UniPose可以很好地处理任何铰接的、刚性的和柔软的对象

UniPose在所有评估数据集上的表现都优于所有通才模型,证明了UniPose作为一个健壮的通才关键点检测器的能力
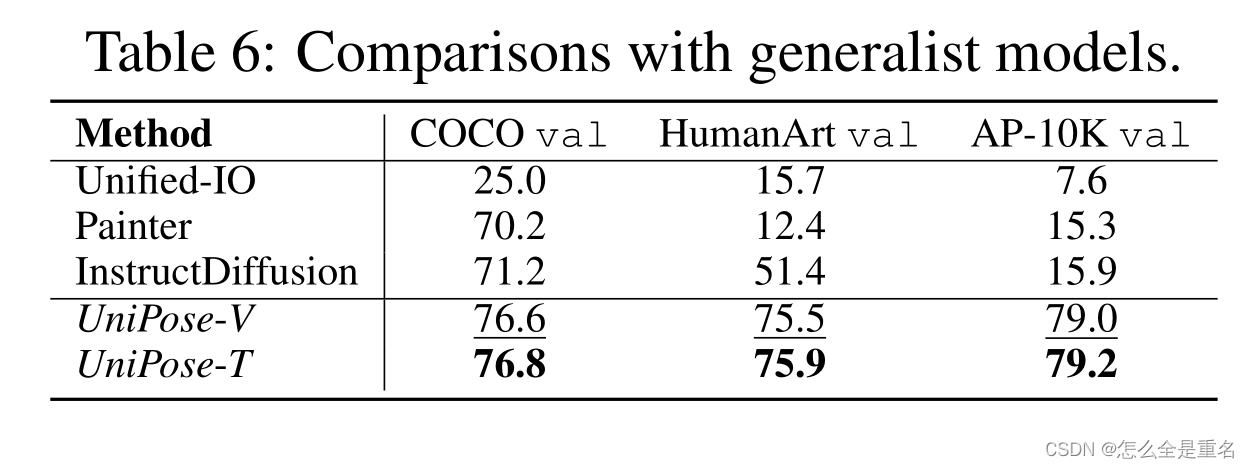
UniPose在实例和关键点水平上始终提供更高质量的文本-图像相似性分数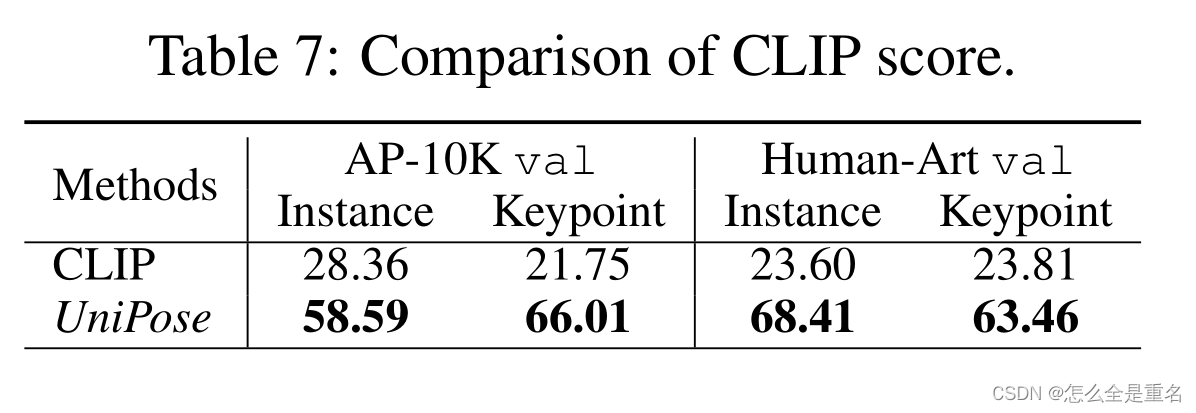
与开放词汇检测模型的比较,UniPose成功地解决了未能定位细粒度的关键点的调整,在所有数据集上实现了显着的改进
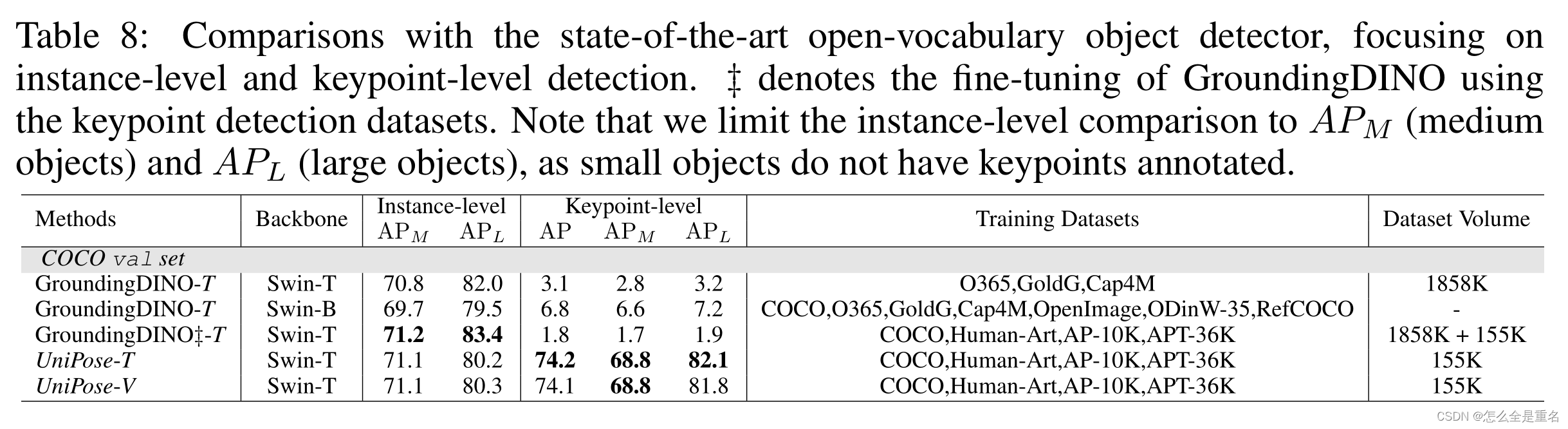
表9的结果强调了 Instance-to-Keypoint Alignment 在帮助模型区分类别和提高分类性能方面的重要性
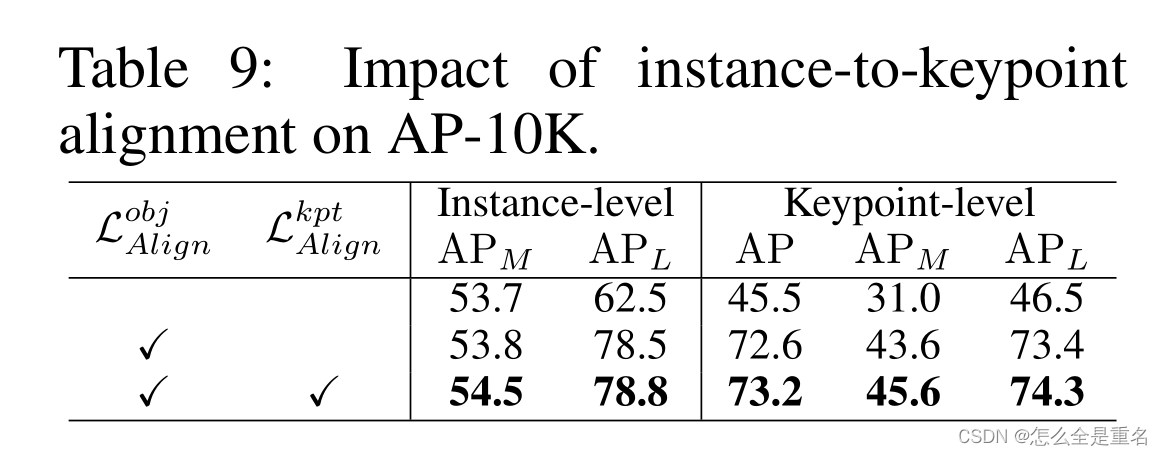
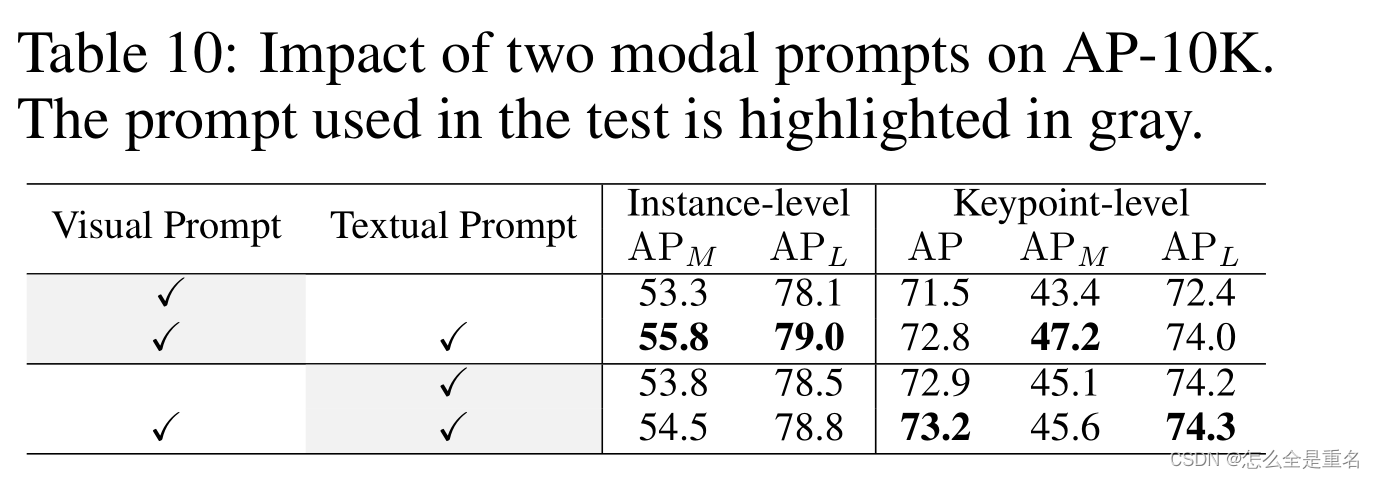
表10结果突出了文本和视觉提示的相互优势
数据集数量对AP-10K和AnimalPose的影响

Conclusion
这项工作研究了通过视觉提示或文本提示从实例到关键点级别检测任何关键点的问题。为了解决这一问题,我们提出了一个基于统一关键点数据集的端到端从粗到细的框架,学习通用语义细粒度关键点概念和全局到局部的关键点结构,实现了高性能和可泛化性。
Appendix(略)
这篇关于UNIPOSE: DETECTING ANY KEYPOINTS(2023.10.12)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







